![]()


Author: Henry Ndubuaku
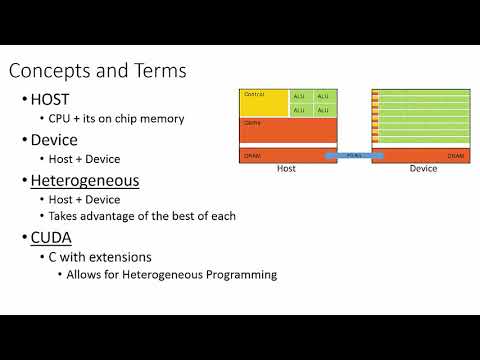
CUDA (Compute Unified Device Architecture) is a parallel computing platform and programming model developed by NVIDIA. It allows software developers to leverage the immense parallel processing power of NVIDIA GPUs (Graphics Processing Units) for general-purpose computing tasks beyond their traditional role in graphics rendering. GPUs are designed with thousands of smaller, more efficient cores optimized for handling multiple tasks simultaneously. This makes them exceptionally well-suited for tasks that can be broken down into many independent operations, such as scientific simulations, machine learning, video processing, and more. CUDA enables substantial speedups compared to traditional CPU-only code for suitable applications. GPUs can process vast amounts of data in parallel, accelerating computations that would take much longer on CPUs. For certain types of workloads, GPUs can be more energy-efficient than CPUs, delivering higher performance per watt.
Host Code (CPU): This is standard C/C++ code that runs on the CPU. It typically includes:
- Initialization of CUDA devices and contexts.
- Allocation of memory on the GPU.
- Transfer of data from CPU to GPU.
- Launching CUDA kernels (functions that execute on the GPU).
- Transfer of results back from GPU to CPU.
- Deallocation of GPU memory.
Device Code (GPU): This code, often written using the CUDA C/C++ extension, is specifically designed to run on the GPU. It defines:
- Kernels: Functions executed in parallel by many GPU threads. Each thread receives a unique thread ID that helps it determine its portion of the work.
- Thread Hierarchy: GPU threads are organized into blocks and grids, allowing for efficient execution across the GPU's architecture.





You can compile and run any file using nvcc <filename> -o output && ./output, but be sure to have a GPU with the appropriate libraries installed. Starting from step 1, we progressively learn CUDA in the context of Mathematics and Machine Learning. Ideal for Researchers and Applied experts hoping to learn how to scale their algorithms on GPUS.