AngleSharp comes currently in two flavors: on Windows for .NET 4.6 and in general targetting .NET Standard 2.0 platforms.
Most of the features of the library do not require .NET 4.6, which means you could create your own fork and modify it to work with previous versions of the .NET-Framework.
The simplest way of integrating AngleSharp to your project is by using NuGet. You can install AngleSharp by opening the package manager console (PM) and typing in the following statement:
Install-Package AngleSharpYou can also use the graphical library package manager ("Manage NuGet Packages for Solution"). Searching for "AngleSharp" in the official NuGet online feed will find this library.
In the most simple case you have already a document source and want it to be parsed. This could look like the following:
using System;
using AngleSharp;
using AngleSharp.Html.Parser;
class MyClass {
static async void Main() {
//Use the default configuration for AngleSharp
var config = Configuration.Default;
//Create a new context for evaluating webpages with the given config
var context = BrowsingContext.New(config);
//Source to be parsed
var source = "<h1>Some example source</h1><p>This is a paragraph element";
//Create a virtual request to specify the document to load (here from our fixed string)
var document = await context.OpenAsync(req => req.Content(source));
//Do something with document like the following
Console.WriteLine("Serializing the (original) document:");
Console.WriteLine(document.DocumentElement.OuterHtml);
var p = document.CreateElement("p");
p.TextContent = "This is another paragraph.";
Console.WriteLine("Inserting another element in the body ...");
document.Body.AppendChild(p);
Console.WriteLine("Serializing the document again:");
Console.WriteLine(document.DocumentElement.OuterHtml);
}
}Of course one could go further and perform a lot more DOM manipulations.
IBrowsingContext represents a browsing context where document evaluations take place. This is a required construct for parsing any HTML page. It also allows submitting forms, following links, downloading resources, and more. We can think of it like a tab in a standard browser.
Alternatively, we could have used the following code in the beginning:
var context = BrowsingContext.New(config);
var parser = context.GetService<IHtmlParser>();
var source = "<h1>Some example source</h1><p>This is a paragraph element";
var document = parser.ParseDocument(source);So what is the IHtmlParser? This is a class that represents the HTML5 parser front-end. It has methods to create an instance of IHtmlDocument, which carries the parsed DOM. Since HTML is quite relaxed about possible errors, there is nothing like exceptions. We only might get some error messages. These messages can be received via a special interface and should be treated like warnings.
The idea behind AngleSharp is to provide state-of-the-art parsers (for CSS, HTML and related objects, such as URLs), which generate the same DOM as a modern browser would do. The same DOM means that the same API is used as known from JavaScript / from current browsers. This API is standardized and well-known among web developers. Also the liveliness of DOM interaction is then not only restricted to JavaScript, or browser hosting scenarios. AngleSharp will make it possible to basically bring the core of a modern browser to your code.
The whole DOM has been transported to a logical class structure. A part of this structure could be resolved as the following picture shows. Note that the picture shows an older DOM model. The current version of AngleSharp implements the latest DOM model, which is slightly different. Nevertheless, the picture is still useful to get the right idea.
