We evaluate the full collection of available models on a suite of 38 datasets in a zero-shot setting (i.e., without fine-tuning), following Gadre et al., 2023. Click below to see the full results.
Below are details for several of our pretrained models.
LAION-400M - https://laion.ai/laion-400-open-dataset
We ran experiments in an attempt to reproduce OpenAI's ViT results with the comparably sized (and open) LAION-400M dataset. Trained weights can be found in release v0.2.
The LAION400M weights have been trained on the JUWELS supercomputer (see acknowledgements section below).
We replicate OpenAI's results on ViT-B/32, reaching a top-1 ImageNet-1k zero-shot accuracy of 62.96%.

Zero-shot comparison (courtesy of Andreas Fürst)

ViT-B/32 was trained with 128 A100 (40 GB) GPUs for ~36 hours, 4600 GPU-hours. The per-GPU batch size was 256 for a global batch size of 32768. 256 is much lower than it could have been (~320-384) due to being sized initially before moving to 'local' contrastive loss.
The B/16 LAION400M training reached a top-1 ImageNet-1k zero-shot validation score of 67.07.

This was the first major train session using the updated webdataset 0.2.x code. A bug was found that prevented shards from being shuffled properly between nodes/workers each epoch. This was fixed part way through training (epoch 26) but likely had an impact.
ViT-B/16 was trained with 176 A100 (40 GB) GPUS for ~61 hours, 10700 GPU-hours. Batch size per GPU was 192 for a global batch size of 33792.
The B/16+ 240x240 LAION400M training reached a top-1 ImageNet-1k zero-shot validation score of 69.21.
This model is the same depth as the B/16, but increases the
- vision width from 768 -> 896
- text width from 512 -> 640
- the resolution 224x224 -> 240x240 (196 -> 225 tokens)

Unlike the B/16 run above, this model was a clean run with no dataset shuffling issues.
ViT-B/16+ was trained with 224 A100 (40 GB) GPUS for ~61 hours, 13620 GPU-hours. Batch size per GPU was 160 for a global batch size of 35840.
The L/14 LAION-400M training reached a top-1 ImageNet-1k zero-shot validation score of 72.77.

ViT-L/14 was trained with 400 A100 (40 GB) GPUS for ~127 hours, 50800 GPU-hours. Batch size per GPU was 96 for a global batch size of 38400. Grad checkpointing was enabled.
A ~2B sample subset of LAION-5B with english captions (https://huggingface.co/datasets/laion/laion2B-en)
A ViT-B/32 trained on LAION-2B, reaching a top-1 ImageNet-1k zero-shot accuracy of 65.62%.

