| title | date | summary | tags | categories |
|---|---|---|---|---|
rust语言基础 |
2022-07-01 10:24:56 -0700 |
Rust 语言使用 let 关键字来声明和定义一个变量。
let 变量名=值
const _MAX: u32=1000;
fn main() {
let a=1;
println!("a={}", a);
let mut b: u32=1;//使用mut才是变量不用就是常量
b=2;
println!("b={}", b);
let b:f32=1.1;
println!("b={}", b);//原来的被隐藏
println!("_MAX={}", _MAX);
}上面的代码中,我们并没有为每一个变量指定它们的数据类型。Rust 编译器会自动从 等号 = 右边的值中推断出该变量的类型。例如 Rust 会自动将 双引号 阔起来的数据推断为 字符串,把没有小数点的数字自动推断为 整型。把 true 或 false 值推断为 布尔类型。
Rust 语言中有四种标量数据类型:
- 整型
- 浮点型
- 布尔类型
- 字符类型
| 大小 | 有符号 | 无符号 |
|---|---|---|
| 8 bit | i8 | u8 |
| 16 bit | i16 | u16 |
| 32 bit | i32 | u32 |
| 64 bit | i64 | u64 |
| 128 bit | i128 | u128 |
| Arch | isize | usize |
整型的长度还可以是 arch。arch 是由 CPU 构架决定的大小的整型类型。大小为 arch 的整数在 x86 机器上为 32 位,在 x64 机器上为 64 位。
fn main(){
let price1 = 100;
let price2:u32 = 200;
let price3:i32 = -300;
let price4:isize = 400;
let price5:usize = 500;
println!("price1 is {}", price1);
//输出 price is 100
println!("price2 is {} and price3 is {}", price3, price2);
//输出 price2 is -300 and price3 is 200
println!("price4 is {} and price5 is {}", price4, price5);
//输出 price4 is 400 and price5 is 500
}f32又称为 单精度浮点型。f64又称为 双精度浮点型,它是 Rust 默认的浮点类型.
Rust 中不能将 0.0 赋值给任意一个整型,也不能将 0 赋值给任意一个浮点型。
当数字很大的时候,Rust 可以用 **(_下划线) ** ,来让数字变得可读性更好。
fn main(){
let price1:f32 = 1.111_111;
let price2:u32 = 2000_00000;
println!("price1 is {}", price1);
println!("price2 is {} ", price2);
}let checked:bool = true;字符(char) ,就是字符串的基本组成部分,也就是单个字符或字。
Rust 使用 UTF-8 作为底层的编码 ,而不是常见的使用 ASCII 作为底层编码。
Rust 中的 字符数据类型 包含了 数字、字母、Unicode 和 其它特殊字符。
fn main(){
let price1 = '好';
println!("price1 is {}", price1);
}
这一点和c语言不同,C语言底层使用ascall,字符不能是汉字fn main(){
const PI:f64=3.141592653589793;
let price1 = '好';
// 初始化:const和static都要求赋予它们一个值。它们必须只能被赋予一个常量表达式的值。换句话说,你不能用一个函数调用的返回值或任何相似的复合值或在运行时赋值。
// 使用 const 关键字定义常量。
// 定义常量时必须指定数据类型。
// 常量名称的命名规则和之前变量的命名规则一样,但常量名称一般都是 大写字母。
//Rust 中,常量不能被隐藏,也不能被重复定义。
// static:具有 ‘static 生命周期的,可以是可变的变量(须使用 static mut 关键字)。
// 有个特例就是 “string” 字面量。它可以不经改动就被赋给一个 static 变量,因为它 的类型标记:
// &’static str 就包含了所要求的生命周期 ‘static。其他的引用类型都 必须特地声明,使之拥有’static 生命周期。
//对于static,Rust以静态量的方式提供了类似“全局变量”的功能。它们与常量类似,不过静态量在使用时并不内联。这意味着对每一个值只有一个实例,并且位于内存中的固定位置。
static BOOK:&'static str = "asd";
static PEN:i32=5;
//因为这是可变的,一个线程可能在更新N同时另一个在读取它,导致内存不安全。
//因此访问和改变一个static mut是不安全(unsafe)的,因此必须在unsafe块中操作
static mut NUM:i32=10;
unsafe{
NUM=NUM+1;
println!("NUM= {}",NUM);//必须放在这里
}
println!("price1 is {}", price1);
println!("PI= {}",PI);
println!("BOOK= {}",BOOK);
println!("PEN= {}",PEN);
}//rust 希望在数组容量不会变化的时候,用 &str。在数组长度可能发生变化的情况下,使用 String。
//字符串字面量&str,字符串字面量和全局变量、static变量一样位于程序运行之后虚拟地址空间中的代码区。
//字符串对象String ,
//&str 转 String
//let s: String = "hello".to_string();
//let t: String = String::from("hello");
//String 转 &str
//在 rust 中,凡是需要用 &str 的地方,都可以直接用 &String 类型的数据
//fn greet(s: &str) {
// ...
//}
//fn main() {
// let s: String = String::from("hello");
// greet(&s);
//}
fn show_name(name:&str){
println!("看看这个{}", name);
}
fn main(){
let s1 = String::new();
println!("s1:{},s1-len:{}",s1,s1.len());
let s2 = String::from("你好世界");
println!("s2:{},s2-len:{}",s2,s2.len());
let mut s3=String::new();//创建一个新的字符串对象
s3.push_str("1111");//再字符串末尾追加字符串。
println!("{}",s3);
s3.push('o');//是在原字符上追加字符,而不是返回一个新的字符串
s3.push('k');
println!("{}",s3);
let s4= String::from("haooooo");
s4.replace("haooooo", "hahahahah");//指定字符串子串替换成另一个字符串
println!("{}",s4);
let a=s4.len();//返回字符串中的 总字节数。该方法会统计包括 制表符 \t、空格 ``、回车 \r、换行 \n 和回车换行 \r\n 等等。
println!("{}",a);
let s5="\tqqqqq\n".to_string();//将字符串转换为字符串对象,方便以后可以有更多的操作。
show_name(s5.as_str());//返回一个字符串对象的 字符串 字面量。
show_name(s5.trim());//去除字符串头尾的空白符。空白符是指 制表符 \t、空格 ``、回车 \r、换行 \n 和回车换行 \r\n 等等
println!("{}",s5.trim().len());
let s6="1,2,3,4,5,6,7,8,9,10,11";
for item in s6.split(",") {//将字符串根据某些指定的 字符串子串 分割,返回分割后的字符串子串组成的切片上的迭代器。
print!(" {}",item);}
for item in s6.chars() {//将一个字符串打散为所有字符组成的数组
