1.安装命令:
sudo apt-get install openssh-server
安装完成,服务默认已经开启,可以远程ssh连接了。
2.查看ssh服务状态:
sudo service ssh status
3.ssh服务重启命令:
sudo service ssh restart
4.ssh服务的配置文件,可以修改服务端口,权限控制等
sudo gedit /etc/ssh/sshd_configvi是最强大的文本编辑器,没有之一。尽管 vi已经是古董级的软件,但还是有无数新人迎着困难去学习使用,可见其经典与受欢迎的程度。
无论是小说中还是电视剧,真正强大的武器都不容易驾驭,需要付出一些努力才能收获到更加强大的力量,对于vi这种**上古神器**来说更是如此。由于它全程使用键盘操作,很多首次接触 vi的人会觉得不习惯而中途放弃。然而,坚持下来的朋友就会渐渐地发现这种键盘操作的设计绝妙,经典之所以能成为经典,必然有它的道理,不用解释太多。
观察一个程序员对vi的熟练程度,可以判断它的技术水平,如果他对vi不熟悉,就肯定不是Linux平台下的程序员,说vi不好用的人也肯定不熟悉vi和Linux,没有例外。
vi 文件名
打开一个文件,如果文件不存在,就创建它。
示例:
vi book.c
vi 有三种模式,命令行模式、插入模式和替换模式,在命令行模式下,任何键盘输入都是命令,在插入模式和替换模式下,键盘输入的才是字符。
插入模式和替换模式也合称为编辑模式。
Esc 从编辑模式切换到命令行模式。
i 在光标所在位置前面开始插入。
a 在光标所在的位置后面开始插入。
o 在光标所在位置行的下面插入空白行。
O 在光标所在位置行的上面插入空白行。
I 在光标所在位置行的行首开始插入。
A 在光标所在位置行的行末开始插入。
k 类似方向键上。
j 类似方向键下。
h 类似方向键左。
l 类是方向键右。
Ctrl+u 向上翻半页。
Ctrl+d 向下翻页。
Ctrl+g 显示光标所在位置的行号和文件的总行数。
nG 光标跳到文件的第n行行首。
G 光标跳到文件最后一行。
:5回车 光标跳到第5行。
:n回车 光标跳到第n行。
0 光标跳到当前行的行首。
$ 光标跳到当前行的行尾。
w 光标跳到下个单词的开头。
b 光标跳到上个单词的开头。
e 光标跳到本单词的尾部。
x 每按一次,删除光标所在位置的一个字符。
nx 如"3x"表示删除光标所在位置开始的3个字符。
dw 删除光标所在位置到本单词结尾的字符。
D 删除本行光标所在位置后面全部的内容。
dd 删除光标所在位置的一行。
ndd 如"3dd"表示删除光标所在位置开始的3行。
yy 将光标所在位置的一行复制到缓冲区。
nyy 将光标所在位置的n行复制到缓冲区。
p 将缓冲区里的内容粘贴到光标所在位置。
r 替换光标所在位置的一个字符 replace。
R 从光标所在位置开始替换,直到按下"Esc"。
cw 从光标所在位置开始替换单词,直到按下"Esc"。
u 撤销命令,可多次撤销。
J 把当前行的下一行接到当前行的尾部。
/abcd 在当前打开的文件中查找“abcd”文本内容。
n 查找下一个。
N 查找上一下。
. 重复执行上一次执行的vi命令。
~ 对光标当前所在的位置的字符进行大小写转换。
列操作
Ctrl+V 光标上或下 大写的I 输入内容 Esc
:w回车 存盘。
:w!回车 强制存盘。
:wq回车 存盘退出。
:x回车 存盘退出。
:q回车 不存盘退出。
:q!回车 不存盘强制退出。
:g/aaaaaaaaa/s//bbbbbb/g回车 把文件中全部的aaaaaaaaa替换成bbbbbb。
Ctl+insert 复制鼠标选中的文本,相当于Ctl+c。
Shift+insert 输出鼠标选中的文本,相当于Ctl+v。
以上两个命令在windows和UNIX中是通用的。
当vim开启smartindent时,对于代码会有自动换行的功效。但是,有时候我们需要在向vim中粘贴代码时,需要暂时关闭自动换行的功能。
解决方法:
:set paste
之后进行插入操作,vim提示变为: – INSERT (paste) –
这时就不再有自动换行。
恢复:
:set nopaste
vim提示变为:– INSERT –
手动复制进去
git clone https://github.com/octol/vim-cpp-enhanced-highlight.git /tmp/vim-cpp-enhanced-highlight
mkdir -p ~/.vim/after/syntax/
mv /tmp/vim-cpp-enhanced-highlight/after/syntax/cpp.vim ~/.vim/after/syntax/cpp.vim
rm -rf /tmp/vim-cpp-enhanced-highlightcp /usr/share/vim/vimrc ~/.vimrc
先复制一份vim配置模板到个人目录下
注:redhat 改成 cp /etc/vimrc ~/.vimrc
步骤2:
vi ~/.vimrc
进入insert模式,在最后加二行
syntax on
set nu!