ViT-B/32 was trained with 112 A100 (40 GB) GPUs. The per-GPU batch size was 416 for a global batch size of 46592. Compute generously provided by stability.ai.
A second iteration of B/32 was trained on stability.ai cluster with a larger global batch size and learning rate, hitting 66.6% top-1. See https://huggingface.co/laion/CLIP-ViT-B-32-laion2B-s34B-b79K
A ViT-L/14 with a 75.3% top-1 ImageNet-1k zero-shot was trained on JUWELS Booster. See model details here https://huggingface.co/laion/CLIP-ViT-L-14-laion2B-s32B-b82K
These weights use a different dataset mean and std than others. Instead of using the OpenAI mean & std, inception style normalization [-1, 1] is used via a mean and std of [0.5, 0.5, 0.5]. This is handled automatically if using open_clip.create_model_and_transforms from pretrained weights.
A ViT-H/14 with a 78.0% top-1 ImageNet-1k zero-shot was trained on JUWELS Booster. See model details here https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K
A ViT-g/14 with a 76.6% top-1 ImageNet-1k zero-shot was trained on JUWELS Booster. See model details here https://huggingface.co/laion/CLIP-ViT-g-14-laion2B-s12B-b42K
This model was trained with a shorted schedule than other LAION-2B models with 12B samples seen instead of 32+B. It matches LAION-400M training in samples seen. Many zero-shot results are lower as a result, but despite this it performs very well in some OOD zero-shot and retrieval tasks.
A ViT-B/32 with roberta base encoder with a 61.7% top-1 ImageNet-1k zero-shot was trained on stability. See model details here https://huggingface.co/laion/CLIP-ViT-B-32-roberta-base-laion2B-s12B-b32k This is the first openclip model using a HF text tower. It has better performance on a range of tasks compared to the standard text encoder, see metrics
{kind=link}
A ViT-B/32 with xlm roberta base encoder with a 62.33% top-1 ImageNet-1k zero-shot was trained on stability. See model details here https://huggingface.co/laion/CLIP-ViT-B-32-xlm-roberta-base-laion5B-s13B-b90k This is the first openclip model trained on the full laion5B dataset; hence the first multilingual clip trained with openclip. It has better performance on a range of tasks compared to the standard text encoder, see metrics A preliminary multilingual evaluation was run: 43% on imagenet1k italian (vs 21% for english B/32), 37% for imagenet1k japanese (vs 1% for english B/32 and 50% for B/16 clip japanese). It shows the multilingual property is indeed there as expected. Larger models will get even better performance.
{kind=link}
A ViT-H/14 with xlm roberta large encoder with a 77.0% (vs 78% for the english equivalent) top-1 ImageNet-1k zero-shot was trained on stability. See model details here https://huggingface.co/laion/CLIP-ViT-H-14-frozen-xlm-roberta-large-laion5B-s13B-b90k
This model was trained following the LiT methodology: the image tower was frozen (initialized from english openclip ViT-H/14), the text tower was initialized from xlm roberta large and unfrozen. This reduced training cost by a 3x factor.
See full english metrics
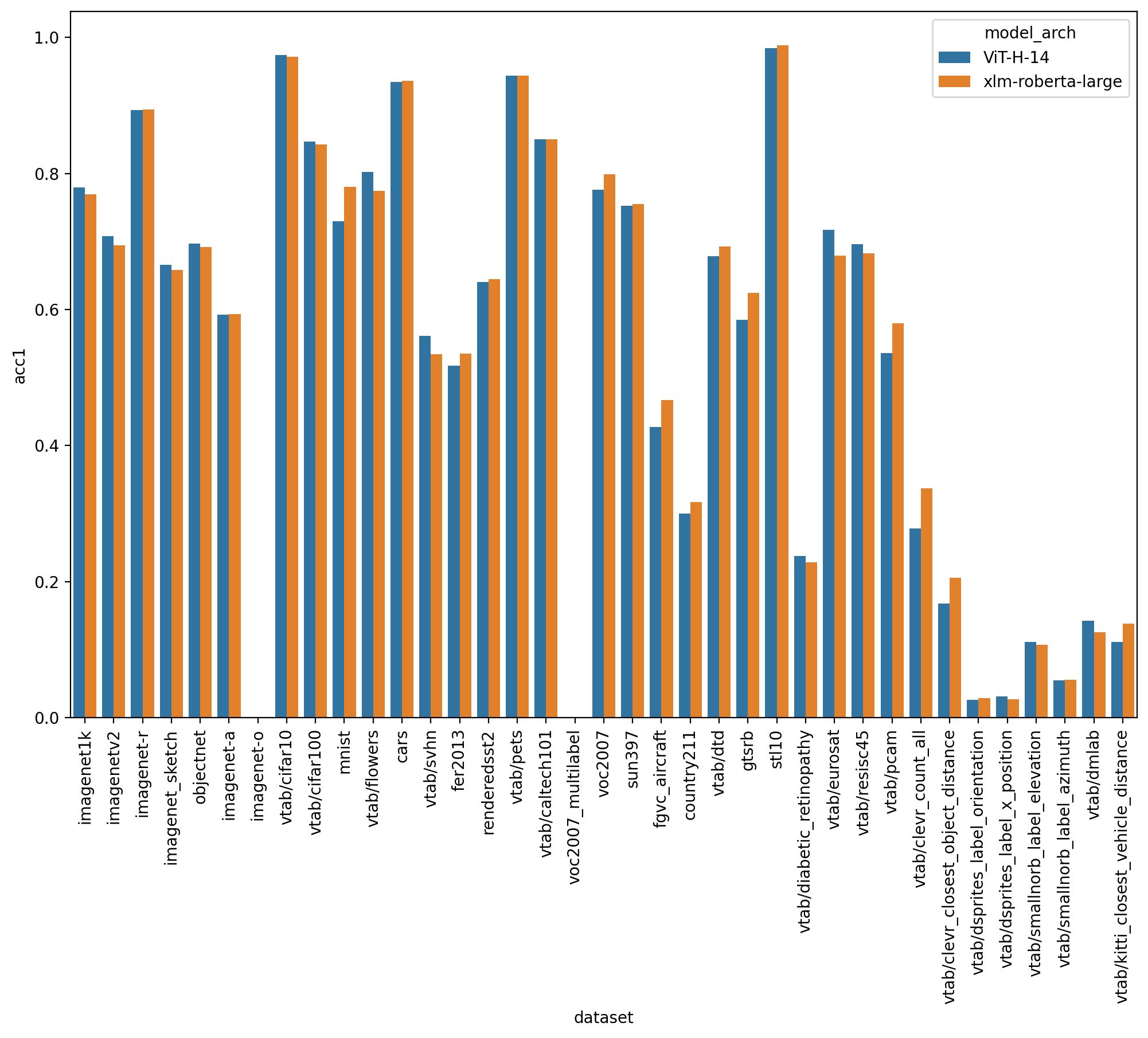{kind=link}
On zero shot classification on imagenet with translated prompts this model reaches:
- 56% in italian (vs 21% for https://github.com/clip-italian/clip-italian)
- 53% in japanese (vs 54.6% for https://github.com/rinnakk/japanese-clip)
- 55.7% in chinese (to be compared with https://github.com/OFA-Sys/Chinese-CLIP)
Below are checkpoints of models trained on YFCC-15M, along with their zero-shot top-1 accuracies on ImageNet and ImageNetV2. These models were trained using 8 GPUs and the same hyperparameters described in the "Sample running code" section, with the exception of lr=5e-4 and epochs=32.
- ResNet-50 (32.7% / 27.9%)
- ResNet-101 (34.8% / 30.0%)
- ResNet-50 (36.45%)
As part of DataComp, we trained models on CommonPool using various data filtering strategies.
The best performing models are specified below for the xlarge scale, see our paper DataComp: In seearch of the next generation of multimodal datasets for more details.
Additional models and more information can be found at /docs/datacomp_models.md.
-
datacomp_xl_s13b_b90k: A ViT-L/14 trained on DataComp-1B for 12.8B steps and batch size 90k. Achieves 79.2% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K. -
commonpool_xl_clip_s13b_b90k: A ViT-L/14 trained on CommonPool-XL filtered using CLIP scores, for 12.8B steps and batch size 90k. Achieves 76.4% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.clip-s13B-b90K. -
commonpool_xl_laion_s13b_b90k: A ViT-L/14 trained on CommonPool-XL filtered using the LAION-2B filtering scheme, for 12.8B steps and batch size 90k. Achieves 75.5% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.laion-s13B-b90K. -