print!("字符: {}|",item);}
let s7=s5+&s6;
println!("{}",s7);
}注:Rust 语言不支持自增自减运算符 ++ 和 --
除if外无switch,switch用match代替
// match variable_expression {
// constant_expr1 => {
// // 语句;
// },
// constant_expr2 => {
// // 语句;
// },
// _ => {
// // 默认
// // 其它语句
// }
// };
fn main(){
let code = "10010";
let choose = match code {
"10010" => "联通",
"10086" => "移动",
_ => "Unknown"
};
println!("选择 {}", choose);
//输出 选择 联通
let code = "80010";
let choose = match code {
"10010" => "联通",
"10086" => "移动",
_ => "Unknown"
};
println!("选择 {}", choose);}
//输出 选择 Unknownfn main(){
for num in 1..5{
println!("num is {}", num);//这是一个左闭右开的区间,1..5,那就只包含 1,2,3,4
}
for num in 1..=5 {
println!("num is {}", num);//可以使用 a..=b 表示两端都包含在内的范围。
}
let a=vec!["a", "b", "c", "d", "e",];
for nmae in a.iter() { //iter - 在每次迭代中借用集合中的一个元素。这样集合本身不会被改变,循环之后仍可以使用。
match nmae {
&"a"=>println!("ok: {}", nmae),
_=>println!("fatal: {}", nmae),
}
}
for name in a.into_iter() {//into_iter - 会消耗集合。在每次迭代中,集合中的数据本身会被提供。一旦集合被消耗了,之后就无法再使用了,因为它已经在循环中被 “移除”(move)了。
match name{
"a"=>println!("ok: {}", name),
_ => println!("fatal: {}", name),
}
}
let mut b=vec!["a", "b", "c", "d", "e", ];
for name in b.iter_mut() {
// iter_mut - 可变地(mutably)借用集合中的每个元素,从而允许集合被就地修改。
// 就是停止本次执行剩下的语句,直接进入下一个循环。
*name =match name {
&mut "a" =>{"riscv"},
&mut "b" =>{"riscv"},
_ => *name,
}
}
println!("b: {:?}", b);
let mut num=1;
while num<5{//上面的条件表达式为真,就会执行 while 循环。
println!("{}", num);
num+=1;
}
let mut c=1;
loop{//一种重复执行且永远不会结束的循环
if c>5{
break;
}
println!("{}", c);
c=c+2;
}
}fn get_name() -> String {
return String::from("1111");
}
//Rust 语言的返回值定义语法,在 小括号后面使用 箭头 ( -> ) 加上数据类型 来定义的。
fn get_name2() -> String {
String::from("2222")
}
//如果函数代码中没有使用 return 关键字,那么函数会默认使用最后一条语句的执行结果作为返回值。
fn double_price(mut price:i32){
//值传递 是把传递的变量的值传递给函数的 形参,所以,函数体外的变量值和函数参数是各自保存了相同的值,互不影响
price=price*2;
println!("内部的price是{}",price)
}
fn double_price2(price:&mut i32){
//值传递变量导致重新创建一个变量。但引用传递则不会,引用传递把当前变量的内存位置传递给函数。传递的变量和函数参数都共同指向了同一个内存位置。引用传递在参数类型的前面加上 & 符号。
*price=*price*2;//星号(*) 用于访问变量 price 指向的内存位置上存储的变量的值。这种操作也称为 解引用。 因此 星号(*) 也称为 解引用操作符。
println!("内部的price是{}",price)
}
fn main() {
println!("r1:{}", get_name());
println!("r2:{}", get_name2());
let mut price:i32 = 1;
double_price(price);
println!("外部的price是{}",price);
double_price2(&mut price);
println!("外部的price是{}",price);
}fn show_tuple(tuple:(&str,&str)){
println!("{:?}",tuple);
}
fn main() {
//Tuple 元组是一个 复合类型 ,可以存储多个不同类型的数据。 Rust 支持元组 tuple 类型。元组使用括号 () 来构造(construct)。函数可以使用元组来返回多个值,因为元组可以拥有任意多个值。
// 元组一旦定义,就不能再增长或缩小,长度是固定的。元组的下标从 0 开始。
let t: (i32, f64, u8) = (500, 6.4, 1);
let (x, y, z) = t;//解构元组
println!("x:{} y:{} z:{}",x,y,z);
println!("{}, {}, {}",t.0, t.1, t.2);//访问元组
let t1:(&str, &str)=("aaaa","bbbb");
show_tuple(t1);
}// 数组 是用来存储一系列数据,拥有相同类型 T 的对象的集合,在内存中是连续存储的。使用中括号 [] 来创建,且它们的大小在编译时会被确定。数组下标是从0 开始。数组是在栈中分配的,数组可以自动被借用成为 切片(slice)
fn show_arr(arr:[&str;3]){
let l = arr.len();
for i in 0..l {
println!("ok: {}",arr[i]);
}
}
fn modify_arr(arr:&mut [&str;3]){
let l = arr.len();
for i in 0..l {
arr[i]="";
}
}
fn main() {
//let 变量名:[数据类型;数组长度]=[值1,值2,值3,...];
let mut a1:[&str;3]=["hello","world","hello world"];
// let 变量名=[值1,值2,值3,...];
let a2=["hello", "world", "hello world"];
//let 变量名:[数据类型;数组长度]=[默认值,数组长度];
let a3:[&str;3]=["";3];
for item in a1.iter() {
println!("{}", item);}
for item in a1{
println!("{}", item);
}
show_arr(a1);//值传递 传递一个数组的副本,副本的修改,不会影响原数组。
modify_arr(&mut a1);//引用传递 传递内存的地址给函数,修改数组的任何值都会修改原来的数组。
println!("{:?}\n", a1);
}Rust 的核心功能(之一)是 所有权(ownership)。虽然该功能很容易解释,但它对语言的其他部分有着深刻的影响。
引入:所有程序都必须管理其运行时使用计算机内存的方式。一些语言中具有垃圾回收机制,在程序运行时不断地寻找不再使用的内存;在另一些语言中,程序员必须亲自分配和释放内存。Rust 则选择了第三种方式:通过所有权系统管理内存,编译器在编译时会根据一系列的规则进行检查。如果违反了任何这些规则,程序都不能编译。在运行时,所有权系统的任何功能都不会减慢程序。
注:因为变量要负责释放它们拥有的资源,所以资源只能拥有一个所有者。这也防止了资源的重复释放。注意并非所有变量都拥有资源(例如引用)。
move:在进行赋值(let a = b)或通过值来传递函数参数(foo(a))的时候,资源的所有权(ownership)会发生转移。按照 Rust 的规范,这被称为资源的移动(move)。
