This tutorial is based on the xarray in 45 minutes https://tutorial.xarray.dev/overview/xarray-in-45-min.html
In this lesson, we discuss cover the basics of Raster analysis data structures. By the end of the lesson, we will be able to:
- Understand the basic data structures in Julia
- Inspect
DimArrayandDimStackobjects. - Read and write netCDF files using Rasters.jl.
- Understand that there are many packages that build on top of xarray
We'll start by reviewing the various components of the Xarray data model, represented here visually:
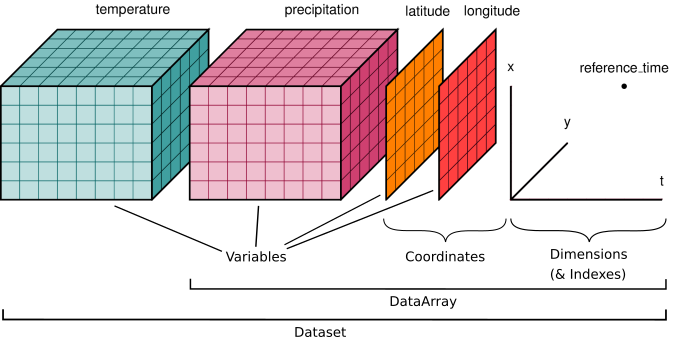
As example data, we use the data in the xarray-data repository.
Here we'll use air temperature from the National Center for Environmental Prediction. Xarray objects have convenient HTML representations to give an overview of what we're working with:
Before we can start we need to activate the current environment.
using Pkg
Pkg.activate(@__DIR__)using Rasters
using NCDatasets
path = "data/air_temperature.nc"
# First we download the data locally if needed.
if !isfile(path)
path = download("https://github.com/pydata/xarray-data/blob/master/air_temperature.nc", "air_temperature.nc")
end
# Now we can open the data as a RasterStack
ds = RasterStack(path)
Many DimArrays!
DimStacks are dictionary-like containers of "DimArray"s. They are a mapping of variable name to DimArray. The RasterStack is a special case of a DimStack with some geospatial information. The DimArray s in the DimStack can share dimensions butdon't have all the same dimensionality. If layers share a dimension name, this dimension is only stored once for the whole DimStack.
# pull out "air" dataarray with dictionary syntax
ds["air"]
You can save some typing by using the "attribute" or "dot" notation and using tab completion.
# pull out dataarray using dot notation
ds.air
data + (a lot of) metadata
da = ds.air
Rasters.name(da)
dims(da) correspond to the axes of your data.
In this case we have 2 spatial dimensions (X and Y) and one temporal dimension (Ti).
dims(da)
You can also extract a single dimension.
# extracting coordinate variables
dims(da, X)
It is useful to think of the values in the dimensions as axis "labels" such as "tick labels" in a figure. These are coordinate locations on a grid at which you have data.
metadata is a metadata object that can hold arbitrary attributes that describe the underlying data.
metadata(da)
# assign your own attributes!
metadata(da)["myattrs"] = "Mine"
A DimensionalData data structures wrap underlying simpler array-like data structures. These arrays have to fit into the Julia Array interface but can be either in memory arrays or DiskArray.jl arrays for lazy access or part of Xarray is quite extensible allowing for distributed array, GPU arrays, sparse arrays, arrays with units etc. We'll briefly look at this later in this tutorial.
To access the underlying data use the parent function:
parent(da)
# what is the type of the underlying data
typeof(parent(da))
We can change the underlying data type by using the lazy keyword for opening the data. This is especially helpful for very large data or data that is hosted online where we would not want to download the whole dataset before starting the analysis.
dsl = RasterStack(path, lazy=true)
dal = dsl.air
typeof(parent(dal))
DimensionalData provides two main data structures:
DimArraysthat wrap underlying data containers and contain associated metadata in theDimStacksthat are dictionary-like containers of DataArrays
DimArrays contain underlying arrays and associated metadata:
- Name
- Dimension names
- Lookup values
- Metadata
Metadata provides context and provides code that is more legible. This reduces the likelihood of errors from typos and makes analysis more intuitive and fun!
# plot the first timestep
lon = ds.air.dims[1].val.data # Vector
lat = ds.air.dims[2].val.data # Vector
temp = parent(da) # vector
using GLMakie
heatmap(lon, lat, temp[1, :, :])
using Statistics
mean(temp, dims=3)# On what dimensions did we apply the reduction? I can't tell by looking at this line.
How readable is this code?
plot(ds.air[Ti=1])
Use dimension names instead of axis numbers
plot((mean(ds.air, dims=Ti)[Ti=1]))
DimensionalData supports
- label-based indexing using
Selectors - position-based indexing using
Integer
See the Documentation about Selectors for more.
DimensionalData implements label based indexing where you can use the name of the dimension and also the labels for the entries in the dimension.
