相识 漫长 了解 靠近 倾心 惊讶 窃喜 慌张 担忧 逃避 试探 渴望 纠结 快乐 小心 假装 疑惑 关于 决定 真心 勇气 承认 庆幸 期待 相信 沉迷 疯狂 幻境 极致 依赖 冷淡 哽咽 心酸 错过 自嘲 痛苦 绝境 极端 迷茫 无奈 摧毁 失败 失望 狠心 缓解 否定 浮沉 人海 真实 早睡 祝好 所谓 爱情 皆与此













- 2️⃣0️⃣2️⃣0️⃣➖3️⃣➖4️⃣〰️3️⃣➖8️⃣
- 2️⃣0️⃣2️⃣0️⃣➖3️⃣➖9️⃣〰️3️⃣➖1️⃣2️⃣
- 2️⃣0️⃣2️⃣0️⃣➖3️⃣➖1️⃣3️⃣〰️3️⃣➖1️⃣6️⃣
- 2️⃣0️⃣2️⃣0️⃣➖3️⃣➖1️⃣7️⃣
- 2️⃣0️⃣2️⃣0️⃣➖3️⃣➖1️⃣8️⃣
- 2️⃣0️⃣2️⃣0️⃣➖3️⃣➖1️⃣9️⃣〰️3️⃣➖2️⃣0️⃣
- 2️⃣0️⃣2️⃣0️⃣➖3️⃣➖2️⃣1️⃣
- 2️⃣0️⃣2️⃣0️⃣➖3️⃣➖2️⃣2️⃣〰️3️⃣➖2️⃣9️⃣
- 2️⃣0️⃣2️⃣0️⃣➖3️⃣➖3️⃣0️⃣〰️4️⃣➖1️⃣
- 2️⃣0️⃣2️⃣0️⃣➖4️⃣➖2️⃣〰️4️⃣➖1️⃣3️⃣
- 2️⃣0️⃣2️⃣0️⃣➖4️⃣➖1️⃣4️⃣〰️4️⃣➖1️⃣9️⃣
- 2️⃣0️⃣2️⃣0️⃣➖4️⃣➖2️⃣0️⃣〰️4️⃣➖3️⃣0️⃣
- 2️⃣0️⃣2️⃣0️⃣➖5️⃣➖1️⃣〰️5️⃣➖1️⃣2️⃣
- 2️⃣0️⃣2️⃣0️⃣➖5️⃣➖1️⃣3️⃣〰️6️⃣➖5️⃣
- 2️⃣0️⃣2️⃣0️⃣➖6️⃣➖6️⃣〰️7️⃣➖3️⃣
- 2️⃣0️⃣2️⃣0️⃣➖7️⃣➖4️⃣〰️7️⃣➖1️⃣3️⃣
- 2️⃣0️⃣2️⃣0️⃣➖7️⃣➖1️⃣4️⃣
- 2️⃣0️⃣2️⃣0️⃣➖7️⃣➖1️⃣5️⃣
- 2️⃣0️⃣2️⃣0️⃣➖7️⃣➖1️⃣6️⃣
- 2️⃣0️⃣2️⃣0️⃣➖7️⃣➖1️⃣7️⃣〰️8️⃣➖7️⃣
- 2️⃣0️⃣2️⃣0️⃣➖8️⃣➖8️⃣〰️8️⃣➖1️⃣2️⃣
- 2️⃣0️⃣2️⃣0️⃣➖8️⃣➖1️⃣3️⃣〰️8️⃣➖1️⃣7️⃣
- 2️⃣0️⃣2️⃣0️⃣➖8️⃣➖1️⃣8️⃣〰️9️⃣➖1️⃣
- 2️⃣0️⃣2️⃣0️⃣➖9️⃣➖2️⃣〰️2️⃣0️⃣2️⃣1️⃣➖4️⃣➖2️⃣
- 2️⃣0️⃣2️⃣1️⃣➖4️⃣➖3️⃣〰️4️⃣➖1️⃣5️⃣
- 2️⃣0️⃣2️⃣1️⃣➖4️⃣➖1️⃣6️⃣
- 2️⃣0️⃣2️⃣1️⃣➖4️⃣➖1️⃣7️⃣
- 2️⃣0️⃣2️⃣1️⃣➖4️⃣➖1️⃣8️⃣〰️4️⃣➖2️⃣3️⃣
- 2️⃣0️⃣2️⃣1️⃣➖4️⃣➖2️⃣4️⃣〰️4️⃣➖3️⃣0️⃣
- 2️⃣0️⃣2️⃣1️⃣➖5️⃣➖1️⃣〰️5️⃣➖1️⃣1️⃣
- 2️⃣0️⃣2️⃣1️⃣➖5️⃣➖1️⃣2️⃣〰️5️⃣➖1️⃣3️⃣
- 2️⃣0️⃣2️⃣1️⃣➖5️⃣➖1️⃣4️⃣〰️5️⃣➖1️⃣6️⃣
- 2️⃣0️⃣2️⃣1️⃣➖5️⃣➖1️⃣7️⃣〰️5️⃣➖1️⃣8️⃣
- 2️⃣0️⃣2️⃣1️⃣➖5️⃣➖1️⃣9️⃣〰️5️⃣➖2️⃣2️⃣
- 2️⃣0️⃣2️⃣1️⃣➖5️⃣➖2️⃣3️⃣〰️5️⃣➖2️⃣5️⃣
- 2️⃣0️⃣2️⃣1️⃣➖5️⃣➖2️⃣6️⃣〰️6️⃣➖5️⃣
- 2️⃣0️⃣2️⃣1️⃣➖6️⃣➖6️⃣〰️6️⃣➖2️⃣2️⃣
- 2️⃣0️⃣2️⃣1️⃣➖6️⃣➖2️⃣3️⃣〰️7️⃣➖4️⃣
- 2️⃣0️⃣2️⃣1️⃣➖7️⃣➖5️⃣〰️7️⃣➖1️⃣0️⃣
- 2️⃣0️⃣2️⃣1️⃣➖7️⃣➖1️⃣1️⃣〰️8️⃣➖1️⃣6️⃣
13号参加了农行的培训,从14号到8月9号开始了为期不到一个月的农行科技岗实习,由于疫情不得不提前终止,总结就是学了vue和vant组件,画了个互联网预约的手机前端页面。
14号的组会具体细节我已经记不清了,小治表示第二篇论文与大论文的框架搭好了,我表示我准备开始写作了。
15号,大概是这天真正开始论文的写作,开始研究代码,准备开始写作,等不及了这就开始,原本以为7月的底能写完,这不已经8中旬了,原本计划好的一切总是在杯打乱,有的是因为其他事情,有的是因为心态被牵制了,无法投入。
21号的组会,我又不是记得很清楚,总之又是一个在实验室开的组会。
27号,今天论文主要还是看了很久,没写什么东西,看了好几篇文章的结构,然后改了一下写作的方向。最后下定决心,就是那样写,然后完成了预备知识的布局,以及后面几章的布局。由于昨天晚上小治说今天台风真正入境,所以今天请了个小假。但其实早上起来看,反而没下雨。
28号,组会。旺旺继续介绍了Vivaldi算法以及代码的复现情况,目前的困难就是很多代码的用js写成的,可能还需要npm环境。浩浩介绍了gossip的调研,分析了很多模拟器用来模拟网络环境。邱珍分享了自己关于倒排压缩的疑问,当然依然得不到有效解答。宝俊意外地远程加入了战斗,表达了归校之情。靖靖口头分享了关于近期的工作,关于算法的实现和刷题,以及实现了一个简单的聊天功能。我立下flag20秒结束战斗,当然确实没有那么快,但也是很快了,自己的论文概况,准备接下来怎么水,立下军令状,这一周完成论文,就像搭积木。翔哥分享了最近看的论文,以及准备投稿的杂志以及自己的论文写作情况,字码得差不多了就差积木搭起来了。
终究7月底没有完成我的目标,原因除了归咎于自己没有他法,更多的是我一直牵挂着她,没法专注于自己的事情,这是病态的。
8.4,这一次组会我没法参加,因为昨天的事情让我失魂,我的心思都在如何挽救上面。
8.11,组会日。到了实验室几乎正好6点30,刚进实验室翔哥就是一句两个礼拜了怎么说啊。然后又是历史性的在实验室开的组会,靖靖交代了这周主要是刷题。我分享了关于论文最新的写作情况,主要是画了个第二张的图。老朱分享了关于论文还没被接收的情况。钱慧最近论文退修的成果,主要是缺少数学公式,准备二次投稿。浩浩分享了最近读的论文还是上次聊过的gossip论文,翔哥别再看了,赶紧写。邱珍分享了关于图相似度搜索的PPT,众人表示很厉害,不是很懂,可以研究一下。旺旺分享了关于空间坐标的最新代码复现情况。宝俊压轴登场分享了关于自己读的联邦学习论文已经自己读的论文。最后听到我饿得不行,翔哥表示论文本来8月能够搞定, 现在又要帮老板搞项目了。
| 组会与农行 | |
|---|---|
| 7.7组会 | 8.11组会 |
 |
 |
| 农行计算机中心 | 广电靴子楼 |
 |
 |
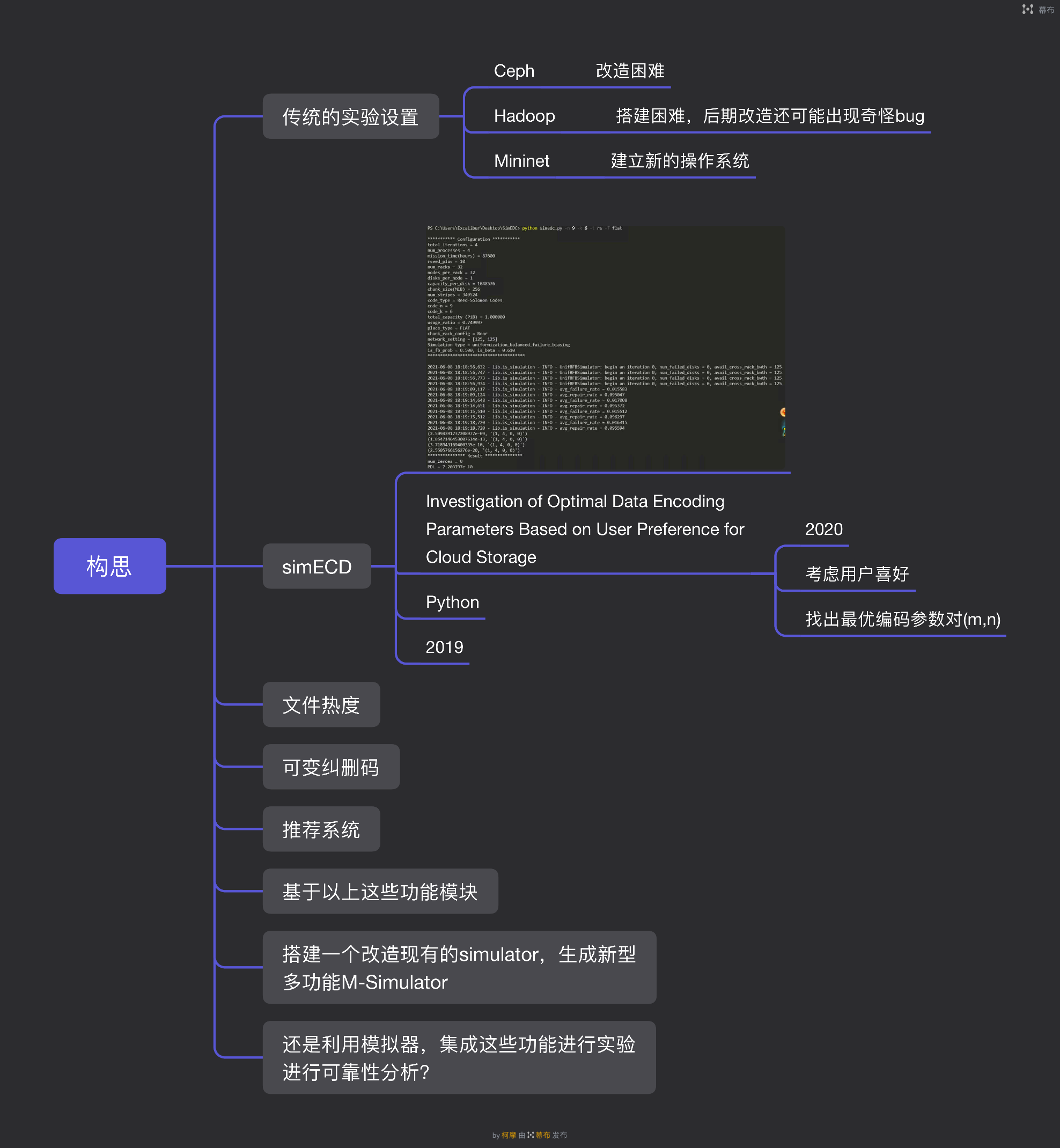
5号,开始继续仔细研究《SimEDC: A Simulator for the Reliability Analysis of Erasure-CodedData Centers 》。还没吃透它本身的代码和论文,主要目标还是在代码的上层和一些接口上加入文件修复顺序以及用户偏好度等相关的想法。
6号。这一天起床太早,导致一天迷迷糊糊。
7号,今天的组会头一次在实验室开。首当其冲的是小治上来发言,爷爷住院,所以没有什么明显的学习上的进展。接下来的是翔哥,翔哥表示除了帮老师写材料,看了点IPFS的libswap的代码就没什么其他的了。然后我主要分享了一下关于指静脉项目的制作过程,基本上将我这几天遇到的问题和盘托出,满足了特征可以保存的需求同时问题也转化为如何提升准确率。宝俊主要分享了最近搭建TF的联邦学习环境以及相关demo即最简单的手写数字识别的过程。旺旺分享了自己关于维瓦尔第空间坐标最新的复现进展,以及跳得太远回不来的问题等一系列其他信息。浩浩分享了自己关于Testground的报告的研读情况。
8号,有了一些想法但不是很具体,我的纠结之处在于到底是基于SimEDC做可靠性分析,还是基于SimEDC改进,创造一个新的SimEDC。另外一个问题就是达到系统最优和用户体验最优,这个东西应该起什么样的名字。
9号,注册了《网络与信息安全学报》的作者,准备开始直接写文章,下载了几篇他们的论文,这些论文包括跟我的领域无关的但是下载量大能够代表他们期刊水平的,跟我领域相关的可以模仿的。这样行文的格式有了,相关领域的在这个期刊上研究的内容也有了。
10号,基本上是停滞不前的状态,还需要一些更多的思考。
23号,码字,基本上是码字。
24号,加油。
25号,在外面。
26号,打球。
27号,研会聚餐。
28号,码字。
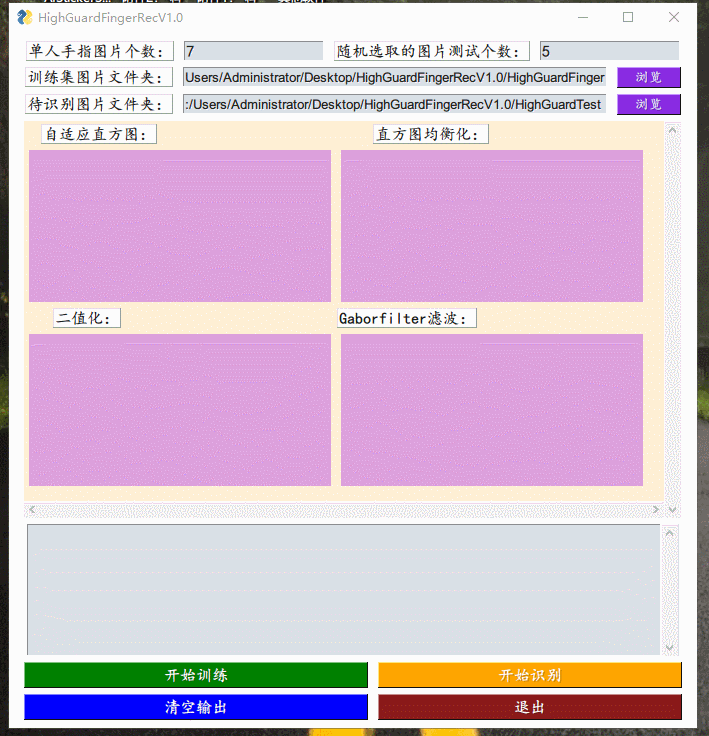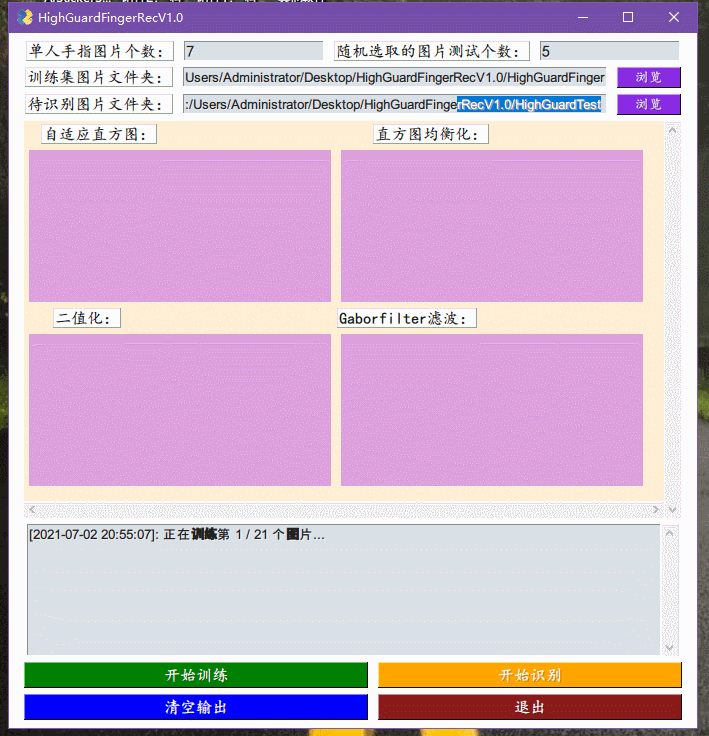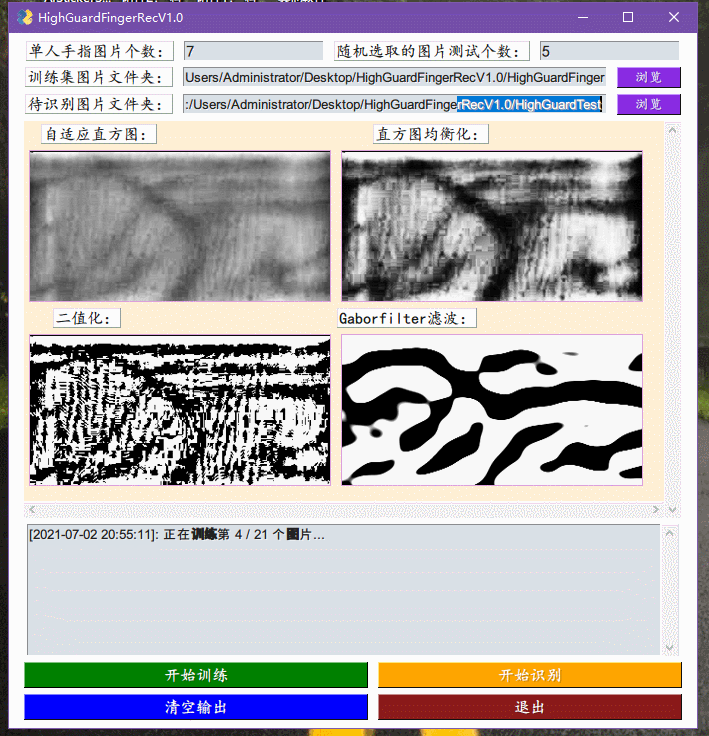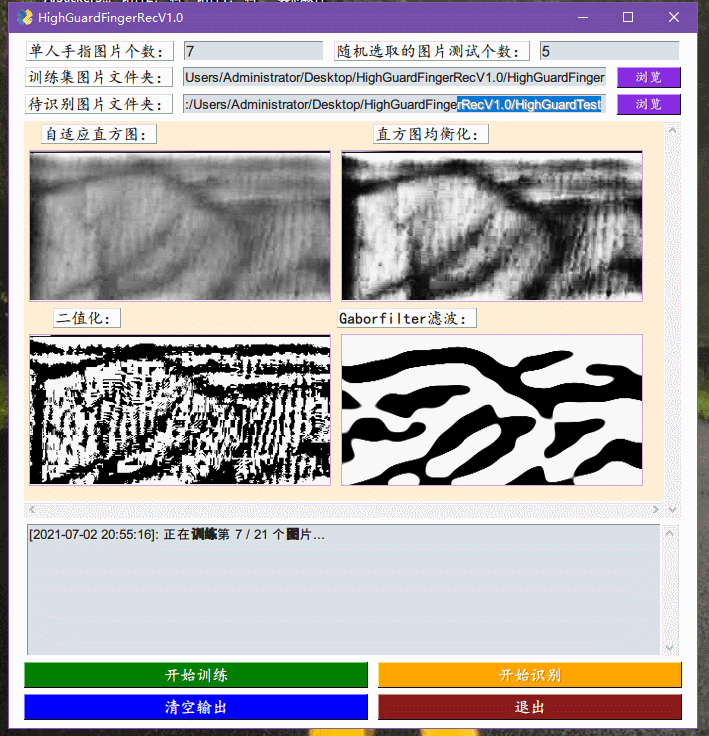
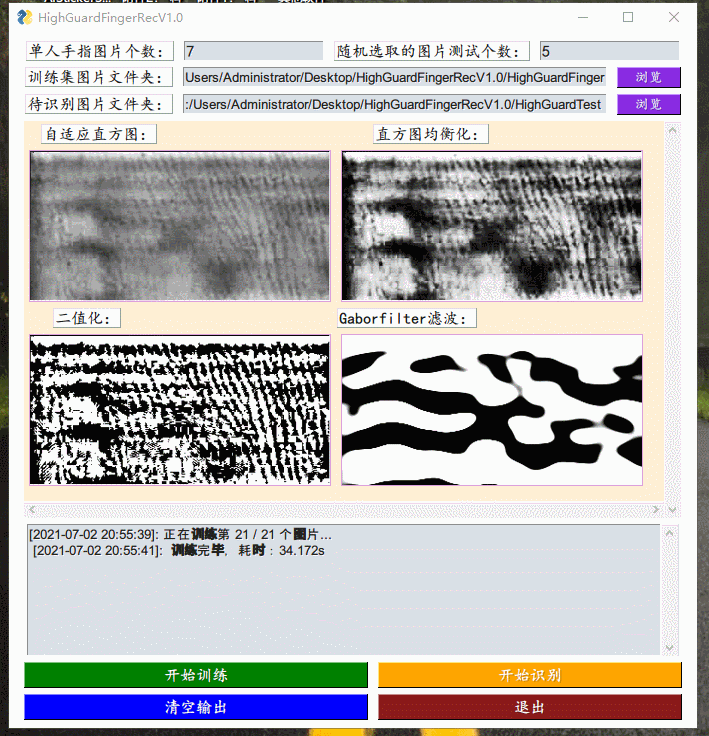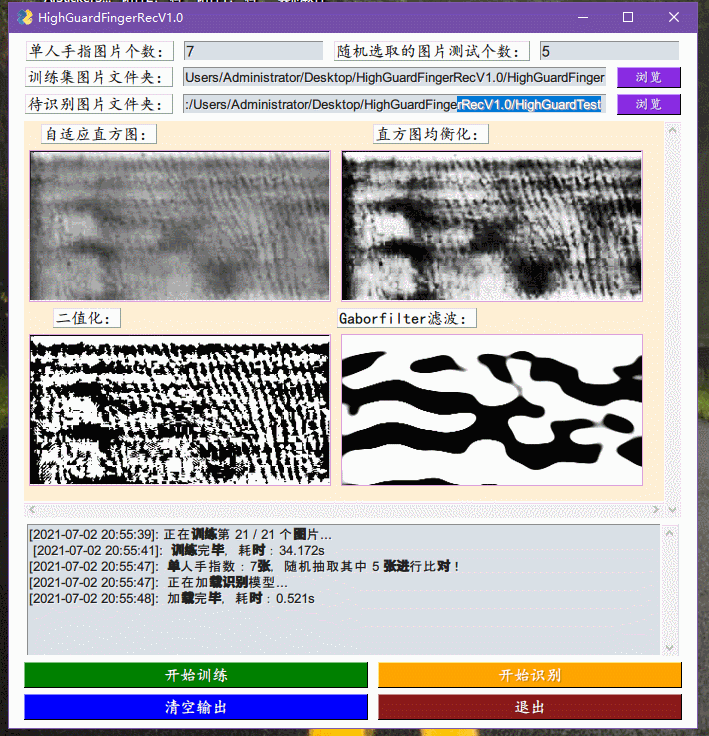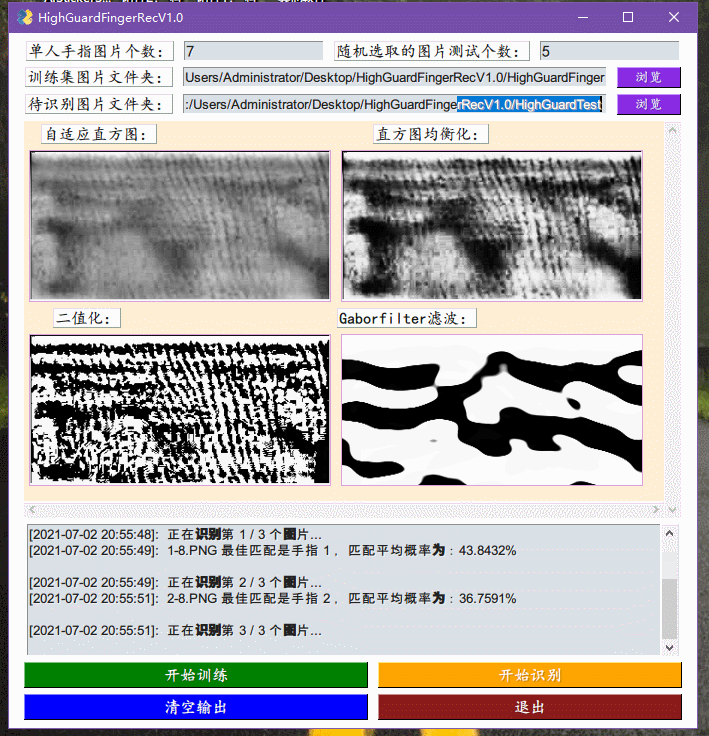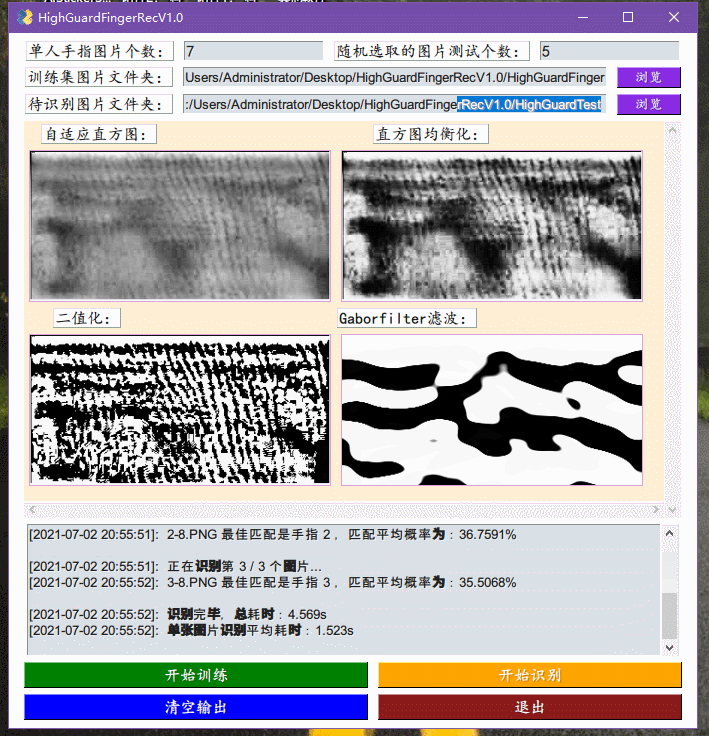
29号,开始了指静脉代码的MATLAB转Python的工作。遇到的主要困难在于自适应直方图以及直方图均衡化、二值化等在MATLAB就是一个函数加参数的问题,但在Python找到对应的却有点难,不一定有还需要自己实现,即使实现了处理的效果的图像的与MATLAB缺不尽相同。调节了很多次参数,也达不到一模一样的效果,后来思考了一下,也许并不需要一样,毕竟也没人说MATLAB处理出来的图像就更好,就算更好对于识别任务也并不是一定是最优的,也许Python带着不同参数处理出来的图像更加适合识别任务也未可知。女友在学校住的最后一天。
30号,上午继续写指静脉代码,在实现了上述的三个处理函数之后,最后就是要实现Gaborfilter滤波函数了。这个在原本的MATLAB中也是一个自己实现的函数,其中涉及了复数运算以及2维卷积,幸亏在opencv中有对应的卷积实现,那么就暂且不提,麻烦的问题就在于Pyhton中复数与float无法直接运算,因为函数中有exp里面包着复数的运算式,导致一直出错。后来经宝俊指点才发现一个致命问题,看的文章中是由于cmath库中导入的exp而不是math中的导入的,一直没有注意到,加了个c之后马上就跑通了,在这里要特别感谢一下宝俊!然后一查才发现cmath与math的区别就在于cmath加入了对复数运算各种优化的内容。下午帮女友搬家,以及众人开组会,然后我们逛新华书店,看《hello world》。
1号,上午观看建党100周年大会,伟大,光荣,正确的中国共产党万岁!伟大,光荣,英雄的中国人民万岁!下午继续改进Python代码,目前完成了图像处理训练模块的内容,在我的设想中处了识别模块之外,应该还有GUI界面以及模型改进。今天实现的应该是识别算法中最重要的内容,原MATLAB中效果最好的方法就是「归一化二维互相关模板匹配算法」,具体的在MATLAB中就是normXcorr2这个函数,摸索了好久才找到opencv对应的函数就TemplateMatch。有人也专门比较过他们的区别,主要在于返回值的这里,看名字就知道TemplateMatch指的就是模板匹配,它的作用就是在大图中找小图的位置,但事实上我们要实现的功能暂且称之为找两张图片的相似度(因为两张指静脉的相似是否就能认为是同一个人的指静脉尚且还需要研究)。所以TemplateMatch其实并不适合这个任务,并且我在debug过程中发现,它要求两张图片大小不一致,必须一大一小,那就有点强人所难,赶紧作罢,转投他路。在各种网上冲浪中,我发现有一个用烂了的VGG16也许适合这个任务,后来还发现了VGG19,好像效果更好一点,并且还发现有一些指静脉的论文也提到了VGG16-modified用来进行识别任务,说明还是有用的模型。用上官方的预训练模型,发现效果还不错,识别率挺高,可能后续的改进就是如何针对这个特定的任务,抽取更加有针对的特征,然后提升识别速度,毕竟这个预训练的参数并不是拿这些指静脉图片进行训练的,但是说起来目前的指静脉图片并不多,我估计最起码得有个几千张的样子。不过用上VGG16之后,保存识别之后的特征成为了可能,也就是每次比较两张图片是否相似就是比较两个特征向量的余弦值,对一个图片进行VGG16处理,得到它的特征向量就可以保存为文件,每多一张图片就读取这个特征向量文件然后进行写入再存储就可以无限快速地进行比较了。
2号,昨晚想一鼓作气实现GUI框架结束整个的工作,但还是觉得可能会扰乱整个工程的美感。今天来完成了指静脉软件的初版,整合了之前实现了训练模块,加入了VGG16的识别模块,以及实现了对应的GUI框架:ExcaliburEX/FingerveinRecognition简单地debug了几次,虽然一定存在着各种奇怪的错误情况,但大体上应该是比较能工作的,主要问题就是识别速度还是太慢,因为一张图片的识别过程包括了对图片进行,自适应直方图,直方图均衡化,二值化,Gaborfilter滤波处理,然后再丢入VGG16进行处理,得到特征向量,然后将这个特征项里与已经识别的图片的特征向量集里面一个一个地比较,得到一个平均相似度最大的手指得出结果。
3号,在后续的使用中发现,在任何一台机器上,VGG16第一次启动过程中需要下载位于github上的预训练模型,有可能因为网络问题导致下载失败,所以开始研究如何本地加载预训练模型之路。后来发现是可以再本地加载的,传递算法文件的同时,还带上50~70M的预训练模型会导致整个工程会非常大,所以研究是否可以将模型文件传递到自己的腾讯云OSS桶,然后写个下载函数实现自动在加载模型前自动下载。
4号,发现keras其实自带VGG19,比VGG16性能提升了一些,但其实只是学术上提升,在工业上那点提升其实没什么区别,但是寻求心理安慰还是修改成了VGG19,预训练模型由50M变成了70M。由于对于输出控制的强迫症,我已经实现了昨天说的在自己云端存储模型文件以及下载逻辑,但是下载进度条一直出现显示BUG,一度各种调整,调了几乎一天吧。虽然其实这个东西卵用没有,只是为了好看而已。核心问题还是由于太慢,如何改进暂时还不知道。
 |
 |
6号,几乎是完成了kemo项目的更新。服务器搭建了TensorFlow的环境。
7号,阅读《Investigation of Optimal Data Encoding Parameters Based on User Preference for Cloud Storage》。
8号,下午跟宝马dd和靖靖一起讨论了一波他新闻搜索引擎项目的前端问题,如何在展示搜索结果之后点击按热度还是按照时间顺序,点击这些按钮之后如何重新排序搜索结果并进行展示。阅读《Investigation of Optimal Data Encoding Parameters Based on User Preference for Cloud Storage》。
9号,组会日。先跟老板翔哥一起开会讨论了下指静脉的事情,我也不知道我为什么突然成为了算法实现的主要负责人。就让我实现将现有的MATLAB程序编译成win上可带参数跑的.exe程序,后期还要是实现终端上的基于open-cv的C版本,我只表示:难顶。组会上,靖靖分享了昨天我们讨论过的新闻搜索引擎的前后端展示,按照不同选项排序的功能已经实现,倒排索引压缩任重而道远。我讲了一下我论文的构思,得到的结论就是先根据现有的模拟器进行可靠性分析。小治,表示我只有两句话,第一论文投出去了,第二这周看了篇论文,说完就想跑,众人只说:水,又得回来讲论文,虽然众人又表示听不懂不想听,总之就是很难啊。浩浩分享了关于gossip最新的实验的进展。慧慧只说论文投出去再进行后续分享。宝俊分享了近期的两门课程的结课情况,完成了分布式与并行计算的作业后期要完成ctex的报告撰写,机器学习的展示还在准备,并行了近期论文的分享。剩下就是关于各自情况的汇报,翔哥表示批3000,买个程序回来跑,慧慧表示3000淘宝压根买不到。翔哥分享了关于同样配置的ipfs节点在网络中互相替代的可能性,以及Testground测试环境的展示,展示了半年。回来跟宝俊搞了一会儿Ctex模板,一直编译不成功,搞不清楚什么问题,后来才发现minted包有问题,其实没有代码高亮也可以,但是这就不够炫酷了,失去了latex的美丽。
10号,上午帮宝马dd研究了一波ctex,minted包一直出错导致编译不成功,后来直接不要minted包来包装代码高亮就成功了。下午主要是打了一下第二针疫苗,报了一下人工智能创新大赛的应用创新组。
11号,利用Microsoft TODO制作了每日清单,我的需求就是每天会更新的清单,等我勾选完之后,第二天又会出现的那种,之前没用好,今天发现它确实有这个功能。
12号,端午假期第一天。
13号,端午假期第二天。
14号,端午假期第三天。
15号,帮轨交院的陈同学继续修缮了遗传算法,自答应她以来已经过了40多天了,实在不能拖了,不过她这个东拼西凑的模型真的四不像。
16号,组会日。搞了一天的MATLAB打包,一开始的解决方案是封装起来包成python包,然后用python导入进而使用,几乎是不行,而且要调用MATLAB非常慢。第二版方案就是打包成exe,但是需要在线下载MATLAB RUNTIME,而且打包出来的exe非常大。后来演示的时候还是采用源代码运行,但是在MAC上无法调用GPU,普通windows上也需要安装CUDA才能进行指静脉识别,最后改成了CPU版本,但其实速度上并没有改变多少。下一步计划,可能是需要改写成Python版本的,但是就算是改写成功了,目前的这种算法速度也是上不去的,就算是上去了,Python代码也无法在终端上运行,所以除了C版本,其他都是没用的。老板不在的情况下,组会稍显水了一点,真的是每个人一句话,解决了战斗,翔哥继续分享了一下自己关于Testground的使用心得,戴佬也回来了,项目可以继续进行了。
17号,完成了vivo的笔试。
18号,继续修缮AIStickerSearcher。
19号,今天主要是下午帮cyq的宿舍拍了一下午毕业照。晚上去独墅湖看了一场2021毕业晚会,拿了很多文创礼品,不说了,难忘之夜。
20号,继续修缮AIStickerSearcher,发现request请求https一直显示ssl证书不可用的错误,搞了半天,最后发现只有用vscode才有这个问题,换成spyder或者pycharm都没有这个错误,心塞。下午打了一下午球,晚上跟昆仑撸了一会儿,乌雕云说是不玩,但又要看直播,我们就开了一个腾讯会议,我共享屏幕,他在那当云解说员。
21号,完成了AIStickerSearcher项目的修缮,基本实现了在线统计功能,多线程优化搜索,以及识别与完善的推出功能。晚上进行了VIVO提前批的面试。
22号,接女友加毕业典礼,几乎全天在外面。上午修改了一下磁链搜索器,准备把它打包成exe。
 |
- 刷题!
26号,组会日。继续看《Fast Predictive Repair in Erasure-Coded Storage》数学理论部分,论证了最小二分匹配。翔哥分享了关于利用bootstrap搭建的节点广域与局域的连接。宝骏分享了关于联邦学习的阅读。慧慧分享了自己论文根据审稿人意见修订的新实验思路,重新定义吞吐量。我分享了关于指静脉算法的实现以及论文的阅读,其中提到了关于基金号的支撑以及《网络与信息安全学报》与我们实验室的关系。浩浩说是还在继续阅读论文。张维娜关于论文的阅读。邱珍关于论文的现场疑问解答。小治关于论文以及考公的分享。旺旺关于空间地图论文的有一次分享。婷婷学姐关于发论文的感想,原来就是我去年夏天提到的,不要想,现在就动手去写去敲代码,写着写着就会有灵感了。剩下的就是与老板讨论关于指静脉仪商用的事情了,已经有产品型号了。。
27号,这一天我主要还是优化了一下指静脉的MATLAB算法实现。基本上在win上运行已经不成问题了,识别精度识别速度在显卡的加持上都可以接受。
28-29,摸鱼。
30号,继续研读《一种混合局部恢复码及 Hitchhiker 码的存储策略》,思考是否可以将编码切换与预测修复结合。
31号,想在fastpr的源代码中加入接口。开始了论文的撰写,研究了很多相关论文的目录。挑选了几个比较具有代表新的论文目录,并进行杂糅成我的目录。
6.1,继续研究fastPR的代码,感觉有几个修复入口,fastpr,Migration以及random修复,或许我还可以再加入一个修复方案。开始准备修改代码,但是想着还是先编译一下他们的源码,运行看看效果。Hadoop始终编译不成功,明天再看看具体情况.
2号,组会日。翔哥介绍了下自己关于IPFS节点连接的研究以及一个TestGround平台搭建的情况。剩下每个人大概地介绍了下各自的最近工作,倒也没什么特别的就是了。靖靖介绍了下新闻搜索引擎,小治介绍了最近看的论文...
3-4号,摸鱼。
5号,开始改变策略,想一想即使Hadoop成功搭建出来了,后续还不知道出现多少BUG,而且写c也很麻烦,即使有想法也无法实现。决定还是开始使用Python做一些模拟类别的文章,我想这样还是走了我之前老路的一些想法。
- 刷题!
23号,大概是同等学力监考一天,跟护理学院的同学聊了她所经历的汶川地震与护士生活。
24号,跟言的师兄师弟在星海来了一场酣畅淋漓的羽球大战,我差点以为都是大佬,亚历山大。此外研究了一下指静脉找到的Python代码:FingerVeinApi、hardnet_triplet和C代码:Finger,Python代码一般实现是基于神经网络或者数学方法,但是深度学习方法的数据集申请不到,数学方法没有Python实现,无法复现。
