PyTorch unofficial implementation of Semantic Image Synthesis with Spatially-Adaptive Normalization paper by Nvidia Research.
My blog post can be found here, SPADE: State of the art in Image-to-Image Translation by Nvidia
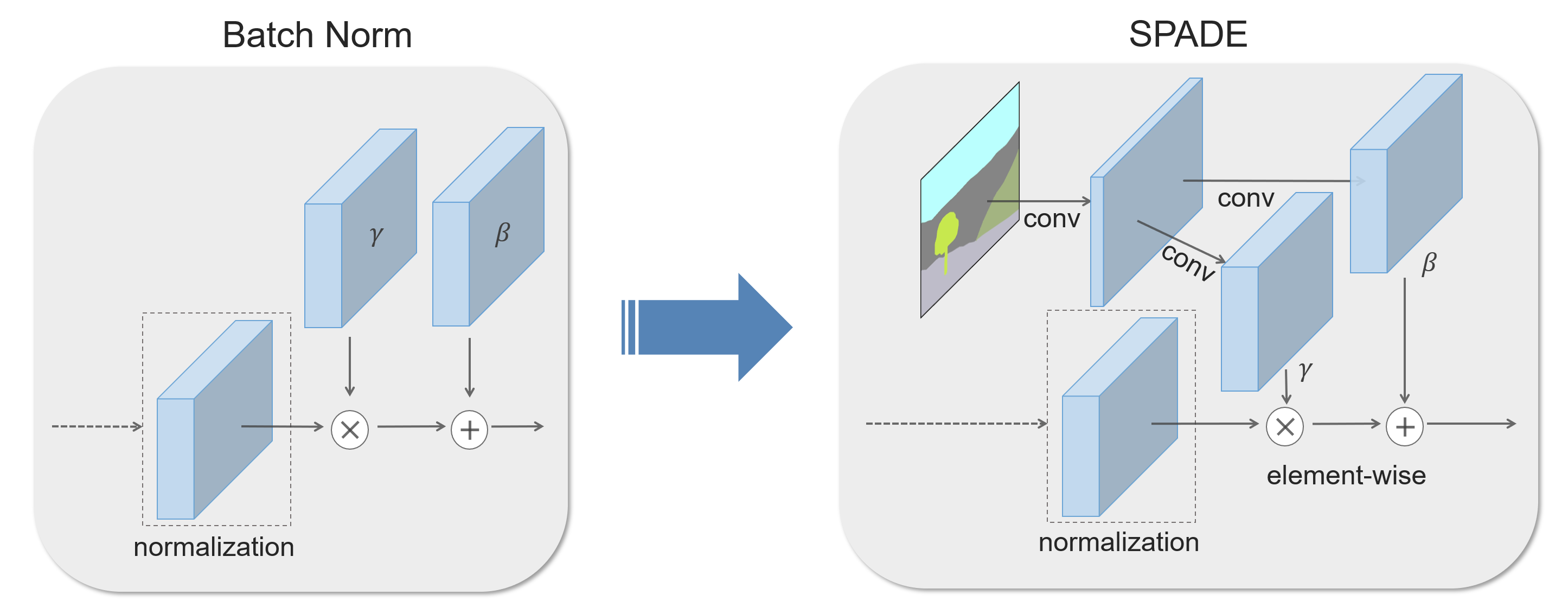
In many common normalization techniques such as Batch Normalization (Ioffe et al., 2015), there are learned affine layers (as in PyTorch and TensorFlow) that are applied after the actual normalization step. In SPADE, the affine layer is learned from semantic segmentation map. This is similar to Conditional Normalization (De Vries et al., 2017 and Dumoulin et al., 2016), except that the learned affine parameters now need to be spatially-adaptive, which means we will use different scaling and bias for each semantic label. Using this simple method, semantic signal can act on all layer outputs, unaffected by the normalization process which may lose such information. Moreover, because the semantic information is provided via SPADE layers, random latent vector may be used as input to the network, which can be used to manipulate the style of the generated images.
All the code for the repo can be found in the src-folder.
└── src
├── dataloader
│ ├── cityscapes.py
├── models
│ ├── spade.py
│ ├── spade_resblk.py
│ ├── generator.py
│ ├── discriminator.py
│ ├── encoder.py
│ ├── ganloss.py
│ └── weights_init.py
├── notebooks
│ ├── develpment.ipynb
│ ├── dis.pth
│ ├── gen.pth
│ ├── Images
│ └── train_model.ipynb
├── args.py
├── plot.py
└── train.py- In
args.pyyou will find the get_parser and you can set various defaults here. - In
train.pyI provide the train script to train your model. (I recommend using train_model.ipynb notebook for training your model, as I present complete model training process there) - In
plot.pyyou will find various plotting functions, which are used in the notebooks also. - In
modelsfolder there are model definitions of all the models discussed in the paper. They are built so as to resemble the paper architectures. - In
notebooksfolder, there are two notebooks,development.ipynbwhich I used when debugging my model architectures. And intrain_model.ipynbI make an actual model from scratch and train it, so if you want to make your own model, follow this notebook.
Comparison of original model and my model

I was limited by my hardware so I changed my motive to being able to reproduce images that show that the model works. (Note:- I did not train my model completely, below are results after every 20 epochs)

After 80 epochs, we can get a sense that we are able to get real life pictures. Also, after downsampling the original CityScape images, they were blurry themselves so some bluriness in the output is expected (By bluriness I am saying we have to print pictures very small to show without being blurred).
- Python 3.7+
- PyTorch 1.1+
- cv2
If some documentation is missing or some piece of code is not clear, open an issue and I would be happy to clarify. Also, if any bug is found, file a PR or open an issue. If you want some genral discussion, I am always open to discussion.
This repo is MIT licensed, as found in the LICENSE file.