注:在移动资源之后,原来的所有者不能再被使用,这可避免悬挂指针(dangling pointer)的产生
当我们将 s1 赋值给 s2,String 的数据被复制了,这意味着我们从栈上拷贝了它的指针、长度和容量。我们并没有复制指针指向的堆上数据
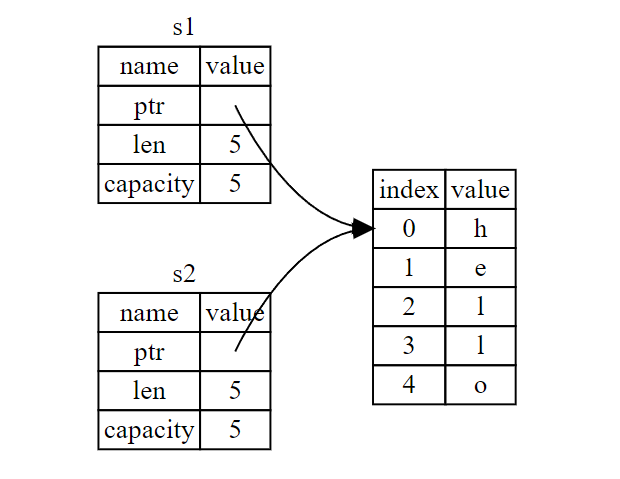
所有权管理内存的特点
Rust 同时使第一个变量无效了,这个操作被称为 移动
另外,这里还隐含了一个设计选择:Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何 自动 的复制可以被认为对运行时性能影响较小。
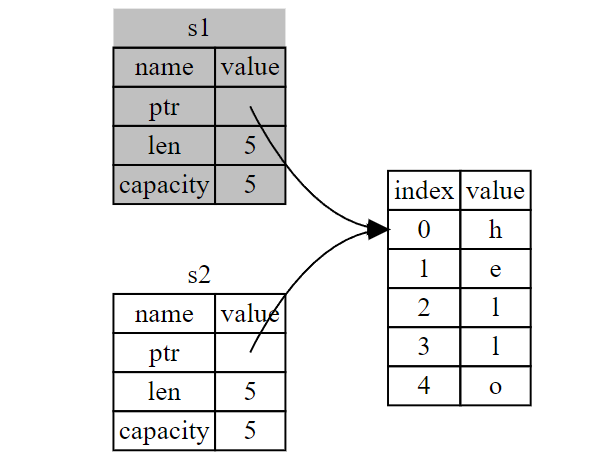
栈:它是一种 后进先出 的机制,类似我们日常的落盘子,只能一个一个向上方,然后从最上面拿一个盘子。一个变量要放到栈上,那么它的大小在编译时就要明确。i32 类型的变量,它就占用 4 个字节。Rust 中可以放到栈上的数据类型,他们的大小都是固定的。如果是字符串,在运行时才会赋值的变量,在编译期的时候大小是未知或不确定的。所以字符串类型存储在堆上。
堆:用于编译时大小未知或不确定的,只有运行时才能确定的数据。在堆上存储一些动态类型的数据。堆是不受系统管理的,是用户自己管理的,也增加了内存溢出的风险。
注:入栈比在堆上分配内存要快,因为(入栈时)分配器无需为存储新数据去搜索内存空间;其位置总是在栈顶。相比之下,在堆上分配内存则需要更多的工作,这是因为分配器必须首先找到一块足够存放数据的内存空间,并接着做一些记录为下一次分配做准备。
访问堆上的数据比访问栈上的数据慢,因为必须通过指针来访问。现代处理器在内存中跳转越少就越快(缓存)
跟踪哪部分代码正在使用堆上的哪些数据,最大限度的减少堆上的重复数据的数量,以及清理堆上不再使用的数据确保不会耗尽空间,这些问题正是所有权系统要处理的。一旦理解了所有权,你就不需要经常考虑栈和堆了,不过明白了所有权的主要目的就是为了管理堆数据,能够帮助解释为什么所有权要以这种方式工作。
所有权规则:
-
Rust 中的每一个值都有一个被称为其 所有者(owner)的变量。
-
值在任一时刻有且只有一个所有者。
-
当所有者(变量)离开作用域,这个值将被丢弃
引用:
值传递,每个值都有一个所有权,允许使得一个新变量获取其所有权,就是让一个变量指向原来变量的即指向另一个变量的地址,由栈分配的资源不存在所有权如基本数据类型,只有由堆分配的资源才存在所有权如字符串
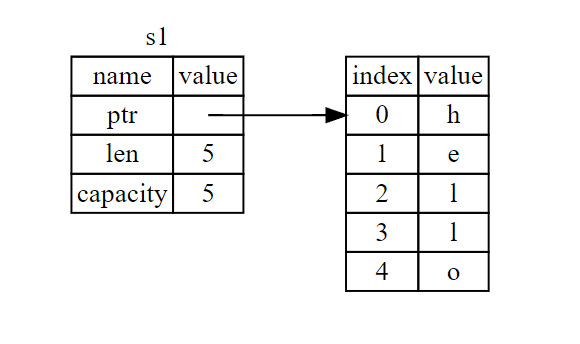
引用传递
这些 & 符号就是 引用,它们允许你使用值但不获取其所有权,就是让这个变量指向另一个变量
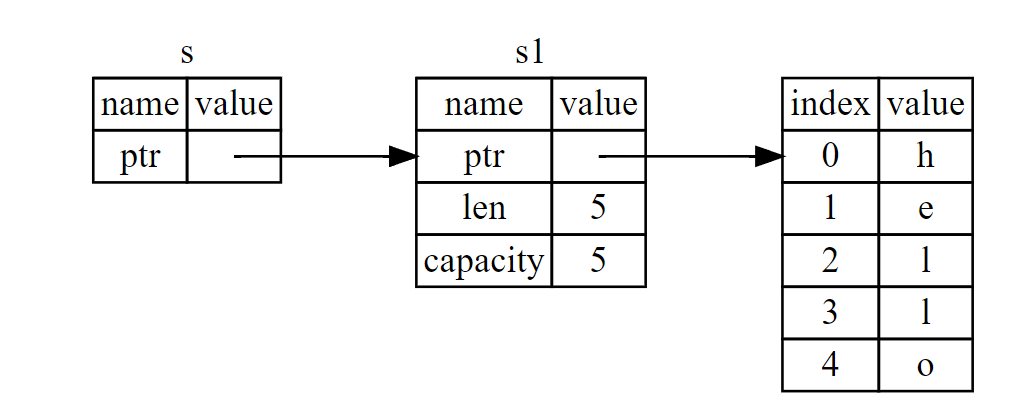
把一个变量赋值给另一个变量 fn main() { // 栈分配的整型 let a = 88; // 将 `a` *复制*到 `b`——不存在资源移动,资源就存在栈上不需要移动 let b = a; // 两个值各自都可以使用 println!("a {}, and b {}", a, b); let v1 = vec!["aaa","bbb","ccc"]; let v2 =v1; // println!("{:?}",v1);会出错因为字符串的内存资源分配由堆分配,资源不移动让所有权移动,v1的所有权被转移到了v2上,再次使用v1会出错 } 把变量传递给函数参数 fn show(v:Vec<&str>){ println!("v {:?}",v) } fn main() { let studyList = vec!["aaaa","bbbb","cccc"]; //studyList 拥有堆上数据管理权 let studyList2 = studyList; // studyList 将所有权转义给了 studyList2 show(studyList2); // studyList2 将所有权转让给参数 v,studyList2 不再可用。 println!("studyList2 {:?}",studyList2); //studyList2 已经不可用。 } 函数中的返回值 fn show2(v:Vec<&str>) -> Vec<&str>{ println!("v {:?}",v); return v; } fn main() { let studyList3 = vec!["aaaa","bbbb","ccc"]; let studyList4 = studyList3; let result = show2(studyList4); println!("result {:?}",result);//不会报错所有权已从函数形参转到result变量 } 注: 基础数据类型与所有权:所有权只会发生在堆上分配的数据,基础数据类型(整型,浮点型,布尔,字符)存储在栈上,所以没有所有权的概念。基础类型可以认为是值拷贝,在内存上另外的地方,存储和复制来的数据,然后让新的变量指向它,赋值并不是唯一涉及移动的操作。值在作为参数传递或从函数返回时也会被移动:
借用:Rust 中,Borrowing(借用),就是一个函数中的变量传递给另外一个函数作为参数暂时使用。也会要求函数参数离开自己作用域的时候将所有权 还给当初传递给它的变量(好借好还,再借不难嘛!)。
//&变量名 //要把参数定义的时候这样定义。 fn show(v:&Vec<&str>){ println!("v:{:?}",v) } fn main() { let studyList = vec!["aaaa","bbbb","cccc"]; let studyList2 =studyList; show2(&studyList2); println!("studyList2:{:?}",studyList2); //我们看到,函数show使用完v2后,我们仍然可以继续使用 }
//可变的借用: //如果我们要在Borrowing(借用)的时候改变其中的值: //1.变量要用mut关键字。 //2.函数参数为可变的要用 &mut 关键字。 //3.传递参数的时候,也要用 &mut 关键字 fn show2(v:&mut Vec<&str>){ v[0]="第一个充电项目已完成"; println!("v:{:?}",v) } fn main() { let mut studyList3 = vec!["aaaa","bbbb","cccc"]; println!("studyList3:{:?}",studyList3); show2(&mut studyList3); println!("调用后,studyList3:{:?}",studyList3);//不会出错并且被gai'b }
// 切片是只向一段连续内存的指针。在 Rust 中,连续内存够区间存储的数据结构:数组(array)、字符串(string)、向量(vector)。切片可以和它们一起使用,切片也使用数字索引访问数据。下标索引从0开始。slice 可以指向数组的一部分,越界的下标会引发致命错误(panic)。 // 切片是运行时才能确定的,并不像数组那样编译时就已经确定了。 // [起始位置..结束位置],这是一个左闭右开的区间。 // 起始位置最小值是0。 // 结束位置是数组、向量、字符串的长度。 fn show_slice(s:&[&str]){ println!("show_slice函数内:{:?}",s); } fn modify_slice(s: &mut [&str]) { s[0] = "这个阶段已学习完毕"; println!("modify_slice:{:?}", s); } fn main() { let mut v = Vec::new(); v.push("aaaa"); v.push("bbbb"); v.push("cccc"); println!("len:{:?}",v.len()); let s1=&v[1..3]; println!("s1:{:?}",s1); let s2=&v[1..2];//左开右闭 println!("s2:{:?}",s2); show_slice(s2); //println!("调用前s3:{:?}",v); //let s3=&mut v[1..2]; //modify_slice( s3); //println!("调用后s3:{:?}",v); println!("调用前s3:{:?}",v); modify_slice(&mut v[1..2]);//函数调用 println!("调用后s3:{:?}",v); }
#[derive(Debug)]
struct Study {
name: String,
target: String,
spend: i32,
}//定义一个结构体
impl Study {