# here's what our dataset looks like
ds
# We can extract the Time dimension
dims(ds, Ti)
# pull out data for all of 2013-May
ds[Ti=Where(x->yearmonth(x) == (2013, 5))]
# demonstrate slicing, extract all time slices between to given dates
ds[Ti=Date(2013,5,1)..Date(2013,8,1)]
# demonstrate "nearest" indexing
ds[X=Near(240.2)]
# "nearest indexing at multiple points"
ds[X=Near([240.125, 234]), Y=Near([40.1, 50.1])]
These selectors can be mixed for different dimensions. So that we could have a Where selection for time and a nearest neighbor selection in space.
This is similar to usual array indexing array[1, 2, 3] but with the power of named
dimensions!
# pull out time index 0, lat index 2, and lon index 3
ds.air[Ti=1, Y=2, X=3] # much better than ds.air[3, 2, 1]
# demonstrate slicing
ds.air[X=1:10]
Consider calculating the mean air temperature per unit surface area for this dataset. Because latitude and longitude correspond to spherical coordinates for Earth's surface, each 2.5x2.5 degree grid cell actually has a different surface area as you move away from the equator! This is because latitudinal length is fixed ($ \delta Lat = R \delta \phi $), but longitudinal length varies with latitude ($ \delta Lon = R \delta \lambda \cos(\phi) $)
So the area element for lat-lon coordinates is
where
TODO: mention the Rasters.coverage function that does this for you.
lon
# Earth's average radius in meters
R = 6.371e6
# Coordinate spacing for this dataset is 2.5 x 2.5 degrees
dϕ = deg2rad(2.5)
dλ = deg2rad(2.5)
dlat = fill(R * dϕ, dims(ds,X))
dlonval = R .* dλ .* cos.(deg2rad.(dims(ds.air, Y)))
dlon = DimArray(reshape(dlonval, (1, length(dlonval))), (X,dims(ds, Y)))
cell_area = dlat .* dlon
You can apply functions like cos and deg2rad elementwise on array types by using broadcasting in Julia.
In DimensionalData the broadcast does not automatically expand the data therefore we have to reshape the underlying data into a row vector to get a 2D array from the two 1D vectors.
cell_area = dlon .* dlat
cell_area
When broadcasting arithmetic operations DimensionalData automatically "aligns" i.e. puts the
data on the same grid. In this case cell_area and ds.air are at the same
lat, lon points we end up with a result with the same shape (25x53):
ds.air[Ti=1] ./ cell_area
DimensionalData only compares the dimension name and would currently broadcast two arrays with the same size along each dimension together.
# make a copy of cell_area
# then add 1e-5 degrees to latitude
cell_area_bad = similar(cell_area)
set(cell_area_bad, set(dims(cell_area_bad, X), 1:53))
cell_area_bad .* ds.air[Ti=1]
This results in the same values but the dimensions are different.
(groupby, resample, rolling, coarsen, weighted)
Rasters has some very useful high level objects that let you do common computations:
groupby: Bin data in to groups and reduceresample: Groupby specialized for time axes. Either downsample or upsample your data.rolling: Operate on rolling windows of your data e.g. running meancoarsen: Downsample your dataweighted: Weight your data before reducing
Below we quickly demonstrate these patterns. See the user guide links above and the tutorial for more.
# here's ds
ds
groups = groupby(ds, Ti=>seasons())
# make a seasonal mean
seasonal_mean = mean.(groups, dims=Ti)
seasonal_mean
#TODO: Plot the mean map for every season
# Reduce the time dimension to monthly means
monthlymeans = dropdims.(mean.(groupby(ds.air, Ti=>yearmonth), dims=Ti), dims=Ti)
# weight by cell_area and take mean over (time, lon)
#ds.weighted(cell_area).mean(["lon", "time"]).air.plot(y="lat");
weightedmean = dropdims(mean(ds.air, dims=(X, Ti)), dims=(X,Ti))
weightedmean
y = dims(weightedmean, Y)
@show y
nx = X(reverse(Float32[75.0, 72.5, 70.0, 67.5, 65.0, 62.5, 60.0, 57.5, 55.0, 52.5, 50.0, 47.5, 45.0, 42.5, 40.0, 37.5, 35.0, 32.5, 30.0, 27.5, 25.0, 22.5, 20.0, 17.5, 15.0]))
ny = Y(reverse(Float32[75.0, 72.5, 70.0, 67.5, 65.0, 62.5, 60.0, 57.5, 55.0, 52.5, 50.0, 47.5, 45.0, 42.5, 40.0, 37.5, 35.0, 32.5, 30.0, 27.5, 25.0, 22.5, 20.0, 17.5, 15.0]))
narr = DimArray(rand(25,25), (ny, nx))
fig, ax, pl = plot(narr)
nsingle = DimArray(rand(25), ny)
fig, ax, pl = plot(nsingle)
ax.finallimits
(.plot)
We have seen very simple plots earlier. Xarray also lets you easily visualize 3D and 4D datasets by presenting multiple facets (or panels or subplots) showing variations across rows and/or columns.
