DataHarmonizer Templates
DataHarmonizer provides spreadsheet data entry and validation templates as defined by LinkML schemas. It doesn't implement all of LinkML's functionality but it covers parts pertinent to tabular data management. DataHarmonizer's /web/templates/ folder contains working examples of individual folders, each dedicated to serving up the one or more templates specified in the folder's LinkML schema.json file, which provides DataHarmonizer with all the textual, datatype and other information used to compose each section and column (field) and picklists of a user-editable spreadsheet.
Before getting into the details, also note LinkML's basic names for data schema parts as they relate to tabular spreadsheets:
- A LinkML schema may contain classes, slots, enums, types, and settings as described below.
- A LinkML class is used to hold a spreadsheet (i.e. tabular data) template specification. It can define its own slots (fields), or draw from a common pool of slots that the schema provides for any template to use.
- A LinkML slot holds a column field specification, so it controls the data entry and validation for a spreadsheet column's cells.
- A LinkML enum holds a flat or hierarchic list of categorical picklist values that can be used by one or more slots.
- A LinkML type often corresponds to a database field datatype, and is referenced in a slot's range of acceptable values.
The stand-alone (webserver-less) DataHarmonizer application needs to read a schema.json file in order to display any of the templates contained therein. Schema.json is a conversion from the LinkML schema.yaml file in its native YAML format. Schema.yaml and schema.json can be generated in 1 step from tsv files containing most of a schema's details by using the /script/tabular_to_schema.py script which reads and processes the following files to produce the schema.
| file | description |
|---|---|
| schema_core.yaml | Optional. A manually managed main LinkML schema file that schema_slots.yaml and schema_enums.yaml are merged with. It contains custom data types, namespace prefixes, and settings. |
| schema_slots.tsv | Optional. A list of all classes (templates) and their slot definition parts (fields). |
| schema_enums.tsv | Optional. A list of all categorical selection lists used by the schema's slots. |
The tsv files can actually be copied directly from respective (e.g. Google) spreadsheets containing column and picklist specifications. For more information, see the Managing-schema.yaml page.
With a terminal window open on a particular template directory,
> python3 ../../../script/tabular_to_schema.py
will generate schema.json and schema.yaml files in the same directory based on the content of schema_core.yaml, schema_slots.tsv, and schema_enums.tsv . This script uses LinkML runtime calls to augment classes and add generic LinkML datatypes to schema.json .
The optional "-m" input parameter adds the template(s) in schema.json to the DataHarmonizer templates menu. It creates the /web/template/menu.json script if needed, and then augments or updates the list of templates it contains with the schema template(s) being generated.
If you want to validate schema.yaml from LinkML's perspective, you can use the linkml-lint program that is provided with LinkML runtime:
> linkml-lint schema.yaml
This will indicate whether schema.yaml is in good shape by outputting a textual display of the schema. Note that this program may issue warnings about enumeration "permissible_values" items not being "standard names" if they have spaces in them. This happens when an enumeration item only has a title attribute, and no "name" attribute; The name attribute is expected to be in lowercase snake_case form, but if it isn't provided, the title is reused for the name attribute.
For those users who want to dispense with the schema core, slots and enums files mentioned above, and just hand-edit the /web/templates/[template folder]/schema.yaml file, this is doable, since a /script/linkml.py script is designed to convert schema.yaml to schema.json. The script will also automatically add the templates to the menu.js folder if they aren't already listed in it.
One also has the option of using LinkML's Schemasheets application to manage a schema's content.
Each web/templates/ subfolder typically includes:
| file | description |
|---|---|
| schema.json | A file containing the schema.yaml content, with some adjustments, in json format which DataHarmonizer loads directly in main.html. |
| schema.yaml | A YAML formatted file containing a LinkML specification for one or more spreadsheet templates, each represented as a LinkML class (which defines all columns and sections of columns for the spreadsheet), along with any necessary supporting LinkML "enums", "types", and "slots". |
| SOP.pdf | Statement of Procedure document. Note, if this isn't included, a broken link will occur in Help menu's SOP link. |
| export.js | Contains permitted export data formats, and any custom transformation case code that DataHarmonizer's generic field export options can't handle. |
| exampleInput/ | A folder containing spreadsheet data that tests validation success or failure cases. |
export.js minimally can contain:
// A dictionary of possible export formats
export default {};
The schema.yaml contains a list of all possible templates for a folder, and supporting information. For those who are building schema.yaml from the 3 files above, the schema_core.yaml file populates schema.yaml's top level entities. Generally schema.yaml (and schema_core.yaml) contain:
- A generic resolvable URI for the schema.
- A name and description for the schema.
- An imports section that indicates below to include the LinkML built-in data types such as decimal and date.
- A list of prefixes that may occur in ontology or other term IRI references.