保存收工。
set nocompatible "去掉有关vi一致性模式,避免以前版本的bug和局限
set nu! "显示行号
set guifont=Luxi/ Mono/ 9 " 设置字体,字体名称和字号
filetype on "检测文件的类型
set history=1000 "记录历史的行数
set background=dark "背景使用黑色
syntax on "语法高亮度显示
set autoindent "vim使用自动对齐,也就是把当前行的对齐格式应用到下一行(自动缩进)
set cindent "(cindent是特别针对 C语言语法自动缩进)
set smartindent "依据上面的对齐格式,智能的选择对齐方式,对于类似C语言编写上有用
set tabstop=4 "设置tab键为4个空格,
set shiftwidth =4 "设置当行之间交错时使用4个空格
set ai! " 设置自动缩进
set showmatch "设置匹配模式,类似当输入一个左括号时会匹配相应的右括号
set guioptions-=T "去除vim的GUI版本中得toolbar
set vb t_vb= "当vim进行编辑时,如果命令错误,会发出警报,该设置去掉警报
set ruler "在编辑过程中,在右下角显示光标位置的状态行
set nohls "默认情况下,寻找匹配是高亮度显示,该设置关闭高亮显示
set incsearch "在程序中查询一单词,自动匹配单词的位置;如查询desk单词,当输到/d时,会自动找到第一个d开头的单词,当输入到/de时,会自动找到第一个以ds开头的单词,以此类推,进行查找;当找到要匹配的单词时,别忘记回车
set backspace=2 " 设置退格键可用
注:如果是mac,更好的办法是直接换掉默认的终端,改用zsh
在UBUNTU中vim的配置文件存放在/etc/vim目录中,配置文件名为vimrc
在Fedora中vim的配置文件存放在/etc目录中,配置文件名为vimrc
在Red Hat Linux 中vim的配置文件存放在/etc目录中,配置文件名为vimrc
set nocompatible "去掉有关vi一致性模式,避免以前版本的bug和局限
set nu! "显示行号
set guifont=Luxi/ Mono/ 9 " 设置字体,字体名称和字号
filetype on "检测文件的类型
set history=1000 "记录历史的行数
set background=dark "背景使用黑色
syntax on "语法高亮度显示
set autoindent "vim使用自动对齐,也就是把当前行的对齐格式应用到下一行(自动缩进)
set cindent "(cindent是特别针对 C语言语法自动缩进)
set smartindent "依据上面的对齐格式,智能的选择对齐方式,对于类似C语言编写上有用
set tabstop=4 "设置tab键为4个空格,
set shiftwidth =4 "设置当行之间交错时使用4个空格
set ai! " 设置自动缩进
set showmatch "设置匹配模式,类似当输入一个左括号时会匹配相应的右括号
set guioptions-=T "去除vim的GUI版本中得toolbar
set vb t_vb= "当vim进行编辑时,如果命令错误,会发出警报,该设置去掉警报
set ruler "在编辑过程中,在右下角显示光标位置的状态行
set nohls "默认情况下,寻找匹配是高亮度显示,该设置关闭高亮显示
set incsearch "在程序中查询一单词,自动匹配单词的位置;如查询desk单词,当输到/d时,会自动找到第一个d开头的单词,当输入到/de时,会自动找到第一个以ds开头的单词,以此类推,进行查找;当找到要匹配的单词时,别忘记回车
set backspace=2 " 设置退格键可用
修改一个文件后,自动进行备份,备份的文件名为原文件名加“~”后缀
if has("vms")
set nobackup
else
set backup
endif如果设置完成后,发现功能没有起作用,检查一下系统下是否安装了vim-enhanced包,查询命令为:
$rpm -q vim-enhanced 注意:如果设置好以上设置后,VIM没有作出相应的动作,那么请你把你的VIM升级到最新版,一般只要在终端输入以下命令即可:sudo apt-get install vim
转自:https://blog.csdn.net/chuanj1985/article/details/6873830
apt install make在软件的工程中的源文件是很多的,其按照类型、功能、模块分别放在若干个目录和文件中,哪些文件需要编译,那些文件需要后编译,那些文件需要重新编译,甚至进行更复杂的功能操作,这就有了我们的系统编译的工具。
在linux和unix中,有一个强大的实用程序,叫make,可以用它来管理多模块程序的编译和链接,直至生成可执行文件。
make程序需要一个编译规则说明文件,称为makefile,makefile文件中描述了整个软件工程的编译规则和各个文件之间的依赖关系。
makefile就像是一个shell脚本一样,其中可以执行操作系统的命令,它带来的好处就是我们能够实现“自动化编译”,一旦写好,只要一个make命令,整个软件功能就完全自动编译,提高了软件开发的效率。
make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说大多数编译器都有这个命令,使用make可以是重新编译的次数达到最小化。
makefile文件的规则可以非常复杂,比C程序还要复杂,我通过示例来介绍它的简单用法。
文件名:makefile,内容如下:
all:book1 book46
book1:book1.c
gcc -o book1 book1.c
book46:book46.c _public.h _public.c
gcc -o book46 book46.c _public.c
clean:
rm -f book1 book46第一行
all:book book46all: 这是固定的写法。
book1 book46表示需要编译目标程序的清单,中间用空格分隔开,如果清单很长,可以用\换行。
第二行
makefile文件中的空行就像C程序中的空行一样,只是为了书写整洁,没有什么意义。
第三行
book1:book1.cbook1:表示需要编译的目标程序。
如果要编译目标程序book1,需要依赖源程序book1.c,当book1.c的内容发生了变化,执行make的时候就会重新编译book1。
第四行
gcc -o book1 book1.c这是一个编译命令,和在操作系统命令行输入的命令一样,但是要注意一个问题,在gcc之前要用tab键,看上去像8个空格,实际不是,一定要用tab,空格不行。
第六行
book46:book46.c _public.h _public.c与第三行的含义相同。
book46:表示编译的目标程序。
如果要编译目标程序book46,需要依赖源程序book46.c、_public.h和_public.c三个文件,只要任何一个的内容发生了变化,执行make的时候就会重新编译book46。
第七行
gcc -o book46 book46.c _public.c与第四行的含义相同。
第九行
clean:清除目标文件,清除的命令由第十行之后的脚本来执行。
第十行
rm -f book1 book46清除目标文件的脚本命令,注意了,rm之前也是一个tab键,不是空格。
makefile准备好了,在命令提示符下执行make就可以编译makefile中all参数指定的目标文件。
执行make编译目标程序:

再执行一次make:

因为全部的目标程序都是最新的,所以提示没有目标可以编译。
执行make clean,执行清除目标文件的指令。

再执行make重新编译。

修改_public.c程序,随便改点什么,只要改了就行。
然后再执行make:

注意了,因为book46依赖的源程序之一_public.c改变了,所以book46重新编译。
book1没有重新编译,因为book1依赖的源文件并没有改变。
makefile中,变量就是一个名字,变量的值就是一个文本字符串。在makefile中的目标,依赖,命令或其他地方引用变量时,变量会被它的值替代。
我通过示例来介绍它的简单用法。
CC=gcc
FLAG=-g
all:book1 book46
book1:book1.c
$(CC) $(FLAG) -o book1 book1.c
book46:book46.c _public.h _public.c
$(CC) $(FLAG) -o book46 book46.c _public.c
clean:
rm -f book1 book46第一行
CC=gcc定义变量CC,赋值gcc。
第二行
FLAG=-g定义变量FLAG,赋值-g。
第七行
$(CC) $(FLAG) -o book1 book1.c$(CC)和$(FLAG)就是使用变量CC和FLAG的值,类似于C语言的宏定义,替换后的结果是:
gcc -g -o book1 book1.c编译效果:

在makefile文件中,使用变量的好处有两个:
1)如果在很多编译指令采用了变量,只要修改变量的值,就相当于修改全部的编译指令;
2)把比较长的、公共的编译指令采用变量来表示,可以让makefile更简洁。
四、应用经验
makefile文件的编写可以很复杂,复杂到我不想看,在实际开发中,用不着那么复杂的makefile,我追求简单实用的方法,腾出更多的时间和精力去做更重要的事情,那些把makefile文件写得很复杂的程序员在我看来是吃饱了撑的。
五、课后作业
把您这段时间写的程序全部编写到makefile中,以后再也不要在命令提示符下用gcc了。
六、版权声明
C语言技术网原创文章,转载请说明文章的来源、作者和原文的链接。
来源:C语言技术网(www.freecplus.net)
作者:码农有道
如果文章有错别字,或者内容有错误,或其他的建议和意见,请您联系我们指正,非常感谢!!!
