Metrics are logged on each batch, but not on each accum. step #1173
Comments
|
could you also pass the sample code you are using? |
|
Here is my function for Trainer construction: def get_trainer(args: argparse.Namespace, experiment_name: str) -> pytorch_lightning.Trainer:
tb_logger_callback = pytorch_lightning.loggers.TensorBoardLogger(
save_dir=args.tensorboard_logdir,
version=experiment_name
)
model_checkpoint_callback = pytorch_lightning.callbacks.ModelCheckpoint(
filepath=pathlib.Path(args.experiments_root) / experiment_name / 'models',
verbose=True,
save_top_k=args.hold_n_models
)
trainer_args = copy.deepcopy(args.__dict__)
trainer_args.update(
{
'logger': tb_logger_callback,
'checkpoint_callback': model_checkpoint_callback,
'show_progress_bar': True,
'progress_bar_refresh_rate': 1,
'row_log_interval': 1,
'val_check_interval': int(trainer_args['val_check_interval']),
}
)
trainer = pytorch_lightning.Trainer(
**trainer_args
)
return trainerAnd here is the Module (some lines are omitted) class MyModule(pl.LightningModule):
def __init__(self, hparams: Union[dict, argparse.Namespace]):
super().__init__()
if isinstance(hparams, dict):
hparams = argparse.Namespace(**hparams)
self.hparams = hparams
# ----------------------------------------
# My custom fields initialization here
# ----------------------------------------
def prepare_data(self):
# ----------------------------------------
# My custom dataset creation here
# ----------------------------------------
pass
def forward(
self, data: rnd_datasets.JointCollateBatchT
) -> Tuple[torch.tensor, torch.tensor, torch.tensor]:
"""
Args:
data: list with input model data (tensors). It contains 4 tensors:
token_ids, token_types, reply_lengths, is_distractor.
Returns:
Tuple with 3 losses: (loss, lm_loss, mc_loss)
"""
loss, lm_loss, mc_loss = self._model(data)
if self.trainer.use_dp or self.trainer.use_ddp2:
loss = loss.unsqueeze(0)
lm_loss = lm_loss.unsqueeze(0)
mc_loss = mc_loss.unsqueeze(0)
return loss, lm_loss, mc_loss
def training_step(self, batch, batch_idx):
loss, lm_loss, mc_loss = self.forward(batch)
lr = self.trainer.optimizers[0].param_groups[0]['lr']
log = {
'MC-Loss/train': mc_loss,
'LM-Loss/train': lm_loss,
'Learning-Rate': lr
}
# Set up placeholders for valid metrics.
if batch_idx == 0:
loss_val = torch.tensor(np.inf).unsqueeze(0).to(loss.device) if len(loss.size()) else np.inf
log.update({'MC-Loss/valid': loss_val, 'LM-Loss/valid': loss_val})
return {'loss': loss, 'log': log}
def validation_step(self, batch, batch_idx):
loss, lm_loss, mc_loss = self.forward(batch)
return {'val_loss': lm_loss, 'mc_loss': mc_loss, 'lm_loss': lm_loss}
def validation_epoch_end(self, outputs):
mc_loss = torch.stack([x['mc_loss'] for x in outputs]).mean()
lm_loss = torch.stack([x['lm_loss'] for x in outputs]).mean()
logs = {
'MC-Loss/valid': mc_loss,
'LM-Loss/valid': lm_loss
}
return {'val_loss': lm_loss, 'log': logs}
def train_dataloader(self):
return self._train_dataloader
def val_dataloader(self):
return self._valid_dataloader
def configure_optimizers(self):
parameters = self._model.parameters()
optimizer = transformers.AdamW(parameters, lr=self._learning_rate)
# ----------------------------------------
# My custom lr_scheduler creation here
# ----------------------------------------
scheduler = {
'scheduler': lr_scheduler,
'interval': 'step',
'frequency': self.trainer.accumulate_grad_batches,
'reduce_on_plateau': True,
'monitor': 'LM-Loss/valid'
}
return [optimizer], [scheduler] |
|
