ABT-MPNN: An atom-bond transformer-based message passing neural network for molecular property prediction
This repository provides codes and materials associated with the manuscript ABT-MPNN: An atom-bond transformer-based message passing neural network for molecular property prediction.
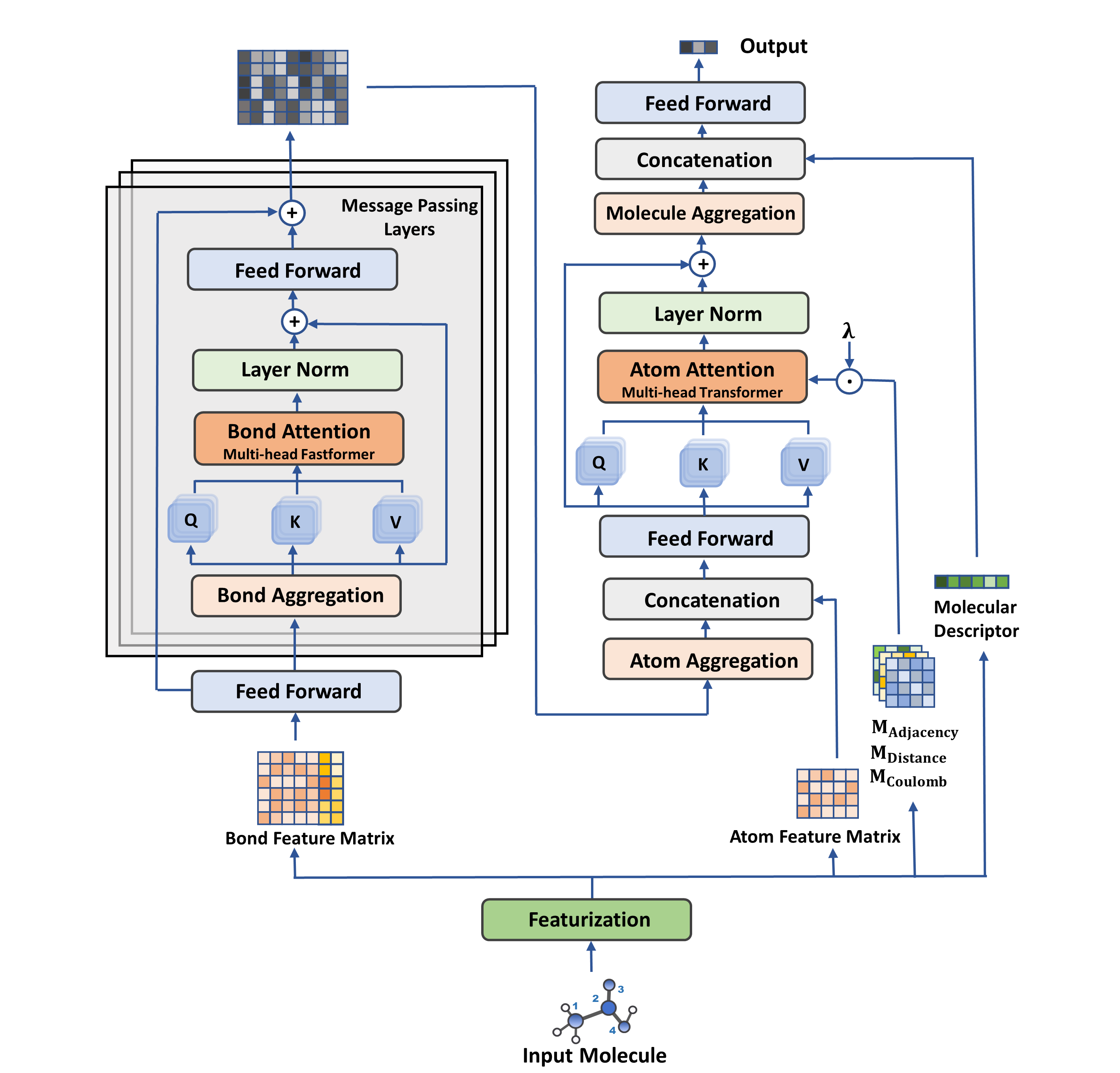
Illustration of ABT-MPNN
We acknowledge the paper Yang et al (2019). Analyzing Learned Molecular Representations for Property Prediction. JCIM, 59(8), 3370–3388 and the Chemprop repository (version 1.2.0) which this code leveraged and built on top of.
cuda >= 8.0 + cuDNN
python>=3.6
flask>=1.1.2
gunicorn>=20.0.4
hyperopt>=0.2.3
matplotlib>=3.1.3
numpy>=1.18.1
pandas>=1.0.3
pandas-flavor>=0.2.0
pip>=20.0.2
pytorch>=1.4.0
rdkit>=2020.03.1.0
scipy>=1.4.1
tensorboardX>=2.0
torchvision>=0.5.0
tqdm>=4.45.0
einops>=0.3.2
seaborn>=0.11.1
Install the dependencies via conda:
conda env create -f environment.yml
conda activate abtmpnn
The data file must be be a CSV file with a header row. For example:
smiles,NR-AR,NR-AR-LBD,NR-AhR,NR-Aromatase,NR-ER,NR-ER-LBD,NR-PPAR-gamma,SR-ARE,SR-ATAD5,SR-HSE,SR-MMP,SR-p53
CCOc1ccc2nc(S(N)(=O)=O)sc2c1,0,0,1,,,0,0,1,0,0,0,0
CCN1C(=O)NC(c2ccccc2)C1=O,0,0,0,0,0,0,0,,0,,0,0
...
Data sets used in our study are available in the data directory of this repository.
- The raw data from the Johnson et al. study is publicly accessible on the web site.
- The details of the data from MoleculeNet can be found here.
To save adjacency / distance / Coulomb matrices for a dataset, run:
python save_atom_features.py --data_path <path> --save_dir <dir> --adjacency --coulomb --distance
where <path> is the path to a CSV file containing a dataset, and <dir> is the directory where inter-atomic matrices will be saved. To generate adjacency, distance, Coulomb matrices, specify --adjacency, --distance, --coulomb flags.
For example:
python save_atom_features.py --data_path data/freesolv.csv --save_dir features/freesolv/ --adjacency --coulomb --distance
To save Molecule-Level RDKit 2D Features (CDF-normalized version) for a dataset, run:
python save_features.py --data_path <path1> --save_path <path2> --features_generator rdkit_2d_normalized
where <path1> is the path to a CSV file containing a dataset, and <path2> is the path where molecular-level features will be saved. --rdkit_2d_normalized is the flag to generate CDF-normalized version of the 200 rdkit descriptors.
For example:
python save_features.py --data_path data/freesolv.csv --save_path features/freesolv/rdkit_norm.npz --features_generator rdkit_2d_normalized
To train a ABT-MPNN model, run:
python train.py --data_path <path> --dataset_type <type> --save_dir <dir> --bond_fast_attention --atom_attention --adjacency --adjacency_path <adj_path> --distance --distance_path <dist_path> --coulomb --coulomb_path <clb_path> --normalize_matrices --features_path <molf_path> --no_features_scaling
Notes:
<path>is the path to a CSV file containing a dataset.<type>is either "classification" or "regression" depending on the type of the dataset.<dir>is the directory where model checkpoints will be saved.- To use bond attention (Fastformer) in the message passing phase, add
--bond_fast_attention - To use atom attention in the readout phase, add
--atom_attention - Specify
--adjacencyto add adjacency matrix and<adj_path>is the path to a npz file containing the saved adjacency matrices of a dataset. - Specify
--distanceto add distance matrix and<dist_path>is the path to a npz file containing the saved distance matrices of a dataset. - Specify
--coulombto add Coulomb matrix and<clb_path>is the path to a npz file containing the saved Coulomb matrices of a dataset. <molf_path>is the path to a npz file containing the saved molecule-level features of a dataset.- Specify
--normalize_matricesto normalize inter-atomic matrices. - Use the
--no_features_scalingflag in the case ofrdkit_2d_normalized, because those features have been pre-normalized and don't require further scaling.
A full list of available command-line arguments can be found in chemprop/args.py
k-fold cross-validation can be run by specifying the --num_folds argument (which is 1 by default).
For example:
python train.py --data_path data/freesolv.csv --dataset_type regression --save_dir data_test/freesolv --bond_fast_attention --atom_attention --adjacency --adjacency_path features/freesolv/adj.npz --distance --distance_path features/freesolv/dist.npz --coulomb --coulomb_path features/freesolv/clb.npz --normalize_matrices --features_path features/freesolv/rdkit_norm.npz --split_type random --no_features_scaling --num_folds 5 --gpu 0
To load a trained model and make predictions, run predict.py and specify:
--test_path <path>Path to the data to predict on.--checkpoint_path <path>Path to a model checkpoint file (.ptfile).--preds_pathPath where a pickle file containing the predictions will be saved.
If features were used during training, they must be specified again during prediction using the same type of features as before:
--adjacency_path <adj_path>Path to a npz file containing the saved adjacency matrices--distance_path <dist_path>Path to a npz file containing the saved distance matrices--coulomb_path <clb_path>Path to a npz file containing the saved Coulomb matrices--features_path <molf_path>Path to a npz file containing the saved molecule-level features.--normalize_matricesand--no_features_scalingalso must be specified if used in training.
For example:
python predict.py --test_path data/freesolv.csv --checkpoint_dir data_test/freesolv --preds_path data_test/freesolv/pred.csv --adjacency_path features/freesolv/adj.npz --distance_path features/freesolv/dist.npz --coulomb_path features/freesolv/clb.npz --features_path features/freesolv/rdkit_norm.npz --normalize_matrices --no_features_scaling
To visualize atomic attention and save similarity maps, run see_attention.py and specify:
--test_path <path>Path to the data to predict on.--checkpoint_path <path>Path to a model checkpoint file (.ptfile).--preds_pathPath where a pickle file containing the predictions will be saved.--viz_dirPath where attention weights will be visualized via similarity maps and.pngfiles (dpi=300) will be saved.
If features were used during training, they must be specified again during prediction using the same type of features as before:
--adjacency_path <adj_path>Path to a npz file containing the saved adjacency matrices--distance_path <dist_path>Path to a npz file containing the saved distance matrices--coulomb_path <clb_path>Path to a npz file containing the saved Coulomb matrices--features_path <molf_path>Path to a npz file containing the saved molecule-level features.--normalize_matricesand--no_features_scalingalso must be specified if used in training.
For example:
python see_attention.py --test_path data/freesolv.csv --checkpoint_dir data_test/freesolv --preds_path data_test/freesolv/pred.csv --viz_dir data_test/freesolv/similarity_maps --adjacency_path features/freesolv/adj.npz --distance_path features/freesolv/dist.npz --coulomb_path features/freesolv/clb.npz --features_path features/freesolv/rdkit_norm.npz --normalize_matrices --no_features_scaling