编译器
apt install gcc-c++编译C程序的命令是gcc,编译C++程序的命令是g++,g++命令和gcc命令的用法相同,把gcc改为g++就可以了,我们在学习C语言时编写的那些示例程序,基本上都可以用g++来编译。
g++ -o book1 book1.c
XSHELL ssh vim 語法高亮配置
文件, 默认/当前会话属性, 终端, 终端类型:linux
文件, 默认/当前会话属性, 终端, 键盘, 功能键类型:linux
如何对xshell中的输入命令的那一行进行高亮显示呢
修改你登录用户目录下的.bashrc文件,把46行的注释去掉保存后重新登录即可
(如果使用其他用户登录,其下的.bashrc也要修改,和xshell无关)
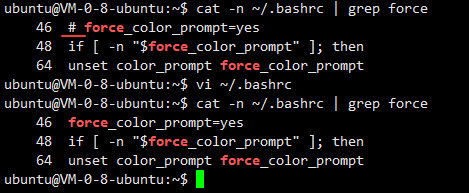
重新登录后
socket就是插座(中文翻译成套接字有点莫名其妙),运行在计算机中的两个程序通过socket建立起一个通道,数据在通道中传输。

socket把复杂的TCP/IP协议族隐藏了起来,对程序员来说,只要用好socket相关的函数,就可以完成网络通信。
socket提供了流(stream)和数据报(datagram)两种通信机制,即流socket和数据报socket。
流socket基于TCP协议,是一个有序、可靠、双向字节流的通道,传输数据不会丢失、不会重复、顺序也不会错乱。就像两个人在打电话,接通后就在线了,您一句我一句的聊天。
数据报socket基于UDP协议,不需要建立和维持连接,可能会丢失或错乱。UDP不是一个可靠的协议,对数据的长度有限制,但是它的速度比较高。就像短信功能,一个人向另一个人发短信,对方不一定能收到。
在实际开发中,数据报socket的应用场景极少,本教程只介绍流socket。
在TCP/IP网络应用中,两个程序之间通信模式是客户/服务端模式(client/server),客户/服务端也叫作客户/服务器,各人习惯。

1)创建服务端的socket。
2)把服务端用于通信的地址和端口绑定到socket上。
3)把socket设置为监听模式。
4)接受客户端的连接。
5)与客户端通信,接收客户端发过来的报文后,回复处理结果。
6)不断的重复第5)步,直到客户端断开连接。
7)关闭socket,释放资源。
服务端示例(server.cpp)
/*
* 程序名:server.cpp,此程序用于演示socket通信的服务端
* 作者:C语言技术网(www.freecplus.net) 日期:20190525
*/
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <netdb.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
int main(int argc,char *argv[])
{
if (argc!=2)
{
printf("Using:./server port\nExample:./server 5005\n\n"); return -1;
}
// 第1步:创建服务端的socket。
int listenfd;
if ( (listenfd = socket(AF_INET,SOCK_STREAM,0))==-1) { perror("socket"); return -1; }
// 第2步:把服务端用于通信的地址和端口绑定到socket上。
struct sockaddr_in servaddr; // 服务端地址信息的数据结构。
memset(&servaddr,0,sizeof(servaddr));
servaddr.sin_family = AF_INET; // 协议族,在socket编程中只能是AF_INET。
servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // 任意ip地址。
//servaddr.sin_addr.s_addr = inet_addr("192.168.190.134"); // 指定ip地址。
servaddr.sin_port = htons(atoi(argv[1])); // 指定通信端口。
if (bind(listenfd,(struct sockaddr *)&servaddr,sizeof(servaddr)) != 0 )
{ perror("bind"); close(listenfd); return -1; }
// 第3步:把socket设置为监听模式。
if (listen(listenfd,5) != 0 ) { perror("listen"); close(listenfd); return -1; }
// 第4步:接受客户端的连接。
int clientfd; // 客户端的socket。
int socklen=sizeof(struct sockaddr_in); // struct sockaddr_in的大小
struct sockaddr_in clientaddr; // 客户端的地址信息。
clientfd=accept(listenfd,(struct sockaddr *)&clientaddr,(socklen_t*)&socklen);
printf("客户端(%s)已连接。\n",inet_ntoa(clientaddr.sin_addr));
// 第5步:与客户端通信,接收客户端发过来的报文后,回复ok。
char buffer[1024];
while (1)
{
int iret;
memset(buffer,0,sizeof(buffer));
if ( (iret=recv(clientfd,buffer,sizeof(buffer),0))<=0) // 接收客户端的请求报文。
{
printf("iret=%d\n",iret); break;
}
printf("接收:%s\n",buffer);
strcpy(buffer,"ok");
if ( (iret=send(clientfd,buffer,strlen(buffer),0))<=0) // 向客户端发送响应结果。
{ perror("send"); break; }
printf("发送:%s\n",buffer);
}
// 第6步:关闭socket,释放资源。
close(listenfd); close(clientfd);
}1)创建客户端的socket。
2)向服务器发起连接请求。
3)与服务端通信,发送一个报文后等待回复,然后再发下一个报文。
4)不断的重复第3)步,直到全部的数据被发送完。
5)第4步:关闭socket,释放资源。
客户端示例(client.cpp)
/*
* 程序名:client.cpp,此程序用于演示socket的客户端
* 作者:C语言技术网(www.freecplus.net) 日期:20190525
*/
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <netdb.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
int main(int argc,char *argv[])
{
if (argc!=3)
{
printf("Using:./client ip port\nExample:./client 127.0.0.1 5005\n\n"); return -1;
}
// 第1步:创建客户端的socket。
int sockfd;
if ( (sockfd = socket(AF_INET,SOCK_STREAM,0))==-1) { perror("socket"); return -1; }
// 第2步:向服务器发起连接请求。
struct hostent* h;
if ( (h = gethostbyname(argv[1])) == 0 ) // 指定服务端的ip地址。
{ printf("gethostbyname failed.\n"); close(sockfd); return -1; }
struct sockaddr_in servaddr;
memset(&servaddr,0,sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(atoi(argv[2])); // 指定服务端的通信端口。
memcpy(&servaddr.sin_addr,h->h_addr,h->h_length); // 不能直接赋值
if (connect(sockfd, (struct sockaddr *)&servaddr,sizeof(servaddr)) != 0) // 向服务端发起连接清求。
{ perror("connect"); close(sockfd); return -1; }
char buffer[1024];
// 第3步:与服务端通信,发送一个报文后等待回复,然后再发下一个报文。
for (int ii=0;ii<3;ii++)
{
int iret;
memset(buffer,0,sizeof(buffer));
sprintf(buffer,"这是第%d个超级女生,编号%03d。",ii+1,ii+1);
if ( (iret=send(sockfd,buffer,strlen(buffer),0))<=0) // 向服务端发送请求报文。
{ perror("send"); break; }
printf("发送:%s\n",buffer);
memset(buffer,0,sizeof(buffer));
if ( (iret=recv(sockfd,buffer,sizeof(buffer),0))<=0) // 接收服务端的回应报文。
{
printf("iret=%d\n",iret); break;
}
printf("接收:%s\n",buffer);
}
// 第4步:关闭socket,释放资源。
close(sockfd);
}在运行程序之前,必须保证服务器的防火墙已经开通了网络访问策略(云服务器还需要登录云控制平台开通访问策略)。
