Summary: This repo gives a brief overview of the process, architecture, and various components used to make a simple Dead By Daylight (DBD) game data stream. This was created primarily for learning purposes. In the simulated data we try to show a correlation between a players play time and the amount of kills they can get (higher play time more likely).
Day one:
 As more data streams (stopped intermittently because of AWS Cost):
As more data streams (stopped intermittently because of AWS Cost):


This DB contains two tables USER and KILLER. The game simulator Python script will query the Database (or AWS Elasticache if the results are cached) to create a match. The DB contains 1000 users and 18 killers.

Two EC2 instances were created. One to run our backed Python scrip to simulate a game and a second for our MySQL DB instance.

To test scalability Docker containers were used to simulate multiple instances of the data being generated.

Steps involved
- Installing Docker on RHEL EC2 instance
docker pull centosdocker run centosdocker run -it -d centosdocker exec -it container_id /bin/bashyum install update -yyum install python3yum install nanoyum install passwduseradd rm_logour service account user for MySQLpasswd rm_logsetting up user passwordsu - rm_log- Setup AWS Credentials
mkdir ~/.awsnano ~/.aws/credentials- Adding:
[default]
aws_access_key_id = YOUR_KEY
aws_secret_access_key = YOUR_SECRET
- Setup AWS Region Config
nano ~/.aws/config- Adding:
[default]
region=us-east-1
- Run
curl icanhazip.comto get public IP and add to AWS security group for port3306 - Grab https://github.com/MPierre9/DBD_Game_Sim/blob/master/dbd_game_sim.py and test in container
- Execute
chmod +x dbd_game_sim.py - Exit container and commit changes
docker commit container_id centos_stream_1 - With the
centos_stream_1image create the desired amount of instances and execute. - Execute `nohup python3 -u ./dbd_game_sim.py > ~/dbd_game_sim.log
- Ensure process is running in background with
ps ax - To kill run
pkill -f dbd_game_sim.py
Checking Container Data Log

Future state, creating a Dockerfile to has libraries and packages pre-installed
The Elasticache cache is used to cache results from the game sim Python script to increase query performance and decrease DB strain. The idea is if multiple game sims are running then they could work off the cached player list and killers.