# facet the seasonal_mean
seasonal_mean.air.plot(col="season", col_wrap=2);
# contours
seasonal_mean.air.plot.contour(col="season", levels=20, add_colorbar=True);
# line plots too? wut
seasonal_mean.air.mean("lon").plot.line(hue="season", y="lat");
For more see the user guide, the gallery, and the tutorial material.
Rasters supports many disk formats. Below is a small example using netCDF. For more see the documentation.
Writing is done through the standard Base interface.
# write to netCDF
write("my-example-dataset.nc", ds)
!!! note
To avoid the SerializationWarning you can assign a _FillValue for any NaNs in 'air' array by adding the keyword argument encoding=dict(air={_FillValue=-9999})
TODO: change this to Rasters.jl syntax
# read from disk
fromdisk = Raster("my-example-dataset.nc")
You can also read these in lazily via the lazy=true keyword.
# check that the two are identical
ds == fromdisk
!!! tip A common use case to read datasets that are a collection of many netCDF files. See the documentation for how to handle that.
Finally to read other file formats, you might find yourself reading in the data using a different library and then creating a DataArray(docs, tutorial) from scratch. For example, you might use h5py to open an HDF5 file and then create a Dataset from that.
For MATLAB files you might use scipy.io.loadmat or h5py depending on the version of MATLAB file you're opening and then construct a Dataset.
Xarray ties in to the larger scientific python ecosystem and in turn many packages build on top of xarray. A long list of such packages is here: https://docs.xarray.dev/en/stable/related-projects.html.
Now we will demonstrate some cool features.
You can easily convert between xarray and pandas structures. This allows you to conveniently use the extensive pandas ecosystem of packages (like seaborn) for your work.
# convert to pandas dataframe
df = ds.isel(time=slice(10)).to_dataframe()
df
# convert dataframe to xarray
df.to_xarray()
This notebook has focused on Numpy arrays. Xarray can wrap other array types! For example:

![]() pydata/sparse : sparse arrays
pydata/sparse : sparse arrays
pint : unit-aware arrays & pint-xarray
Dask cuts up NumPy arrays into blocks and parallelizes your analysis code across these blocks

# demonstrate dask dataset
dasky = xr.tutorial.open_dataset(
"air_temperature",
chunks={"time": 10}, # 10 time steps in each block
)
dasky.air
All computations with dask-backed xarray objects are lazy, allowing you to build up a complicated chain of analysis steps quickly
# demonstrate lazy mean
dasky.air.mean("lat")
To get concrete values, call .compute or .load
# "compute" the mean
dasky.air.mean("lat").compute()
Quickly generate interactive plots from your data!
The hvplot package attaches itself to all
xarray objects under the .hvplot namespace. So instead of using .plot use .hvplot
import hvplot.xarray
ds.air.hvplot(groupby="time", clim=(270, 300), widget_location='bottom')
The time slider will only work if you're executing the notebook, rather than viewing the website
cf_xarray is a project that tries to
let you make use of other CF attributes that xarray ignores. It attaches itself
to all xarray objects under the .cf namespace.
Where xarray allows you to specify dimension names for analysis, cf_xarray
lets you specify logical names like "latitude" or "longitude" instead as
long as the appropriate CF attributes are set.
For example, the "longitude" dimension in different files might be labelled as: (lon, LON, long, x…), but cf_xarray let's you always refer to the logical name "longitude" in your code:
import cf_xarray
# describe cf attributes in dataset
ds.air.cf
The following mean operation will work with any dataset that has appropriate
attributes set that allow detection of the "latitude" variable (e.g.
units: "degress_north" or standard_name: "latitude")
# demonstrate equivalent of .mean("lat")
ds.air.cf.mean("latitude")
# demonstrate indexing
ds.air.cf.sel(longitude=242.5, method="nearest")
- xgcm : grid-aware operations with xarray objects
- xrft : fourier transforms with xarray
- xclim : calculating climate indices with xarray objects
- intake-xarray : forget about file paths
- rioxarray : raster files and xarray
- xesmf : regrid using ESMF
- MetPy : tools for working with weather data
Check the Xarray Ecosystem page and this tutorial for even more packages and demonstrations.
- Read the tutorial material and user guide
- See the description of common terms used in the xarray documentation:
- Answers to common questions on "how to do X" with Xarray are here
- Ryan Abernathey has a book on data analysis with a chapter on Xarray
- Project Pythia has foundational and more advanced material on Xarray. Pythia also aggregates other Python learning resources.
- The Xarray Github Discussions and Pangeo Discourse are good places to ask questions.
- Tell your friends! Tweet!
DimensionalData and the whole Julia data analysis ecosystem is an open-source project and gladly welcomes all kinds of contributions. This could include reporting bugs, discussing new enhancements, contributing code, helping answer user questions, contributing documentation (even small edits like fixing spelling mistakes or rewording to make the text clearer). Welcome!