25号,编译了一会儿C代码,但是总是出现一堆bug,win上显示指针有问题,Ubuntu上总是报undefined referenced的错误,还是联合编译的问题,或许还有c标准的问题,因为有些库函数无法识别,配置了一会儿RTX 2070的服务器,想要使用它远程jupyter服务,但是只要重启就黑屏只能还原快照,多次重启再还原快照就再也无法开机,只能重启ESXi主机。本来是不用重启就可以一直用的,但是欠打的是更新了一下源,导致显卡驱动版本跟支持的版本不一致无法调用,那这就是个普通的Ubuntu,一点用没有,只能重启,一旦重启就没,就很淦。继续《Fast Predictive Repair in Erasure-Coded Storage》,这是一篇关于纠删码预测修复的文章,主要目标就是预测即将失效的节点即STF node(Soon-To-Fail node),然后进行数据迁移与重建。实验复现有具体的文档:2021-05-26-fastpr_readme.pdf,感觉可以改一改脚本的参数实现自己的新idea,最新的基于幕布的论文撰写技术素材。
- 刷题!
- 论文
- 《Fast Predictive Repair in Erasure-Coded Storage》
+scattered repair 和 hot-standby repair+实验使用C++实现,大概2400行代码,无缝连接HDFS
- 《Fast Predictive Repair in Erasure-Coded Storage》
19号,组会。众人各自的分享,bj利用幕布分享了幕布以及
zotero的使用以及几篇论文和情感状态的分享,hh说像是我带出的徒弟。我分享了我关于ADSLab实验室的发现,剩下的就是两位学姐的毕业预答辩。
20号,应该是仔细研究了一下bj找到的MATLAB版指静脉代码,基本研究通了,然后告诉我是用C实现。
21号,研究性学习,某人回来了。
22号,由于仅有一个的同住苏州的大学同学邀请,与昆山舍友一起同游吴中永旺,共品「江边城外」,共赏「速9之人体描边奔向太空特别篇」,主要聊了银行工作这个职业的各种具体情况。吃饭间听闻袁爷爷去世的真新闻,缅怀之余吃完了碗中的饭粒,电影结束看到了大连宝马事件,这一天恐怕太黑暗了。
17号,这一天白天主要实现了在线答题软件的同时在线人数功能的实现,主要就是启动软件的瞬间就启动一个线程每隔三秒循环不断访问MySQL,统计提前建好的表中OnlineState值为T的个数,若改变就进行展示,当用户点击登录时就基于用户名找到相应的数据行,把状态值改为T,用户退出就基于用户名将OnlineState值改为F。晚上,收到了HACFS(基于RS码与LRC码以及HDFS可变修复策略系统)的作者的回信,代码属于IBM研究院无法公开,推荐我去看HDFS源码。
18号,偶尔中发现了一个来自于港城大的实验室:Applied Distributed Systems Lab,之前就看过他们实验室的一篇论文,研究的是分布式存储系统的可靠性,自己用Python做了一个simulator来进行仿真,而且少见的开源了代码,今天发现他们实验室所有的论文都展示在主页且几乎每篇论文都有开源实现,亦或是放在Github上,亦或是放在实验室主页上,难怪在Github上直接搜是搜不到的。其中当然也有我所需要相关的基于HDFS融合自己算法的作为插件的实现,接下来要细细研究。
 |
-
目前该实验室值得阅读且有开源实现的论文:
- 2017,《Repair Pipelining for Erasure-Coded Storage》
+基于HDFS实现:ecpipe
- 2018,《A Simulation Analysis of Redundancy and Reliability in Primary Storage Deduplication》
+Python2实现:SIMD
- 2019,《Fast Predictive Repair in Erasure-Coded Storage》
+基于HDFS插件实现:fastpr
- 2019,《OpenEC: Toward Unified and Configurable Erasure Coding Management in Distributed Storage Systems》
+基于HDFS-RAID实现:OpenEC
- 2020,《On the Optimal Repair-Scaling Trade-off in Locally Repairable Codes》
+C++实现:infocom20_lrctradeoff
- 2017,《Repair Pipelining for Erasure-Coded Storage》
-
刷题!
停滞不前,总归是有点懈怠,再加之周末等等。没什么想法,因为之前关于动态变换修复编码的论文都是来自于16年的一篇HACFS的论文的想法,作者直接能在github上搜到他的名字,因为他的名字就是他的ID,发出的邮件都没有回复。也发现了《An Adaptive Erasure-Coded Storage Scheme with an Efficient Code-Switching Algorithm》的中文版,原来真的可以这样操作,一模一样翻译一下,重新再发表一篇。真的有些不明白,这些论文的实验无论在ceph还是HDFS上,一个都没有开源,网上也搜索不到任何相关实验,他们是怎么一步一步做起来的,审稿人又怎么相信他们真的做了实验呢?我现在只想自己用py自己写个实验,实在不知道怎么在这两个开源系统上进行实验。
12号组会,即兴的一场辩论赛,关于「好马该不该吃回头草」,我们有了好马周遭吃,研究调查说等观点,有裂缝说对磨合修复说,被刺破缝隙说驳回,我们还有论文横向吸取与纵向工作的针锋相对...此后是关于网络空间地图的讨论以及其实验平台PlanetLab的好奇与不知怎用,各自汇报了下情况,在阅读论文到构思下一个点不等,我还是困惑于实验,建议是重构ceph关于纠删码模块的插件或者构建一套自己的实验环境,剩下的就是关于指静脉仪的图像识别项目的蠢蠢欲动。
13号,结束了《An Adaptive Erasure-Coded Storage Scheme with an Efficient Code-Switching Algorithm》的阅读,开始了另一篇IEEE ACCESS上的类似的动态切换修复编码的文章《A New Adaptive Coding Selection Method for Distributed Storage Systems》的阅读,本文的实验建立在HDFS上面,使用的编码是RS与LRC之间的切换,依旧好像还是难以复现。另外听bj说的之前利用ML优化RAFT选举过程参数的论文已于一年前实现,这是一篇来自于韩国梨花女子大学的文章。此外顺便在Zotero上建立的文献共享群组,这样可以互相分享正在读的文献以及实时获取相应的笔记信息了,采用了坚果云备份后更加稳定,之后换电脑也更方便。
- 刷题!
- 论文
- 结束《An Adaptive Erasure-Coded Storage Scheme with an Efficient Code-Switching Algorithm》 ,B
- 开始《A New Adaptive Coding Selection Method for Distributed Storage Systems》
+热数据采用三份复制,暖数据采用LRC,冷数据采用RS+实验运行在HDFS上
CentOS上的ceph集群环境终于算是勉强搭好了,OSD添加总是莫名其妙的出错,而且还要保证虚拟机有两块硬盘,不然会格式化的是系统盘那就又得重来。Grafa的可视化也做好了,那么问题来了,如何更改ceph的内部运行纠删码算法,ceph系统的纠删码就是通过设置erasure-code-profile的参数k与m来调节它本身默认的RS码的设置,然后创建基于纠删码的pool,整个修复过程也都是ceph内部运行的,如何将自己设计的算法应用于ceph集群内部的修复,有点无法深入进去,像个黑盒。询问了清华的大佬没有回信,问了问亮亮大佬说是人家用的是HDFS,那就又要推到重来。,总之到这里又要停滞不前了。
- 刷题!
发现大部分论文的实验都是运行在ceph系统上,所以这几天都是在寻找实验的方法,看到一篇清华的论文,辗转联系到已经毕业的一作,要到了java代码,但是实验是改写成C跑在ceph上的,不知道怎么实现。。。发现了一个改进ceph纠删码性能的小组作业,给出了很多实验细节,看到他们记录中提到感谢实验室学长徐亮亮提供的物理机,巧了,最近一直在看他发表的几篇论文,真的这么巧嘛,果然还是研究水平高导致了更多的展现率。后记就是,因为要参加婚礼,提前回了老家,只能通过VPN连接服务器操作,这速度,无论是SSH还是实际操作,每个命令等待时间恐怕都可以喝杯咖啡。。以至于29号从早到晚,四台Ubuntu从早到晚,搭了一天,总是到ceph -s报HEALTH-WARN,我只能告诉自己Ubuntu不行,还是改CentOS吧。晚上花了点时间跟她视频的间隙淦完了开题,只能说很强。
- 刷题后面几天还没跟上,还要继续努力!
- 搭建论文的实验环境
- 完成了开题的结尾工作,只能说其实也没干啥
基本就是开题加上面试,总结:一地鸡毛。
-
完成了一次开题。所谓的开题就是老师开始时帮忙看结构,后来老师挑刺,再后来老师累了,读完了下一位,毕竟大家互相也不懂,无论从学术知识上,还是心理上。后面的路还要走,还是很崎岖。
-
完成了两次面试。凉的都很快,贝壳晾在很多知识都不会,spring,网络,数据库等等,字节晾在题没刷多,手生,简单的题没写出来,再加之,他一直看着,加老叹气,虽然很和蔼也说的诚恳,但我还是压力山大,脑袋直接空了,什么都想不出来,简单的都不会,这种打击恐怕是最大的吧,本来想的是多面试面试磨练磨练心智,也看看自己哪些不会,以免后面正式校招的时候露怯,但他说的一句“你知道你的面试表现会记录在册,影响以后的招聘...你这纯属是在浪费机会”还是给我多抹了一把汉。总之感谢面试官的诚恳,有种望生不成器的失望与责备,感激是真的感激,打击是真的打击,继续努力吧。
看了一天的文章吧,毕竟要开题了。
- 《A popularity-aware reconstruction technique in erasure-coded storage systems》
+Journal of Parallel and Distributed Computing 146 (2020)+提出一种称为POST的重构技术,以减少存储系统在响应用户请求时进行数据重构时的用户等待时间+糅合了:K-prototype、naive-Bayes-based text analysis algorithms、推荐模型来进行暖数据(介于热数据和冷数据之间)重构
由于乌雕云的到访,今天除了搞了一搞阿里的笔试,其他就是撸了好久没撸的局,一撸就是四局,就赢了一局....
- 阿里的数据研发,一道签到,一道回溯不会做,因为我现在的算法能力约等于0,只能做常人能想出来的题
- 开题,开题啊~
又拖了好久才来更新,好刺激,但又很烦躁,这种感觉非常糟糕,一次又一次希望自己记录每天的学习活动,可我都在干什么呢....
- 完成了项目的阶段工作,写了一些go的CURD工作
- 做了一半携程的笔试,什么也没做出来的sqlite,当了逃兵
- 刷了一题力扣:124. 二叉树中的最大路径和
- 或许我该开始Java的学习了
- 明天要开始准备开题报告
- 也许也要开始填写科研记录本了
- 或许也应该把《1Q84》看完了
- 或许之前绕校园跑要继续,俯卧撑也要继续
- 实习之路,任重而道远
沉寂了将尽满6个月,终于要开始了。今天更新Daily-Plan-In-Graduate-Life到了最新,完结了AutoOA的更新也做出了声明,,又更新了简历,加入了fontawesome图标,接下来要开始:刷题,写论文,准备开题。
1️⃣ 刷题
2️⃣ 写论文
3️⃣ 准备开题
不知道在干嘛。
1. 分布式存储系统中的纠删码容错方法研究
-
期刊,《计算机工程》
-
2019年
-
关键词:
分布式存储系统;纠删码;数据容错;数据编码;数据冗余 -
HRC 码是一种具有存储效率高、计算复杂度低等优点的纠删码, 但其存在编解码计算开销大、实现较为复杂等不足。通过对 HRC 码的译码算法进行优化, 提出一种新型的纠删码 HRCSD。采用内外层分层结构, 内部的冗余由 HRC 码的编码结构组成, 外层采用偏移复制策略, 将原始信息进行旋转存储, 能够实现并行读写。实验结果表明, 与三副本技术和 S 2-RAID 纠删码相比, HRCSD 纠删码具有容错性能高、修复开销低等优势, 可满足大规模分布式存储系统的容错需求。
-
引用格式
孙黎, 苏宇, 张弛, 等. 分布式存储系统中的纠删码容错方法研究[J]. 计算机工程,2019, 45( 11) : 74-80.
- 本文针对目前大规模分布式存储系统中数据容错存储效率低、纠删码的编译码计算复杂等问题, 提出一种具有较高容错能力且能够快速实现的纠删码容错编码 HRCSD。HRCSD 基于 HRC 进行偏移复制得到, 通过复制技术, 可满足在分布式系统中对数据的并行读取需求。实验结果表明, 与三副本技术和 S2-RAID 码相比, HRCSD 具有较低的存储开销、较高的容错能力和单节点故障下快速修复的性能。本文提出的 HRCSD 在故障修复过程中考虑的是单一节点发生故障的情况, 下一步将研究多节点发生故障的修复方式, 以降低修复带宽, 加快数据的修复 。
没怎么仔细看,不过估计作用不大。
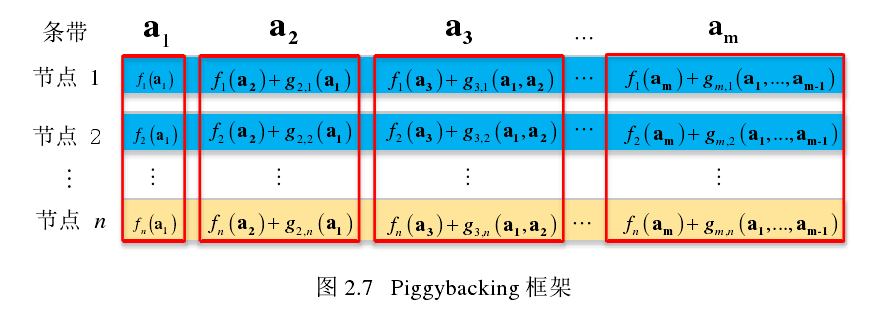
2. 基于piggybacking框架的分布式存储编码研究
2. 基于piggybacking框架的分布式存储编码研究
基本信息
-
硕士论文
-
2019年
-
关键词:
Piggybacking编码;MDS码;分布式存储;节点修复修复;带宽比率 -
摘要
互联网、5 G 及其相关产业的飞速发展使我们迈入了大数据时代,存储海量数据将面临着巨大挑战。为了解决大数据存储中存储节点失效的问题,具有容错能力且节约存储资源的分布式存储编码成为大数据时代重点研究的核心技术之一。Piggybacking 编码作为分布式存储编码中的一类,以其优异的节点修复性能和较高的存储效率,再加上其复杂度低,设计灵活等特点,最近几年受到了越来越多的关注。本论文主要面向数据的容错存储,针对存储中的节点修复问题,为大数据和移动数据的分布式存储编码提供理论基础,为海量数据的高效、可靠存储提供技术支撑。
首先,本论文对传统的数据存储容错,即多副本机制和 MDS 码进行了概述。接着介绍了三种主要的分布式存储编码,即再生码(RGC)、局部可修复码(LRC)和piggybacking 编码的基本原理、 发展现状以及它们各自的优缺点,为后续深入地研究打好基础。
其次,本论文针对一种用于修复校验节点的 piggybacking 框架提出了两种改进。在保持编译码复杂度基本不变的前提下,第一种针对修复校验节点的改进使得信息节点和校验节点的修复带宽均有不同程度地降低,且改进后 piggybacking 框架的设计更加灵活多变。第二种针对信息节点修复的改进,通过牺牲校验节点很小部分的修复带宽来换取节点数更多的信息节点的修复带宽是有意义的。
再次,本论文先对广义 piggybacking 编码进行了深入研究,指出了其校验节点修复存在的部分问题。更重要的是,本文基于广义 piggybacking 编码框架首次提出了 piggybacking 编码的多节点修复策略。经分析得到了诸如修复节点数、保护列比例、设计列比例、信息节点数以及校验节点数等因素对多节点的最小平均修复带宽比率产生的影响。这对设计出多节点修复性能优良的 piggybacking 编码具有一定的参考价值。
最后,本论文提出了一个全新的双层 piggybacking 框架(D-PB-1),通过最优化预留子条带比例
$p_a$ 和捎带子条带比例$p_b$同时有效地修复了信息节点和校验节点,大大降低了修复带宽。经分析,当信息节点数 𝑘 和校验节点数 𝑟 趋于无穷大时,所有节点的平均修复带宽比率无限接近于 0。其次,本文又提出了改进的双层piggybacking 框架(D-PB-2),通过改变修复信息节点的 piggyback 块的构造方式进一步降低了修复带宽。与其它 piggybacking 编码相比,这两类双层 piggybacking 编码不仅结构设计灵活,还拥有最佳的综合修复能力,尤其以 D-PB-2 表现最佳。接着本文还给出了双层 piggybacking 框架多例嵌套的模型,在保证修复性能不变的前提下,降低了 piggybacking 框架中的子条带数。最后,本文通过分析一种针对 MDS 码校验节点的构造方式,联系到改进的双层 piggybacking 编码的一种极端情况,揭示了它们修复本质相同的事实。另外,本文据此在理论上还给出了基本 piggybacking框架节点修复下限的猜想。 -
引用格式
李鑫, 基于piggybacking框架的分布式存储编码研究, 2019, 西安电子科技大学. 第 103页.
摘录
-
首先介绍了传统的多副本,MDS,再生码,局部可修复码;
-
Piggybacking 框架是在一个任意的、 我们称之为基本码的基础上操作的,目前的基本码都采用 MDS 码。piggybacking 编码保持了基本码的很多属性,比如最小距离和操作域。简单来说,piggybacking 框架是考虑 MDS 码的多个例(条带),并将某些例的数据通过设计的 piggyback 函数(线性组合)嵌入到其它例中,在修复失效节点的过程中将一部分 MDS 译码的操作转化为求解 piggyback 方程,有效地降低了修复带宽。通常 piggybacking 编码采用系统形式,因为系统形式中的信息节点承载了所有未编码的原始数据。因此用户通过直接访问信息节点就可以得到原始数据而不用访问某些校验节点采用 MDS 译码来恢复原始数据,这样不仅降低了获取原始数据的复杂度,还降低了获取数据的延迟。
-
两种改进的piggybacking编码,一种针对修复校验节点的改进,一种针对修复信息节点的改进;
-
多节点修复;
-
双层piggybaing框架的分布式存储编码;
思考
信息量太大,目前为止我还是不知道piggybacking到底是什么玩意儿,最奇怪的是整篇文章貌似并没有做任何实验,更涉及不到什么Ubuntu,什么分布式存储系统,貌似就是纯数学领域的推理,然后用推导出的公式带入不同的数值就形成了曲线,从这个角度来说貌似好像还挺轻松,我压根不需要什么分布式环境,什么多节点机器,只需要一些基础理论知识,加以时日的思考,但涉及到数学又是最难的东西。
3. A Piggybacking Design Framework for Read-and Download-Efficient Distributed Storage Codes —— silde
3. A Piggybacking Design Framework for Read-and Download-Efficient Distributed Storage Codes —— silde
-
PPT
-
2013
-
关键词:无
-
摘要
这是Rashmi做的一场关于Piggybacking框架的汇报。
-
引用格式
无
无
解决了我诸多疑惑:
-
MDS码到底是怎么实现的,比如RS code,跟多副本有什么区别:
-
piggybacking框架的最简单的实现:
-
一般化的piggybacking框架:
-
piggybacking does not reduce minimum distance: can choose arbitrary functions (任意函数)for piggybacking.
-
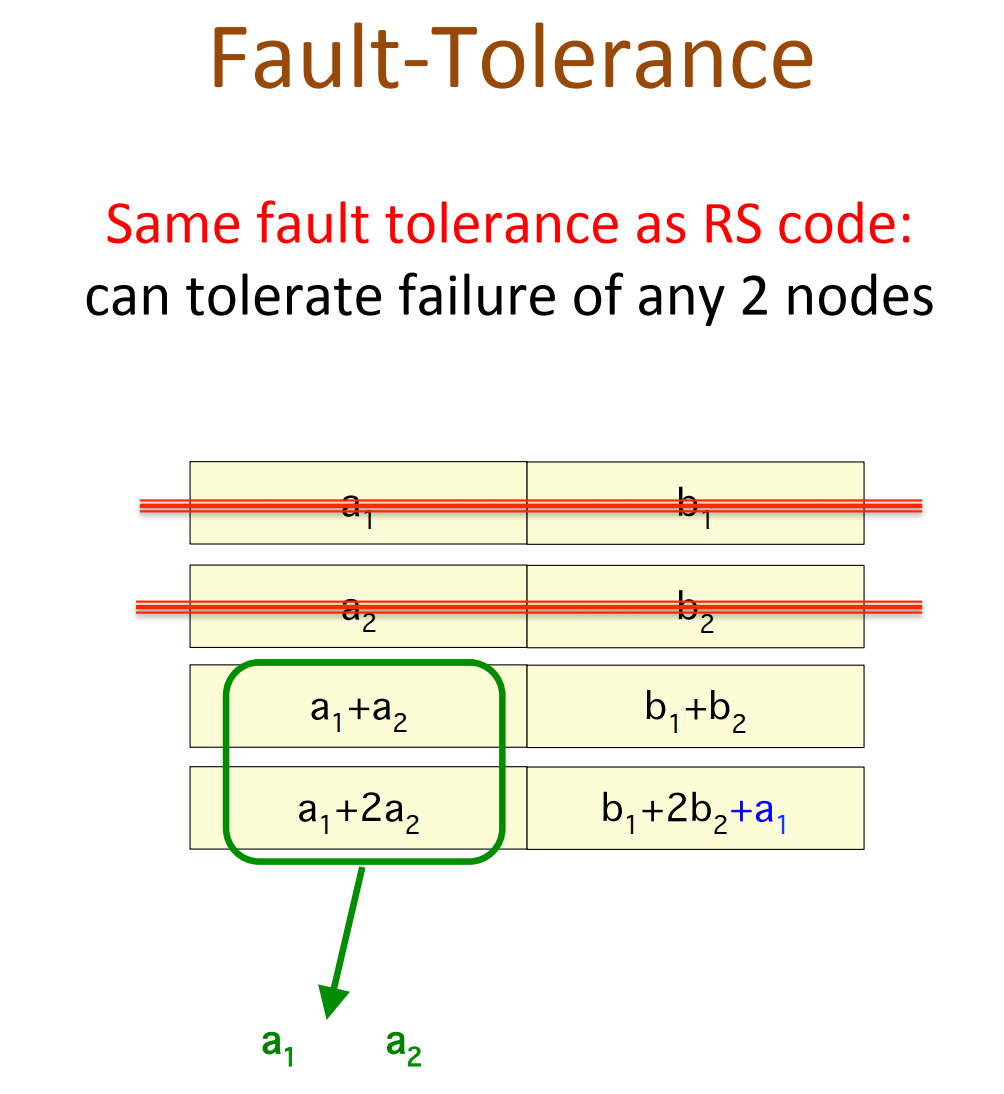
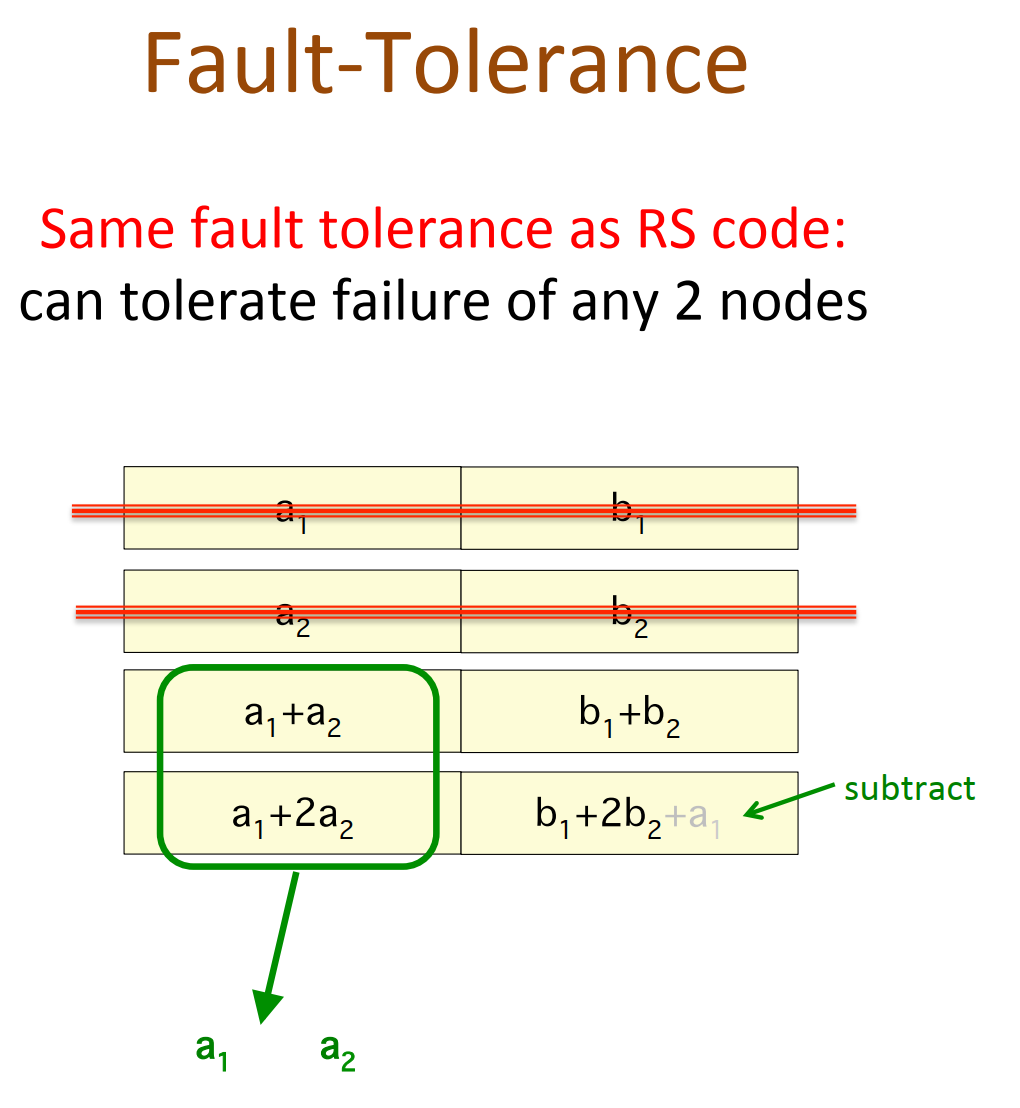
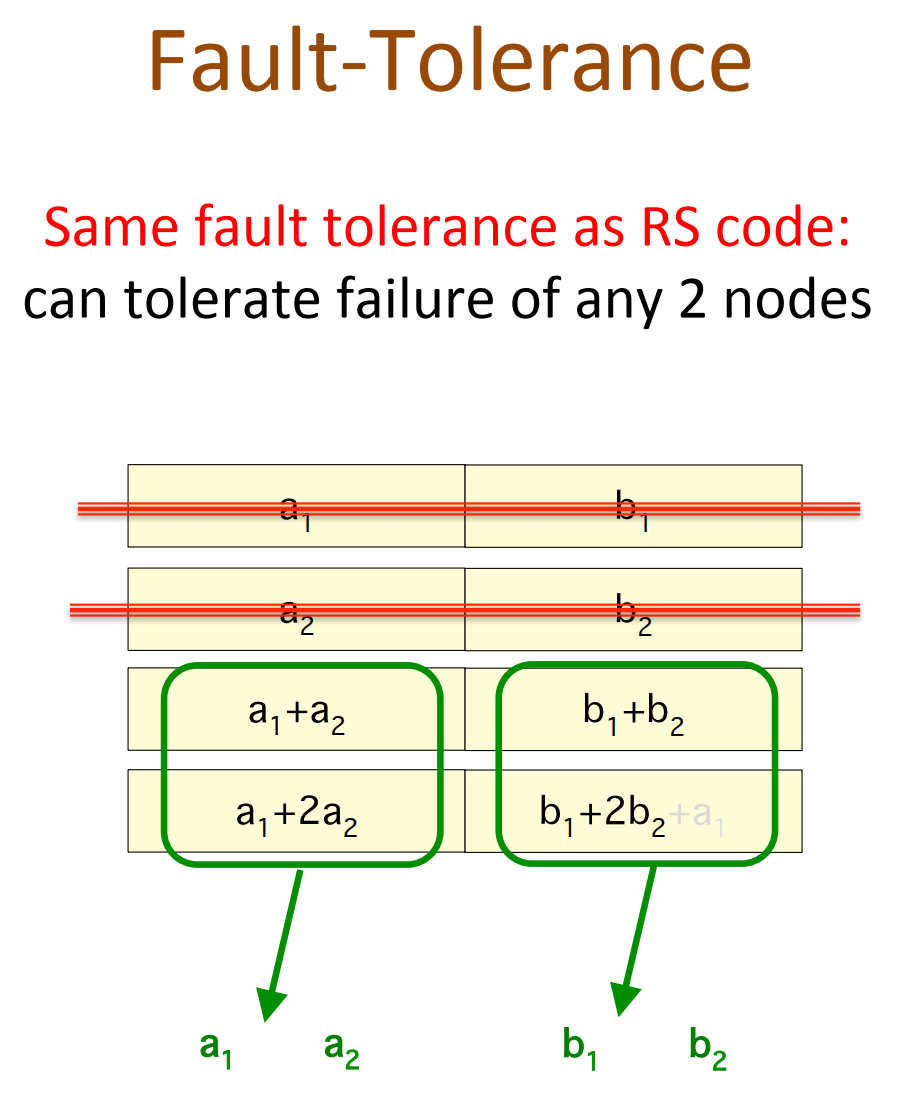
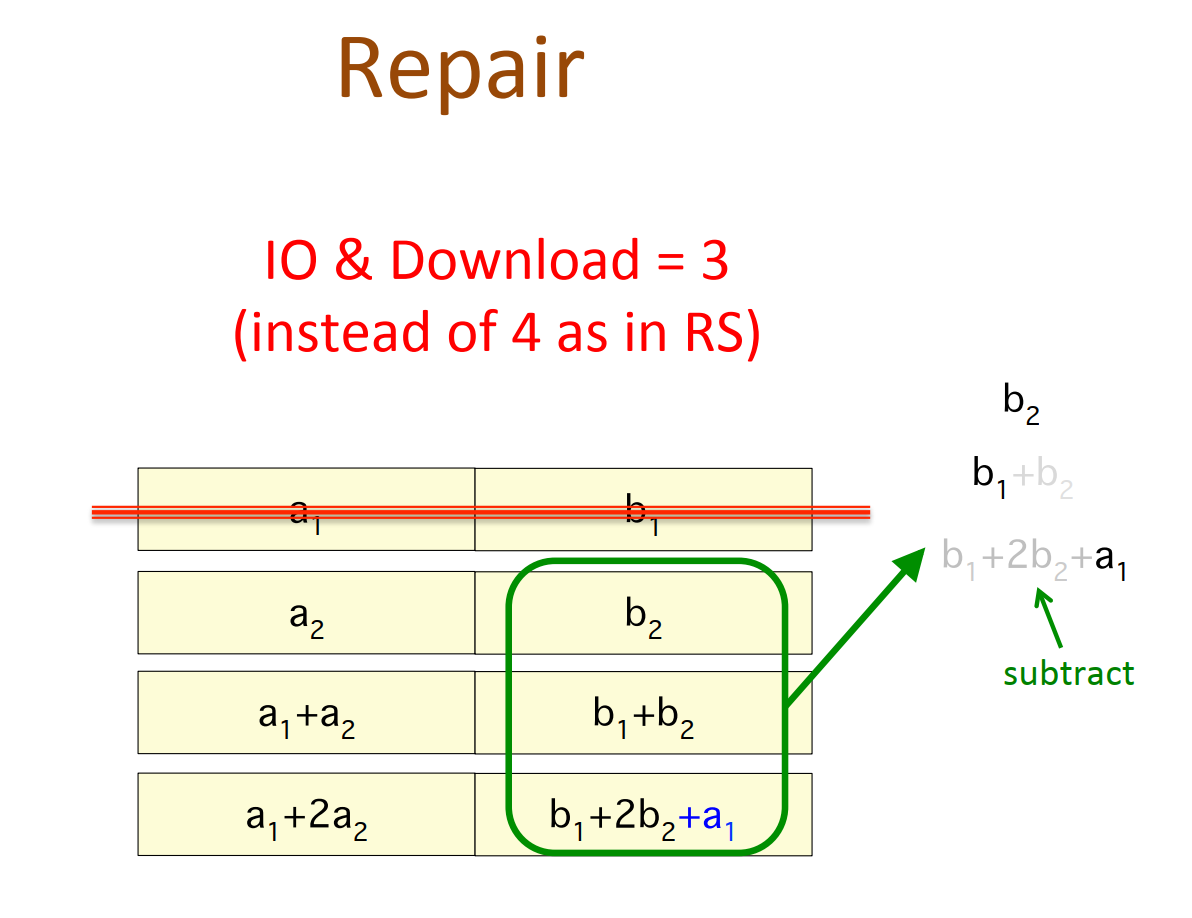
通过piggybacking框架可以:
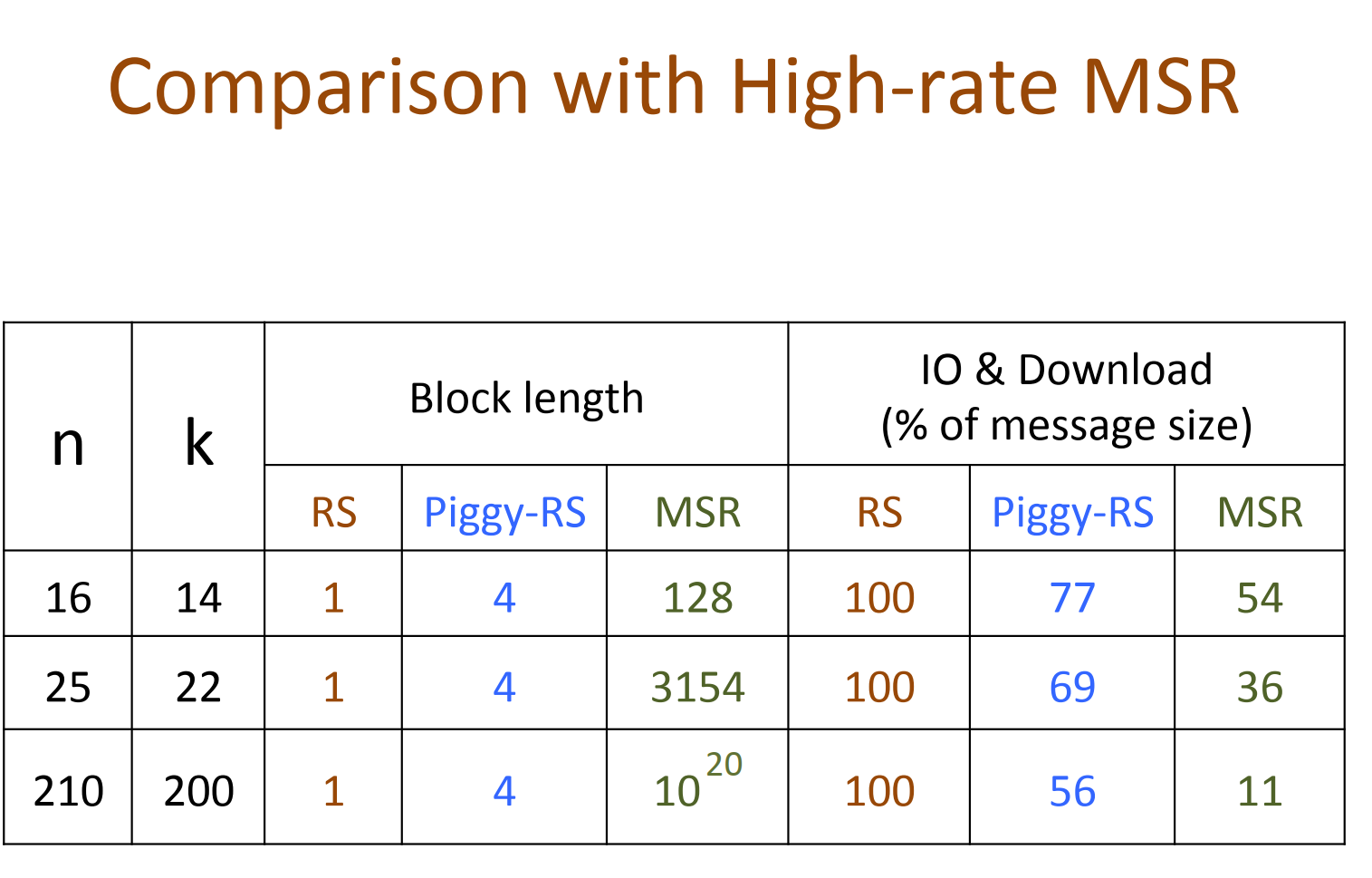
- High-rate MDS codes:Lowst known IO & download during repair;
- Binary MDS(vector)codes:
- Lowst known IO & download during repair;
- for all parameter where binary MDS(vector) codes exist
- lowest when #parity >= 3; En Gad et al. ISIT 2013 for #parity = 2
- Enabling parity repair in regenerating codes designed for only systematic repair
- efficiency in systematic repair retained;
- parity repair improved.
- Currently implementing (14,10) Piggyback-RS in HDFS:
- 30% reduction in IO and download;
- same storage & fault tolerance.
-
为什么不用High-rate Minimum Storage Regenerating(MSR) codes 作为基本码:require block length exponential in k (Tamo et al. 2011)
-
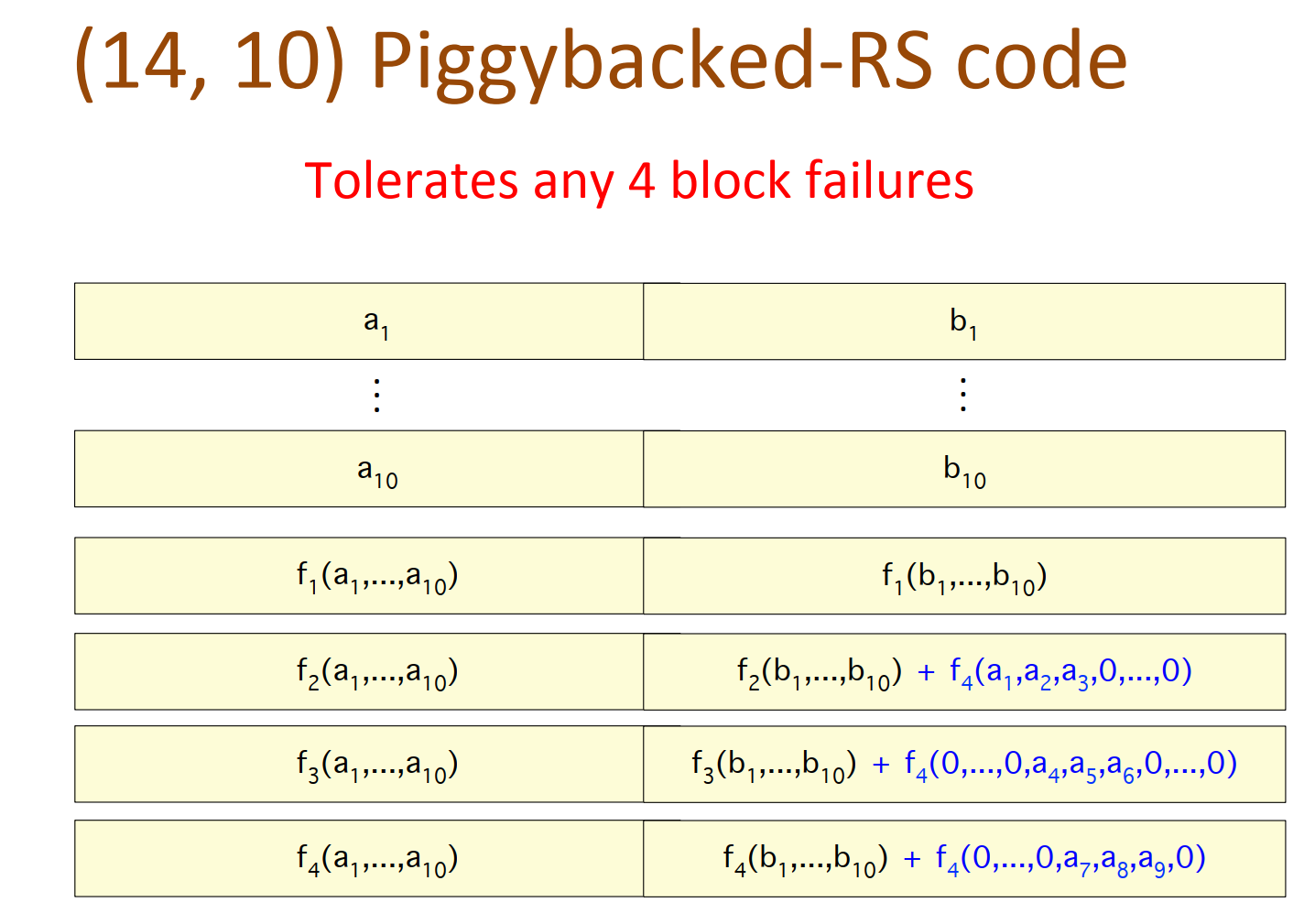
(14,10) Piggybacked-RS code
-
需要的connectivity > in RS, 这是否是一个值得关注的问题?
-
未来工作与开放性问题:











这一周几乎就是在发呆中度过的,好像有了方向,但好像又没什么方向。能做的太多,做得到的太少。一读到复杂的东西就开始读不下去,脑海中想的是即使我把它全都读懂了,能不能复现呢,就算是能复现了,能不能改造呢,就算能改造了,能不能发论文呢,就算能发论文了,这中间的时间是多少呢?几个月亦或是一两年?这些问题都是未知数,做下去还是放弃,时时刻刻萦绕在周围,我开始束手束脚,寸步难行,畏首畏尾,消极懈怠,什么都做不成。这种状态再这么持续下去,夏天真的就已经结束了。
1.A High-availability Data Backup Strategy for IPFS
-
2019 IEEE International Conference on Consumer Electronics - Taiwan, ICCE-TW 2019
-
2019年
-
关键词:
-
摘要
The InterPlanetary File System (IPFS) is a peer-to-peer distributed file system. It can greatly reduce the cost of data storage and improve the performance of data download. Currently, the IPFS-based distributed storage systems mostly uses the centralized backup mechanism. Although it can provide high data availability, centralized nodes will be single fault peer and become the bottleneck of system performance. This paper proposes a high-availability data backup strategy based on QoS and interest of IPFS nodes. Compared with the existing methods, the experimental results demonstrate that our proposed strategy is more effective and practical.
-
引用格式
Shi, L., Luo, H., Yang, X., & Sun, Y. (2019, May 1). A High-availability Data Backup Strategy for IPFS. 2019 IEEE International Conference on Consumer Electronics - Taiwan, ICCE-TW 2019. https://doi.org/10.1109/ICCE-TW46550.2019.8991855
-
系统模型
-
实验
-