Let me show more extreme case. And this I can see on tensorboard: Only 2 steps are logged (as expected), but each step (vertical orange lines) contains all accumulation step metrics. That's why the vertical lines are here. On the other hand, if I set This image is clear. No vertical lines. Each step corresponds to a single metric estimation. This problem may look minor :) But in my particular case, there is a huge variance between metrics inside the one accumulation step and I don't want to plot them all, but I want to have one aggregated estimation. Without such aggregation I have a dirty messy plots: Hope this will help to understand the problem) |




|
@Borda any thoughts on this? I can do a PR, so you can look closer on this. |
|
@jeffling @jeremyjordan any thought? ^^ |
|
at a quick glance i would think you'd want to use |
|
Hi! Sorry for the late reply. |
|
yeah we should handle that case better, would you be interested in drafting a PR to address this? |
|
Yes, I'll try to handle this |
|
@jeremyjordan Let me first formalize the problem. Here are
@rank_zero_only
def log_metrics(self, metrics: Dict[str, float], step: Optional[int] = None) -> None:
for k, v in metrics.items():
if isinstance(v, torch.Tensor):
v = v.item()
self.experiment.add_scalar(k, v, step)
@rank_zero_only
def log_metrics(
self,
metrics: Dict[str, Union[torch.Tensor, float]],
step: Optional[int] = None
) -> None:
for key, val in metrics.items():
self.log_metric(key, val, step=step)
@rank_zero_only
def log_metrics(
self,
metrics: Dict[str, Union[torch.Tensor, float]],
step: Optional[int] = None
) -> None:
for key, val in metrics.items():
self.log_metric(key, val, step=step)
@rank_zero_only
def log_metrics(self, metrics: Dict[str, float], step: Optional[int] = None) -> None:
timestamp_ms = int(time() * 1000)
for k, v in metrics.items():
if isinstance(v, str):
log.warning(f'Discarding metric with string value {k}={v}.')
continue
self.experiment.log_metric(self.run_id, k, v, timestamp_ms, step)
@rank_zero_only
def log_metrics(
self,
metrics: Dict[str, Union[torch.Tensor, float]],
step: Optional[int] = None
) -> None:
# Comet.ml expects metrics to be a dictionary of detached tensors on CPU
for key, val in metrics.items():
if is_tensor(val):
metrics[key] = val.cpu().detach()
self.experiment.log_metrics(metrics, step=step)As we can see, each logger's method receives the It happens, because the train loop calls And when we have So, I see here the following solutions:
What do you think? maybe you have another options? Or maybe I've totally missed something, and there exists some already implemented trick in the PL, which solves this issue? |
|
@alexeykarnachev great analysis! Personally I would not do abstraction in Trainer as it is already very large, rather I would do some abstraction in base logger classes and the logic is very similar for all particular loggers... |
🐛 Bug
I'm not sure, that this is a bug, but it's really unexpected behavior.
Metrics are logged on each batch, as we can see here:
https://github.com/PyTorchLightning/pytorch-lightning/blob/c32e3f3ea57dd4439255b809ed5519608a585d73/pytorch_lightning/trainer/training_loop.py#L435-L439
In case of using Tensorboard logger we will see the following picture:
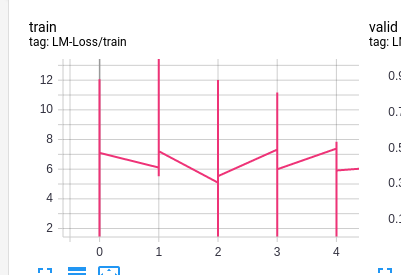
these vertical lines are a sets of points, logged for each individual step.
Is there any way to log aggregated metrics for each step (so that only one log point appears for each step) ?
I can set
row_log_intervalequal to the accumulation steps, and only one logging point will appear, but in this case, I'll not aggregate the accumulation step metrics, but only take the last one.Environment
PyTorch version: 1.4.0
OS: Ubuntu 16.04.6 LTS
Python version: 3.7
Versions of relevant libraries:
[pip] numpy==1.18.1
[pip] pytorch-lightning==0.7.1
[pip] torch==1.4.0
[pip] torchvision==0.5.0
The text was updated successfully, but these errors were encountered: