给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {
public int val;
public List<Node> neighbors;
}
测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
示例 1:
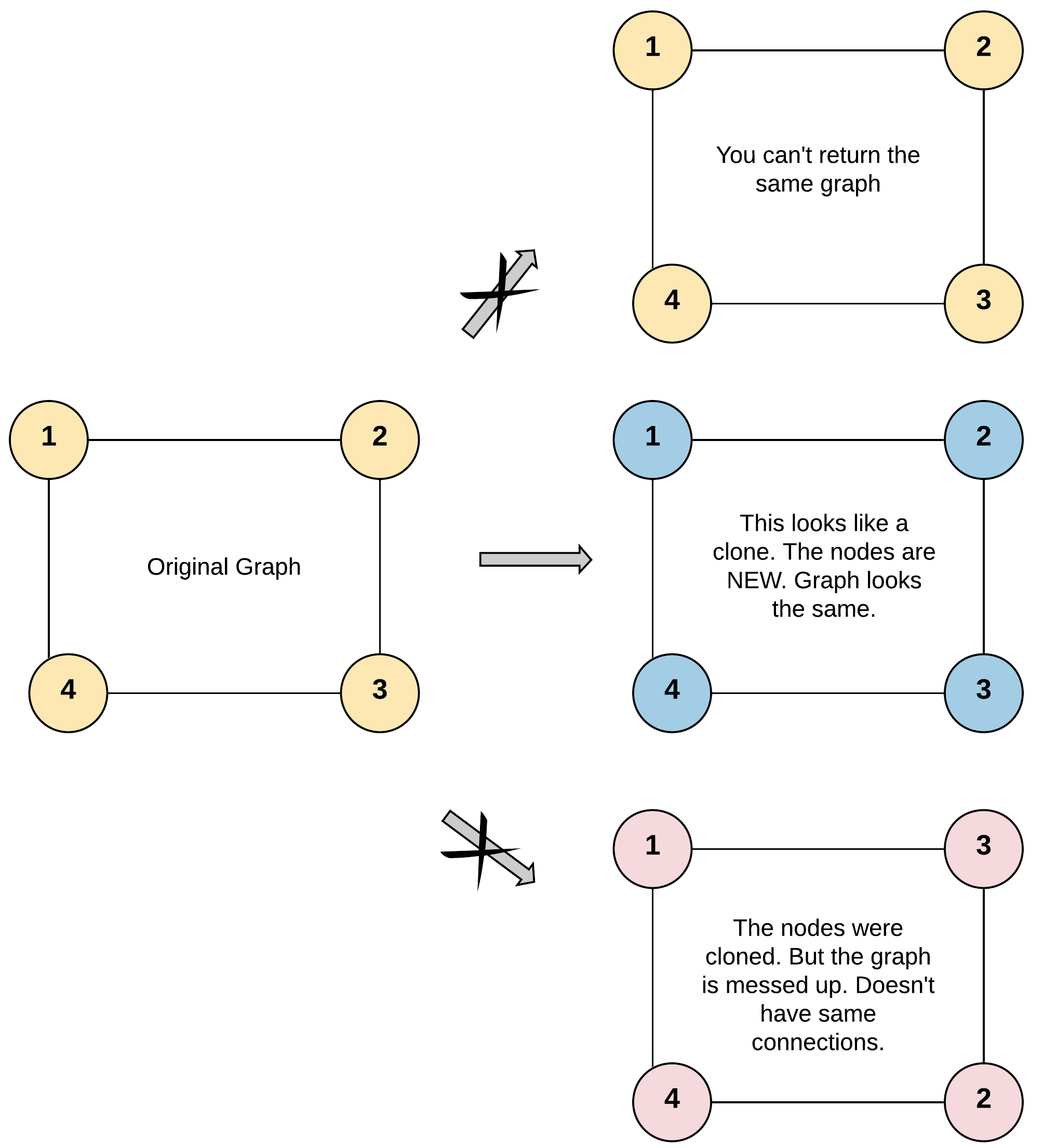
输入:adjList = [[2,4],[1,3],[2,4],[1,3]]
输出:[[2,4],[1,3],[2,4],[1,3]]
解释:
图中有 4 个节点。
节点 1 的值是 1,它有两个邻居:节点 2 和 4 。
节点 2 的值是 2,它有两个邻居:节点 1 和 3 。
节点 3 的值是 3,它有两个邻居:节点 2 和 4 。
节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
示例 2:
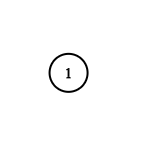
输入:adjList = [[]]
输出:[[]]
解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。
示例 3:
输入:adjList = []
输出:[]
解释:这个图是空的,它不含任何节点。
示例 4:
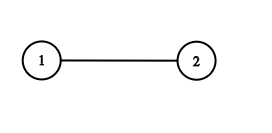
输入:adjList = [[2],[1]]
输出:[[2],[1]]
提示:
- 节点数不超过 100 。
- 每个节点值 Node.val 都是唯一的,1 <= Node.val <= 100。
- 无向图是一个简单图,这意味着图中没有重复的边,也没有自环。
- 由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。
- 图是连通图,你可以从给定节点访问到所有节点。
- 使用
visited记录节点是否访问过,而且缓存新节点的值,如果访问过,则visited中就有当前的key - 如果访问过的节点,就不需要重复生成节点,也不需要重复遍历
- 所以每次遍历节点的邻居,如果邻居没被访问过,则生成新节点,并且放入队列待访问,然后将其放入当前节点的邻居列表中
- 如果访问过,则直接放入邻居列表中,而不进行其他操作
/**
* // Definition for a Node.
* function Node(val, neighbors) {
* this.val = val === undefined ? 0 : val;
* this.neighbors = neighbors === undefined ? [] : neighbors;
* };
*/
/**
* @param {Node} node
* @return {Node}
*/
var cloneGraph = function(node) {
if(!node || !node.val){
return node
}
const queue = [], visited = [];
queue.push(node)
visited[node.val] = new Node(node.val)
while(queue.length){
const {val: curVal, neighbors} = queue.shift();
for(let nig of neighbors){
const {val: nigVal} = nig;
if(!Reflect.has(visited, nigVal)){
visited[nigVal] = new Node(nigVal);
queue.push(nig)
}
visited[curVal].neighbors.push(visited[nigVal]);
}
}
return visited[node.val]
};- 与思路一相同,只不过遍历顺序变成了深度优先,即使用递归实现
- 一层一层找邻居,每访问过一个邻居,就将这个邻居就存在
map中,然后再次访问的时候就返回缓存的节点
/**
* // Definition for a Node.
* function Node(val, neighbors) {
* this.val = val === undefined ? 0 : val;
* this.neighbors = neighbors === undefined ? [] : neighbors;
* };
*/
/**
* @param {Node} node
* @return {Node}
*/
var cloneGraph = function(node) {
return clone(node, new Map());
};
const clone = (node, visited) => {
if (!node) return null;
let newNode = visited.get(node);
if (newNode){
return newNode;
}
newNode = new Node(node.val);
visited.set(node, newNode);
node.neighbors.forEach(neighbor => {
newNode.neighbors.push(clone(neighbor, visited));
})
return newNode;
}- 主要是还深度或者广度遍历,然后使用
visited来进行缓存访问过的节点