先启动服务端程序server,服务端启动后,进入等待客户端连接状态,然后启动客户端。
客户端的输出如下:

服务端的输出如下:

在socket通信的客户端和服务器的程序里,出现了多种数据结构,调用了多个函数,涉及到很多方面的知识,对初学者来说,更重要的是了解socket通信的过程、每段代码的用途和函数调用的功能,不要去纠缠这些结构体和函数的参数,这些函数和参数虽然比较多,但可以修改的非常少,别抄错就可以了,需要注意的地方我会提出。
在UNIX系统中,一切输入输出设备皆文件,socket()函数的返回值其本质是一个文件描述符,是一个整数。
如果服务器有多个网卡,多个IP地址,socket通信可以指定用其中一个地址来进行通信,也可以任意ip地址。
1)指定ip地址的代码
m_servaddr.sin_addr.s_addr = inet_addr("192.168.149.129"); // 指定ip地址2)任意ip地址的代码
m_servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // 本主机的任意ip地址在实际开发中,采用任意ip地址的方式比较多。
m_servaddr.sin_port = htons(5000); // 通信端口 struct hostent* h;
if ( (h = gethostbyname("118.89.50.198")) == 0 ) // 指定服务端的ip地址。
{ printf("gethostbyname failed.\n"); close(sockfd); return -1; } servaddr.sin_port = htons(5000);send函数用于把数据通过socket发送给对端。不论是客户端还是服务端,应用程序都用send函数来向TCP连接的另一端发送数据。
函数声明:
ssize_t send(int sockfd, const void *buf, size_t len, int flags);sockfd为已建立好连接的socket。
buf为需要发送的数据的内存地址,可以是C语言基本数据类型变量的地址,也可以数组、结构体、字符串,内存中有什么就发送什么。
len需要发送的数据的长度,为buf中有效数据的长度。
flags填0, 其他数值意义不大。
函数返回已发送的字符数。出错时返回-1,错误信息errno被标记。
注意,就算是网络断开,或socket已被对端关闭,send函数不会立即报错,要过几秒才会报错。
如果send函数返回的错误(<=0),表示通信链路已不可用。
recv函数用于接收对端socket发送过来的数据。
recv函数用于接收对端通过socket发送过来的数据。不论是客户端还是服务端,应用程序都用recv函数接收来自TCP连接的另一端发送过来数据。
函数声明:
ssize_t recv(int sockfd, void *buf, size_t len, int flags);sockfd为已建立好连接的socket。
buf为用于接收数据的内存地址,可以是C语言基本数据类型变量的地址,也可以数组、结构体、字符串,只要是一块内存就行了。
len需要接收数据的长度,不能超过buf的大小,否则内存溢出。
flags填0, 其他数值意义不大。
函数返回已接收的字符数。出错时返回-1,失败时不会设置errno的值。
如果socket的对端没有发送数据,recv函数就会等待,如果对端发送了数据,函数返回接收到的字符数。出错时返回-1。如果socket被对端关闭,返回值为0。
如果recv函数返回的错误(<=0),表示通信通道已不可用。
对服务端来说,有两个socket,一个是用于监听的socket,还有一个就是客户端连接成功后,由accept函数创建的用于与客户端收发报文的socket。
socket是系统资源,操作系统打开的socket数量是有限的,在程序退出之前必须关闭已打开的socket,就像关闭文件指针一样,就像delete已分配的内存一样,极其重要。
值得注意的是,关闭socket的代码不能只在main函数的最后,那是程序运行的理想状态,还应该在main函数的每个return之前关闭。
socket函数用于创建一个新的socket,也就是向系统申请一个socket资源。socket函数用户客户端和服务端。
函数声明:
int socket(int domain, int type, int protocol);参数说明:
domain:协议域,又称协议族(family)。常用的协议族有AF_INET、AF_INET6、AF_LOCAL(或称AF_UNIX,Unix域Socket)、AF_ROUTE等。协议族决定了socket的地址类型,在通信中必须采用对应的地址,如AF_INET决定了要用ipv4地址(32位的)与端口号(16位的)的组合、AF_UNIX决定了要用一个绝对路径名作为地址。
type:指定socket类型。常用的socket类型有SOCK_STREAM、SOCK_DGRAM、SOCK_RAW、SOCK_PACKET、SOCK_SEQPACKET等。流式socket(SOCK_STREAM)是一种面向连接的socket,针对于面向连接的TCP服务应用。数据报式socket(SOCK_DGRAM)是一种无连接的socket,对应于无连接的UDP服务应用。
protocol:指定协议。常用协议有IPPROTO_TCP、IPPROTO_UDP、IPPROTO_STCP、IPPROTO_TIPC等,分别对应TCP传输协议、UDP传输协议、STCP传输协议、TIPC传输协议。
说了一大堆废话,第一个参数只能填AF_INET,第二个参数只能填SOCK_STREAM,第三个参数只能填0。
除非系统资料耗尽,socket函数一般不会返回失败。
返回值:成功则返回一个socket,失败返回-1,错误原因存于errno 中。
把ip地址或域名转换为hostent 结构体表达的地址。
函数声明:
struct hostent *gethostbyname(const char *name);参数name,域名或者主机名,例如"192.168.1.3"、"www.freecplus.net"等。
返回值:如果成功,返回一个hostent结构指针,失败返回NULL。
gethostbyname只用于客户端。
gethostbyname只是把字符串的ip地址转换为结构体的ip地址,只要地址格式没错,一般不会返回错误。失败时不会设置errno的值。
向服务器发起连接请求。
函数声明:
int connect(int sockfd, struct sockaddr * serv_addr, int addrlen);
函数说明:connect函数用于将参数sockfd 的socket 连至参数serv_addr 指定的服务端,参数addrlen为sockaddr的结构长度。
返回值:成功则返回0,失败返回-1,错误原因存于errno 中。
connect函数只用于客户端。
如果服务端的地址错了,或端口错了,或服务端没有启动,connect一定会失败。
服务端把用于通信的地址和端口绑定到socket上。
函数声明:
int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen);参数sockfd,需要绑定的socket。
参数addr,存放了服务端用于通信的地址和端口。
参数addrlen表示addr结构体的大小。
返回值:成功则返回0,失败返回-1,错误原因存于errno 中。
如果绑定的地址错误,或端口已被占用,bind函数一定会报错,否则一般不会返回错误。
listen函数把主动连接socket变为被动连接的socket,使得这个socket可以接受其它socket的连接请求,从而成为一个服务端的socket。
函数声明:
int listen(int sockfd, int backlog);返回:0-成功, -1-失败
参数sockfd是已经被bind过的socket。socket函数返回的socket是一个主动连接的socket,在服务端的编程中,程序员希望这个socket可以接受外来的连接请求,也就是被动等待客户端来连接。由于系统默认时认为一个socket是主动连接的,所以需要通过某种方式来告诉系统,程序员通过调用listen函数来完成这件事。
参数backlog,这个参数涉及到一些网络的细节,比较麻烦,填5、10都行,一般不超过30。
当调用listen之后,服务端的socket就可以调用accept来接受客户端的连接请求。
返回值:成功则返回0,失败返回-1,错误原因存于errno 中。
listen函数一般不会返回错误。
服务端接受客户端的连接。
函数声明:
int accept(int sockfd,struct sockaddr *addr,socklen_t *addrlen);参数sockfd是已经被listen过的socket。
参数addr用于存放客户端的地址信息,用sockaddr结构体表达,如果不需要客户端的地址,可以填0。
参数addrlen用于存放addr参数的长度,如果addr为0,addrlen也填0。
accept函数等待客户端的连接,如果没有客户端连上来,它就一直等待,这种方式称之为阻塞。
accept等待到客户端的连接后,创建一个新的socket,函数返回值就是这个新的socket,服务端使用这个新的socket和客户端进行报文的收发。
返回值:成功则返回0,失败返回-1,错误原因存于errno 中。
accept在等待的过程中,如果被中断或其它的原因,函数返回-1,表示失败,如果失败,可以重新accept。
服务端函数调用的流程是:socket->bind->listen->accept->recv/send->close
客户端函数调用的流程是:socket->connect->send/recv->close
其中send/recv可以进行多次交互。
六、课后作业
1)把client.cpp和server.cpp抄下来,编译运行,试试修改参数再运行。
2)client.cpp和server.cpp程序中,有些代码不能动,有些代码可以动,把能动的都动一下,就算是抄代码,也要抄个明白。
3)服务端的accept函数会阻塞,阻塞是专业名词,即等待,可以用代码测试一下。
