O objetivo desse repositório é oferecer um roteiro de estudo para deep learning, que possa ser utilizado para iniciantes ou para consultas. Sinta-se convidado para colaborar caso tenha algo para compartilhar, criticar ou corrigir.
Atualmente Python é uma das principais linguagens de programação para quem deseja trabalhar com Machine Learning. Esta linguagem oferece uma abstração mais clara e fácil de usar, possibilitando uma curva de aprendizado maior. As melhores bibliotecas de ML mais oferecem interface de aplicação para que você possa programar em Python e, ao executar o código, elas utilizam funções em C/C++ por baixo dos panos, devido à velocidade destas linguagens.
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| Pycubator | Curso | Iniciante | Link | Curso rápido bem completo |
| Python para Zumbis | Curso | Iniciante | Link | Curso básico |
Nesta tabela estão as principais bibliotecas que serão utilizada/explicadas neste tutoria. É importante lembrar que elas não são as únicas, é sempre bom dá oportunidade para outras bibliotecas/linguagens/técnicas.
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| Pandas | Manipulação de dados | Iniciante | Link | Completa para dataset volumosos |
| Numpy | Manipulação de dados | Iniciante | Link | Fácil de usar |
| Pyplot | Visualização | Iniciante | Link | Prática e fácil |
| Plotly | Visualização | Avançado | Link | Gráficos muito bonitos e dinâmicos |
| Sklearn | Machine learning | Avançado | Link | Tem ótimas ferramentas |
| Tensorflow | Deep learning | Avançado | Link | Uma das melhores de deep learning |
Obtenção: O acesso aos dados pode ser realizado de diversas maneiras, seja por um arquivo no seu computador ou por um serviço API online ( como uma requisição HTTP GET). Normalmente, a forma mais comum de obter dados, é por meio de um arquivo .csv.
Exemplo de acesso a dados em arquivo csv. Mais detalhes (link)
import pandas as pd
dataframe = pl.read_csv('local_do_meu_arquivo/arquivo.csv)
print(dataframe.head())
Manipulação de dados : Há diversas bibliotecas para manipular dados no seu código, porém as mais utilizadas em data-science são
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| 28 comandos rápidos | Tutorial | Intermediário | Link | Conteúdo para acesso rápido - bom |
| Introdução ao Pandas | Tutorial | Intermediário | Link | Muito bom para estudar |
| A Complete Introduction | Tutorial | Intermediário | Link | Só use se quiser se aprofundar |
Salvando dados: As vezes é necessário salvar o dataframe pandas ou até mesmo outros dados que você quer manter registrado em arquivo, veja o exemplo para salvar em csv (Mais detalhes link).
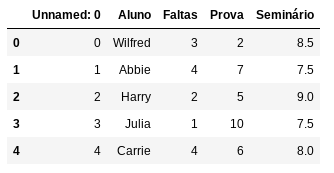
df = pd.DataFrame({'Aluno' : ["Wilfred", "Abbie", "Harry", "Julia", "Carrie"],
'Faltas' : [3,4,2,1,4],
'Prova' : [2,7,5,10,6],
'Seminário': [8.5,7.5,9.0,7.5,8.0]})
df.to_csv("aulas.csv")
pd.read_csv("aulas.csv")
Resultado:
A seção anterior e está se complementam, pois ambas envolvem seus conhecimentos e habilidades para trabalhar com as bibliotecas de manipulação de dados, tais como Pandas, Numpy e etc.
A limpeza consiste na eliminação de dados nulos. Durante a limpeza, é preciso analisar cuidadosamente a distribuição dos dados nulos:
- Eliminação horizontal (de linhas) representa a redução de amostras do dataset, este tipo de eliminação é recomendado quando a linha apresenta muitos campos nulos, o que torna seu uso inviável.
- Eliminação vertical (da coluna, ou feature). Esta redução é recomendada quando várias linhas (várias mesmo) apresentam valores nulos na mesma coluna, para este tipo de remoção é preciso conhecer a relevância da coluna em relação ao problema, pois ao eliminar uma feature importante é possível dificultar o aprendizado do modelo.
Padronização de dados Tipos de dados
A matriz de correlação é uma abordagens mais comuns para uma análise prévia da relação entre as features. Uma correlação positiva indica que ambas as features se movem na mesma direção e uma correlação negativa indica que as features se movem em direções opostas, ou seja, quando o valor de uma feature aumenta, o valor da outra feaure diminui. A correlação também pode ser nula ou zero, o que significa que as variáveis não estão relacionadas.
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| Sobre Correlações | Intermediário | Link | Muito bom | |
| Como selecionar as melhores features | Intermediário | Link | Muito bom |
Features selections Features eliminations
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| An introduction to machine learning with scikit-learn | Tutorial | Avançado | Link | Muito bom |
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| An introduction to machine learning with scikit-learn | Tutorial | Avançado | Link | Muito bom |
Há três principais tipos de aprendizados, supervisionado, não supervisionado e por reforço. O mais comum é o aprendizado supervisionado, porém é sempre bom conhecer os outros, pois vai depender muito da abordagem do seu problema e da disponibilização dos dados.
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| Os Três Tipos de ML | Tutorial | Iniciante | Link | Bom para aprender |
| Tipos de aprendizagem | Tutorial | Iniciante | Link | Bom para aprender |
Mais a frente eu explico resumidamente as métricas utilizando o poster apresentado por Paulo Vasconcelos link. Porém estes links na tabela são ótimos, recomendo a leitura.
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| Avaliando o modelo de ML | Tutorial | Intermediário | Link | Muito bom |
| Matriz de Confusão e AUC ROC | Tutorial | Intermediário | Link | Bem completo |
| As Métricas Mais Populares | Tutorial | Intermediário | Link | Explicação mais direta |
| As Métricas Mais Comuns de ML | Tutorial | Intermediário | Link | Leia todos os 4 postes |
A Matriz de confusão, nos mostras as taxas de acertos e erros do nosso modelo.
Exemplo: Imagine que seu modelo tem que classificar se uma foto é de um gato ou não. Em seu dataset há 50 fotos de gatos e 50 fotos que não são de gatos. Após treinar o modelo, você roda a matriz de confusão e descobre que das 50 fotos de gatos, seu modelo classificou 25 corretamente, enquanto das 50 fotos de não gato, ele classificou 40. A matriz ficaria mais ou menos assim:
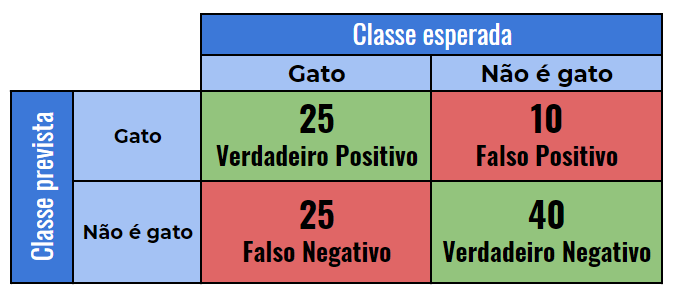
Dessa imagem podemos extrair:
- Verdadeiro Positivo: Quando de casos que o modelo previu como gato e que de fato é gato (acertou).
- Verdadeiro negativo: Quantidade de casos que o modelo previu como não gato, e que de fato não são gatos. (acertou).
- Falso positivo: Quantidade de casos não gatos que ele previu como gato (errou).
- Falso negativo: Quantidade de casos de imagem de não gato que o modelo previu como gato (errou).
Para saber como seu modelo está funcionando, é necessário fazer algum tipo de medição, para isso temos as métricas. Utilizando a matriz apresentada anteriormente, temos:
Acurácia (Accuracy): a proporção de casos que foram corretamente previstos, sejam eles verdadeiro positivo ou verdadeiro negativo. Em nosso exemplo: 65/100 = 0,65
Sensibilidade (Sensibility): a proporção de casos positivos que foram identificados corretamente. No nosso caso, o cálculo é feito da seguinte forma: 25/50 = 0,5 (25 imagens de gatos foram previstas corretamente em um total de 50 imagens);
Especificidade (Specificity): a proporção de casos negativos que foram identificados corretamente. De forma semelhante a sensibilidade, calculamos a especificidade assim: 40/50 = 0,8;
A Receiver Operating Characteristics (ROC), é ilustrada pela plotagem da sensibilidade — a taxa de Verdadeiro Positivo — e a especificidade — a taxa de Falso Positivo. Quanto mais alto e mais distante da linha diagonal a sua curva estiver, melhor.
