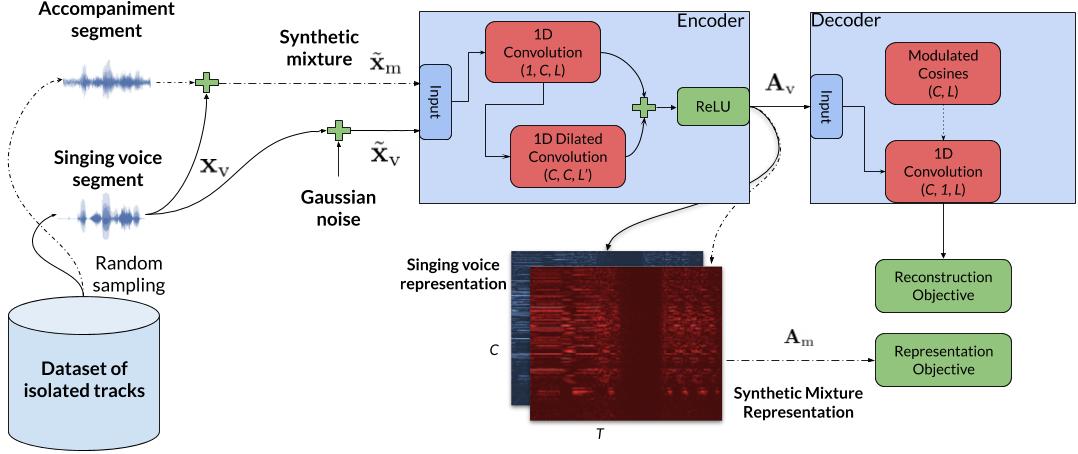
This repository contains the PyTorch (1.4) implementation of our method for representation learning. Our method is based on (convolutional) neural networks, to learn representations from music signals that could be used for singing voice separation. The trick here is that the proposed method is employing cosine functions at the decoding stage. The resulting representation is non-negative and real-valued, and it could employed, fairly easily, by current supervised models for music source separation. The proposed method is inspired by Sinc-Net and dDSP.
S.I. Mimilakis, K. Drossos, G. Schuller
- Code for the neural architectures used in our study and their corresponding minimization objectives (
nn_modules/) - Code for performing the unsupervised training (
scripts/exp_rl_*) - Code for reconstructing the signal(s) (
scripts/exp_fe_test.py) - Code for inspecting the outcome(s) of the training (
scripts/make_plots.py) - Code for visualizing loss functions, reading/writing audio files, and creating batches (
tools/) - Perks (unreported implementations/routines)
- The discriminator-like objective, as a proxy to mutual information, reported here
- Our papers: EUSIPCO-2020 (accepted), arXiv
- Additional results that didn't fit in the EUSIPCO-2020 paper
- The used dataset →
- The optimized models reported in EUSIPCO-2020 →
- The optimized models reported here →
- Download the dataset and declare the path of the downloaded dataset in
tools/helpers.py - Apply any desired changes to the model by tweeking the parameters in
settings/rl_experiment_settings.py - Execute
scripts/exp_rl_vanilla.pyfor the basic method - Execute
scripts/exp_rl_sinkhorn.pyfor the extended method, using Sinkhorn distances
- Download the dataset and declare the path of the downloaded dataset in
tools/helpers.py - Download the results and place them under the
resultsfolder - Load up the desired model by declaring the experiment id in
settings/rl_experiment_settings.py(e.g.r-mcos8) - Execute
scripts/exp_fe_test.py(some arguments for plotting and file writing are necesary)
If you find this code useful for your research, cite our papers:
@inproceedings{mim20_uirl_eusipco,
author={S. I. Mimilakis and K. Drossos and G. Schuller},
title={Unsupervised Interpretable Representation Learning for Singing Voice Separation},
year={2020},
booktitle={Proceedings of the 27th European Signal Processing Conference (EUSIPCO 2020)}
} @misc{mimilakis2020revisiting,
title={Revisiting Representation Learning for Singing Voice Separation with Sinkhorn Distances},
author={S. I. Mimilakis and K. Drossos and G. Schuller},
year={2020},
eprint={2007.02780},
archivePrefix={arXiv},
primaryClass={cs.SD}
}Stylianos Ioannis Mimilakis is supported in part by the German Research Foundation (AB 675/2-1, MU 2686/11-1).
MIT