- Objects containing dictionaries of classes (templates), slots (fields), enumerations (pick lists), types (datatypes), and settings (search & replace key / values).
From the example schema_core.yaml below, the "CanCOGeN Covid-19" schema will be built, with one "CanCOGeN Covid-19" class (template) which DataHarmonizer will show in its menu system. IMPORTANT: DataHarmonizer will add each schema class as a template to its menu system if it finds that the class has an "is_a" relationship to the special "dh_interface" class.
id: https://example.com/CanCOGeN_Covid-19
name: CanCOGeN_Covid-19
description: ""
in_language:
- en
imports:
- "linkml:types"
prefixes:
linkml: "https://w3id.org/linkml/"
GENEPIO: "http://purl.obolibrary.org/obo/GENEPIO_"
classes:
dh_interface:
name: dh_interface
description: "A DataHarmonizer interface"
from_schema: https://example.com/CanCOGeN_Covid-19
"CanCOGeN Covid-19":
name: "CanCOGeN Covid-19"
description: Canadian specification for Covid-19 clinical virus biosample data gathering
is_a: dh_interface
slots: ...
enums: ...
types:
WhitespaceMinimizedString:
name: "WhitespaceMinimizedString"
typeof: string
description: "A string that has all whitespace trimmed off of beginning and end, and all internal whitespace segments reduced to single spaces. Whitespace includes #x9 (tab), #xA (linefeed), and #xD (carriage return)."
base: str
uri: xsd:token
Provenance:
name: "Provenance"
typeof: string
description: "A field containing a DataHarmonizer versioning marker. It is issued by DataHarmonizer when validation is applied to a given row of data."
base: str
uri: xsd:token
settings:
Title_Case: "(((?<=\\b)[^a-z\\W]\\w*?|[\\W])+)"
UPPER_CASE: "[A-Z\\W\\d_]*"
lower_case: "[a-z\\W\\d_]*"
As described in Managing schema.yaml, a class's "slots: " and "enums: " dictionaries can be filled in by the tabular_to_schema.py script.
The data types available for a slot to reference and which control user interface functionality are listed in the schema.js types dictionary. (It reflects custom types specified in the schema.yaml types dictionary as well as the generic linkml:types which should be set in the imports section. The schema_core.yaml file contributes to both these type sources.)
The types object should include the WhitespaceMinimizedString shown above (it translates to the XML xsd:token data type). This enables slots that hold strings to use it as their range especially in the case where a string field is stored in a tab or comma separated tabular dataset field.
The Provenance type is a special data type which, on validation, inserts or overwrites a "DataHarmonizer provenance: vX.Y.Z" string as content for each row to indicate which version of DataHarmonizer has done the validation. (In the future this may also take on the version of the template, and other information).
Additional types, imported via linkml.py, include:
| type | description | XML equivalent | OLD DataHarmonizer type |
|---|---|---|---|
| string | A character string | xsd:string | xs:token |
| integer | An integer | xsd:integer | xs:nonNegativeInteger |
| boolean | A binary (true or false) value | xsd:boolean | - |
| float | A real number that conforms to the xsd:float specification | xsd:float | - |
| double | A real number that conforms to the xsd:double specification | xsd:double | - |
| decimal | A real number with arbitrary precision that conforms to the xsd:decimal specification | xsd:decimal | xs:decimal |
| time | A time object represents a (local) time of day, independent of any particular day | xsd:dateTime | - |
| date | a date (year, month and day) in an idealized calendar | xsd:date | xs:date |
| datetime | The combination of a date and time | xsd:dateTime | - |
| uriorcurie | a URI or a CURIE | xsd:anyURI | - |
| uri | a complete URI | xsd:anyURI | - |
| ncname | Prefix part of CURIE | xsd:string | - |
| objectidentifier | A URI or CURIE that represents an object in the model. Used for inheritence and type checking | shex:iri | - |
| nodeidentifier | A URI, CURIE or BNODE that represents a node in a model. | shex:nonLiteral | - |
The old DataHarmonizer <= 0.15.5 had some data types that are now handled as properties of slots:
- select: This is now replaced by a range containing the name of the enumeration to use as a menu
- multiple: In addition to supplying a range as with select above, a slot property called "multivalued" is set to TRUE
- xs:unique: Replaced by a slot property called identifier with a TRUE value.