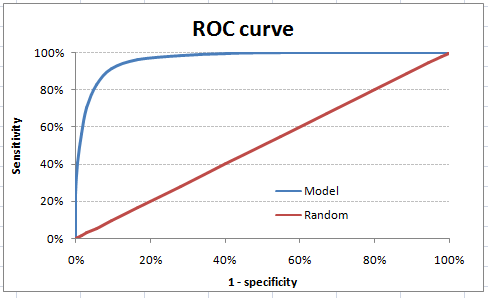
Area Under the ROC Curve (AUC) é um número de 0 a 1 que mostra como seu modelo está performando ao utilizar como base para o cálculo a Taxa de Falso Positivo e a Taxa de Verdadeiro Positivo. interpretá-lo é fácil: quanto mais próximo de 1 esse número estiver, melhor.
Estes métricas dão a ideia de quão bem as classes estão separadas como explica o Marcos Silva no link
Cross-Validation é uma das melhores técnicas para saber se o seu modelo generaliza bem. Quando você executa seu modelo várias vezes, pode receber valores diferentes devido a vários fatores (dataset, quantidade de épocas, modelo ruim e etc). Esse é um tipo de problema que você pode resolver com o Cross-Validation. Essa técnica que visa entender como seu modelo generaliza, ou seja, como ele se comporta quando vai prever um dado que nunca viu.
Cross-Validation serve para criar diferentes conjuntos de treino e teste, treinar o modelo e ter certeza de que ele está performando bem. Nesse caso, ao invés de usarmos apenas um conjunto de teste para validar nosso modelo, utilizaremos N outros a partir dos mesmos dados.
Existem vários métodos de Cross-Validation, aqui vamos ver apenas o K-Fold, esse método consiste em dividir seu dataset K vezes.

No exemplo acima, o dataset foi dividido em 5 partes, para cada uma dessas partes, o modelo irá usar 4 partes (K-1) para treinar, enquanto usará 1 parte para validar. Ao final do processo, quando o modelo iterar/treinar 5 vezes, você terá um verdadeiro score de como seu modelo está generalizando, geralmente ao tirar a média e desvio padrão de todos os treinos realizados. Esse processo faz com que o treino demore um pouco mais, mas é crucial para ter certeza de que seus dados estão generalizando bem.
Apesar das bibliotecas oferecer um alto nível de abstração, deixando que você fique livre da implementação das funções e estruturas da Rede, é importante ter o mínimo de conhecimento sobre o que é e como funciona uma rede neural artificial, uma vez que tais conhecimentos poderão te ajudar a entender como configurar sua rede e como corrigir alguma problemas de eficiência.
AVISO: A maior parte das explicações utilizadas nesta parte foram retiradas do site http://deeplearningbook.com.br/. Recomendo a leitura do conteúdo deles, é muito bom e e completo.
O neurônio artificial assim como a própria rede neural, são estruturas que tentam simular o funcionamento do seus originais biológicos que há no cérebro humano.
Resumidamente, um neurônio artificial é um componente que calcula a soma ponderada de vários inputs, aplica uma função e passa o resultado adiante. Como é ilustrado no diagrama a seguir, o neurônio artificial consiste em um sinal de entrada (representado pela letra X).
continua ...

Topologias de redes Rede MLP
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| Neuronio Artificial | Tutorial | Intermediario | Link | Explicação bem clara |
| Deep-learning book | Curso | Ini - Avançado | Link | Se você tiver tempo, lei todos os capítulos |
Rede Neural Profunda
Rede Neural Convolucional
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| DATA EXPLORATION WITH PYTHON | Tutorial | Avançado | Link | Muito muito completo |
| Mineração de dados | Tutorial | Avançado | Link | Muito bom e completo |
| xx | Curso | Avançado | Link | xx |
| xx | Curso | Avançado | Link | xx |
| Titulo | Tipo | Nível | Link | Descrição |
|---|---|---|---|---|
| Datascience pizza | Dataset | Intermediário | Link | Muito bom para explorar |
| Kaggle | Dataset | Intermediário | Link | Tutoriais, competições datasets e etc. |
| xx | Dataset | Intermediário | Link | xxx |
| xx | Curso | Avançado | Link | xx |