fn get_spend(&self) -> i32 {//self 是“自己”的意思,&self 表示当前结构体的实例。 &self 也是结构体普通方法固定的第一个参数
return self.spend;
}
fn get_spend2(name:String,target:String,spend:i32) ->Study {//静态方法可全局使用,不能有自身实例
return Study {
name,
target,
spend,
};
}
}//结构体方法
fn get_instance(name: String, target: String, spend: i32) -> Study {
return Study {
name,
target,
spend,
};
}//结构体作为返回值
fn main() {
let s = Study {//实例化一个结构体
name: String::from("abc"),
target: String::from("aaaaaa"),
spend: 3,
};
println!("{:?}", s);//访问实例
println!("{}",s.name);//访问实例属性
let mut s2 = Study {//实例化一个可修改结构体
name: String::from("abc"),
target: String::from("aaaaaa"),
spend: 3,
};
s2.spend=7;//修改结构体实例
println!("{}",s2.spend);
let s3=get_instance("1".to_string(),"2".to_string(),3);//结构体作为形参
println!("{:?}", s3);//访问实例
println!("{}",s3.get_spend());//调用实例方法
let s4=Study::get_spend2(String::from("111"),String::from("222"),333);//调用静态方法
println!("{:?}", s4);//访问实例
let pair =(String::from("111"),1);//实例化一个元组结构体
println!("pair:{:?},{}",pair.0,pair.1);//使用println!("{:?}")可以打印数据类型。
let(num1,num2) = pair;//解构元组结构体
println!("num1:{:?},num2:{:?}",num1,num2);
}#[derive(Debug)]//#[derive(Debug)] 注解的作用,就是让 派生自Debug`。
enum RoadMap {
一,
二,
三,
}
fn print_RoadMap(r: RoadMap){//判断一个枚举变量的值,唯一操作符就是 match。
match r{
RoadMap::一 => println!("RoadMap::一"),
RoadMap::二 => println!("RoadMap::二"),
RoadMap::三 => println!("RoadMap::三"),
}
}
#[derive(Debug)]
enum StudyRoadMap{
Name(String),
}//带数据类型枚举
// enum Option<T> {
// Some(T), // 用于返回一个值
// None // 用于返回 null,用None来代替。
// }
// Option 枚举经常用在函数中的返回值,它可以表示有返回值,也可以用于表示没有返回值。如果有返回值。
// 可以使用返回 Some(data),如果函数没有返回值,可以返回 None。
fn getDiscount(price: i32) -> Option<bool> {
if price > 100 {
Some(true)
} else {
None
}
}
fn main() {
let level = RoadMap::一;
println!("level---{:?}",level);
let a=100;
println!("{:?}",getDiscount(a));
print_RoadMap(RoadMap::一);
let level2 = StudyRoadMap::Name(String::from("aaaaa"));
match level2 {
StudyRoadMap::Name(val)=>{
println!("{:?}",val);
}
}
}1.向量的使用方法
| 方法 | 说明 |
|---|---|
| new() | 创建一个空的向量的实例 |
| push() | 将某个值 T 添加到向量的末尾 |
| remove() | 删除并返回指定的下标元素。 |
| contains() | 判断向量是否包含某个值 |
| len() | 返回向量中的元素个数 |
Rust 在标准库中定义了结构体 Vec 用于表示一个向量。向量和数组很相似,只是数组长度是编译时就确定了,定义后就不能改变了,那要么改数组,让他支持可变长度,显然 Rust 没有这么做,它用向量这个数据结构,也是在内存中开辟一段连续的内存空间来存储元素。
特点:
-
向量中的元素都是相同类型元素的集合。
-
长度可变,运行时可以增加和减少。
-
使用索引查找元素。(索引从 0 开始)
-
添加元素时,添加到向量尾部。
-
向量的内存在堆上,长度可动态变化。
let mut v = Vec::new();//调用 Vec 结构的 new() 静态方法来创建向量。 v.push("aaaa"); //通过push方法添加元素数据。并且追加到向量尾部 println!("len :{}",v.len()); // 通过len方法获取向量中的元素个数。 let mut v2 = vec!["aa","bb","cc"]; // 通过vect!宏创建向量时,向量的数据类型由第一个元素自动推断出来。 println!("{:?}",v2); let x=v2.remove(0); // remove()方法移除并返回向量中指定的下标索引处的元素,将其后面的所有元素移到向左移动一位。 //contains() 用于判断向量是否包含某个值。如果值在向量中存在则返回 true,否则返回 false。 if v.contains(&"aa"){ println!("找到了") } //访问向量中的某个元素,使用索引 let y = v[0]; println!("{}",y); //遍历向量 for item in v { println!("输出: {}", item); }
2.HashMap
HashMap 就是键值对集合。键是不能重复的,值是可以重复的。
使用
HashMap结构体之前需要显式导入std::collections模块。方法 说明 insert() 插入/更新一个键值对到哈希表中,如果数据已经存在则返回旧值,如果不存在则返回 None len() 返回哈希表中键值对的个数 get() 根据键从哈希表中获取相应的值 iter() 返回哈希表键值对的无序迭代器,迭代器元素类型为 (&’a K, &’a V) contains_key 如果哈希表中存在指定的键则返回 true 否则返回 false remove() 从哈希表中删除并返回指定的键值对
use std::collections::HashMap;
let mut process = HashMap::new();//这个哈希表只有当我们添加了元素之后才能正常使用。因为现在还没指定的数据类型
process.insert("aaaa", 1);
process.insert("bbbb", 2);
println!("{:?}", process);
// get() 方法用于根据键从哈希表中获取相应的值。
match process.get(&"aaaa"){
Some(v)=>{
println!("HashMap v:{}", v);
}
None=>{
println!("找不到");
}
}
//迭代哈希表 iter()
for (k, v) in process.iter() {
println!("k: {} v: {}", k, v);
}
// contains_key() 方法用于判断哈希表中是否包含指定的 键值对。如果包含指定的键,那么会返回相应的值的引用,否则返回 None。
if process.contains_key(&"aaaa") {
println!("找到了");
}
// remove() 用于从哈希表中删除指定的键值对。如果键值对存在则返回删除的键值对,返回的数据格式为 (&'a K, &'a V)。如果键值对不存在则返回 None
let x=process.remove(&"bbbb");
println!("{:?}",x);
println!("{:?}",process);3.HashSet