4)不管是服务端还是客户端recv函数也会阻塞,可以用代码测试一下。
5)修改client.cpp和server.cpp,实现点对点的聊天功能,用户在客户端输入一个字符串,然后发送给服务端,服务端收到客户端的报文后,也提示用户输入一个字符串,返回给客户端,如果服务端收到客户端的报文是“bye”通信结束。
6)如果以上作业都能完成,建议再把本文章的内容再看一次,对文章开始部分的理论知识将有新的理解。
七、版权声明
C语言技术网原创文章,转载请说明文章的来源、作者和原文的链接。
来源:C语言技术网(www.freecplus.net)
作者:码农有道
// ulimit -a 1024 个
ubuntu@ubuntu:~/Desktop$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 15399
max locked memory (kbytes, -l) 65536
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 15399
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
// 修改为 2000 个
ubuntu@ubuntu:~/Desktop$ ulimit -HSn 2000服努端程序的端口释放后可能会处于 TIME WAIT 状态,等待两分钟之后才能再被使用SO_REUSEADDR是让端口释放后立即就可以被再次使用。
// 设置 SO_REUSEADDR选项
int opt=1;
unsigned int len=sizeof(opt);
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, len)netstat -na
-
字节顺序:
- 是指占内存多于一个字节类型的数据在内存中的存放顺序,一个32位整数由4个字节组成。內存中存储这4个字节有两种方法:一种是将低序字节存储在起始地址,这称为小端(little-endian)字节序;另一种方法是将高序字节存储在起始地址,这称为大端(big-endian)字节序。

- 这两种字节序之间没有标准可循,两种格式都有系统使用。比如,Inter x86、ARM核采用的是小端模式,Power pc、MIPS UNIX和HP-PA UNIX釆用大端模式。 大于一个字节类型的数据在内存中的存放有顺序,一个字节的数据没有顺序的问题
-
网络字节序:网络字节序是TCP/P中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。网络字节序采用 big endian排序方式
-
主机字节序:不同的机器主机字节序不相同,与CPU设计有关,数据的顺序是由cpu决定的,而与操作系统无关。
-
由于这个原因不同体系结构的机器之间无法通信,所以要转换成一种约定的字节序,也就是网络字节序。即使是同一台机器上的两个进程(比如一个由C语言,另一个由Java编写)通信,也要考虑字节序的问题(VM采用大端字节序)。
-
网络字节序与主机字节序之间的转换函数:
hons(),、ntohs()、htonl()、ntohl()- htons和 ntohs完成16位无符号数的相互转换,
- htonl和ntohl完成32位无符号数的相互转换。host to network short long

struct sockaddr{
unsigned short sa_family;
char sa_data[14];
}
struct sockaddr_in{
short int sin_family;
unsigned short int sin_port;
struct in addr sin_addr;
unsigned char sin_zero[8];
}
struct in addr{
unsigned long s_addr;
}强制转换为老的 sockaddr
int bind (int sockfd, const struct sockaddr *addr, socklen_t addr len)struct hostent {
char* h_name; //主机名
char*h_aliases; //主机所有别名构成的字符串数组,同一P可绑定多个域名int h int h_addrtype; //主机P地址的类型,例如PV4(AF INET)还是PV6
int h_length; //主机IP地址长度,IPV4地址为4,IPV6地址则为16
char*h addr_list; //主机的jp地址,以网络字节序存储。
}
#define h_addr h_addr_list[0]/*for backward compatibility*/
// gethostbyname函数可以利用字符串格式的域名获得IP网络字节顺序地址。
struct hostent*gethostbyname(const char*name)- 将一个字符串IP地址转换为一个32位的网络字节序IP地址。如果这个函数成功,函数的返回值非零,如果输入地址不正确则会返回零。使用这个函数并没有错误码存放在errno中,所以它的值会被忽略
- 把网络字节序IP地址转换成字符串的IP地址。
int inet_aton(const char*cp,struct in_addr*inp);
char*inet_ntoa(struct in_addr in);
in_addr_t inet_addr(const char*cp);// 和第一个相同返回新的socket,生成队列。
accept从队列中获取一个
1)服务端在调用 llisten0之前,客户端不能向服务端发起连接请求的
2)服务端调用 listen0函数后,服务端的 socke开始监听客户端的连接
3)客户端调用 connect0函数向服务端发起连接请求
4)在cP底层,客户端和服务端握手后建立起通信通道,如果有多个客户端请求,在服务端就会形成一个已准备好的连接的队列
5)服务端调用 accept0函数从队列中获取一个已准备好的连接,函数返回一个新的socket,新的 socket用于与客户端通信,listen的 socket只负责监听客户端的连接请求。
- 内核会为ten状态的 socket维护两个队列:不完全连接请求队列(SYN RECV状态) 和等待acep建立 socke的队列(ESTABLISHED状态)
- 在linux内核22之后,backlog参数的形为改变了,现在它指等待 accept的完全建立的socket的队列长度,而不是不完全连接请求的数量。不完全连接队列的长度可以使用 /proc/sys/net/ipv4/tcp_max_syn_backlog设置(缺省值128)
- backlog参数如果比/proc/sys/net/ipv4/tcp max syn backlog,则截断
分包:发送方发送字符串”helloworld",接收方却接收到了两个字符串”hello和"world粘包:发送方发送两个字符串”hello”+"world",接收方却一次性接收到了"helloworld" 但是TcP传输数据能保证几点: 1)顺序不变,例如发送方发送hell,接收方也一定顺序接收到helo,这个是TCP协议承诺的,因此这点成为我们解决分包和粘包问题的关键
2)分割的包中间不会插入其他数据。
在实际开发中,为了解决分包和粘包的问题,就一定要自定义一份协议,最常用的方一法是
报文长度+报文内容0010helloworld 报文长度asci码,二进制的数字
用于解决分包和粘包,封装成类。
基础:
- 信号;
- 多进程;
- xml登录和身份验证
- client与 server建立连接进行通信,通信完成后释放连接,建立连接时需要3次握手,释放连接需要4次挥手,连接的建立和释放都需要时间,server还有创建新进程或线程的开销。
- 短连接:client/server间只进行一次或连续多次通信,通信完成后马上断开了。管理起来比较简单,不需要额外的控制手段。
- 长连接:client/server间需要多次通信,通信的频率和次数不确定,所以client和 server需要保持这个连接。 根据不同的应用场景采用不同的策略,没有十全十美的选择,只有合适的选择
-
在实际项目开发中,除了完成程序的功能,还需要测试性能。
- 在充分了解服务端的性能后,才能决定如何选择服务端的架构,还有网络带宽、硬件配置等。
- 服务端的性能指标是面试中必问的。
- 如果不了解系统的性能指标,面试官会认为您没有实际项目开发经验或对网络编程是一知半解。主要的性能指标如下:
- 1)服务端的并发能力;
- 2)服务端的业务处理能力
- 3)客户端业务响应时效;
- 4)网络带宽。
重要的业务系统,最好是与系统管理员和网络管理员一起测试。
- 多进程/线程并发模型,为每个 socket分配一个进程/线程。
- I/O(多路)复用,采用单个进/线程就可以管理多个 socket
- 网络设备(交换机、路由器);
- 大型游戏的后台
- nginx、redis
- l/O复用有三种方案:select、poll、epoll,各有优缺点,select并不是一定就不行,epoll 也不是什么都好,各有应用场景,必须全部掌握。


- select的水平触发
- selec采用“水平触发"的方式,如果报告了fd后事件没有被处理或数据没有被全部读取,那么下次 select时会再次报告该fd。
- select的缺点
- 1)select支持的文件描述符数量太小了,默认是1024,虽然可以调整,但是,描述符数量越大,效率将更低,调整的意义不大。
- 2)每次调用 select,都需要把 fdset从用户态拷贝到内核。
- 3)同时在线的大量客户端有事件发生的可能很少,但还是需要遍历 feet,因此随着监视的描述符数量的增长,其效率也会线性下降。
- select的其它用途
- 在unⅸ(Linux)世界里,一切皆文件,文件就是一串二进制流,不管 socket、管道、終端、设备等都是文件,一切都是流。在信息交换的过程中,都是对这些流进行数据的收发操作,简称为Ⅳ◎操作input and output),往流中读出数据,系统调用read,写入数据,系统调用write