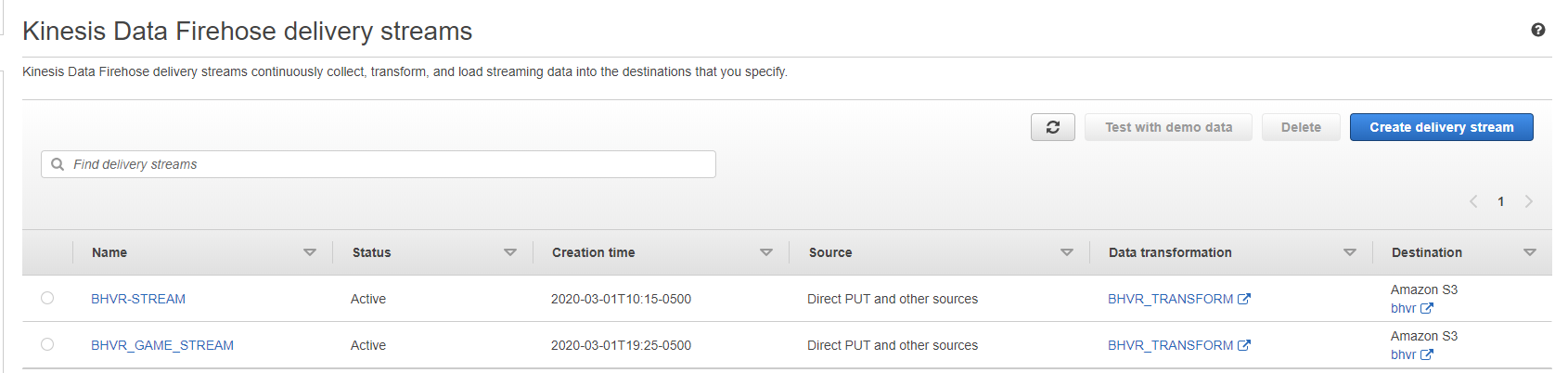
Once a game is complete two streams are sent via AWS Kinesis Firehose to be stored in S3.
{"username": "cmenhenitthv", "play_time": 25, "killer": "", "killed": true, "match_id": "14a9b218-cc99-428e-932a-872acf357f99-02-03-2020-00-46-38"} {"username": "dinnettrm", "play_time": 70, "killer": "", "killed": true, "match_id": "14a9b218-cc99-428e-932a-872acf357f99-02-03-2020-00-46-38"} {"username": "dbaskeyfield87", "play_time": 93, "killer": "", "killed": true, "match_id": "14a9b218-cc99-428e-932a-872acf357f99-02-03-2020-00-46-38"} {"username": "jtabert6g", "play_time": 47, "killer": "the demogorgon", "killed": false, "match_id": "14a9b218-cc99-428e-932a-872acf357f99-02-03-2020-00-46-38"} {"username": "jantoniouez", "play_time": 148, "killer": "", "killed": true, "match_id": "14a9b218-cc99-428e-932a-872acf357f99-02-03-2020-00-46-38"}
{"match_id": "00778193-85d9-4256-9f52-e2c229eebcd0-02-03-2020-00-46-08", "match_time": "02-03-2020-00-46-08"}
A lambda function called BHVR_TRANSFORM decodes the base64 data to ascii and adds a newline character to make the JSON records look a bit nicer.
console.log('Loading function');
exports.handler = async (event, context, callback) => {
/* Process the list of records and transform them */
const output = event.records.map((record) => {
/* This transformation is the "identity" transformation, the data is left intact */
let entry = (new Buffer(record.data, 'base64')).toString('ascii');
let result = entry + "\n";
const payload = (new Buffer(result, 'ascii')).toString('base64');
return {
recordId: record.recordId,
result: 'Ok',
data: payload
};
});
console.log('Processing completed. Successful records ${output.length}.');
callback(null,{ records: output });
};
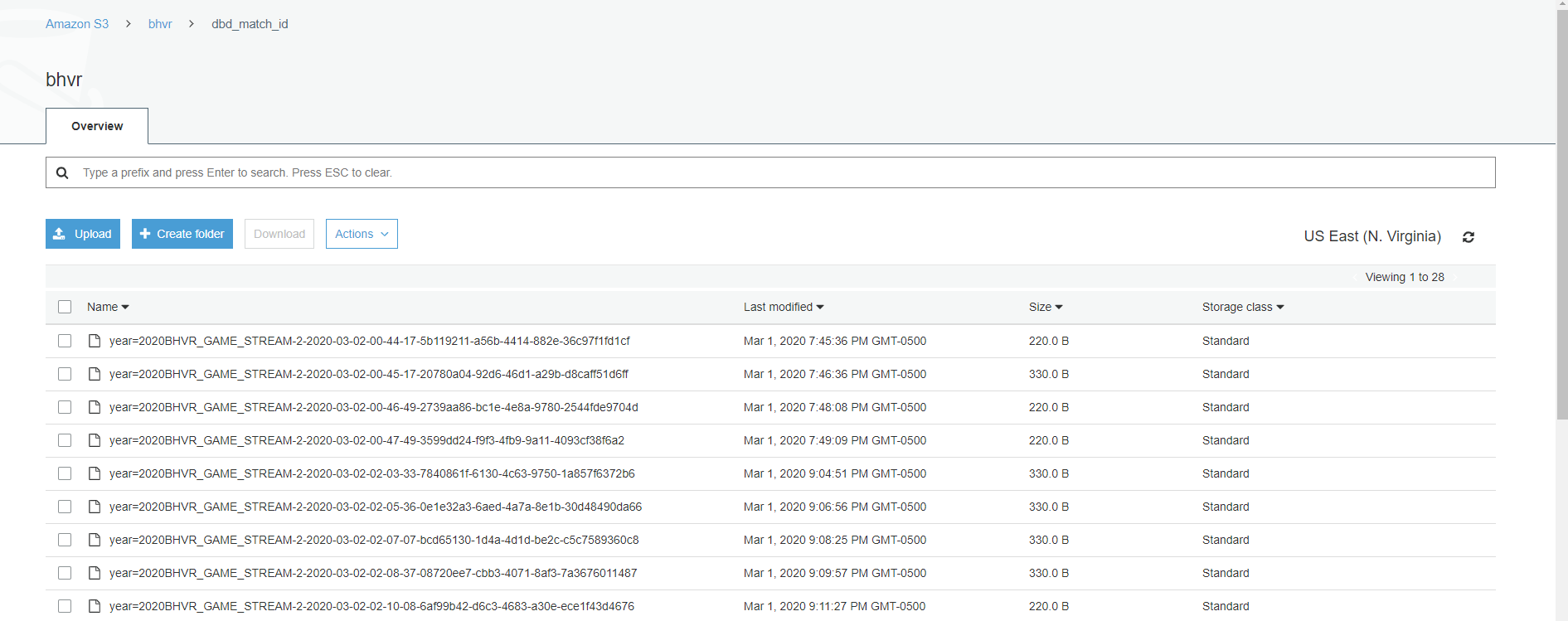
AWS S3 is the destination for our JSON records streaming via Kinesis Firehose. There are two directories in S3 for the data. dbd_match_id which contains all the match_ids and the date the match occurred. dbd_player_match which contains all the player data for that match (survivor info, who was the killer, who did they kill, etc).
Glue is the best. In Glue we have two Crawlers BHVR_CRAWLER and BHVR_MATCH_ID_CRAWLER which connect to S3 to poll for additional match data and add any new data to tables dbd_match_id and dbd_player_match.

Used to query the tables we have in the Data Catalog from AWS Glue. From there a pretty query was made to see the kill count for each respective killer in a match
select username, killer, play_time, (select count(*) from "bhvr"."dbd_player_match" where killed and match_id=b.match_id) as kill_count from "bhvr"."dbd_player_match" as a INNER JOIN "bhvr"."dbd_match_id" as b ON a.match_id=b.match_id WHERE a.match_id=b.match_id and killer <> '' GROUP BY username, killer, play_time, b.match_id
Finally this data is visualized in AWS Quicksight.