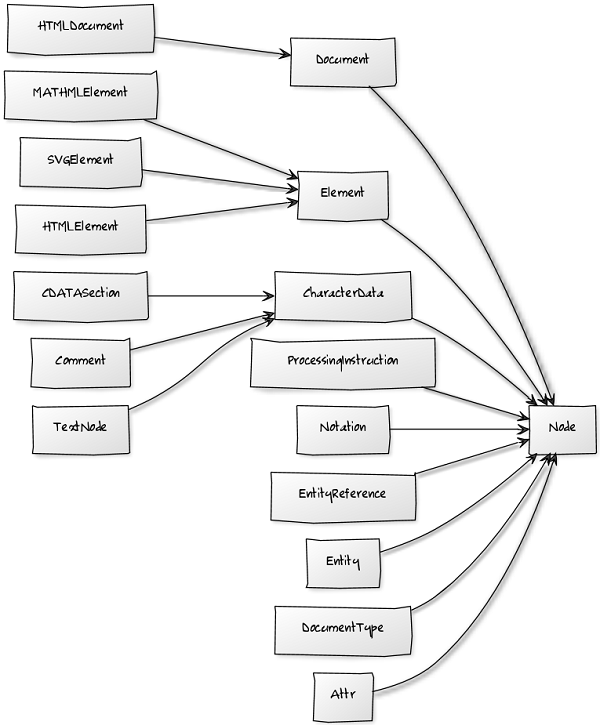
There are some restrictions to the DOM:
- One cannot just create elements in general - there are nearly always factories in the
IDocumentinstance or specialization such as theIHtmlDocument - Inheritance of known elements is not possible
- Modifications of the DOM have to follow the given paths
This means that one cannot write code like (note: the HtmlParagraphElement element is internal, anyway - it is the (default) implementation of the IHtmlParagraphElement interface),
var paragraph = new HTMLParagraphElement();as this is also not possible in e.g. JavaScript. What one requires is an instance of the IDocument interface. If we assume that this instance is called document we can now write
var paragraph = document.CreateElement("p");which creates the paragraph (<p>) element and assigns the given document as the owner of the node. As in the JavaScript / DOM world, we did not append the paragraph anywhere in the document. When an element is not being appended it has no parent and thus does not appear in the DOM tree. As a consequence it would not be serialized again, and some special actions would be without meaning. Furthermore, queries on the DOM tree would not show the given elements.
On the other side those restrictions result in all constructors being marked as internal. This prevents inheritance (even though the class might be not sealed) and requires users to follow the given paths.
The advantage of scripting languages such as JavaScript is that even though CreateElement only returns an IElement, one is able to access even specialized properties and methods of, e.g., IHtmlElement, if available. In static typed languages (such as C#) we require casts. One way out would be to use dynamic, or handy extension methods such as
var paragraph = document.CreateElement<IHtmlParagraphElement>();This works and directly returns an object of type IHtmlParagraphElement. No cast needed and one (dubious) string allocation saved. This particular extension method is placed in the namespace AngleSharp.Dom.
AngleSharp provides several properties and methods that are not accessible via the standardized DOM properties and methods. To distinguish between standardized and extended a simple attribute class called DomNameAttribute has been added. The attribute is applied in those cases, where the decorated class / event / method or property is also specified in the official W3C standard. Additionally the official name is set, since AngleSharp follows the PascalCase convention, while the DOM follows the camelCase convention.
AngleSharp also provides objects that are not listed at all in the official W3C specification. Sometimes those classes are specializations of W3C defined objects (e.g. MathElement is derived from Element, however, while Element is also specified in the official specification, MathElement is not), or just part of the AngleSharp eco-system.
The interface IConfiguration can be used to configure the behavior of AngleSharp. It is possible to derive from a sample implementation called Configuration, to use the sample implementation directly (e.g. new Configuration()) or to start by implementing our own configuration via IConfiguration.
If no configuration is provided, AngleSharp will use a default configuration. The default configuration can also be set, removing any configuration transportation requirements at all. In most scenarios using Configuration.Default makes sense. Note that the Configuration is immutable and that all extension methods for IConfiguration will never try to modify the passed object. They will always return an unmodified object, or a new object with the modifications.
Finally AngleSharp also brings some very helpful extension methods that try to be similar for what jQuery offers in JavaScript. Using the namespace AngleSharp one can access methods like Html, Css, Attr or Text. These methods operate on a given IEnumerable<IElement> like an existing IHtmlCollection. The purpose is quite simple: To easily modify the given DOM.
// using AngleSharp.Html.Parser;
// using AngleSharp.Dom;
// using AngleSharp;
//Create a new browsing context for hosting the document
var context = Browsing.New(Configuration.Default);
//Generate HTML DOM for the following source code
var document = await context.OpenAsync(req => req.Content("<ul><li>First element<li>Second element<li>third<li class=bla>Last"));
//Get all li elements and set the test attribute to the value test; elements still contains all li elements
var elements = document.QuerySelectorAll("li").Attr("test", "test");It should be noted that applying Text or Html will have consequences for the DOM. For example if we apply it to a list of several elements, where some elements of the list contain other elements of the same list, the resulting list will still contain all those elements, however, the document will not.
The reason for this behavior is quite simple: Applying e.g. Html will remove all children of a node and append new children, which have been obtained by parsing the given source. Similarly Text will remove all children and append an IText node with the given textual content.