- select是io复用函数,除了用于网络通信,还可以用于文件、管道、终端、设备等操作,但开发场景比较少。 了解 pselect函数。
-
poll 模型
- poll 和 select在本质上没有差别,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。
- select 用 fdset 采用 bitmap,poll 用了数组。
- poll和 select同样存在一个缺点就是,文件描述符的数组被整体复制于用户态和内核态的地址空间之间,而不论这些文件描述符是否有事件,它的开销随着文件描述符数量的增加而线性增大。
- 还有 poll 返回后,也需要历遍整个描述符的数组才能得到有事件的描述符。
-
poll 函数和参数
#include <poll.h> int poll(struct pollfd *fdarray,unsigned long nfds,int timeout); struct pollfd{ int fd; //需要检测的文件描述符 short events; //请求的事件 short revents; //返回的事件 };
-
返回:若有就绪描述符则为其数目,若超时返回0,出错返回-1
第一个参数是指向一个结构体数组第一个元素的指针。每个元素都是一个pollfd结构,用于指定测试某个给定描述符fd的条件
-
-
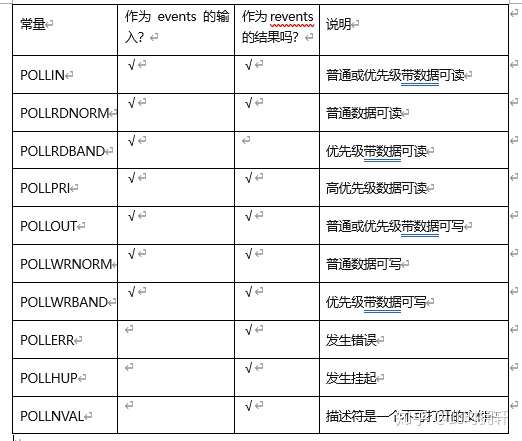
下表说明了能够作为events和revents的常量
结构体数组中元素的个数是由nfds参数指定。
timeout 参数指定poll函数返回前等待多长时间。它是一个指定应等待毫秒数的正值。取值如下表:
timeout值说明-1永远等待,直到有描述符就绪0立即返回,不阻塞进程>0等待指定的毫秒数
使用poll函数建立的服务器端如下:
// // Created by silver on 2020/8/23. // #include <stdio.h> #include <stdlib.h> #include <arpa/inet.h> #include <netinet/in.h> #include <sys/unistd.h> #include <sys/socket.h> #include <sys/types.h> #include <errno.h> #include <string.h> #include <sys/wait.h> #include <sys/select.h> #include <poll.h> #include <sys/stropts.h> #define MAXLINE 4096 #define PORT 9873 #define LISTQUE 1024 #define OPEN_MAX 256 int main(int argc,char* argv[]) { int listenfd,confd,sockfd; struct pollfd client[OPEN_MAX]; int nready; int maxcount = -1; int count = 0; char buf[MAXLINE]; struct sockaddr_in SerAddr,Cliaddr; socklen_t Clilen = sizeof(Cliaddr); //initializer bzero(&SerAddr,sizeof(SerAddr)); bzero(&Cliaddr,Clilen); bzero(buf,MAXLINE); listenfd = socket(AF_INET,SOCK_STREAM,IPPROTO_IP); SerAddr.sin_family = AF_INET; SerAddr.sin_port = htons(PORT); SerAddr.sin_addr.s_addr = htonl(INADDR_ANY); if (bind(listenfd,(struct sockaddr*)&SerAddr,sizeof(SerAddr)) < 0) { perror("Bind error"); } if (listen(listenfd,LISTQUE) < 0) { perror("listen error"); } client[0].fd = listenfd; client[0].events = POLLRDNORM; for (count = 1; count < OPEN_MAX; count++) { client[count].fd = -1; } maxcount = 0; ssize_t n; fputs("server waiting....",stdout); fflush(stdout); while(true) { nready = poll(client,maxcount +1,-1); if (client[0].revents & POLLRDNORM) // new client connection { confd = accept(listenfd,(struct sockaddr*)&Cliaddr,&Clilen); printf("client address: %s\n",inet_ntoa(Cliaddr.sin_addr)); if (confd < 0){ perror("accept error");} for (count = 1; count<OPEN_MAX ; count++) { if (client[count].fd < 0) { client[count].fd = confd; break; } } if (count == OPEN_MAX) {printf("too many clients");exit(-1);} client[count].events = POLLRDNORM; if (count > maxcount) maxcount = count; if (--nready <= 0) continue; //no more readable descriptions } for (count = 1; count <=maxcount ; count++) { if ((sockfd = client[maxcount].fd) < 0){ continue;} if(client[count].revents & (POLLRDNORM | POLLERR)) { n = read(sockfd,buf,MAXLINE); if (n < 0) { if (errno == ECONNRESET) { close(sockfd); client[count].fd = -1; } else { printf("read error"); exit(-1); } } else if (n == 0){ close(sockfd); client[count].fd = -1; } else{ writen(sockfd,buf,n); } } if (--nready <= 0) break; //no more readable descriptions } } close(listenfd); return 0; }
编辑于 2020-09-12
epoll 解决了select和poll 所有的问题(fdset拷贝和轮询),采用了最合理的设计和实现方案。
epoll在现在的软件中占据了很大的分量,nginx,libuv等单线程事件循环的软件都使用了epoll。之前分析过select,今天分析一下epoll。
们按照epoll三部曲的顺序进行分析。
asmlinkage long sys_epoll_create(int size)
{
int error, fd;
struct inode *inode;
struct file *file;
error = ep_getfd(&fd, &inode, &file);
error = ep_file_init(file);
return fd;
}我们发现create函数似乎很简单。 1 操作系统中,进程和文件系统是通过fd=>file=>node联系起来的。ep_getfd就是在建立这个联系。
static int ep_getfd(int *efd, struct inode **einode, struct file **efile)
{
// 获取一个file结构体
file = get_empty_filp();
// epoll在底层本身对应一个文件系统,从这个文件系统中获取一个inode
inode = ep_eventpoll_inode();
// 获取一个文件描述符
fd = get_unused_fd();
sprintf(name, "[%lu]", inode->i_ino);
this.name = name;
this.len = strlen(name);
this.hash = inode->i_ino;
// 申请一个entry
dentry = d_alloc(eventpoll_mnt->mnt_sb->s_root, &this);
dentry->d_op = &eventpollfs_dentry_operations;
file->f_dentry = dentry;
// 建立file和inode的联系
d_add(dentry, inode);
// 建立fd=>file的关联
fd_install(fd, file);
*efd = fd;
*einode = inode;
*efile = file;
return 0;
}形成一个这种的结构。
2 通过ep_file_init建立file和epoll的关联。
static int ep_file_init(struct file *file)
{
struct eventpoll *ep;
ep = kmalloc(sizeof(struct eventpoll), GFP_KERNEL)
memset(ep, 0, sizeof(*ep));
// 一系列初始化
file->private_data = ep;
return 0;
}epoll_create函数主要是建立一个数据结构。并返回一个文件描述符供后面使用。