Hashset 是相同数据类型的集合,它是没有重复值的。如果集合中已经存在相同的值,则会插入失败。
常用方法如下
| 方法 | 描述 |
|---|---|
| insert() | 插入一个值到集合中 如果集合已经存在值则插入失败 |
| len() | 返回集合中的元素个数 |
| get() | 根据指定的值获取集合中相应值的一个引用 |
| iter() | 返回集合中所有元素组成的无序迭代器 迭代器元素的类型为 &'a T |
| contains_key | 判断集合是否包含指定的值 |
| remove() | 从结合中删除指定的值 |
let mut studySet = HashSet::new();
studySet.insert("aaaa);泛型是运行时指定数据类型的一种机制。好处是通过高度的抽象,使用一套代码应用多种数据类型。比如我们的向量,可以使用数值类型,也可以使用字符串类型。泛型是可以保证数据安全和类型安全的,还同时减少代码量。
Rust 语言中的泛型主要包含 泛型集合、泛型结构体、泛型函数、范型枚举 和 特质 。
Rust 使用使用 <T> 语法来实现泛型, 其中 T 可以是任意数据类型。
//泛型集合
let mut v:Vec<i32> =vec![1,2,3];
v.push("4");//此处会报错 ^^^ expected `i32`, found `&str`
//泛型结构体
//struct 结构体名称<T> {
// 元素:T,
//}
struct Data<T> {
value:T,
}
fn main() {
let t:Data<i32> = Data{value:100};
println!("值:{} ",t.value);//输出 值:100
let t:Data<f64> = Data{value:66.00};
println!("值:{} ",t.value);//输出 值:66
}
//特质 Trait
//可以把这个特质(traits)对标其他语言的接口,都是对行为的抽象。使用 trait关键字用来定义。特质,可以包含具体的方法,也可以包含抽象的方法
trait some_trait {//类似java抽象方法
// 没有任何实现的虚方法
fn method1(&self);
// 有具体实现的普通方法
fn method2(&self){
//方法的具体代码
}
}
//实现特质
//Rust 使用 impl for 为每个结构体实现某个特质。impl 是 implement 的缩写。
struct Book {
name: String,
id: u32,
author: String,
}
trait ShowBook {
fn Show(&self);
}
impl ShowBook for Book{
fn Show(&self) {
println!("Id:{},Name:{},Author:{}",self.id,self.name,self.author);
}
}
fn main() {
let book = Book{
id:1,
name: String::from("aaaa"),
author: String::from("bbbb")
};
book.Show();//输出 Id:1,Name:aaaa,Author:bbbb
}
//泛型函数
//主要是指参数是泛型类型,不要求所有参数都必须是泛型参数,可以是某一个参数是泛型类型。
//fn 方法名<T[:特质名称]>(参数1:T, ...) {
// 函数实现代码
//}
fn largest<T: std::cmp::PartialOrd>(a: T, b: T) -> T {
if a > b {
a
} else {
b
}
}
fn main() {
println!("{}", largest::<u32>(1, 2));
println!("{}", largest::<f32>(1.0, 2.1));
}fn main() {
// let mut in_word = String::new();
// let result = std::io::stdin().read_line(&mut in_word).unwrap();
// println!("您的输入是: {}", in_word);
// println!("读取的字节数为: {}", result);
// std::io::stdin() 返回标准输入流 stdin 的句柄。read_line() 是标准入流 stdin 的句柄上的一个方法,从标准输入流读取一行的数据。返回值是一个 Result 枚举,而 unwrap() 则是一个帮助方法,用于简化可恢复错误的处理。它会返回 Result 中存储的实际值。read_line() 方法会自动删除行尾的换行符 \n
// let result1 = std::io::stdout().write("aaaa".as_bytes()).unwrap();
// println!("写入的字节数为: {}\n", result1);
// let result2 = std::io::stdout().write("www".as_bytes()).unwrap();
// println!("写入的字节数为: {}\n", result2);
// std::io::stdout() 会返回标准输出流 stdout 的句柄。
// write() 是标准输出流 stdout 的句柄上的一个方法,用于向标准输出流写入字节流内容。
// write() 方法的返回值值一个 Result 枚举,而 unwrap() 则是一个帮助方法,用于简化可恢复错误的处理。它会返回 Result 中存储的实际值。
// write() 方法并不会输出结束时自动追加换行符 \n。如果需要换行符则需要手动添加
let input_args = std::env::args();
for arg in input_args{
println!("命令行参数:[{}]",arg);
}
//cargo build 生成二进制文件
//进入target/debug目录
// ./hello_cargo 123 123 2344 556 656
// 命令行参数:[./hello_cargo]
// 命令行参数:[123]
// 命令行参数:[123]
}Rust 语言使用结构体 File 来描述/展现一个文件。
所有对结构体 File 的操作方法都会返回一个 Result 枚举。
以下是一些常用的文件方法
| 模块 | 方法 | 说明 |
|---|---|---|
| std::fs::File | open() | 静态方法,以 只读 模式打开文件 |
| std::fs::File | create() | 静态方法,以 可写 模式打开文件。 如果文件存在则清空旧内容 如果文件不存在则新建 |
| std::fs::remove_file | remove_file() | 从文件系统中删除某个文件 |
| std::fs::OpenOptions | append() | 设置文件模式为 追加 |
| std::io::Writes | write_all() | 将 buf 中的所有内容写入输出流 |
| std::io::Read | read_to_string() | 读取所有内容转换为字符串后追加到 buf 中 |
//打开文件
let file = std::fs::File::open("data.txt").unwrap();//模块提供了静态方法 open() 用于打开一个文件并返回文件句柄。
println!("文件打开成功\n:{:?}",file);
//创建文件
let file = std::fs::File::create("data2.txt").expect("创建失败");
println!("文件创建成功:{:?}",file);
//删除文件
fs::remove_file("data.txt").expect("无法删除文件");
println!("文件已删除");
//追加内容
let mut file = OpenOptions::new().append(true).open("data2.txt").expect("失败");
file.write("dsvddf".as_bytes()).expect("写入失败");
println!("\n数据追加成功");
//写入所有内容
file.write_all("Rust".as_bytes()).expect("创建失败");
file.write_all("\nRust".as_bytes()).expect("创建失败");
println!("数据已写入完毕");
//注意: write_all() 方法并不会在写入结束后自动写入换行符 \n。
//读取内容
let mut file = std::fs::File::open("data2.txt").unwrap();
