#PALLAIDIUM - a generative AI movie studio integrated into the Blender video editor. AI-generate video, image, and audio from text prompts or video, image, or text strips.

| Text to video | Text to audio |
| Text to speech | Text to image |
| Image to image | Image to video |
| Video to video | Image to text |
| ControlNet | OpenPose |
| ADetailer | IP Adapter Face/Style |
| Canny | Illusion |
| Multiple LoRAs | Segmind distilled SDXL |
| Seed | Quality steps |
| Frames | Word power |
| Style selector | Strip power |
| Batch conversion | Batch refinement of images. |
| Batch upscale & refinement of movies. | Model card selector. |
| Render-to-path selector. | Render finished notification. |
| Model Cards | One-click install and uninstall dependencies. |
| User-defined file path for generated files. | Seed and prompt added to strip name. |

- Windows (Unsupported: Linux and MacOS).
- A CUDA-supported Nvidia card with at least 6 GB VRAM.
- CUDA: 12.4
- 20+ GB HDD. (Each model is 6+ GB).
For Mac and Linux, we'll have to rely on contributor support. So, post your issues here for Mac: tin2tin#106 and here for Linux: tin2tin#105, and hope some contributor wants to help you out.
-
First, download and install git (must be on PATH): https://git-scm.com/downloads
-
Download the add-on: https://github.com/tin2tin/text_to_video/archive/refs/heads/main.zip
-
On Windows, right-click on the Blender icon and "Run Blender as Administrator"(or you'll get write permission errors).
-
Install the add-on as usual: Preferences > Add-ons > Install > select file > enable the add-on.
-
In the Generative AI add-on preferences, hit the "Uninstall Dependencies" button (to clear out any incompatible libs).
-
Restart Blender.
-
In the Generative AI add-on preferences, hit the "Install Dependencies" button.
-
Restart Blender.
-
Open the add-on UI in the Sequencer > Sidebar > Generative AI.
-
The first time any model is executed, 5-10 GB will have to be downloaded first.
| Tip |
|---|
| If any Python modules are missing, use this add-on to install them manually: |
| https://github.com/amb/blender_pip |
- 2024-8-5: Add: Flux Dev - NB. needs update of dependencies and 24 GB VRAM
- 2024-8-2: Add: Flux Schnell - NB. needs update of dependencies and 24 GB VRAM
- 2024-7-12: Add: Kwai/Kolors (txt2img & img2img)
- 2024-6-13: Add: SD3 - A "Read" token from HuggingFace must be entered, it's free (img2img). Fix: Installation of Dependencies
- 2024-6-6: Add: Stable Audio Open, Frame:-1 will inherit duration.
- 2024-6-1: IP Adapter(When using SDXL): Face (Image or folder), Style (image or folder) New image models: Mobius, OpenVision, Juggernaut X Hyper
- 2024-4-29: Add: PixArt Sigma 2k, PixArt 1024 and RealViz V4
- 2024-2-23: Add: Proteus Lightning and Dreamshaper XL Lightning
- 2024-2-21: Add: SDXL-Lightning 2 Step & Proteus v. 0.3
- 2024-1-02: Add: WhisperSpeech
- 2024-01-01: Fix installation and Bark bugs.
- 2024-01-31: Add OpenDalle, Speed option, SDXL, and LoRA support for Canny and OpenPose, including OpenPose rig images. Prune old models including SD.
- 2023-12-18: Add: Bark audio enhance, Segmind Vega.
- 2023-12-1: Add SD Turbo & MusicGen Medium, MPS device for MacOS.
- 2023-11-30: Add: SVD, SVD-XT, SDXL Turbo
Install Dependencies, and set Sound Notification in the add-on preferences:

Video Sequence Editor > Sidebar > Generative AI:


See SDXL handling most of the styles here: https://stable-diffusion-art.com/sdxl-styles/
https://replicate.com/blog/get-the-best-from-stable-diffusion-3
https://github.com/invoke-ai/InvokeAI/blob/main/docs/features/PROMPTS.md
https://stablediffusion.fr/prompts
https://blog.segmind.com/generating-photographic-images-with-stable-diffusion/
| Tip |
|---|
| If the image of your renders breaks, use the resolution from the Model Card in the Preferences. |
| Tip |
|---|
| If the image of your playback stutters, then select a strip > Menu > Strip > Movie Strip > Set Render Size. |
| Tip |
|---|
| If you get the message that CUDA is out of memory, restart Blender to free up memory and make it stable again. |
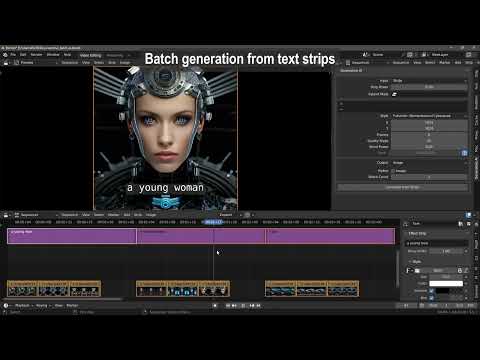
Select multiple strips and hit Generate. When doing this, the file name, and if found the seed value, are automatically inserted into the prompt and seed value. However, in the add-on preferences, this behavior can be switched off.
ai_batch_ex2_0000-0574.mp4
Find Bark documentation here: https://github.com/suno-ai/bark
- [laughter]
- [laughs]
- [sighs]
- [music]
- [gasps]
- [clears throat]
- — or ... for hesitations
- ♪ for song lyrics
- capitalization for emphasis on a word
- MAN/WOMAN: for bias towards the speaker
Speaker Library: https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c
| Tip |
|---|
| If the audio breaks up, try processing longer sentences. |
The performance can be improved by following this guide: https://nvidia.custhelp.com/app/answers/detail/a_id/5490/~/system-memory-fallback-for-stable-diffusion
Watch this tutorial: https://youtu.be/4_MIaxzjh5Y?feature=shared
Hugging Face Diffusers models are downloaded from the hub and saved to a local cache directory. By default, the cache directory is located at:
On Linux and macOS: ~/.cache/huggingface/hub
On Windows: %userprofile%\.cache\huggingface\hub
Here you can locate and delete the individual models.
Since the Generative AI add-on can only input images or movie strips, you'll need to convert other strip types to movie-strip. For this purpose, this add-on can be used:
https://github.com/tin2tin/Add_Rendered_Strips

For creating a mask on top of a clip in the Sequencer, this add-on can be used to input the clip as background in the Blender Image Editor. The created mask can then be added to the VSE as a strip, and converted to video with the above add-on:
https://github.com/tin2tin/vse_masking_tools

Edit and navigate in the generated text strips.
https://github.com/tin2tin/Subtitle_Editor
Get chatGPT to generate stories, which can be used as prompts.
https://github.com/tin2tin/Blender_Screenwriter_Assistant_chat_GPT
Convert text from the Text Editor to strips which can be used as prompts for batch generation.
https://github.com/tin2tin/text_to_strip
Trainer for LoRAs: https://github.com/Nerogar/OneTrainer https://github.com/johnman3032/simple-lora-dreambooth-trainer
HD Horizon(LoRA for making SD 1.5 work at higher resolutions): https://civitai.com/models/238891/hd-horizon-the-resolution-frontier-multi-resolution-high-resolution-native-inferencing
Triton for manual installation on Windows: https://huggingface.co/madbuda/triton-windows-builds
derush20001-0571.mp4
Illusion_silent_0001-0366.mp4
scribble_0001-0156.mp4
TEXTs_010000-0495.mp4
Controlnet_final_0001-0603.mp4
OpenPose10000-0320.mp4

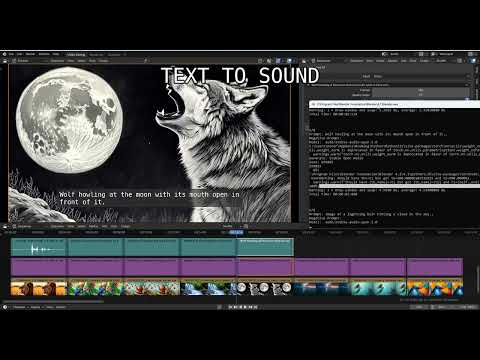



bagel.mp4
Burger4.mp4
3160-3714.mp4
Hammershoi.mp4
https://huggingface.co/blog/lcm_lora
- It is prohibited to use Pallaidium to generate content that is demeaning or harmful to people, their environment, culture, religion, etc.
- It is prohibited to use Pallaidium for pornographic, violent, and bloody content generation.
- It is prohibited to use Pallaidium for error and false information generation.
- Pallaidium does not include any genAI models(weights). If the user decides to use a model, it is downloaded from HuggingFace.
- In general, the models can only be used for non-commercial purposes and are meant for research purposes.
- Consult the individual models on HuggingFace to read up on their licenses and ex. if they can be used commercially.