-
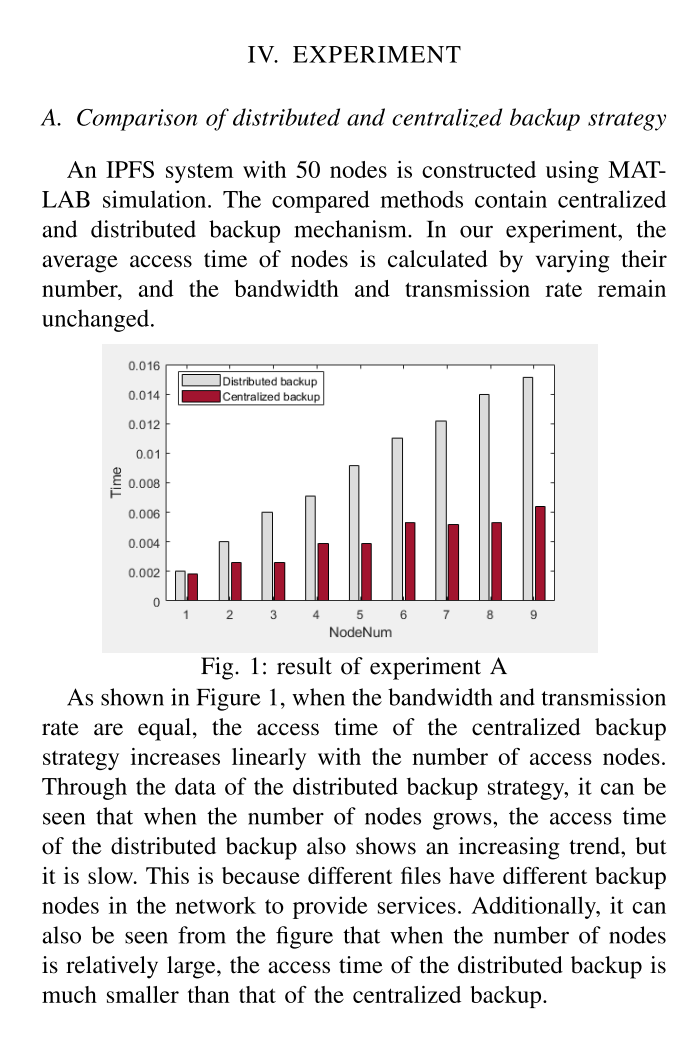
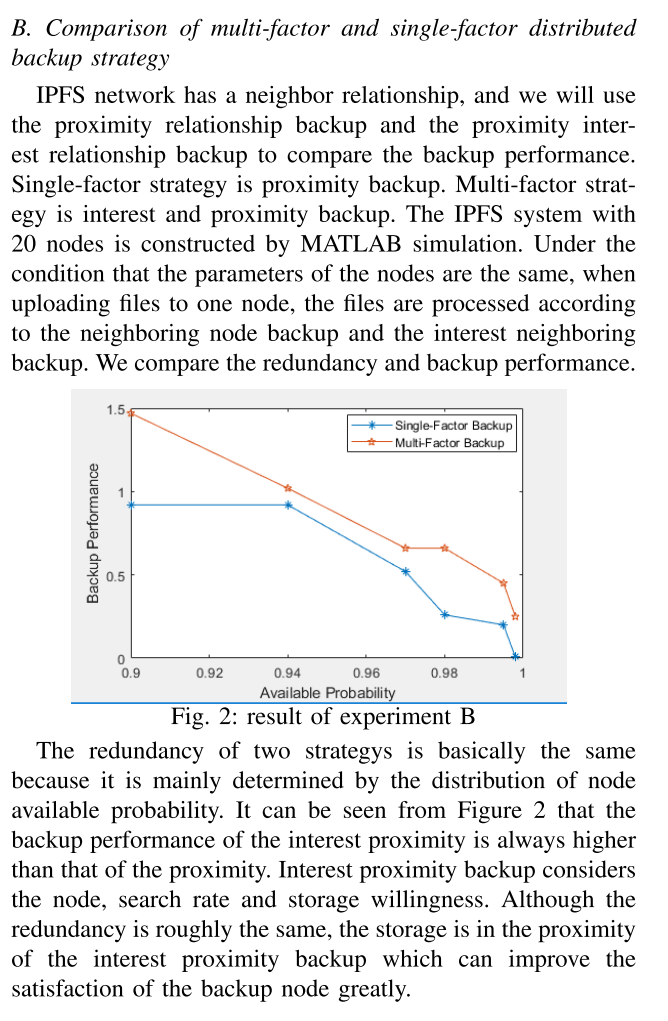
这篇文章首先很短,其实几乎什么都没写。看似好像提出了
IPFS的新的备份策略,但他们提出的节点之间的距离d,甚至都没有给出明确的定义,什么是节点距离,如何定义,无法得知,在这种情况下,设计的算法事实上是无法站住脚的。 -
在具体实验中,原文写的是:
An IPFS system with 50 nodes is constructed using MAT-LAB simulation.
这句话,无论怎么翻译都是在
MATLAB Simulink中实现了IPFS系统。(卧槽,这么高级的吗?!)但事实上,我发了邮件询问之后才发现,并不是。。。一个说不是我做的实验,并没有代码,另一个直接说MATLAB中没有IPFS系统。好吧,是我的英文理解有限,瑞斯拜。 -
最后,事实上这个备份算法的实质:直接复制进行备份。只不过在节点的选择上,设计了一些特别的算法,但在节点选择算法中最关键的节点距离定义却一笔带过,没有详细定义,实在不知道他们是如何进行节点选择的。
2.A Piggybacking Design Framework for Read-and Download-Efficient Distributed Storage Codes
-
IEEE International Symposium on Information Theory - Proceedings
-
2013年
-
关键词:
Distributed storage;bandwidth and I/O;code-design framework;erasure codes;repair -
摘要
We present a new piggybacking framework for designing distributed storage codes that are efficient in the amount of data read and downloaded during node-repair. We illustrate the power of this framework by constructing explicit codes that attain the smallest amount of data to be read and downloaded for repair among all existing solutions for three important settings: (a) codes meeting the constraints of being maximum distance separable (MDS), high-rate, and having a small number of substripes, (b) binary MDS codes for all parameters where binary MDS codes exist, and (c) MDS codes with the smallest repair-locality. In addition, we show how to use this framework to enable efficient repair of parity nodes in existing codes that are constructed to address the repair of only the systematic nodes. The basic idea behind this framework is to take multiple stripes of existing codes and add carefully designed functions of the data of one stripe to other stripes. Typical savings in the amount of data read and downloaded during repair are 25% to 50% depending on the choice of the system parameters. © 2013 IEEE.
-
引用格式
Rashmi, K. V., Shah, N. B., & Ramchandran, K. (2013). A piggybacking design framework for read-and download-efficient distributed storage codes. IEEE International Symposium on Information Theory - Proceedings, 63(9), 331–335. https://doi.org/10.1109/ISIT.2013.6620242
-
piggybacking编码示意图 -
Four classes of explicit code constructions
- (Class 1) A class ofcodes meeting the constraints ofbeing MDS, high-rate, and having a small number of substripes, with the smallest known average amount of data read and downloaded for repair.
- (Class 2) Binary MDS codes with the lowest known average amount of data read and download for repair, for all parameters where binary MDS codes exist.
- (Class 3) Repair-efficient MDS codes with smallest possi-ble repair-locality.
- (Class 4) A method for reducing the amount of data read and downloaded during repair of parity nodes in existing codes that address only the repair of systematic nodes.
-
Framework
-
Desgin 1
-
Experiment Results