let mut contents = String::new();
file.read_to_string(&mut contents).unwrap();
print!("{}", contents);迭代器 就是把集合中的所有元素按照顺序一个接一个的传递给处理逻辑。
Iterator 特质有两个函数:
-
一个是
iter(),用于返回一个 迭代器 对象,也称之为 项 ( items ) 。 -
一个是
next(),用于返回迭代器中的下一个元素。如果已经迭代到集合的末尾(最后一个项后面)则返回None。方法 描述 iter()返回一个只读可重入迭代器,迭代器元素的类型为 &Tinto_iter()返回一个只读不可重入迭代器,迭代器元素的类型为 Titer_mut()返回一个可修改可重入迭代器,迭代器元素的类型为 &mut T
fn main() {
let v = vec!["aaa", "vbbb", "vvvv"];
let mut it = v.iter();
println!("{:?}",it.next());
println!("{:?}",it.next());
println!("{:?}",it.next());
println!("{:?}",it.next());
let iter = v.iter();
for item in iter{
print!("{}\n",item);
}
}Rust 中的闭包(closure),也叫做 lambda 表达式或者 lambda,是一类能够捕获周围作用域中变量的函数。
调用一个闭包和调用一个函数完全相同,不过调用闭包时,输入和返回类型两者都可以自动推导,而输入变量名必须指明。
其他的特点包括:
-
声明时使用 || 替代 () 将输入参数括起来。
-
函数体定界符({})对于单个表达式是可选的,其他情况必须加上。
-
有能力捕获外部环境的变量。
定义闭包
普通函数 fn 函数名(参数列表) -> 返回值 { // 业务逻辑 } // 闭包 |参数列表| { // 业务逻辑 } // 无参数闭包 || { // 业务逻辑 }
从上面看,去掉了 fn,去掉了函数名,把参数用 2 个竖线。
包也可以赋值给一个变量,可以通过调用这个变量来完成闭包的调用。
let 闭包变量 = |参数列表| {
// 闭包的具体逻辑
}fn main(){
let double = |x| { x * 2 };
let add = |a, b| { a + b };
let x = add(2, 4);
println!("{}", x);
let y = double(5);
println!("{}", y);
let v = 3;
let add2 = |x| { v + x };
println!("{}", add2(4));
}捕获:
闭包本质上很灵活,闭包可以在没有类型标注的情况下运行。可移动(move),又可借用(borrow)。闭包可以通过以下方式捕获变量:
- 通过引用:&T
- 通过可变引用:&mut T
- 通过值:T
总结:
-
闭包就是在一个函数内创建立即调用的另一个函数。
-
闭包是一个匿名函数。
-
闭包虽然没有函数名,但可以把整个闭包赋值一个变量,通过调用该变量来完成闭包的调用。
-
闭包不用声明返回值,但它却可以有返回值。并且使用最后一条语句的执行结果作为返回值。闭包的返回值可以赋值给变量。
-
闭包又称之为 内联函数。可以让闭包访问外层函数里的变量。
- 现代的操作系统,是一个多任务操作系统,系统可以管理多个程序的运行,一个程序往往有一个或多个进程,而一个进程则有一个或多个线程。
- 让一个进程可以运行多个线程的机制叫做多线程。
- 一个进程一定有一个主线程,主线程之外创建出来的线程叫 子线程
多线程(并发)编程的一个重要思想就是 程序不同的部分可以同时独立运行互不干扰。
use std::time::Duration; use std::thread; fn main() { //方法:std::thread::spawn() //spawn() 函数的原型 //pub fn spawn<F, T>(f: F) -> JoinHandle<T> //参数 f 是一个闭包(closure ) 是线程要执行的代码。 // 子线程 // thread::spawn(|| { // for i in 1..10 { // println!("子线程 {}", i); // thread::sleep(Duration::from_millis(1)); // } // }); // // 主线程 // for i in 1..5 { // println!("主线程 {}", i); // thread::sleep(Duration::from_millis(1)); // } //当主线程执行结束,子线程就自动结束。 //thread::sleep() 会让线程睡眠一段时间,某个线程睡眠的时候会让出 CPU,可以让不同的线程交替执行,要看操作系统如何调度线程。 //上面的例子主线程结束后,子线程还没有运行完,但是子线程也结束了。如果想让子线程结束后,主线程再结束,我们就要使用Join 方法,把子线程加入主线程等待队列。 //spawn<F, T>(f: F) -> JoinHandle<T> //子线程 let handler = thread::spawn(|| { for i in 1..10 { println!("子线程 {}", i); thread::sleep(Duration::from_millis(1)); } }); // 主线程 for i in 1..5 { println!("主线程 {}", i); thread::sleep(Duration::from_millis(1)); } handler.join().unwrap(); }
Rust 语言也有错误这个概念,而且把错误分为两大类:可恢复 和 不可恢复,相当于其它语言的 异常 和 错误。
| Name | 描述 |
|---|---|
| Recoverable | 可以被捕捉,相当于其它语言的异常 Exception |
| UnRecoverable | 不可捕捉,会导致程序崩溃退出 |
panic!() 不可恢复错误
panic!() 程序立即退出,退出时调用者抛出退出原因。
一般情况下,当遇到不可恢复错误时,程序会自动调用 panic!()。
fn is_even(no:i32)->Result<bool,String> {
return if no % 2 == 0 {
Ok(true)
} else {
Err("输入值,不是偶数".to_string())
}
}
fn main() {
// panic!("出错啦");
// println!("Hello Rust"); // 不可能执行的语句
// Result 枚举和可恢复错误
// enum Result<T,E> {
// OK(T),
// Err(E)
// }
// OK(T) T OK 时作为正常返回的值的数据类型。
// Err(E) E Err 时作为错误返回的错误的类型。
// let f = File::open("abc.jpg"); //文件不存在,因此值为 Result.Err
// println!("{:?}",f);
// let result = is_even(11).unwrap();
// println!("结果 {}",result);
let f = File::open("abc.txt").expect("无法打开该文件"); // 文件不存在
//expect方法的作用和unwrap类似,区别在于,expect方法接受msg: &str作为参数,它在运行时的panic信息为format!("{}: {}", msg, error),使用expect时,可以自定义报错信息,因此出现panic时比较容易定位。
}Rust 可以在 堆 上存储数据。Rust 语言中的某些类型,如 向量 Vector 和 字符串对象 String 默认就是把数据存储在 堆 上的。
Rust 语言把指针封装在如下两个特质Trait中。
| 特质名 | 包 | Description |
|---|---|---|
| Deref | std::ops::Deref | 用于创建一个只读智能指针,例如 *v |
| Drop | std::ops::Drop | 智能指针超出它的作用域范围时会回调该特质的 drop() 方法。 类似于其它语言的 析构函数。 |
当一个结构体实现了以上的接口后,它们就不再是普通的结构体了。
Rust 提供了在 堆 上存储数据的能力并把这个能力封装到了 Box 中。
这种把 栈 上数据搬到 堆 上的能力,我们称之为 装箱。
box指针:
//Box 指针可以把数据存储在堆(heap)上,而不是栈(stack)上。这就是装箱(box),栈(stack)还是包含指向 堆(heap) 上数据的指针。