asmlinkage long
sys_epoll_ctl(int epfd, int op, int fd, struct epoll_event __user *event)
{
int error;
struct file *file, *tfile;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
error = -EFAULT;
// 不是删除操作则复制用户数据到内核
if (
EP_OP_HASH_EVENT(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event))
)
goto eexit_1;
// 根据一种的图,拿到epoll对应的file结构体
file = fget(epfd);
// 拿到操作的文件的file结构体
tfile = fget(fd);
// 通过file拿到epoll_event结构体,见上面的图
ep = file->private_data;
// 看这个文件描述符是否已经存在,epoll用红黑树维护这个数据
epi = ep_find(ep, tfile, fd);
switch (op) {
// 新增
case EPOLL_CTL_ADD:
// 还没有则新增,有则报错
if (!epi) {
epds.events |= POLLERR | POLLHUP;
// 插入红黑树
error = ep_insert(ep, &epds, tfile, fd);
} else
error = -EEXIST;
break;
// 删除
case EPOLL_CTL_DEL:
// 存在则删除,否则报错
if (epi)
error = ep_remove(ep, epi);
else
error = -ENOENT;
break;
// 修改
case EPOLL_CTL_MOD:
// 存在则修改,否则报错
if (epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_modify(ep, epi, &epds);
} else
error = -ENOENT;
break;
}
}epoll_ctl函数看起来也没有很复杂,就是根据用户传进来的信息去操作红黑树。对于红黑树的增删改查,查和删除就不分析了。就是去操作红黑树。增和改是类似的逻辑,所以我们只分析增操作就可以了。在此之前,我们先了解一些epoll中其他的数据结构。
当我们新增一个需要监听的文件描述符的时候,系统会申请一个epitem去表示。epitem是保存了文件描述符、事件等信息的结构体。然后把epitem插入到eventpoll结构体维护的红黑树中。
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
{
int error, revents, pwake = 0;
unsigned long flags;
struct epitem *epi;
struct ep_pqueue epq;
// 申请一个epitem
epi = EPI_MEM_ALLOC()
// 省略一系列初始化工作
// 记录所属的epoll
epi->ep = ep;
// 在epitem中保存文件描述符fd和file
EP_SET_FFD(&epi->ffd, tfile, fd);
// 监听的事件
epi->event = *event;
epi->nwait = 0;
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
revents = tfile->f_op->poll(tfile, &epq.pt);
// 把epitem插入红黑树
ep_rbtree_insert(ep, epi);
// 如果监听的事件在新增的时候就已经触发,则直接插入到epoll就绪队列
if ((revents & event->events) && !EP_IS_LINKED(&epi->rdllink)) {
// 把epitem插入就绪队列rdllist
list_add_tail(&epi->rdllink, &ep->rdllist);
// 有事件触发,唤醒阻塞在epoll_wait的进程队列
if (waitqueue_active(&ep->wq))
wake_up(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
}新增操作的大致流程是 1 申请了一个新的epitem表示待观察的实体。他保存了文件描述符、感兴趣的事件等信息。 2 插入红黑树 3 判断新增的节点中对应的文件描述符和事件是否已经触发了,是则加入到就绪队列(由eventpoll->rdllist维护的一个队列) 下面具体看一下如何判断感兴趣的事件在对应的文件描述符中是否已经触发。相关代码在ep_insert中。下面单独拎出来。
/*
struct ep_pqueue {
// 函数指针
poll_table pt;
// epitem
struct epitem *epi;
};
*/
struct ep_pqueue epq;
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
revents = tfile->f_op->poll(tfile, &epq.pt);
static inline void init_poll_funcptr(poll_table *pt, poll_queue_proc qproc)
{
pt->qproc = qproc;
}上面的代码是定义了一个struct ep_pqueue 结构体,然后设置他的一个字段为ep_ptable_queue_proc。然后执行tfile->f_op->poll。poll函数由各个文件系统或者网络协议实现。我们以管道为例。
static unsigned int
pipe_poll(struct file *filp, poll_table *wait)
{
unsigned int mask;
// 监听的文件描述符对应的inode
struct inode *inode = filp->f_dentry->d_inode;
struct pipe_inode_info *info = inode->i_pipe;
int nrbufs;
/*
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && wait_address)
p->qproc(filp, wait_address, p);
}
*/
poll_wait(filp, PIPE_WAIT(*inode), wait);
// 判断哪些事件触发了
nrbufs = info->nrbufs;
mask = 0;
if (filp->f_mode & FMODE_READ) {
mask = (nrbufs > 0) ? POLLIN | POLLRDNORM : 0;
if (!PIPE_WRITERS(*inode) && filp->f_version != PIPE_WCOUNTER(*inode))
mask |= POLLHUP;
}
if (filp->f_mode & FMODE_WRITE) {
mask |= (nrbufs < PIPE_BUFFERS) ? POLLOUT | POLLWRNORM : 0;
if (!PIPE_READERS(*inode))
mask |= POLLERR;
}
return mask;
}我们看到具体的poll函数里会首先执行poll_wait函数。这个函数只是简单执行struct ep_pqueue epq结构体中的函数,即刚才设置的ep_ptable_queue_proc。
// 监听的文件描述符对应的file结构体,whead是等待监听的文件描述符对应的inode可用的队列
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = EP_ITEM_FROM_EPQUEUE(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = PWQ_MEM_ALLOC())) {
pwq->wait->flags = 0;
pwq->wait->task = NULL;
// 设置回调
pwq->wait->func = ep_poll_callback;
pwq->whead = whead;
pwq->base = epi;
// 插入等待监听的文件描述符的inode可用的队列,回调函数是ep_poll_callback
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}主要的逻辑是把当前进程插入监听的文件的等待队列中,等待唤醒。
asmlinkage long sys_epoll_wait(int epfd, struct epoll_event __user *events,
int maxevents, int timeout)
{
int error;
struct file *file;
struct eventpoll *ep;
// 通过epoll的fd拿到对应的file结构体
file = fget(epfd);
// 通过file结构体拿到eventpoll结构体
ep = file->private_data;
error = ep_poll(ep, events, maxevents, timeout);
return error;
}
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res, eavail;
unsigned long flags;
long jtimeout;
wait_queue_t wait;
// 计算超时时间
jtimeout = timeout == -1 || timeout > (MAX_SCHEDULE_TIMEOUT - 1000) / HZ ?
