앱과 독립적이기 때문에 데이터 구조를 변경하더라도 앱에 영향을 주지 않습니다. 또한 데이터의 정확성과 일관성을 유지합니다. 인가된 사용자만 접근 가능하도록 하여 보안을 유지 할 수 있습니다. 마지막으로 데이터 중복성 문제를 해결할 수 있습니다.
데이터베이스는 디스크 원판에서 헤더가 데이터의 위치로 이동해서 읽는데, 순차인경우 연속적으로 접근이 가능하지만, 랜덤인 경우 여러곳에서 읽어야 합니다. 랜덤의 경우 헤더가 많이 이동하게 되서 속도가 느립니다. 이때 index 를 만들어 원하는 랜덤 데이터를 순차데이터로 만들어 헤더를 조금 움직이게 만들어 성능을 높일 수 있습니다.
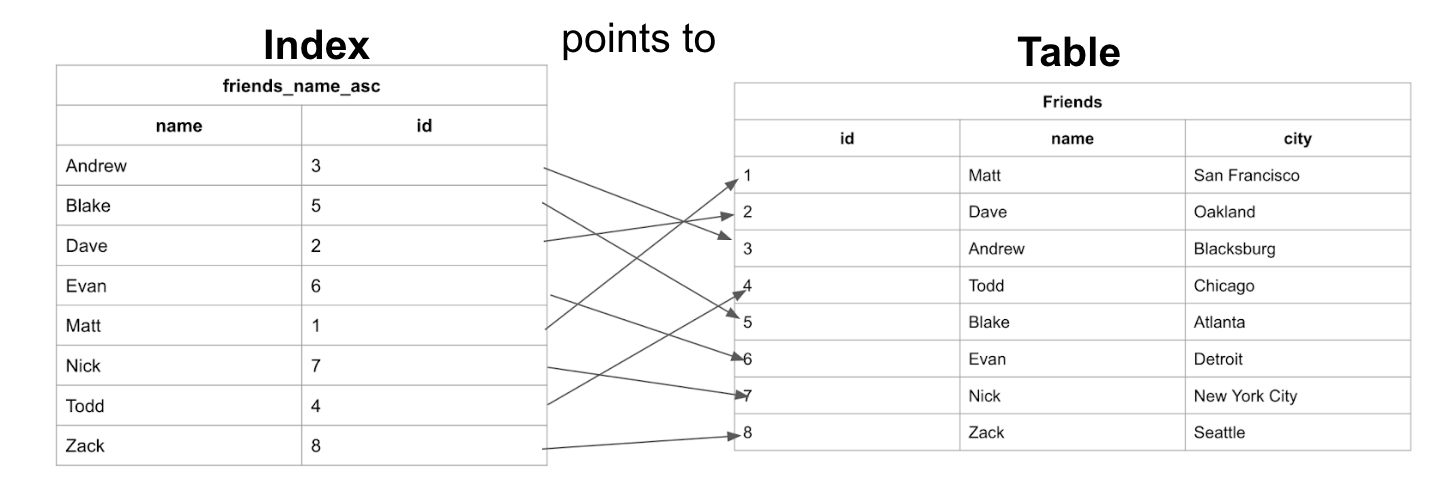
database indexing 은 데이터 베이스 내에서 저장된 위치에 대한 포인터를 만들어 열보다 빠르게 쿼리할 수 있는 방법입니다.
알파벳 순서대로 인덱스가 정렬되어있다면,
Zack의 경우 맨 마지막 쯤 찾을 수 있습니다. 이때, 알파벳 순으로 되어있는 것을 안다면, 이진탐색을 통해 접근 속도를 빠르게 확인할 수 있습니다.