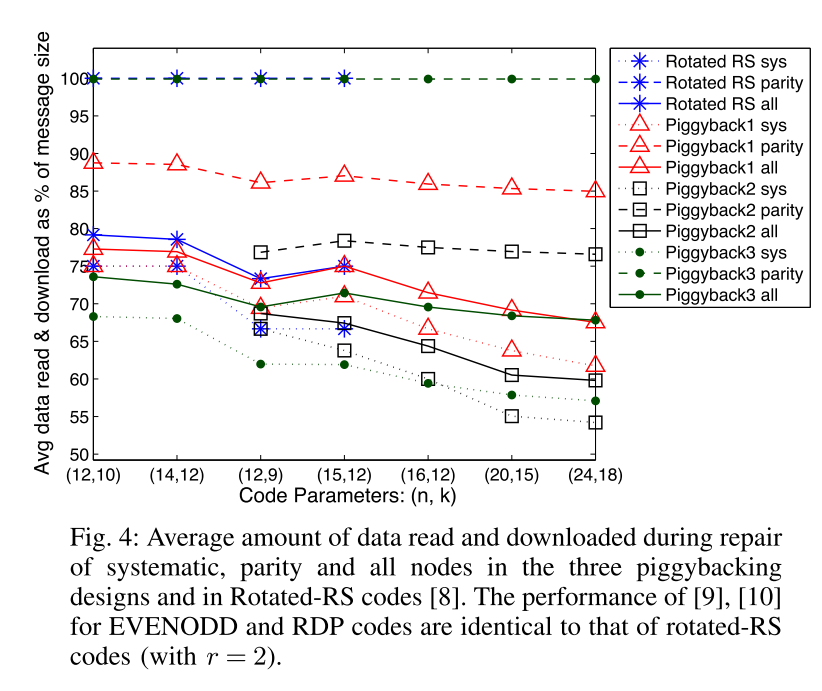
- 这是冗余纠删领域在2013年的一篇具有很强开创性的具有引领整个领域发展方向的重磅文章。基于现有的
MDS再加上新的编码层,在不改变既有的工业界已投入使用的算法上,附加上新的规则,并且能极大降低读取与下载的负荷,应该说是非常厉害的原创性工作,类似于2012年的获得ImageNet第一的AlexNet之于深度学习与图像识别,以及2016年的XGBoost之于机器学习与数据挖掘。 - 就像在那之后AI领域大放异彩,就快取代所有基础自然学科一样,仿佛这世界只有一种学科。当然对于
piggybacking没有如此神乎其神,但它确实有着这样的潜力,毕竟Rashmi等人提出的是一种框架,而后人可以在这个框架上进行各种改造,以达在实验上得到更加优秀的存储上传下载实验数值,在这个层面上来说类似于AI调参一样,可以调出优秀的参数,只是从复现上来说,不仅仅是装个python环境,import一些包,安装一些tf,pytorch之类,敲几行代码而已,这里的调参意味着首先要有一套完善的实验环境,从搭建存储系统,构建冗余算法,感觉步步是坑呢。 - 当然还有一个问题就是这篇文章涉及的旧有算法太多,并且又掺杂了自己的新算法,而且是基于
MDS实现的,意味着还要熟悉MDS的具体思想与构建方法,此外还有大量的数学推导,又增加了理解难度,不提复现,理解起来难度就不小。只能继续看看往后七年里面有没有将其实现,并且以更加易于理解的方式解析的文章。
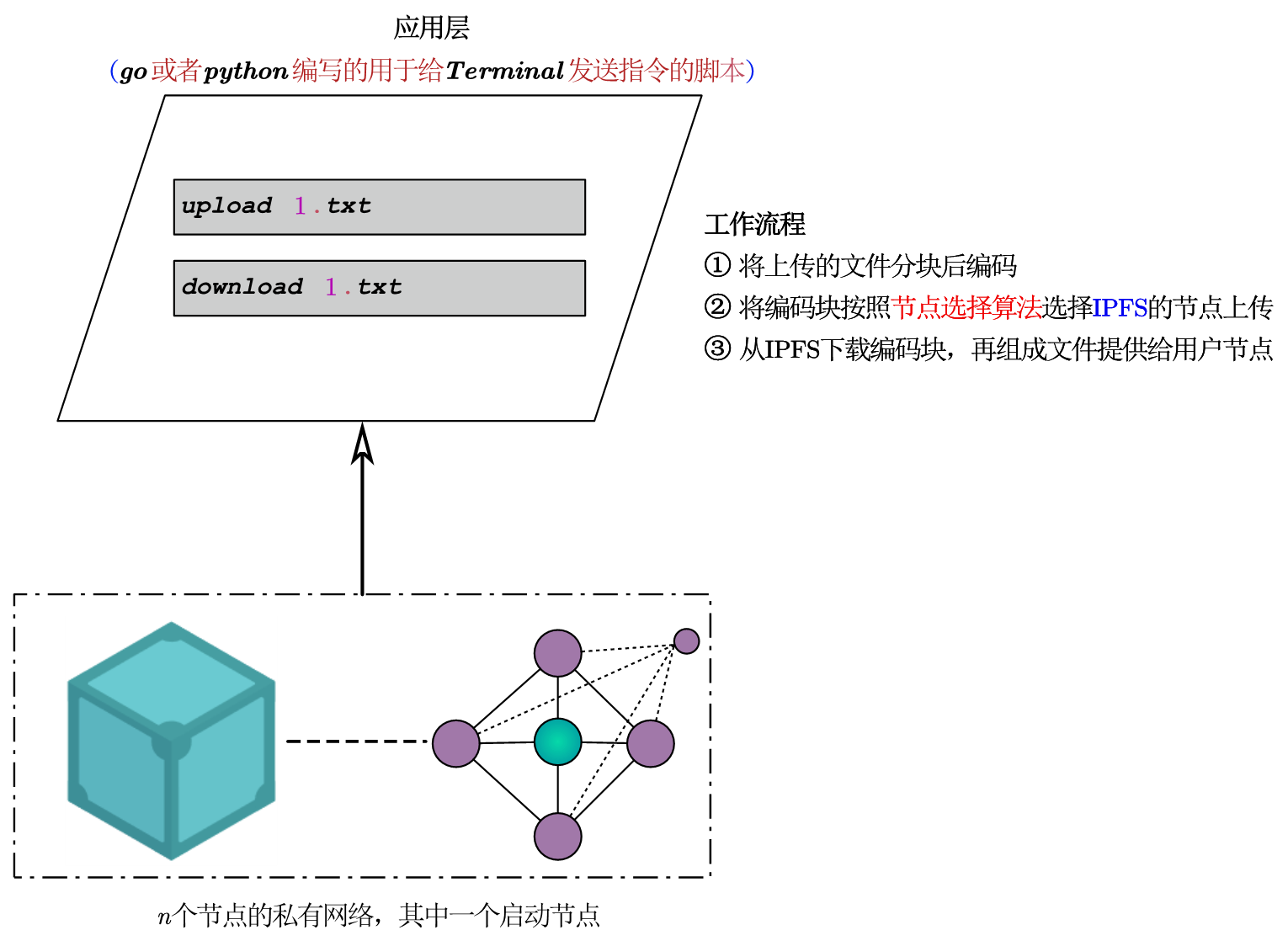
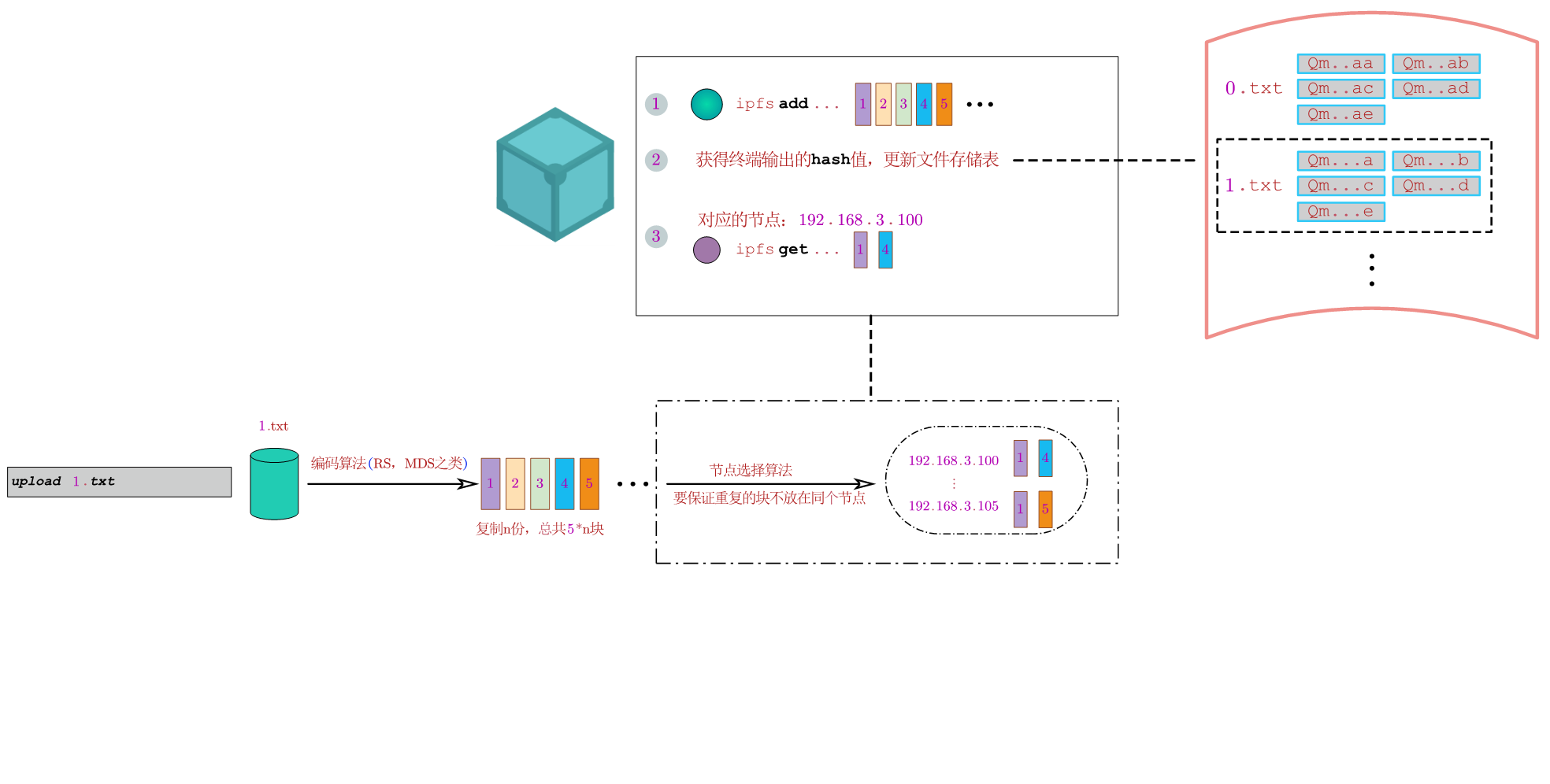
也许就这样就挺好的吧,不加引用格式了。10号的组会,分享了下自己7号周五立秋那晚,跟浩浩酣畅淋漓吃鸡两小时后的深夜突然来的灵感。后来想想也不是啥灵感,就是把整个项目全局考虑了下需要实现的东西罢了,只是看的还不够多,所以没有细节考虑,详情就在下面的图片。虽然我不断地向众人展示我的想法的时候,我也慢慢地思路清晰了起来,虽然我在讲冗余的实现,事实上是讲了整个系统的实现流程,但是冗余的进程确实贯穿着文件上传下载的始终,但问题是一个存储系统主要就包含了上传于下载,所以在讲冗余实现时,事实上就讲了整个系统的实现过程。结果也很明显,翔哥还是让我只专注于纠删码算法的细节部分,毕竟说了这么多,我只是用IPFS作为底层实现了一个非常简单的冗余demo,其中大部分都是IPFS定死的,无法改变。所以忙活了一通,我其实毫无进展,原地徘徊。可是这个领域我不知该怎么走下去。此时,有两人程序已经开始跑程序了,一个跑完程序开始写文章了。
-
框架图
-
上传流程
- 下载流程
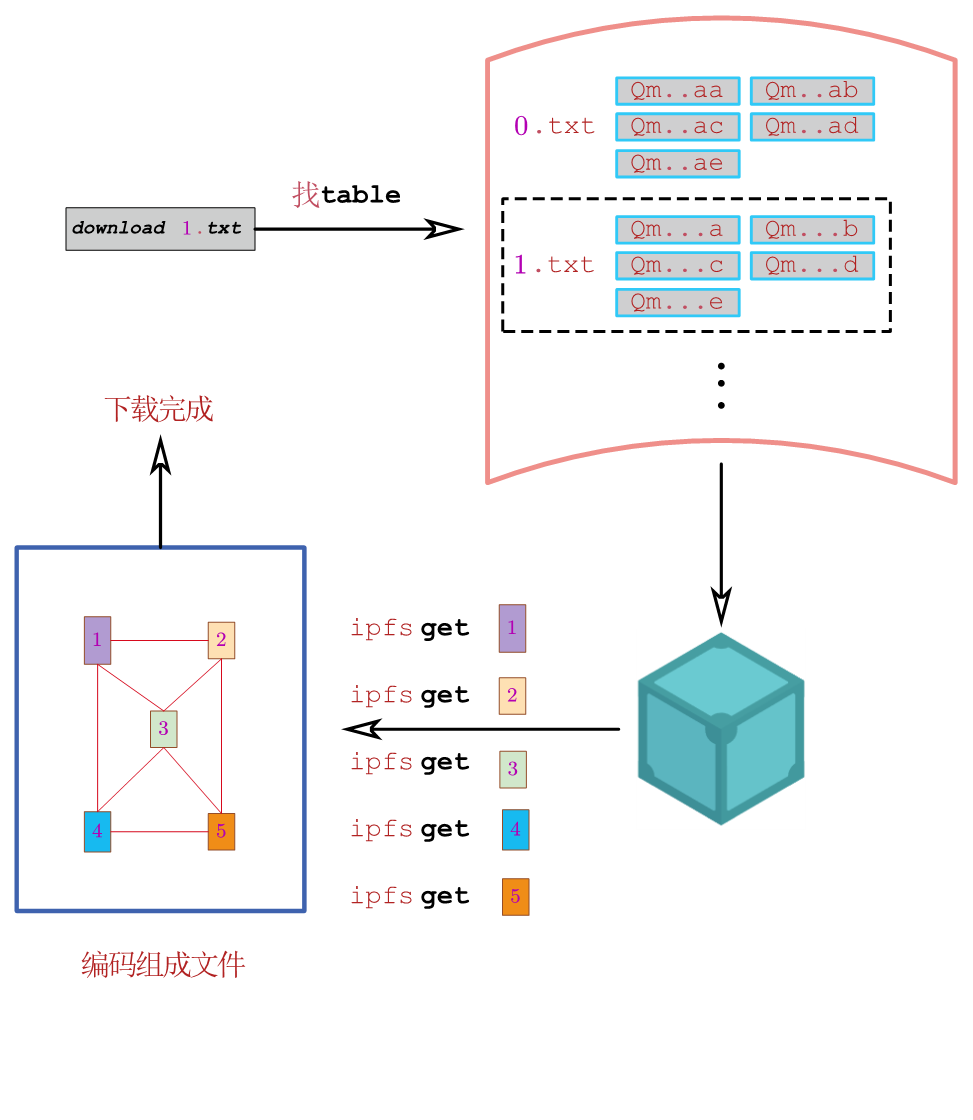
嚯,这一下就过去了大半个月。浑浑噩噩,不知道每天都在干啥。最近论文停滞的原因主要在于不知道该看什么方向,有思路的方向,发不出论文,可以发论文的方向,没有能力做下去,项目的工作内容完全无法发论文。24号的时候,看的一篇论文,完全看不懂,太打击自信心,导致后来卡着看了好几天,什么都没看懂,心态就有点崩,后来就慢慢完全看不下去,不知道目的地在哪里,不知道方向在哪里。最近搭建实验环境,将近一个礼拜,写了三篇文章。但是在这样的环境中,中心节点可以与其他子节点通信,但是这些子节点相互之间却不能通信,只有子节点上传一个文件,中心节点查看了,有了缓存之后,其他的子节点才能访问这个文件,这就完全脱离了分布式的特点,只要中心节点一宕机,其他节点全抓瞎。好难,前路漫漫,不知坑处。s
P2P网络存储系统的数据可靠性研究
-
硕士论文,哈尔滨工程大学
-
2011年
-
关键词:
P2P存储系统;冗余策略;服务成本;数据恢复;访问频度 -
摘要
随着互联网的快速发展,互联网上的数据呈现几何级数态势增长,大量的多媒体数据充斥在网络中,网络上海量数据的增长给传统的存储系统技术带来了严峻的挑战,基于P2P网络的存储系统因具有高可扩展性、能充分地利用各种潜在资源等优点而成为存储主流技术。然而一旦存储系统数据因自然灾害、网络攻击或人为恶意损坏而无法及时访问,就会对工作生产造成影响甚至是难以弥补的损失,因此,如何保证基于P2P存储系统的数据可靠性成了当前的研究热点。
本文深入研究了结构化P2P覆盖网的数据可靠性,针对P2P网络存储系统数据冗余策略和数据恢复策略进行优化和改进。
为提高冗余策略的效率,对不同的冗余策略算法进行比较分析,针对传统的P2P存储系统采取单一的冗余策略所带来冗余效率低的问题,提出基于用户体验和服务成本的冗余策略,该策略分析用户数据价值,根据服务成本模型,制定对应的冗余规则。根据冗余规则,对不同的数据特征进行最合适的冗余编码方式。设计原型系统并进行实验,并通过实验验证该方法的有效性。
针对P2P存储系统本身节点概率性掉线导致数据失效的问题,为保证数据的可靠恢复,提高系统的数据恢复策略的稳定性,提出基于访问频度的数据可靠恢复策略,当冗余数据量不足时,根据恢复节点的访问频度模型制定数据恢复策略。设计模拟仿真试验,并通过实验验证该方法的有效性。
-
引用格式
许劲斌, P2P网络存储系统的数据可靠性研究, 2011, 哈尔滨工程大学.
1.完全副本复制冗余:

- 纠删码原理图
- 纠删码比较
- 基于用户体验和服务成本的数据冗余策略
- 其中数据分发流程
- 其中数据分发流程
- 基于访问频度的数据可靠恢复策略
- 数据失效的发现机制
- 定期心跳法,是指每个数据节点定期向其对应的目录主节点报告自己存在数据的状态,如果对应的目录节点一段时间内没有收到该节点发送过来的心跳则认为该数据节点下线。
- 失效事件广播法,是指存放目录主节点定期主动探测其负责的数据节点的状态,如果探测失败,则认为该数据节点下线。
- 定期心跳法,是指每个数据节点定期向其对应的目录主节点报告自己存在数据的状态,如果对应的目录节点一段时间内没有收到该节点发送过来的心跳则认为该数据节点下线。
- 具体算法:
- 数据失效的发现机制









作者说进一步的研究和探索:在复杂的网络环境中,大量节点的频繁加入或退出的条件下
- 怎样更好的维持数据的负载均衡,以提高可靠访问;
- 各冗余副本之间如何高效、合理的保证数据的一致性;
- 研究如何能够更精确地测量数据的访问频度,以制定更加符合应用的可靠恢复策略;
- 研究如何更好的精确查询。
这篇文章,还是在可以想见的范围内对冗余算法进行了改进,就是基于访问热度的冗余策略,另外让我注意到了(当然以往也有看到),在冗余之后的如何分发是一个比较困难的问题。
1.分布式存储系统中容错技术综述
1.分布式存储系统中容错技术综述
基本信息
-
期刊论文,《无线电通讯技术》
-
2019年
-
关键词:
分布式存储;MDS码;再生码;局部可修复码;Piggybacking编码 -
摘要
互联网5G及其相关产业的飞速发展使我们迈入了大数据时代,存储海量数据将面临着巨大挑战。大规模分布式存储系统以其海量存储能力、高吞吐量、高可用性和低成本的突出优势取代了集中式存储系统成为主流系统。由于分布式存储系统中节点数量庞大,经常会产生各种类型故障,从而导致节点失效情况频。因此,必须采用容错技术来保证在部分存储节点失效的情况下,数据仍然能够被正常读取和下载,具有容错能力且节约存储资源的分布式存储编码成为大数据时代重点研究的核心技术之一。讨论了大数据背景下存储与可靠性的问题,从而引出数据容错对分布式存储的重要性。阐述了传统的2种数据存储容错技术,即多副本机制和MDS码。重点分析了3种主要的分布式存储编码,即再生码(RGC)、局部可修复码(LRC)和Piggybacking编码的基本原理、优缺点以及发展现状。总结对比了这5种数据容错技术的性能差异。面向数据的容错存储,针对存储中的节点修复问题,为大数据和移动数据的分布式存储编码提供理论基础,为海量数据的高效、可靠存储提供技术支撑。
-
引用格式
李鑫, 孙蓉与刘景伟, 分布式存储系统中容错技术综述. 无线电通信技术, 2019. 45(05): 第463-475页.
摘录
-
MDS码(Maximum Distance Separable最大距离可分):如Reed——Solomon,RS码,Google Colossus,HDFS Raid,Microsoft Azure,Ocean Store。存储成本更低,但是其拥有更高的修复成本和访问延迟,而且没有考虑存储开销、磁盘I/O 开销等,因此并不适合用于大规模分布式存储系统 。如果系统编码设计的目标是在不牺牲磁盘故障容忍度的前提下最大化存储效率,那么存储系统采用MDS码来储存数据,因为它可以为相同的存储开销提供更高的可靠性。也就是说MDS码是一种能提供最优储存与可靠性权衡的纠删码。在一个分布式存储方案中,原始文件首先被分成k个数据块,接着它们编码生成n个编码块并存储在n个节点 中。访问任意l(l≥k)个节点,通过纠删码的译码就可恢复出原始文件,如果l= k ,该码就满足MDS性质,最多能够容忍 (n-k)个节点的失效。
- 目前主流的分布式编码:
- 再生码(Regenerating Codes,RGC),修复带宽较小,但由于它们在修复过程中有大量的矩阵运算,计算复杂度很高,因此构造过程非常复杂。
- 局部可修复码(Locally Repairable Codes,LRC),同RGC。
- MDS阵列码,如EVENODD,B-code,X-code,RDP,STAR,Zigzag,它们的编译码过程基本都是构建在低阶域的简单运算之上,复杂度低。但受限于阵列码的构造过程,它们所设计的冗余节点很少,导致其容错能力有限,修复能力一般都比较弱,修复效率较低。
- Piggybacking编码,研究还处在起步阶段,有很多理论和实际应用还不太完善。
-
RGC
- Dimakis等人受网络编码的启发将编码数据的修复建模为信息流图,从而提出了再生码,其约束条件是维持容忍磁盘故障的能力。
- 在信息流图中,所有的服务器可以分为源节点、存储节点和数据收集器,其中源节点表示数据对象产生的服务器。
-
- 纵然RGC达到了存储与带宽开销之间的最优权衡,但因为其需要繁琐的数学参数和复杂的编码理论基础,实现过程很难。目前RGC大多在有限域$GF(2^q)$上进行多项式运算。加法在计算机上处理较为简单,然而乘法和除法却相对复杂,更有甚者需要用到离散对数和查表才能处理。这使得RGC的编译码复杂度很高,因而很难满足分布式存储系统对计算复杂度的要求。RGC作为MDS码的改进版,拥有良好的理论基础,但是现有的绝大部分RGC编译码复杂度很高且码率低,所以迫切地提出高码率且编译码复杂度低的RGC,这具有积极的现实意义。若同时结合磁盘I/O、数据存储安全和网络结构等方面构造,能进一步推广RGC的应用范围。
-
LRC:与通过牺牲磁盘I/O开销来节省带宽消耗的RGC不同,LRC具有较少的磁盘访问数量。它是通过强制一个失效节点中的数据只能通过某些特定的存储节点来进行修复,从而减少需要读取和下载的数据量来降低修复带宽。
- 假定任意3个节点都足以得到原始数据的 MDS码,即k= 3。修复一个故障节点,MDS码和再生码需要读取6个编码段,而图6中却只需要读取2个特定的编码段,所以能降低磁盘I/O 开销。
- 以存储为代价,目前采用的系统有:Facebook的分布式文件系统 HDFS和微软的 Azure。主要实现方法有:分层编码(Hierarchical Codes)和简单再生码(Simple Regenerating Codes,SRC)。
- 发展现状:
- 2016年,Kumar等人为分布式存储设计了一种可修复喷泉码(Repairable Fountain Codes,RFC),在信息安全理论上提出了针对存储节点的窃听模型,应对通过失效节点的修复来窃取其他幸存节点数据的威胁;
- Rawat等人通过平衡LRC 的安全性和修复度,提出了安全性最佳的局部修复度结构的编码方案,可有效抵抗监听;
- 2017年,Kadhe等人又通过内码和外码的联合设计,构造了一种广泛的安全存储码方案,同时考虑了 MSR码和 LRC这2种分布式存储编码;
- 针对单个节点失效LRC的研究:
- 基于二元LDPC码的构造 :2016年,Hao等人阐述了一类有着多修复组的 LRC与二元 LDPC码的关系,提出了用正则LDPC码去构造LRC的方法。 2017年,Su等 人在上述工作基础上基于循环置换矩阵和仿射变换矩阵提出了2种二元LRC的构造方法,达到了距离限 ;
- 基于联合信息可用性构造
- 基于联合信息可用性构造
- 基于平均修复度的构造
- 基于 Matroid理论的构造
- 基于Rank-Metric理论的构造
- 假定任意3个节点都足以得到原始数据的 MDS码,即k= 3。修复一个故障节点,MDS码和再生码需要读取6个编码段,而图6中却只需要读取2个特定的编码段,所以能降低磁盘I/O 开销。
-
Piggybacking编码: 2013年 Rashmi等人首次提出了 Piggybacking框架的概念,且将该框架下构造的 Piggybacking编码用来应对存储系统中频发的故障节点。他们解释 Piggybacking的 含 义 是 将 MDS码 作 为 基 本码,将扩展后的 MDS码中某些条带的数据符号通过精心设计好的 Piggyback函数嵌入到其他条带中形成 Piggybacking块的一种设计。失效的数据符号可以通过求解 Piggybacking方程来替代传统的MDS译码来恢复,这样能有效降低修复带宽。
- Piggybacking框架有一个显著的特点就是在不改变原有存储节点的分布结构下减少了额外的存储开销,即不需要增加除MDS编码以外的校验节点,依旧能保持数据重建性;
- Piggybacking编码支持任意码长为n 、信息位长度为k 的基本码(码参数的选择取决于基本码的需要);
- 目 前 已 经 应 用 于Facebook Warehouse Cluster,HDFS等系统中;
-
- 目前有三种设计:
- 第1种设计是基于较少的子条带数量,其中最少的子条带数只有2。这类设计修复信息节点时根据码参数不同可以节省25%~50%不等的修复带宽,且该设计也具备修复校验节点的能力;
- 第2种设计是由(2r-3)列结构相同的MDS码组成,并在最后(r-1)列中增加了Piggyback方程。该设计要求校验节点数r≥3,相比第1种设计拥有更高的修复效率,平均能有效减少约50%的修复带宽;
- 第3种Piggybacking编码,该码可以有效修复最小修复度可达k+1的MDS码中的信息节点。
-
- 最终比较