MAX_SCHEDULE_TIMEOUT: (timeout * HZ + 999) / 1000;
retry:
res = 0;
// 就绪队列为空
if (list_empty(&ep->rdllist)) {
// 加入阻塞队列
init_waitqueue_entry(&wait, current);
add_wait_queue(&ep->wq, &wait);
for (;;) {
// 挂起
set_current_state(TASK_INTERRUPTIBLE);
// 超时或者有就绪事件了,则跳出返回
if (!list_empty(&ep->rdllist) || !jtimeout)
break;
// 被信号唤醒返回EINTR
if (signal_pending(current)) {
res = -EINTR;
break;
}
// 设置定时器,然后进程挂起,等待超时唤醒(超时或者信号唤醒)
jtimeout = schedule_timeout(jtimeout);
}
// 移出阻塞队列
remove_wait_queue(&ep->wq, &wait);
// 设置就绪
set_current_state(TASK_RUNNING);
}
// 是否有事件就绪,唤醒的原因有几个,被唤醒不代表就有就绪事件
eavail = !list_empty(&ep->rdllist);
write_unlock_irqrestore(&ep->lock, flags);
// 处理就绪事件返回
if (!res && eavail &&
!(res = ep_events_transfer(ep, events, maxevents)) && jtimeout)
goto retry;
return res;
}总的来说epoll_wait的逻辑主要是处理就绪队列的节点。 1 如果就绪队列为空,则根据timeout做下一步处理,可能定时阻塞。 2 如果就绪队列非空则处理就绪队列,返回给用户。处理就绪队列的函数是ep_events_transfer。
static int ep_events_transfer(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
int eventcnt = 0;
struct list_head txlist;
INIT_LIST_HEAD(&txlist);
if (ep_collect_ready_items(ep, &txlist, maxevents) > 0) {
eventcnt = ep_send_events(ep, &txlist, events);
ep_reinject_items(ep, &txlist);
}
return eventcnt;
}主要是三个函数,我们一个个看。 1 ep_collect_ready_items收集就绪事件
static int ep_collect_ready_items(struct eventpoll *ep, struct list_head *txlist, int maxevents)
{
int nepi;
unsigned long flags;
// 就绪事件的队列
struct list_head *lsthead = &ep->rdllist, *lnk;
struct epitem *epi;
for (nepi = 0, lnk = lsthead->next; lnk != lsthead && nepi < maxevents;) {
// 通过结构体字段的地址拿到结构体首地址
epi = list_entry(lnk, struct epitem, rdllink);
lnk = lnk->next;
/* If this file is already in the ready list we exit soon */
if (!EP_IS_LINKED(&epi->txlink)) {
epi->revents = epi->event.events;
// 插入txlist队列,然后处理完再返回给用户
list_add(&epi->txlink, txlist);
nepi++;
// 从就绪队列中删除
EP_LIST_DEL(&epi->rdllink);
}
}
return nepi;
}2 ep_send_events判断哪些事件触发了
static int ep_send_events(struct eventpoll *ep, struct list_head *txlist,
struct epoll_event __user *events)
{
int eventcnt = 0;
unsigned int revents;
struct list_head *lnk;
struct epitem *epi;
// 遍历就绪队列,记录触发的事件
list_for_each(lnk, txlist) {
epi = list_entry(lnk, struct epitem, txlink);
// 判断哪些事件触发了
revents = epi->ffd.file->f_op->poll(epi->ffd.file, NULL);
epi->revents = revents & epi->event.events;
// 复制到用户空间
if (epi->revents) {
if (__put_user(epi->revents,
&events[eventcnt].events) ||
__put_user(epi->event.data,
&events[eventcnt].data))
return -EFAULT;
// 只监听一次,触发完设置成对任何事件都不感兴趣
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
eventcnt++;
}
}
return eventcnt;
}3 ep_reinject_items重新插入就绪队列
static void ep_reinject_items(struct eventpoll *ep, struct list_head *txlist)
{
int ricnt = 0, pwake = 0;
unsigned long flags;
struct epitem *epi;
while (!list_empty(txlist)) {
epi = list_entry(txlist->next, struct epitem, txlink);
EP_LIST_DEL(&epi->txlink);
// 水平触发模式则一直通知,即重新加入就绪队列
if (EP_RB_LINKED(&epi->rbn) && !(epi->event.events & EPOLLET) &&
(epi->revents & epi->event.events) && !EP_IS_LINKED(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ricnt++;
}
}
}我们发现,并有没有在epoll_wait的时候去收集就绪事件,那么就绪队列是谁处理的呢?我们回顾一下插入红黑树的时候,做了一个事情,就是在文件对应的inode上注册一个回调。当文件满足条件的时候,就会唤醒因为epoll_wait而阻塞的进程。epoll_wait会收集事件返回给用户。
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
struct epitem *epi = EP_ITEM_FROM_WAIT(wait);
struct eventpoll *ep = epi->ep;
// 插入就绪队列
list_add_tail(&epi->rdllink, &ep->rdllist);
// 唤醒因epoll_wait而阻塞的进程
if (waitqueue_active(&ep->wq))
wake_up(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
return 1;
}epoll的实现涉及的内容比较多,先分析一下大致的原理。有机会再深入分析。
发布于 2020-03-28