PSANet: Point-wise Spatial Attention Network for Scene Parsing
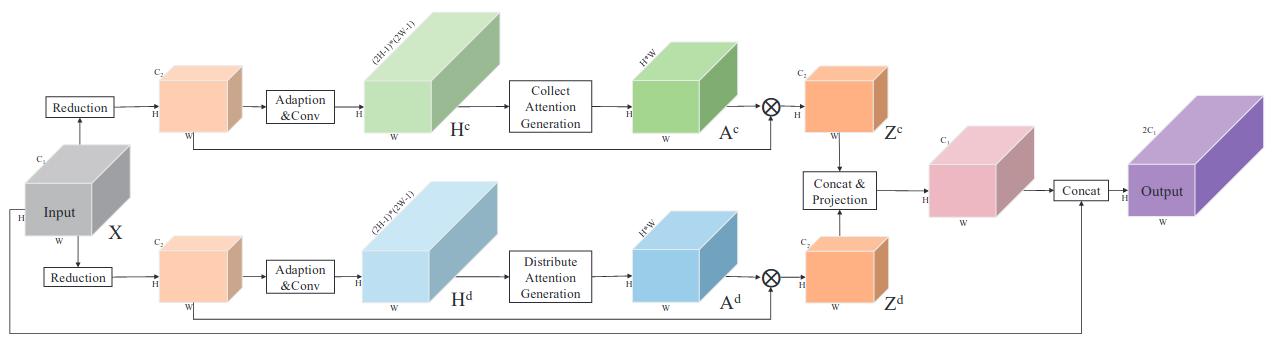
We notice information flow in convolutional neural networksis restricted inside local neighborhood regions due to the physical de-sign of convolutional filters, which limits the overall understanding ofcomplex scenes. In this paper, we propose thepoint-wise spatial atten-tion network(PSANet) to relax the local neighborhood constraint. Eachposition on the feature map is connected to all the other ones througha self-adaptively learned attention mask. Moreover, information propa-gation in bi-direction for scene parsing is enabled. Information at otherpositions can be collected to help the prediction of the current positionand vice versa, information at the current position can be distributedto assist the prediction of other ones. Our proposed approach achievestop performance on various competitive scene parsing datasets, includ-ing ADE20K, PASCAL VOC 2012 and Cityscapes, demonstrating itseffectiveness and generality.
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|
| PSANet | R-50-D8 | 512x1024 | 40000 | 7 | 3.17 | V100 | 77.63 | 79.04 | config | model | log |
| PSANet | R-101-D8 | 512x1024 | 40000 | 10.5 | 2.20 | V100 | 79.14 | 80.19 | config | model | log |
| PSANet | R-50-D8 | 769x769 | 40000 | 7.9 | 1.40 | V100 | 77.99 | 79.64 | config | model | log |
| PSANet | R-101-D8 | 769x769 | 40000 | 11.9 | 0.98 | V100 | 78.43 | 80.26 | config | model | log |
| PSANet | R-50-D8 | 512x1024 | 80000 | - | - | V100 | 77.24 | 78.69 | config | model | log |
| PSANet | R-101-D8 | 512x1024 | 80000 | - | - | V100 | 79.31 | 80.53 | config | model | log |
| PSANet | R-50-D8 | 769x769 | 80000 | - | - | V100 | 79.31 | 80.91 | config | model | log |
| PSANet | R-101-D8 | 769x769 | 80000 | - | - | V100 | 79.69 | 80.89 | config | model | log |
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|
| PSANet | R-50-D8 | 512x512 | 80000 | 9 | 18.91 | V100 | 41.14 | 41.91 | config | model | log |
| PSANet | R-101-D8 | 512x512 | 80000 | 12.5 | 13.13 | V100 | 43.80 | 44.75 | config | model | log |
| PSANet | R-50-D8 | 512x512 | 160000 | - | - | V100 | 41.67 | 42.95 | config | model | log |
| PSANet | R-101-D8 | 512x512 | 160000 | - | - | V100 | 43.74 | 45.38 | config | model | log |
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|
| PSANet | R-50-D8 | 512x512 | 20000 | 6.9 | 18.24 | V100 | 76.39 | 77.34 | config | model | log |
| PSANet | R-101-D8 | 512x512 | 20000 | 10.4 | 12.63 | V100 | 77.91 | 79.30 | config | model | log |
| PSANet | R-50-D8 | 512x512 | 40000 | - | - | V100 | 76.30 | 77.35 | config | model | log |
| PSANet | R-101-D8 | 512x512 | 40000 | - | - | V100 | 77.73 | 79.05 | config | model | log |
@inproceedings{zhao2018psanet,
title={Psanet: Point-wise spatial attention network for scene parsing},
author={Zhao, Hengshuang and Zhang, Yi and Liu, Shu and Shi, Jianping and Change Loy, Chen and Lin, Dahua and Jia, Jiaya},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={267--283},
year={2018}
}