思考
- MDS码(Maximum Distance Separable最大距离可分):如Reed——Solomon,RS码,Google Colossus,HDFS Raid,Microsoft Azure,Ocean Store。
- 再生码(Regenerating Codes,RGC),修复带宽较小,但由于它们在修复过程中有大量的矩阵运算,计算复杂度很高,因此构造过程非常复杂。
- 局部可修复码(Locally Repairable Codes,LRC),同RGC。
- MDS阵列码,如EVENODD,B-code,X-code,RDP,STAR,Zigzag,它们的编译码过程基本都是构建在低阶域的简单运算之上,复杂度低。但受限于阵列码的构造过程,它们所设计的冗余节点很少,导致其容错能力有限,修复能力一般都比较弱,修复效率较低。
- Piggybacking编码,研究还处在起步阶段,有很多理论和实际应用还不太完善。
全篇花了大篇幅在论述piggybacking的理论,构造以及应用,而且19年有一篇硕士论文专门论文了piggyback技术,说明还是一个研究热点,可以做做功夫。
1.基于HDFS的分布式文件系统数据冗余技术研究
1. 基于HDFS的分布式文件系统数据冗余技术研究
基本信息
-
硕士论文,西安电子科技大学
-
2011年
-
关键词:
分布式文件系统;HDFS;数据冗余技术;数据可靠性 -
摘要
随着信息技术的发展,存储系统占有举足轻重的地位。在数据爆炸性增长的今天,本地的存储很难满足不断增长的海量存储的需要,而且个人移动计算和企业级计算对底层的存储系统也提出了更高的要求,人们越来越多地使用分布式文件系统,它可以带来更高的存储能力、可靠性、安全性和移动性。
本文主要研究了分布式文件系统的数据冗余技术。传统的分布式系统大多采用独立磁盘冗余阵列(RAID)和复制技术进行数据的冗余,要达到一定的可靠性对存储空间的要求较高。后来又出现了编码方法对数据进行编码存放,这在提高了可靠性的同时又带来了数据读取和写入时性能的较大损失。为了更好地平衡数据可靠性和读取性能,本文提出了综合采用复制和网络编码技术对数据存储的方案。在开源的 HDFS(Hadoop Distributed File System)项目基础上,给出了文件分块编解码、编码块放置策略、文件读取和写入的完整流程和方案,之后又研究了如何进行负载均衡以及怎样在大规模廉价低可靠机器组成的集群上处理机器的频繁退出和加入的问题。借助于这种数据冗余技术,可以在相同的冗余度上提高数据的可靠性,同时又尽可能地降低编码对读取性能的负面影响。
本文首先介绍了分布式系统的研究现状,研究了主流的架构技术,在介绍了各种数据冗余技术的基础上提出了复制和网络编码结合的方案,在 HDFS 架构下描述了具体的设计。最后对可靠性进行了理论分析和实际仿真,证明了该设计可以达到预期的效果。
-
引用格式
吴昊, 基于HDFS的分布式文件系统数据冗余技术研究, 2011, 西安电子科技大学.
摘录
-
HDFS:Hadoop 是 Apache 基金会支持的一个开源的分布式计算平台项目。基于其的云计算平台的研究正成为一个科研和商业领域的热点问题。HDFS 是 GFS 的开源实现,并有大量的参考文档和实验方式。
- 总体架构:
- HDFS与GFS的异同:
- 相同:
- GFS 和 HDFS 都采用单一主控机+多台工作机的模式,由一台主控机(Master)存储系统全部元数据,并实现数据的分布、复制、备份决策,主控机还实现了元数据的 checkpoint 和操作日志记录及回放功能。工作机存储数据,并根据主控机的 指令进行数据存储、数据迁移和数据计算等。
- .GFS 和 HDFS 都通过数据分块和复制(多副本,一般是 3)来提供更高的可靠性和更高的性能。当其中一个副本不可用时,系统都提供副本自动复制功能。针对数据读多于写的特点,读服务被分配到多个副本所在机器,提供了系统的整 体性能。
- GFS 和 HDFS 都提供了一个树结构的文件系统,实现了类似与 Linux 下的文件复制、改名、移动、创建、删除操作以及简单的权限管理等。
- 不同:
- GFS 最为复杂的部分是对多客户端并发追加同一个文件,即多客户端并发Append 模型。GFS 允许文件被多次或者多个客户端同时打开以追加数据,以记录为单位。假设 GFS 追加记录的大小为 16KB ~ 16MB 之间,平均大小为 1MB,如果每次追加都访问 GFS Master 显然很低效,因此,GFS 通过 Lease 机制将每个Chunk 的写权限授权给 Chunk Server。写 Lease 的含义是 Chunk Server 对某个 Chunk在 Lease 有效期内(假设为 12s)有写权限,拥有 Lease 的 Chunk Server 称为 Primary Chunk Server,如果 Primary Chunk Server 宕机,Lease 有效期过后 Chunk 的写 Lease可以分配给其它 Chunk Server。多客户端并发追加同一个文件导致 Chunk Server需要对记录进行定序,客户端的写操作失败后可能重试,从而产生重复记录,再加上客户端 API 为异步模型,又产生了记录乱序问题。Append 模型下重复记录、乱序等问题加上 Lease 机制,尤其是同一个 Chunk 的 Lease 可能在 Chunk Server之间迁移,极大地提高了系统设计和一致性模型的复杂度。而在 HDFS 中,HDFS文件只允许一次打开并追加数据,客户端先把所有数据写入本地的临时文件中,等到数据量达到一个 Chunk 的大小(通常为 64MB),请求 HDFS Master 分配工作机及 Chunk 编号,将一个 Chunk 的数据一次性写入 HDFS 文件。由于累积 64MB数据才进行实际写 HDFS 系统,对 HDFS Master 造成的压力不大,不需要类似 GFS中的将写 Lease 授权给工作机的机制,且没有了重复记录和乱序的问题,大大地简化了系统的设计。然而,我们必须知道,HDFS 由于不支持 Append 模型带来的很多问题,构建于 HDFS 之上的 Hypertable 和 HBase 需要使用 HDFS 存放表格系统的操作日志,由于 HDFS 的客户端需要攒到 64MB 数据才一次性写入到 HDFS 中,Hypertable 和 HBase 中的表格服务节点(对应于 Bigtable 中的 Tablet Server)如果宕机,部分操作日志没有写入到 HDFS,可能会丢数据。
- Master 单点失效的处理。 GFS 中采用主从模式备份 Master 的系统元数据,当主 Master 失效时,可以通过分布式选举备机接替主 Master 继续对外提供服务,而由于 Replication 及主备切换本身有一定的复杂性,HDFS Master 的持久化数据只写入到本机(可能写入多份存放到 Master 机器的多个磁盘中防止某个磁盘损害),出现故障时需要人工介入。
- 对快照的支持。 GFS 通过内部采用 copy-on-write 的数据结构实现集群快照功能,而 HDFS 不提供快照功能。在大规模分布式系统中,程序有 bug 是很正常的情况,虽然大多数情况下可以修复 bug,不过很难通过补偿操作将系统数据恢复到一致的状态,往往需要底层系统提供快照功能,将系统恢复到最近的某个一致状态。
- 相同:
- 总体架构:
- 随机线性网络编码
-
- 为了保证目标节点对收到的数据包可解,需要保证不同数据包的编码向量线性无关,使用规则化统一化的编码方式往往是不可行的。在分布式环境中,如网络中,有时会存在处于中心地位的节点,网络编码方案中中心节点的作用就是了解网络拓扑,为不同节点决定编码向量。然而在实际的实现中,这 样的要求会使中心节点存储的信息和承受的负载严重偏大,同时网络的拓扑结构在不断发生动态的变化,中心节点难以及时掌控这些变化。因而,实际的网络编码倾向于非集中式的编码。
-
- Galois域:是指一个包含 n 个元素的集合,任意两个元素的加法和乘法后得到元素都在这个集合里,即对加法和乘法是封闭的,并且除零元素外每个元素在这个集合内都有加法逆元素和乘法逆元素,这里 n 是素数也可以是素数的幂,除此之外的 n 无法构成 Galois 域。
- 以$GF(2^4)$为例进行说明,$(1011)_2$和$(0110)_2$相乘,设既约多项式为$x^4+x+1$,$(1011)_2$对应的多项式是$x^3+x+1$,$(0110)_2$对应的多项式$(x^2+x)$,两者相乘,$\left(x^{3}+x+1\right)\left(x^{2}+x\right) \bmod \left(x^{4}+x+1\right)=x^{3}+x^{2}+x+1$,结果为$(1111)_2$。在算法实现较小的域如$GF(2^4)、GF(2^8)、GF(2^{16})$的运算时,可以预先计算出Galois域上的指数和对数表来并存在内存中,计算两个数的加减法时,仍为两个数的异或,计算乘法时等价于通过查表计算两个数的对数和之后再取其和的指数表中的值,同理,计算除法时等价于通过查表计算两个数的对数差之后再取其和的指数表中的值。
-
-
总体架构设计:
-
- 编码放置策略
- 中心节点元数据设计
- 内存中的数据结构
- Block位置信息
- 操作日志
-
- 仿真:
- 环境
- 结果
- 环境






思考
- 主要介绍了HDFS的特点以及与GFS的异同;
- 基于HDFS系统,用随机线性网络编码实现了冗余技术;
- 设计了编码以及相应的放置策略,同时设计了中心节点的元数据包括,数据结构,Blokc位置和操作日志;
- 最后考虑了负载均衡以及在Fedora 13 上用Eclipse进行了仿真。
1.P2P分布式存储系统中冗余策略研究
1.P2P分布式存储系统中冗余策略研究
基本信息
-
期刊论文,《现代计算机》,
-
2009年
-
关键词:
P2P 模型;复制;冗余;纠删码;数据可用性 -
摘要
由于 P2P 系统具有高动态性,为了提高存储的可靠性,必须采用冗余策略,使数据文件以副本的形式分布在系统的多个节点中。 阐述 P2P 分布式存储系统中使用的冗余策略,并分析它们对文件可用性的影响以及在真实 P2P 系统中的应用。
-
引用格式
董辉与雷大军, P2P分布式存储系统中冗余策略研究. 现代计算机(专业版), 2009(09): 第8-10页.
摘录
-
系统的冗余策略主要有复制 (Replication)和纠删码 (Erasure Coding) , 两种方式,而复制策略主要又可分为全文件复制和分块复制两类。
-
数据可用性定义:数据在时间 t 能被访问到的概率。
-
系统节点总数为 n,从中任意取 h 个节点,其中可用的节点个数为 y 的概率会满足二项式分布概率公式:
$$ P(y)=\left(\begin{array}{l} h \ y \end{array}\right) \mu^{y}(1-\mu)^{(h-y)} $$ -
在全文件复制中,假如文件有 c 个副本分布在不同的节点上,c 个副本中至少应该有一个副本有效才能用于恢复数据。 因此,全文件复制的可用性定义为 :
-
分块复制 将文件分割成小块,文件存储负担可由系统中的节点均匀地承担,而且有利于并行下载和负载平衡。 如果将文件划分成 b 块,并对每块生成 c 个副本,文件可用性可定义为:
$$ P(y \geqslant 1)=\left(1-(1-\mu)^{c}\right)^{b} $$ -
纠删码:
-
三种方式的比较:
-
P2P系统:
- Total Recall ,是圣地亚哥加州州立大学 (UCSD)设计的 P2P 存储系统,设计目标是自动配置系统所需要的各种参数,以避免繁琐且困难的人工设置。系统会根据可用性的需求,基于文件大小、等级以及文件读写请求的访问模式等来自动选择最有效的复制方案和冗余度。小文件采用复制策略和积极修复法,对 大文件采用纠删码和懒惰修复法 。
- OceanStore ,来自Berkeley, 使用了复制和纠删码两种复制策略,一方面使用纠删码存储归档的数据以减小空间和带宽消耗,另一方面使用复制来提高数据访问的效率。
- CFS ,是一种只读存储系统,CFS 系统认为存储空间不是稀缺资源,因此不采用纠删码,而只采用复制方式冗余:将数据实施分块复制,然后用 DHT 直接分发的方式将副本按顺序放置在数据 ID 对应的负责节点及后继节点上,当底层覆盖网络检测到有一个副本丢失时,数据的主节点负责立即再修复出一个副本。



思考
水文,首先分析了冗余的定义和数据可用性的定义,然后分别阐述了全文复制,分块复制以及纠删码的冗余因子及其性能,最后罗列了现有的p2p分布式存储系统采用的冗余策略。可以,当科普看看。
2.基于私有云的数据冗余技术研究
2.基于私有云的数据冗余技术研究
基本信息
-
期刊论文,《电脑知识与技术》
-
2011年
-
关键词:
云存储;数据冗余;纠删码 -
摘要
作为云计算技术的一个分支,云存储的应用逐渐兴起。 文章介绍了私有云存储的概念和特点,在此基础上结合私有云存储的环境,对几种数据冗余方式进行了分析比较。
-
引用格式
周游等, 基于私有云的数据冗余技术研究. 电脑知识与技术, 2011. 7(01): 第16-19页.
摘录
- 纠删码:具备识别错码和纠正错码的功能,当错码超过纠正范围时可把无法纠错的信息删除。 纠删码将一份数据分解成 m 块,通过编码将其转化成 n 块,只需要 t(t≥m)块数据存在,便可以恢复出原始数据。
- 纠删码冗余种类:
-
RS(Reed-solomon)编码:由 Reed 和 Solomon 在 1960 年提出,它是一种前向纠错算法,能够从收到的 t 个数据块中恢复原有的数据,主要用于数据通信和存储中。 RS 编码具有可靠性高、任意冗余度、空间最优等特点,并且实现简单。 编解码性能较低是 RS 编码的缺点,由于所有运算都是在伽罗华域中展开,在进行乘除运算时需要进行两次伽罗华域转换,使
得计算复杂,而不适合对实存储系时性能要求高的统使用。
- 基于范德蒙德矩阵的 RS 编码(VRS)
- 基于柯西矩阵的 RS 编码(CRS) ,CRS 在 VRS 基础上有两个改进,一是使用柯西矩阵代替范德蒙德矩阵,二是把 GF 域上的运算全部转换为异或运算。柯西编码极大地提高了 RS 编码的 性能。
- LDPC编码(Low-Density Parity-Check)是一种线性分组编码,其校验矩阵0多1少,呈现稀疏矩阵特征,因此称为低密度校验码。
- Tornado编码,是一种速度非常快的LDPC编码,基于稀疏矩阵,对数据对象及与其详尽的数据对象进行异或操作生成校验码,并且通过不规则级联二分图对校验码进行编码,使得可靠性得到保证。由于Tornado校验矩阵的稀疏性,其编解码性能呈线性增长,具有比RS编解码更优良的性能,但由于Digital Fountain对算法版权的保护,有关资料较少。且被证明必须获得$k(1+\varepsilon )$个节点才能完成解码,相比较,RS只需要$k$个。
-
RS(Reed-solomon)编码:由 Reed 和 Solomon 在 1960 年提出,它是一种前向纠错算法,能够从收到的 t 个数据块中恢复原有的数据,主要用于数据通信和存储中。 RS 编码具有可靠性高、任意冗余度、空间最优等特点,并且实现简单。 编解码性能较低是 RS 编码的缺点,由于所有运算都是在伽罗华域中展开,在进行乘除运算时需要进行两次伽罗华域转换,使
得计算复杂,而不适合对实存储系时性能要求高的统使用。
- RAID冗余:RAID(Redundant Array of Independent Disks)早期使用最简单的奇偶校验码保证数据的可靠性,从RAID0-RAID6,RAID5在N+1的情况下,允许出现1块磁盘损坏,而RAID6中则允许出现2块磁盘损坏。
思考
- 了解到纠删码的种类以及除了纠删码冗余之外还有RAID冗余;
- 总的来说,完全副本实现简单,在高动态的系统,节点平均可用性低的系统中还是适合纠删码,其中基于柯西矩阵的 RS 编码(CRS)又更好,反之,纠删码只会增加系统设计的复杂性;
- RAID有广泛运用的历史,但不能满足新的存储需求。
1.基于P2P的分布式存储的研究与实现
1.基于P2P的分布式存储的研究与实现
基本信息
-
硕士论文
-
2004年
-
关键词:
P2P 模型;资源查找;冗余 -
摘要
“基于 P2P 的分布式存储系统”是四川省科技厅“青年软件创新工程”资助项目。
本系统在 P2P 的基础上采用了 Server-to-Server 的模型,各个 Server 之间完全对等,通过路由关系连接起来。客户从任何一个 Server 上都可以查询并访问系统中的所有文件,同时每一个 Server 上的文件及其存储信息都被冗余备份到其他Server 上,提供了较高的容错性。此外,本系统的文件存储信息采用 XML 方式存放,有利于 WEB 方式发布和查询信息。
在基础理论中,首先介绍了 I/O 模型,并对几种网络服务器内部架构进行了分析和比较,最后介绍了 XML 语言的基本概念和相关语法。随后,我们讨论了P2P 的各种资源查找算法,并详细描述了本系统使用的基于关键字的路由模型的主要算法和设计。在对网络分布存储及其技术研究的基础上,我们设计了一个基于 P2P 模型的分布式存储系统。本系统采用分层结构,以路由层作为基础,在其上实现了对象传输层和命令解释层。在命令解释层实现了一个基于线程池的任务驱动的服务器框架模型,它监听 UDP 端口,并维护一个全局任务队列,所有收到的命令都作为一个任务放到任务队列中由处理线程进行命令分发,调用对象传输层处理;在对象传输层实现了资源查找算法,设计并实现了一套基于 UDP 的传输协议用于客户与服务器之间,以及服务器内部之间的命令交互,同时还设计了以 XML 方式存放的文件存储指针格式;最后,实现了一个定时模块,使得各种网络延时较大的任务可以通过定时队列得到异步响应,从而释放相应的处理线程,并且对于延时太久的任务可以实现超时重发。
通过对本系统的初步测试,表明该系统实现了设计目标并具有较好的性能。
-
引用格式
陈刚, 基于P2P的分布式存储的研究与实现, 2004, 电子科技大学.
摘录
-
Server-to-Server模型,各个Server之间完全对等,通过路由关系连接起来,同时每一个 Server 上的文件及其存储信息都被冗余备份到其他Server 上。 - 在本系统中冗余备份主要包括:实际文件的冗余和文件存储指针的冗余。
- 实际文件的冗余包括分片冗余和拷贝冗余。这部分工作是上传服务器在文件上传成功后,调用冗余备份模块,进行冗余存储,并将冗余信息记录在文件存储指针中,这些对于用户来说都是透明的。
- 如果是分片存储,在下载时需要客户端的支持。文件存储指针的冗余则分为三个层次。
- 第一个层次是在通过文件名哈希算法计算出文件
$ID$ 值时,对这个$ID$ 值加上两个偏移量,从而得到另外两个$ID$ ,这样文件存储指针按照三个$ID$ 值分别存放在三个不同的服务器上,从而实现冗余。偏移量的选取跟$ID$ 值的取值空间有关,假设取值空间中最大值为$ID_{max}$,则两个偏移量为$\dfrac{1}{3}ID_{max}$,$\dfrac{2}{3}ID_{max}$,由于本系统的路由算法跟距离相关,$ID$ 值相差越大,节点的实际距离也越大,因此这样取值的偏移量可以使的三个拷贝尽量存放在相隔较远的节点。 - 第二个层次的冗余是当文件存储指针存放到某个节点服务器后,它会再备份到跟它
$ID$ 值最相近的两个节点上,一个是$ID$ 值比它大,一个$ID$ 值比它小,因为如果这个节点出现故障时,那么原来那些把它作为相关节点的文件,当再次进行路由定位时将会定位到跟它$ID$ 值最接近的两个节点上,而这两个节点就接替它成为那些文件的相关节点。 - 第三个层次是通过高速缓存来冗余备份,具体来说就是,每个节点都建立自己的高速缓存,在一个文件存储指针从初始节点到目的节点的路由过程中,所经过的所有节点都把该存储指针在自己的高速缓存中留一份拷贝。这样当某个节点查询一个文件时,查询报文在路由过程中将会在每个路由节点的高速缓存中查找,如果发现有匹配项,就可以立刻返回,最坏的情况是直到相关节点才找到。当然,如果查找高速缓存没有命中的话反而会延缓查找过程,为了防止这种情况出现,我们采用旁路技术,即在每个路由节点查找高速缓存的时候,不管是否命中缓存,都直接把查询报文向下一个节点转发。这样就不会因为没有命中缓存而延缓查询过程,但是如果有多个节点命中缓存的话,就会产生多份冗余报文发送给请求服务器。不过对于路由节点不多的情况下,是可以忍受的。
- 如图 3-2所示,当文件 Myfile 存储到 A 节点后,根据资源定位算法,它的文件存储指针被存放到 F 节点上。当我们在 B 节点访问 Myfile 时,如果没有高速缓存,则需要从 B 路由到 F,才能从 F 节点上获得 Myfile 的文件存储指针,然后 B 再跟 A连接,访问到 Myfile;而引入高速缓存后,在从 A 路由到 F 节点的过程中, C、D 节点上的高速缓存中就保存了 Myfile 的文件存储指针拷贝,此时 B 在路由到C 时就在 C 的高速缓存中发现了 Myfile 的存储指针,从而立刻返回到 B,然后 B就可以直接从 A 中访问到 Myfile 了。
-
- 第一个层次是在通过文件名哈希算法计算出文件
- 在系统设计的时候我们的目标是在存放文件存储指针的服务器故障的时候,通过冗余备份信息获得文件存储指针。