commonpool_xl_s13b_b90k: A ViT-L/14 trained on CommonPool-XL without any filtering, for 12.8B steps and batch size 90k. Achieves 72.3% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL-s13B-b90K.
If you use models trained on DataComp-1B or CommonPool variations, please consider citing the following:
@article{datacomp,
title={DataComp: In search of the next generation of multimodal datasets},
author={Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alexander Ratner, Shuran Song, Hannaneh Hajishirzi, Ali Farhadi, Romain Beaumont, Sewoong Oh, Alex Dimakis, Jenia Jitsev, Yair Carmon, Vaishaal Shankar, Ludwig Schmidt},
journal={arXiv preprint arXiv:2304.14108},
year={2023}
}MetaCLIP models are described in the paper Demystifying CLIP Data. These models were developed by Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer and Christoph Feichtenhofer from Meta, New York University and the University of Washington.
Models are licensed under CC-BY-NC. More details are available at https://github.com/facebookresearch/MetaCLIP.
If you use MetaCLIP models, please cite the following:
@inproceedings{xu2023metaclip,
title={Demystifying CLIP Data},
author={Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu, Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer and Christoph Feichtenhofer},
journal={arXiv preprint arXiv:2309.16671},
year={2023}
}EVA-CLIP models are described in the paper EVA-CLIP: Improved Training Techniques for CLIP at Scale. These models were developed by Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang and Yue Cao from BAAI and HUST.
Models are licensed under the MIT License. More details are available at https://github.com/baaivision/EVA/tree/master/EVA-CLIP.
If you use EVA models, please cite the following:
@article{EVA-CLIP,
title={EVA-CLIP: Improved Training Techniques for CLIP at Scale},
author={Sun, Quan and Fang, Yuxin and Wu, Ledell and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2303.15389},
year={2023}
}NLLB-CLIP models are described in the paper NLLB-CLIP - train performant multilingual image retrieval model on a budget by Alexander Visheratin.
The model was trained following the LiT methodology: the image tower was frozen, the text tower was initialized from the NLLB encoder and unfrozen.
The model was trained on the LAION-COCO-NLLB dataset.
The first version of the model (nllb-clip) described in the paper was trained using the OpenAI CLIP image encoder.
The second version of the model (nllb-clip-siglip) was trained using the SigLIP image encoder.
Models are licensed under CC-BY-NC.
If you use NLLB-CLIP models, please cite the following:
@article{visheratin2023nllb,
title={NLLB-CLIP--train performant multilingual image retrieval model on a budget},
author={Visheratin, Alexander},
journal={arXiv preprint arXiv:2309.01859},
year={2023}
}CLIPA models are described in the following papers by Xianhang Li, Zeyu Wang, Cihang Xie from UC Santa Cruz:
- An Inverse Scaling Law for CLIP Training
- CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy
Models are licensed under Apache 2.0. More details are available at https://github.com/UCSC-VLAA/CLIPA and here.
If you use CLIPA models, please cite the following:
@inproceedings{li2023clipa,
title={An Inverse Scaling Law for CLIP Training},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
booktitle={NeurIPS},
year={2023},
}@article{li2023clipav2,
title={CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
journal={arXiv preprint arXiv:2306.15658},
year={2023},
}SigLIP models are described in the paper Sigmoid Loss for Language Image Pre-Training. These models were developed by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer from Google Deepmind.
Models are licensed under the Apache 2 license. More details are available at hhttps://github.com/google-research/big_vision.
If you use SigLIP models, please cite the following:
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}Data Filtering Network models are described in https://arxiv.org/abs/2309.17425. These models were developed by Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander Toshev and Vaishaal Shankar from Apple and the University of Washington.
Models are licensed under the following: https://huggingface.co/apple/DFN5B-CLIP-ViT-H-14-384/blob/main/LICENSE.
If you use DFN models, please cite the following:
@article{fang2023data,
title={Data Filtering Networks},
author={Fang, Alex and Jose, Albin Madappally and Jain, Amit and Schmidt, Ludwig and Toshev, Alexander and Shankar, Vaishaal},
journal={arXiv preprint arXiv:2309.17425},
year={2023}
}