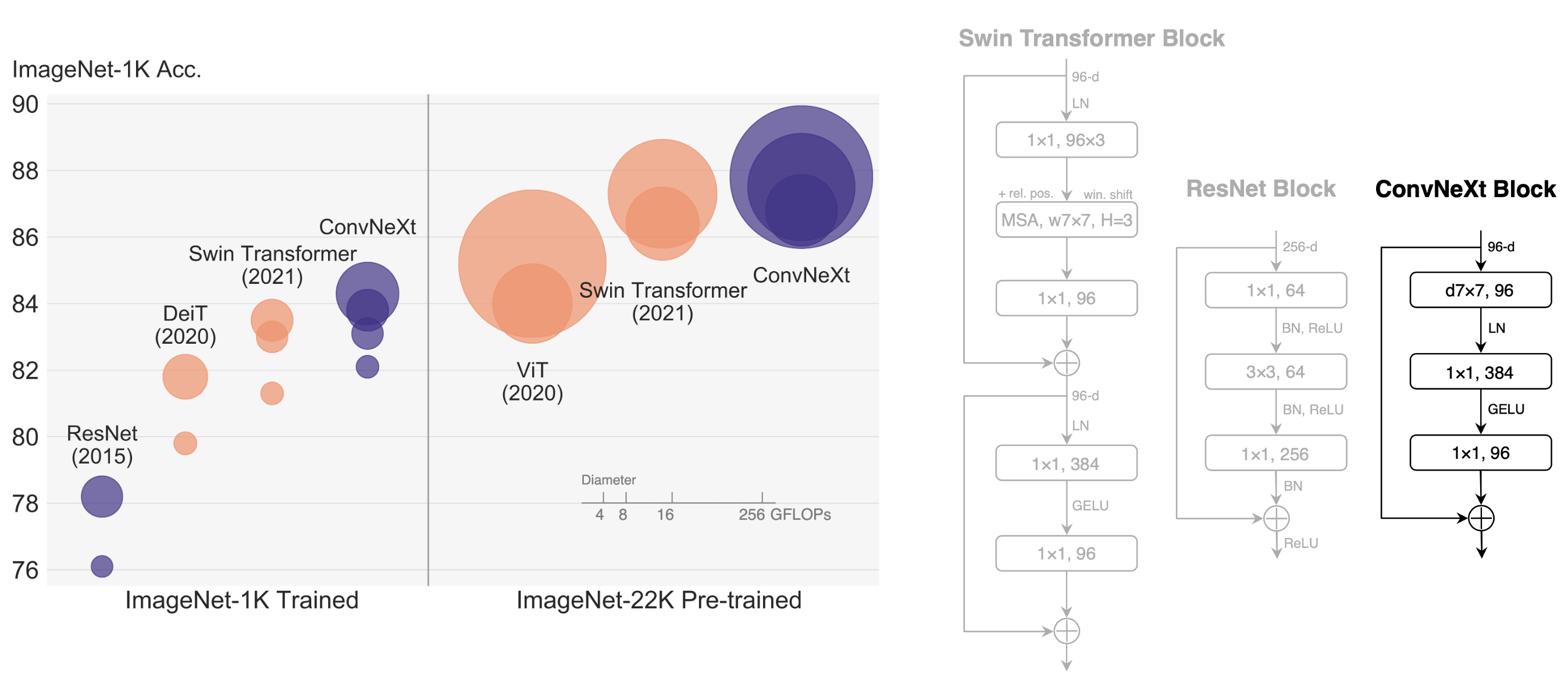
The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
- ConvNeXt backbone needs to install MMClassification first, which has abundant backbones for downstream tasks.
pip install mmcls>=0.20.1The pre-trained models on ImageNet-1k or ImageNet-21k are used to fine-tune on the downstream tasks.
| Model | Training Data | Params(M) | Flops(G) | Download |
|---|---|---|---|---|
| ConvNeXt-T* | ImageNet-1k | 28.59 | 4.46 | model |
| ConvNeXt-S* | ImageNet-1k | 50.22 | 8.69 | model |
| ConvNeXt-B* | ImageNet-1k | 88.59 | 15.36 | model |
| ConvNeXt-B* | ImageNet-21k | 88.59 | 15.36 | model |
| ConvNeXt-L* | ImageNet-21k | 197.77 | 34.37 | model |
| ConvNeXt-XL* | ImageNet-21k | 350.20 | 60.93 | model |
Models with are converted from the official repo.*
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|
| UPerNet | ConvNeXt-T | 512x512 | 160000 | 4.23 | 19.90 | V100 | 46.11 | 46.62 | config | model | log |
| UPerNet | ConvNeXt-S | 512x512 | 160000 | 5.16 | 15.18 | V100 | 48.56 | 49.02 | config | model | log |
| UPerNet | ConvNeXt-B | 512x512 | 160000 | 6.33 | 14.41 | V100 | 48.71 | 49.54 | config | model | log |
| UPerNet | ConvNeXt-B | 640x640 | 160000 | 8.53 | 10.88 | V100 | 52.13 | 52.66 | config | model | log |
| UPerNet | ConvNeXt-L | 640x640 | 160000 | 12.08 | 7.69 | V100 | 53.16 | 53.38 | config | model | log |
| UPerNet | ConvNeXt-XL | 640x640 | 160000 | 26.16* | 6.33 | V100 | 53.58 | 54.11 | config | model | log |
Note:
Mem (GB)with * is collected whencudnn_benchmark=True, and hardware is V100.
@article{liu2022convnet,
title={A ConvNet for the 2020s},
author={Liu, Zhuang and Mao, Hanzi and Wu, Chao-Yuan and Feichtenhofer, Christoph and Darrell, Trevor and Xie, Saining},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}