思考
2.Peer-to-Peer存储系统中一种高效的数据维护方案
2.Peer-to-Peer存储系统中一种高效的数据维护方案
基本信息
-
软件学报
-
2009年
-
关键词:
对等网络存储;数据维护;永久失效;暂时失效;失效检测;带宽优化 -
摘要
提出一套完整的数据维护方案.该方案建立在 P2P 环境动态性特点的基础上.一方面,该方案考虑了节点动态性差异,它基于不同的动态性作相应的数据冗余,能够用更少的冗余开销来保证数据的目标可用性;
另一方面,该方案给出如何利用判别器来区分永久失效和暂时失效,以减少由于不必要的数据修复而带来的额外修复开销.通过在真实 P2P 系统 Maze 上的实验结果表明,该方案比目前主流的方案能够节省大约 80%的数据维护带宽。
-
引用格式
杨智, 朱君与代亚非, Peer-to-Peer存储系统中一种高效的数据维护方案. 软件学报, 2009. 20(01): 第80-95页.
摘录
-
本文基于 P2P 系统节点的动态性规律,研究存储节点的选择方案,以降低系统屏蔽暂时失效所需的数据冗余度,同时;本文将研究如何使用永久失效判别器来检测系统中节点的永久失效,以降低由于系统无法区分暂时失效和永久失效所带来的额外开销.本文的主要贡献如下:
- 本文考虑了节点的动态性差异,提出一种基于节点动态性的数据分发算法,它把数据放在动态性相近的节点上,并精确计算出相应的冗余度.相对于传统的随机分发算法,能够在 P2P 这种高动态环境下用更少的冗余开销达到数据的目标可用性.
- 如何在时间阈值判别器中设置时间阈值来区分永久和暂时失效是当前 P2P 存储系统研究中的一个难题,本文基于漏判抵消误判的思想,给出了永久失效判别器中参数设置的统一原则,使得时间阈值判别器的性能接近于最优的理想判别器.
- 为了提高判别器精度,本文提出了一种新的永久失效判别器:基于节点离开概率的判别器.它在不同的离线长度下给出相应的永久失效概率,而不是只用一个阈值来确定性地判别永久失效,因此,本文提出的判别器比时间阈值判别器更为精确.
-
冗余方式主要包含两类:副本和纠删码(erasure code).
- 参数是$(m,n)$的纠删码将原始文件分成$ m$ 个碎片,然后编码成$ n(n>m)$ 个碎片,并保证其中任意
$m$ 个碎片都可以重构文件.最早人们用量化的方法分析了纠删码和副本方式冗余对系统可靠性的影响,但考虑的是较为稳定的环境.之后,研究者重新考察了纠删码对 P2P 存储 系统可用性的影响,更关注高动态性的系统,指出对于节点可用性比较低的系统,用副本的方式较好,但并没有考虑修复带宽开销[14].关注在 P2P 系统中两种冗余方式下的修复开销,指出副本方式在高动态系统中更为有效.更为复杂的方式是采用副本和纠删码结合的方式,文献[15]的研究表明,这种方式能够更好地优化修复带宽 .
- 参数是$(m,n)$的纠删码将原始文件分成$ m$ 个碎片,然后编码成$ n(n>m)$ 个碎片,并保证其中任意
-
数据放置策略决定一个数据对象的副本存放在哪些节点上.数据放置策略可以分为两类:随机放置策略和选择放置策略
-
目前,主流的数据冗余策略是随机分发数据,然后利用节点在线概率的平均值计算出数据的目标冗余度. 但这种方法却忽略了节点间动态性的差异.
- 冗余度定义为冗余后的数据量与原始数据量的比值.对于副本方式,冗余度就等于数据副本的个数.对于参数是(m,n)的纠删码,冗余度为 n/m.
- 目标冗余度是指能够达到数据目标可用性的最小冗余度
-
本文提出一种基于节点动态性的数据分发算法,它采用与主流方法相同的可用性计算模型,但根据不同的节点动态性产生不同的冗余度,更好地适用于节点动态性差异较大的 P2P 系统.
-
时间阈值判别器,本文将回答如何自动、合理地设置时间阈值τ的难题.另外,还提出一种新的永久错误判别器:基于概率的判别器.基于真实 P2P 系统运行日志的模拟实验表明,这两种判别器的性能都接近最优的理想判断器(没有误判和漏判的判断器).
-
系统的开销模型 :冗余和修复会耗费系统的资源,从而产生冗余数据或修复数据,这种开销称为系统维护开销。作出如下假设
- 假设节点间是相互独立的;
- 节点加入和永久离开系统的平均速率是恒定的;
- 系统中节点的数量是稳定的。
-
系统的开销模型具体细节
-
数据的冗余优化:目前,主流的数据冗余算法是在整个系统里随机选择节点分发数据,然后利用节点在线概率的平均值计算出数据的目标冗余度 ,本节提出的优化算法仍能保证系统中节点的负载平衡(即分发后每个节点上存储相等的数据量),而不是通过不断将负载移向高可用节点来减少冗余度。
-
节点动态性差异对$k_L$的影响:提出一种新的衡量目标冗余度的算法,相对主流算法在理论上能够节省 30%左右的带宽
$$ I=1-\frac{\tilde{k}{L}}{k{L}}=1-\frac{\int_{0}^{1} h f(h) \mathrm{d} h}{\int_{0}^{1}-\log (1-h) f(h) \mathrm{d} h} $$ -
基于节点动态性的概率放置算法:
-
-
数据修复优化
-
基于判别器的数据修复算法
-
Timeout(
$\tau$ ) ,时间阈值判别器,属于确定型永久判别器 $$ f(\text {node,t})=\left{\begin{array}{ll} A, & \text { if } d(t)=0 \ U, & \text { if } 0<d(t)<\tau \ D, & \text { if } d(t) \geq \tau \end{array}\right. $$ -
Probability($f(\xi)$),概率判别器,$f(\xi)$)是一个以节点离线时间$\xi$为 自 变 量 的 概 率 函 数
$$ f(\text {node,t})=\left{\begin{array}{ll} Z=A, & \text { if } d(t)=0 \ P(Z=U)=1-f(d(t)), & \text { if } d(t)>0 \ P(Z=D)=f(d(t)), & \text { if } d(t)>0 \end{array}\right. $$ -
-
-
误判和漏判对$k_R$的影响
-
两类永久判别器中参数的设置
-
-
-
-







思考
- 算法构件:
- 冗余算法
- 纠删码Erasure code
- 副本冗余方式
- 数据的随机分发方式
- 修复算法
- 积极修复
- 懒惰修复
- 冗余算法
- 服务构件:
- 数据目录服务:Total Recall 中,每个对象都由一个节点来负责,称为 Master.Master 知道它所负责的对象的每个副本存放在哪个节点上,维护了副本与系统中节点的映射关系.当用户(对应图中的 client)读取数据时,首先联系 Master,获取副本的位置,然后再联系存储副本的节点(对应图中的 Data storage hosts)下载 。
- 节点监控目录:系统中存储每个存储副本的节点向其对应的存储索引的 Master 节点定期发送心跳信息,汇报自己的在线状态.因此,Master 也维护了节点的在线状态,它同时是目录服务和监控服务的提供者.当用户读取数据时,Master 可以用这两种信息告诉用户一个 当前可用的副本的位置.
-
- 系统的运行过程如下:数据对象最初存入系统时,冗余算法被调用.冗余算法根据数据的目标可用性并通过监控服务统计出的节点动态性为对象产生一个配置,包括冗余方式、冗余度和放置策略.当数据存入系统后,系统通过目录服务建立副本和节点的对应关系.对于每个数据对象,系统定期地通过目录服务和监控服务查看存放其副本的节点失效情况,以评估对象的冗余度.如果冗余度低于能够保证目标可用性的最低冗余度,则系统触发修复并调用修复算法产生新的副本。

到公司后这个项目的更新就有点迟缓了,按理说到公司后大量的工作涌来应该有更多关于各种研究工作的内容可以记录,但事实恰恰相反,心事太多,做了不少事情,但更多地只是想写一旦心事。近来的事情大致可以罗列一下吧。
1️⃣ 博客又重新修缮了一下,更多地更重要的是对这个相识的增加更新。说道博客,也帮小治整了老久的博客,我们已经无聊到这种地步了吗?
2️⃣ 2号下午,新认了个Ai的徒弟,顺便大家一起花了一下午设计了实验室的各种版本的图标。如下:





3️⃣ 在overleaf上创造了我们实验室的专属Latex模板。
待续
1️⃣ 用PySimpleGUI实现一个简易的分布式计算系统——简易多机协同计算原型系统(Simply Multi-Machine Collaborative Computing)
2️⃣ Adobe Illustrator自制苏大计科院院徽
3️⃣ 全国人社窗口单位业务技能在线自动答题——全国人社自动学习机
少年不识愁滋味,爱上层楼。爱上层楼。为赋新词强说愁。
而今识尽愁滋味,欲说还休。欲说还休。却道天凉好个秋。
真的难,是真的难。
这半个月过的是真的辛酸,一忽疹疾缠身,一忽又骑车飞摔,蹭的皮开肉绽。身体动弹不得,疹疾又致全身不得按宁。着实不知如何是好,现如今母上也奔赴都市生活,不知不觉,这段儿时至现在都未曾体验过的与母上一起生活这么久的时光已然结束了。激动的三月,慵懒的四月,以前未曾想到会有这样的一段怀念终身的生活,原以为这样的生活只有很多年后的年老之时才可体验。如今只因其过于美好,但终究是要结束的,即使我迷恋这样的生活,但内心的忧虑却也不断地在增加,再美好的时光,但总也要面对现实的压迫的。它的日复一日,每天的日常又是如此的重复,母亲终日看着小说,而我终日地在楼上看着电脑,虽然不舍,但这样的生活终究是不平衡的,我们都不应该被束缚在这里,虽然我们幸福地平平淡淡地陪伴在彼此左右,但此时的它应该是短暂的,我们彼此都有应该去做的事情,于当前,它只是看上去那么平静罢了,可我们还未实现的东西太多了,这样的生活提前来到了,幸福了但也徒增了很多不安。
1️⃣ 接的爬虫作业(¥500),应该是利兹大学的,爬取既定网站的所有网页,为每次单词创造包含出现位置以及词频的反向索引等等,写了篇文章:简单地打造一个搜索工具——爬取所有网页并创造单词的反向索引
2️⃣ 帮学妹写了一个遗传算法,地铁大小交路优化模型的遗传算法求解
3️⃣ 接了法学院关于垃圾分类的视频剪辑(¥500),改的头有点发晕,反馈还是很Nice的。链接: 垃圾分类 提取码: 2hbi
4️⃣ 近期讲座汇总:
- 人工智能前沿与交叉_李凡长_2020-05-08 提取码: tre6
- 功能纳米与软物质研究院讲座_仲启轩_2020-05-10 提取码: k5u5
- 知识图谱讲座_李直旭_2020-05-11 提取码: pzaj
时间过的真快,不知不觉,已经来到了这充满谎言的时代的终点。干了点什么呢,记忆逐渐有些模糊不清了。哦,对,因为之前我参加了一个组队学习的活动,因此认识了一些队友,最近队友接单发现没时间做,就拜托我完成。我因此也发现一个代写各种算法作业的地方,第一份任务很满意,从零写一个朴素贝叶斯分类器,一天写完赚了400,还是挺酸爽的。后来又干了什么呢?不记得就是大概是各种琐事缠身,也许这就是孤独的常态。完成了HPC的三个作业,做了一个视频,录了一个演讲。
1️⃣ 实现了三个作业,高性能分布式计算(HPC)作业1——节点实时通信、高性能分布式计算(HPC)作业2——节点通信,发布计算任务、高性能分布式计算(HPC)作业3——节点通信,发布计算任务,并在计算任务中阻塞。
2️⃣ 从零实现一个朴素贝叶斯分类器为学生分班,发了CSDN,从零实现朴素贝叶斯分类器(离散情况)——以学生分班为例
3️⃣ 最近pyq充斥了各种问卷星调查问卷,所以写了个秒填爬虫。利用Selenium秒填朋友圈各种问卷星调查问卷
4️⃣ 关于剪的研会的云采访视频,已经上传到B站,点击下方图片跳转。

5️⃣ 近期的一些图片。


至此,一周的「ONE」的线上实习也接近了尾声。
这次活动,很明显是一个双赢的活动。有几个点想表达一下:
1️⃣ 作为一个「ONE」8年的老用户,还是挺激动能有这样的机会的。那是在高中语文课上,“遥远”的语文老师推荐给我们的,至那以后它就陪伴在我周围。
2️⃣ 这次活动所有人也经历了一开始的满腔热情,到后来在日常生活中,没有声息的交流后面渐渐失去热情的过程。当然这是所有小组活动的通病,更别提一群互不相识的陌生人之间的合作了。
3️⃣ 虽然我对新媒体的热情并不是那么高涨,我内心只不过希望我的文字能得到少部分人的共鸣反应就足够了。「ONE」的有些内容于我有强烈的共鸣,自然我也想通过它来理解如何获得产生网络时代持续不断共鸣文字的能力。
4️⃣ 最后一个任务我们没有完成的很好,因为最后坚持下来的人越来越少,大家你一言我一语,甚至出现有人觉得自己被冷落了,拒绝交流,开小窗交流,然后让组长转达的骚操作。不过至少跟以往学校的小组活动一样,我完成了大部分工作,以往是这样,以后亦是如此。
最后感谢那些与我一同坚持到最后的队友,感谢「ONE」!有缘,江湖见!






时光匆匆,又过了许多个日夜。感觉也没干啥,除了搞了个有颜色的项目外,刚参加了「one」线上实习已经开始了,希望这一周能有所收获吧。
1️⃣ AutoS&D
2️⃣ 「one」的实习活动,第一个任务是活动策划分析报告。我选取了一个心理测试和一个Datawhale的线上组队学习项目,写在了简书上「one」线上实习任务一 活动策划分析报告

3️⃣ 天池比赛也结束了,得了一些虚名。



1️⃣ 天池比赛的第二个任务搞定,写完文章天池_二手车价格预测_Task3_特征工程
关于本任务总结的脑图:
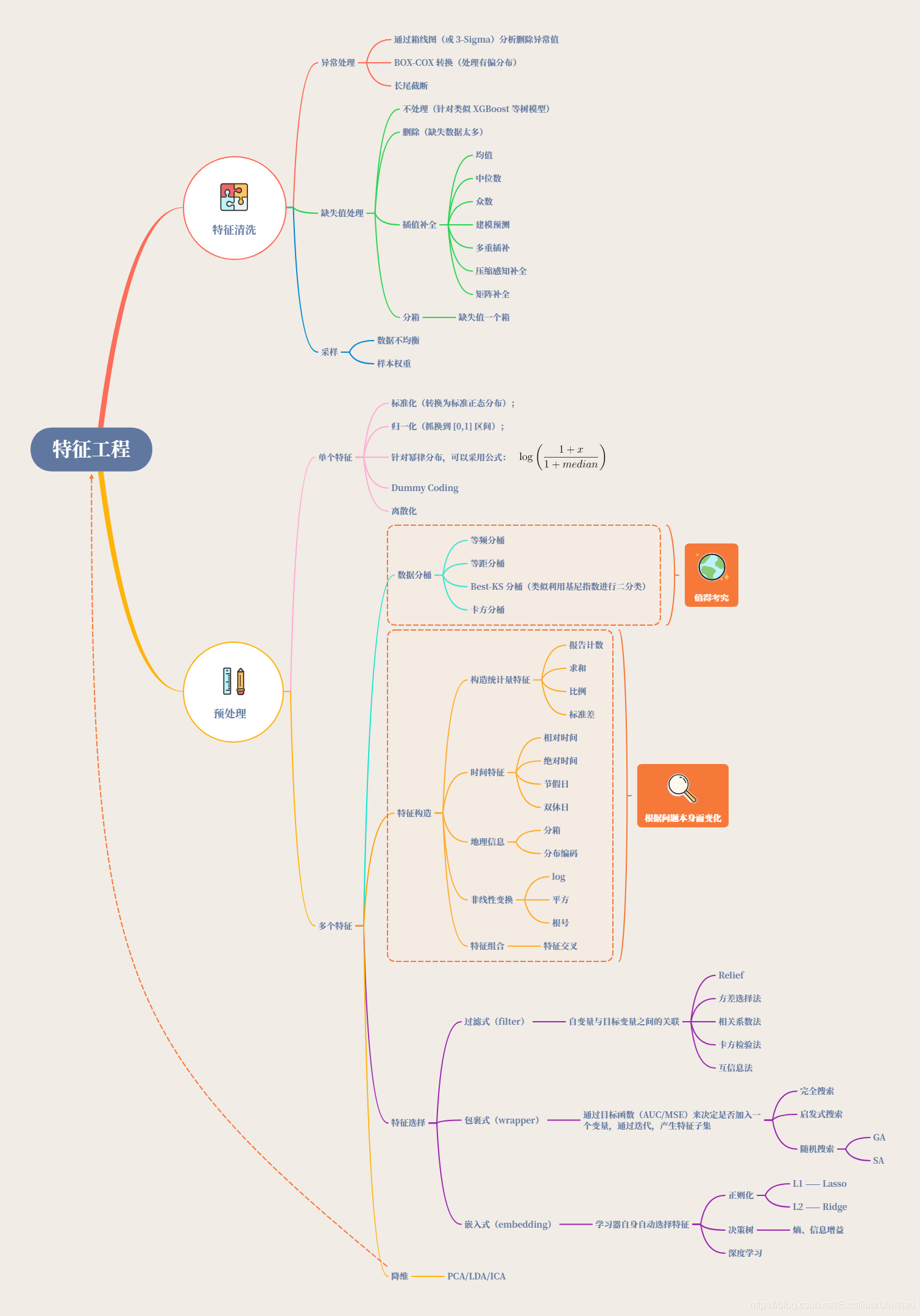
2️⃣ 3天工作总结
- 天池比赛 ❎3️⃣
- Daily-Plan-In-Graduate-Life项目的更新 ❎3️⃣
3️⃣ 明日计划

终于有机会更新了,这后面的5天里,我只做了一件事,就是改造个人博客网站。改到天昏地暗,改到海枯石烂,改到脾气逐渐暴躁,发髻逐渐凌乱,面目逐渐可憎,键盘逐渐散架(砸的)。
1️⃣ 最近重新修缮鼓捣个人博客,首先大刀阔斧地改造背景以及动态效果,移除那些没有用的js动画,当代世界的快节奏,人们已经不再喜欢复杂,充斥颗粒的东西了,内容至上,简约独特,这是永远的核心。其次加入友链,虽然朋友们没有什么博客,但他们有qq空间和B站啊。最重要的是加入具有大师锋范的相册,qq空间的相册太难看,微信又没有相册,B站又不适合,简书,csdn,github都是技术,也不适合,还是这里最安全最炫酷。学习了不少css的知识,最重要的是自己给自己增加了更新的动力与压力吧。——发自于3.25号的打卡
2️⃣ 8天工作总结
-
博客修缮完毕
-
天池比赛的特征工程做了一半,勉强打卡,还得继续磕 ❎2️⃣
-
Daily-Plan-In-Graduate-Life项目的更新 ❎2️⃣
1️⃣ 花了一天时间完成了比赛项目的数据分析工作,写了blog分别在kemo以及csdn。
2️⃣ 工作总结
- Daily-Plan-In-Graduate-Life项目的更新 ❎1️⃣
- 天池比赛的研究,数据分析 ❎1️⃣
这两天没顾得上学
go,总觉得有些事没思考清楚。
1️⃣ 忧心论文,所以看了知网研学的哈工大专场-论文阅读写作与学术规范,要算收获的话是以前没注意到的知网的分析分类功能,主要问题还是怎样找自己的研究方向吧。
2️⃣ 有点想拍点vlog记录生活,为每一天赋予意义。所以看了一下小苏的vlog相机
- 大疆Osmo pocket
- G7XMark2
- GoPro7
- Mac
✈️
嗯,买不起,刚不动。
3️⃣ 关于文献管理工具,目前想用NoteExpress,知网研学以及Mendeley的组合。
4️⃣ 参与了datawhale与天池举办的一个天池新手入门赛,组了个小队,希望这半个月能在这个完整的流程中有所收获。
1️⃣ 继续go的学习
今日学习的思维导图:

具体内容如下:
- 容器
- 数组
- 多维数组
- 切片
- map
- 列表list
- nil
具体内容移步到实时更新的Go-Learning-20200318
1️⃣ 开始了go的学习
今日学习的思维导图:

具体如下:
- 基本语法
- 变量声明
- 变量的初始化
- 多变量同时赋值
- 匿名变量:下划线“_”
- 变量作用域(没什么好讲的,跟
python类似) - 浮点类型
- 字符串(一个不可改变的字节序列)
- 指针
- 常量(
const) type关键字(类型别名)- 关键字
- 运算优先级
具体内容移步到实时更新的Go-Learning-20200317
1️⃣ 把毕设以及代码以及毕设期间代写毕设的代码上传到Graduation-Design-and-MATLAB-Code
1️⃣ !!!∑(゚Д゚ノ)ノ参与了一个Github上近一周Trending排名第一的项目(fucking-algorithm)的翻译工作。
该项目主要是将Leetcode上的算法进行结构化,框架化的解读,项目作者将自己一年刷题的经验与心得整合为一份gitbook并持续更新,用动图,编码,通俗的语言对各种经典的动态规划,数据结构,算法思维,并引经据典,旁征博引《算法4》等经典算法著作。
我参与了项目的KMP算法的翻译工作,KMP算法是字符串匹配算法的高效算法,由三位计算机科学界的大佬提出,所以全名为Knuth-Morris-Pratt 算法,它与传统的暴力匹配不同的是,它利用记忆数组存储匹配记忆,以达到快速匹配的目的。目前我已经将我的翻译工作commit,并对该项目进行了pull request并且已经merged,成为了一名Contributor。😊
2️⃣ 写了一下午的HPC作业,在这里HPC_Homework。
- 主要涉及了文件数据的处理工作。在进行高性能分布式计算时,一个最基本的工作就是将数据集成化,有序化,准确地输入到工作流中。
- 在分割文件时会出现很多种情况:如相应的文件不存在,相应的sheet不存在或者无法打开;相应的id出现了重复情况,无法判断何者为原始数据;在sheetn(n>=2)中出现的id不是id的子集;抑或是其余等等情况。所以在处理数据时需要提前考虑到大部分的失败情况,对每一种情况都做相应的措施然后继续推进任务。

1️⃣ 搭建了go的环境包括[VScode 以及 Goland],😫 完成了基本语法的学习,亦即:
- 「数据类型」
- 「循环选择结构」
- 「函数」
- 「等」
2️⃣ get😆到了一个科研神器Grammarly以及Linggle。
3️⃣ Aixcoder 北大出品,必属精品。😈利用DL技术,以历史编码模式为输入,进行智能补全提示。
4️⃣ 比较了好几款文献管理工具, 包括 NoteExpress(适合中文),以及Mendeley, Zotero。三款软件常用的功能都具备,如文献标签整理,快速导入参考文献,自带阅读器,浏览器插件等等,都可用于日常阅读工作。😎
5️⃣ 通过落拓的系列视频是落拓啊-区块链,复习了POW工作量证明机制,哈希碰撞,并且快速实现了一个小型的区块系统。
6️⃣ 「等」,暂时想不来了,哪天想起来再更。🙋♂️

{kind=link}
{kind=link}
{kind=link}