fn main() {
let a = 6; // 默认保存在 栈 上
let b = Box::new(a); // 使用 Box 后数据会存储在堆上
println!("b = {}", b);// 输出 b = 6
}
//访问 Box 存储的数据
//如果想访问 Box 存储的数据,可以使用 星号 *访问,这个操作叫做 解引用。 星号 *也叫 解引用符。
let price1 = 158; // 值类型数据
let price2 = Box::new(price1); // price2 是一个智能指针,指向堆上存储的数据 158
println!("{}",158==price1);
println!("{}",158==*price2); // 为了访问 price2 存储的具体数据,需要解引用
//输出
//true
//true
//158==price1,是基础类型的比较只是比较值是否相等,所以返回 true。
//158==*price2,price2 是一个智能指针,是引用类型,想访问到具体的值,就要对 price2 进行解引用的操作。
Deref特质:
实现 Deref 特质需要我们实现 deref() 方法。deref() 方法返回一个指向结构体内部数据的指针。
use std::ops::Deref;
struct CustomBox<T>{
value: T
}
impl<T> CustomBox<T> {
fn new(v:T)-> CustomBox<T> {
CustomBox{value:v}
}
}
impl<T> Deref for CustomBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.value
}
}
fn main() {
let x = 666;
let y = CustomBox::new(x); // 调用静态方法 new() 返回创建一个结构体实例
println!("666==x is {}",666==x);//true
println!("666==*y is {})",666==*y; // 解引用 y true
println!("x==*y is {}",x==*y); // 解引用 y true
}drop特质:
Drop Trait 只有一个方法 drop()。当实现了 Drop Trait 的结构体,在超出了它的作用域范围时会触发调用 drop() 方法。
struct CustomBox<T>{
value: T
}
impl<T> CustomBox<T> {
fn new(v:T)-> CustomBox<T> {
CustomBox{value:v}
}
}
// impl<T> Deref for CustomBox<T> {
// type Target = T;
// fn deref(&self) -> &T {
// &self.value
// }
// }
impl<T> Drop for CustomBox<T>{
fn drop(&mut self){
println!("drop CustomBox 对象!");
}
}
fn main() {
let x = 666;
let y = CustomBox::new(x); // 调用静态方法 new() 返回创建一个结构体实例
// println!("666==x is {}",666==x);//true
// println!("666==*y is {})",666==*y; // 解引用 y true
// println!("x==*y is {}",x==*y); // 解引用 y true
}
//输出drop CustomBox 对象!Rust 内置了一个包管理器 cargo和 Rust 自带安装的,它也可以管理项目。
cargo --version//查看 cargo 版本
cargo --list//查看 Cargo 命令列表Cargo 提供的命令,常用的如下:
| 命令 | 说明 |
|---|---|
cargo new |
在当前目录下新建一个 cargo 项目 |
cargo check |
分析当前项目并报告项目中的错误,但不会编译任何项目文件 |
cargo build |
编译当前项目 |
cargo run |
编译并运行文件 src/main.rs |
cargo clean |
移除当前项目下的 target 目录及目录中的所有子目录和文件 |
cargo update |
更新当前项目中的 Cargo.lock 文件列出的所有依赖 |
我们常说 功能模块,就是用于将函数或结构体按照功能分组。也常常把相似的函数或者实现相同功能的或者共同实现一个功能的函数和结构体划分到一个模块中。
Rust 中的模块,类似 C++ 中的命名空间,Java 语言中的包。
在代码组织上,比模块更高级的是 crate ,一个crate 可以存放多个模块,在 Rust 语言中crate 是基本编译单元,分为 可执行二进制文件(包含 main 函数作为程序入口) 或者 一个库。
crates.io 是 Rust 官方提供的第三方包的地址。可以使用 cargo install 命令从 crates.io 上下载你所需要的 crate。
//定义模块
mod module_name {
fn function_name() {
// 具体的函数逻辑
}
}-
module_name 要是一个合法的名称。
-
Rust 语言中的模块默认是私有的。
-
如果一个模块或者模块内的函数需要导出为外部使用,则需要添加
pub关键字。 -
私有的模块不能为外部其它模块或程序所调用。
-
私有模块的所有函数都必须是私有的,而公开的模块,则即可以有公开的函数也可以有私有的函数。
//公开的模块 pub mod public_module { pub fn public_function() { // 公开的方法 } fn private_function() { // 私有的方法 } } //私有的模块 mod private_module { // 私有的方法 fn private_function() { } }
use关键字
use 公开的模块名::函数名;在根目录下,执行 cargo new –lib mylib,创建类库。
pub mod add_salary {
pub fn study(name:String) {
println!("34535{}",name);
}
}
第一步 进入 mylib目录执行cargo build
第二步 打开根目录 Cargo.toml
[dependencies]
mylib={ path="../module_demo/mylib" }
第三步 在main.rs中修改
use mylib::add_salary::study;
fn main(){
study("ghfgh".to_string());
}
use AddSalary::study;
fn main() {
study("fnhfh".to_string());
}Rust 允许一个模块中嵌套另一个模块,换种说法,就是允许多层级模块。
pub mod mod1 {
pub mod mod2 {
pub mod mod3 {
pub fn 方法名(参数) {
//代码逻辑
}
}
}
}调用或使用嵌套模块的方法使用两个冒号 (::) 从左到右拼接从外到内的模块即可
use mod1::mod2::mod3::方法名;fn main() { 方法名();}变量绑定默认是不可变的(immutable),但加上 mut 修饰语后变量就可以改变
作用域和遮蔽
变量绑定有一个作用域(scope),它被限定只在一个代码块(block)中生存(live)。 代码块是一个被 {} 包围的语句集合。另外也允许变量遮蔽(variable shadowing)。
// 此绑定生存于 main 函数中
let spend = 1;
// 这是一个代码块,比 main 函数拥有更小的作用域
{
// 此绑定只存在于本代码块
let target = "adaf";
println!("inner short: {}", target);
// 此绑定*遮蔽*了外面的绑定
let spend = 2.0;
println!("inner long: {}", spend);
}
// 代码块结束
// 报错!`target` 在此作用域上不存在
// error[E0425]: cannot find value `target` in this scope
println!("outer short: {}", target);
println!("outer long: {}", spend);
// 此绑定同样*遮蔽*了前面的绑定
let spend = String::from("asdad");
println!("outer spend: {}", spend);可以先声明(declare)变量绑定,后面才将它们初始化(initialize)。但是这种做法很 少用,因为这样可能导致使用未初始化的变量。 编译器禁止使用未经初始化的变量,因为这会产生未定义行为(undefined behavior)。
// 声明一个变量绑定
let spend;
{
let x = 2;
// 初始化一个绑定
spend = x * x;
}
println!("spend: {}", spend);
let spend2;
// 报错!使用了未初始化的绑定
println!("spend2: {}", spend2);
// 改正 ^ 注释掉此行
spend2 = 1;
println!("another binding: {}", spend2);资源存在使用的引用时,在当前作用域中这一资源是不可被修改的,称之为“冻结”。
let mut spend4 = Box::new(1);
let spend5 = &spend4;
spend4= Box::new(100);
println!("{}", spend4);
println!("{}", spend5);
报错如下
let spend5 = &spend4;
------- borrow of `spend4` occurs here
spend4= Box::new(100);
^^^^^^ assignment to borrowed `spend4` occurs here
println!("{}", spend4);
println!("{}", spend5);
------ borrow later used hereRust 不提供原生类型之间的隐式类型转换,但可以使用 as 关键字进行显式类型转换。 整型之间的转换大体遵循 C 语言的惯例,除了 C 会产生未定义行为的情形。在 Rust 中所 有整型转换都是定义良好的。
PLAINTEXT
let spend = 1;
// 错误!不提供隐式转换
// error[E0308]: mismatched types
// let cost: f64 = spend;
// 可以显式转换
let cost = spend as f64;
println!("转换: {} -> {}", spend, cost);对数值字面量,只要把类型作为后缀加上去,就完成了类型说明。比如指定字面量 42 的 类型是 i32,只需要写 42i32。
无后缀的数值字面量,其类型取决于怎样使用它们。如果没有限制,编译器会对整数使用 i32,对浮点数使用 f64。
PLAINTEXT
// 带后缀的字面量,其类型在初始化时已经知道了。
let x = 1u8;
let y = 2u32;
let z = 3f32;
// 无后缀的字面量,其类型取决于如何使用它们。
let i = 1;
let f = 1.0;Rust 的类型推断引擎是很聪明的,它不只是在初始化时看看右值(r-value)的 类型而已,它还会考察变量之后会怎样使用,借此推断类型。
PLAINTEXT
// 因为有类型说明,编译器知道类型是 u8。
let study = String::from("asffa");
// 创建一个空向量(vector,即不定长的,可以增长的数组)。
let mut vec = Vec::new();
// 现在编译器还不知道 `vec` 的具体类型,只知道它是某种东西构成的向量(`Vec<?>`)
// 在向量中插入元素。
vec.push(study);
// 现在编译器知道 `vec` 是 String 的向量了(`Vec<String>`)。
println!("{:?}", vec);可以用 type 语句给已有的类型取个新的名字。类型的名字必须遵循驼峰命名法(像是 CamelCase 这样),否则编译器将给出警告。原生类型是例外,比如: usize、f32,等等。别名的主要用途是避免写出冗长的模板化代码。 type 新名字 = 原名字;
PLAINTEXT
type MyU64 = u64;
type OtherU64 = u64;
type ThirdU64 = u64;
fn main(){
let MyU64: MyU64 = 5 as ThirdU64;
let otherU64: OtherU64 = 2 as ThirdU64;
println!(
"{} MyU64 + {} OtherU64es = {} unit?",
MyU64,
otherU64,
MyU64 + otherU64
);
}注意类型别名并不能提供额外的类型安全,因为别名并不是新的类型。
Rust 使用 trait 解决类型之间的转换问题。最一般的转换会用到 From 和 Into 两个 trait。
From 和 Into 两个 trait 是内部相关联的,实际上这是它们实现的一部分。如果我们能够从类型 B 得到类型 A,那么很容易相信我们也能把类型 B 转换为类型 A。
From trait 允许一种类型定义 “怎么根据另一种类型生成自己”,因此它提供了一种类型转换的简单机制。在标准库中有无数 From 的实现,规定原生类型及其他常见类型的转换功能。
PLAINTEXT
let s1 = "从0到Go语言微服务架构师";
let s2 = String::from(s1);
#[derive(Debug)]
struct MyNumber {
num: i32,
}
impl From<i32> for MyNumber {
fn from(item: i32) -> Self {
MyNumber { num: item }
}
}
fn main() {
let my_number = MyNumber { num: 1 };
println!("{:?}", my_number);
}Into trait 就是把 From trait 倒过来而已。也就是说,如果你为你的类型实现了 From,那么同时你也就免费获得了 Into。 使用 Into trait 通常要求指明要转换到的类型,因为编译器大多数时候不能推断它。不过考虑到我们免费获得了 Into,这点代价不值一提。
PLAINTEXT
let spend = 3;
let my_spend: MyNumber = spend.into();
println!("{:?}", my_spend);经常需要把字符串转成数字。完成这项工作的标准手段是用 parse 函数。
只要对目标类型实现了 FromStr trait,就可以用 parse 把字符串转换成目标类型。 标准库中已经给无数种类型实现了 FromStr。如果要转换到用户定义类型,只要手动实现 FromStr 就行。
PLAINTEXT
let cost: i32 = "5".parse().unwrap();
println!("{}", cost);在一些场合下,用 match 匹配枚举类型并不优雅。 if let 在这样的场合要简洁得多,并且允许指明数种失败情形下的选项:
let s = Some("ddd");
let s1: Option<i32> = None;
let s2: Option<i32> = None;
// 如果 `let` 将 `s` 解构成 `Some(i)`,则执行语句块(`{}`)
if let Some(i) = s {
println!("已上车 {:?}!", i);
}
// 如果要指明失败情形,就使用 else:
if let Some(i) = s1 {
println!("Matched {:?}!", i);
} else {
// 解构失败。切换到失败情形。
println!("不匹配。");
};
// 提供另一种失败情况下的条件。
let flag = false;
if let Some(i) = s2 {
println!("Matched {:?}!", i);
// 解构失败。使用 `else if` 来判断是否满足上面提供的条件。
} else if flag {
println!("不匹配s2");
} else {
// 条件的值为 false。于是以下是默认的分支:
println!("默认分支");
};
输出
已上车 "ddd"
不匹配。
默认分支
```
//while let
// 将 `optional` 设为 `Option<i32>` 类型
let mut num = Some(0);
// 当 `let` 将 `optional` 解构成 `Some(i)` 时,就
// 执行语句块(`{}`)。否则就 `break`。
while let Some(i) = num {
if i > 9 {
println!("{},quit!",i);
num = None;
} else {
println!("`i` is `{:?}`. Try again.", i);
num = Some(i + 1);
}
}