- xs:token: Usually replaced by type WhitespaceMinimizedString
- xs:date: Replaced by type date
- provenance: Replaced by the DataHarmonizer 1.0.0 custom Provenance type
Detailed information about these parameters from a LinkML perspective is here.
| property | description |
|---|---|
| title | A user-friendly label that gets displayed in the first row of spreadsheet column |
| name | optional but may supply the database field name, if different from the title. |
| slot_group | the section header of the template this field should be displayed under. Note that output .tsv and .csv tabular data will show section header names in the first row, and the second row for field/column names. |
| description | Helpful description of what field is about. Available in column help info. |
| comments | Data entry guidance for a field. Available in column help info. |
| examples | An array of values which are displayed as a bulleted list in column help info. |
| slot_uri | an ontology id or URI that provides a unique semantic web identifier for this slot. (Was Ontology ID in DH <= v0.15.5) |
| range | A data type that a slot value validates to. |
| any_of | A list of ranges that indicate the kind of data this slot validates to. |
| identifier | If true means this field value should be unique within the column (of tabular data). |
| multivalued | If true then more than one value is allowed for this field. Multiple values are usually delimited by semi-colons. |
| required | If true means this field requires a data value. |
| recommended | If true means this field is suggested for data entry but this is not required. |
| minimum_value | Contains a minimum numeric number that a decimal or integer value can take on. |
| maximum_value | Contains a maximum numeric number that a decimal or integer value can take on. |
| todos | Currently DataHarmonizer uses this special field to list a set of minimum and maximum conditions that a date can match to, e.g. "<={today}" will cause a date entry to be validated against today; if it is in the future, validation will fail. This functionality may be moved over to LinkML "rules" as that is finalized. |
| pattern | A regular expression to validate a field's textual content by. Include ^ and $ start and end of line qualifiers for full string match. Example simple email validation: ^\S+@\S+.\S+$ |
| structured_pattern | A LinkML system for specifying strings containing regular expression pattern names which are compiled into a pattern. Takes advantage of search and replace operations of names stored in a schema's settings dictionary. |
| exact_mappings | A list of external database fields this slot's content could be exported to. |
Description, comments, and examples properties and a few other properties get echoed in column display information when double-clicking on column header, and are also echoed in the Help menu "Reference Guide".
DataHarmonizer <=0.15.5 used to have a "capitalize" field that would control capitalization of a given field with options [ lower | UPPER | Title ], but this functionality is now achieved by specifying {lower_case} or {UPPER_CASE} or {Title_Case} in the structured_pattern field.
The specimen collector sample ID slot below shows a typical template field specification.
specimen collector sample ID:
name: specimen collector sample ID
title: specimen collector sample ID
description: The user-defined name for the sample.
comments: Every Sample ID from a single submitter must be unique. It can have
any format, but we suggest that you make it concise, unique and consistent within
your lab, and as informative as possible.
examples:
- value: prov_rona_99
slot_uri: GENEPIO:0001123
range: WhitespaceMinimizedString
required: true
exact_mappings:
- GISAID:Sample ID given by the sample provider
- GISAID:Sample ID given by the submitting laboratory
- NCBI_BIOSAMPLE:sample_name
- NCBI_SRA:sample_name
- NCBI_Genbank:sample_name
- NCBI_Genbank_source_modifiers:Sequence_ID
In the LinkML schema, slots can describe elemental data entry fields, including those that capture numbers, dates, strings, or categorical values. Alternately, a slot might contain more complex data structures such as value + unit combinations. Each slot can have one or more ranges specified that supply a field type or complex structure reference. If a slot has only one range data type, such as "integer", that will be found in its "range" property.
number of base pairs sequenced:
name: number of base pairs sequenced
title: number of base pairs sequenced
description: The number of total base pairs generated by the sequencing process.
comments: Provide a numerical value (no need to include units).
examples:
- value: '2639019'
slot_uri: GENEPIO:0001482
range: integer
minimum_value: '0'
If a slot has multiple range possibilities, each range will be listed in an "any_of" property list. For example the "sample collected by" slot below has an "any_of" list of ranges containing "WhitespaceMinimizedString" and a "null value menu", thus allowing a free text entry, but also a menu of metadata values like "Missing", "Not Collected", "Restricted Access", etcetera :
sample collected by:
...
any_of:
- range: WhitespaceMinimizedString
- range: null value menu
A class may include a slot_usage dictionary, which allows the listing of generic slots to include in the class, along with other properties to augment them with for the given class. In this way:
- a slot's ordering is controlled by way of a rank property.
- a slot_group property controls which section the slot occurs within.
Other properties such as required or recommended can be added here too.
Field picklist menus are stored in a schema's enums dictionary with picklist menu name as a key, and the resulting object containing a permissable_values array of picklist items. Each item can have a meaning ontology identifier for mapping purposes. As shown there is a mechanism to make them hierarchical rather than just flat, using the "is_a" property. Here 'Ageusia (complete loss of taste):' is_a 'Abnormality of taste sensation', so user interfaces have the information to position Ageusia under its parent in the menu system, as DataHarmonizer does. Finally, there is a mechanism for each picklist item to be mapped to another database's field content by way of the exact_mappings parameter which holds a database namespace reference, a field name to map to, and optionally, a value to map to, all separated by colons.
signs and symptoms menu:
name: signs and symptoms menu
permissible_values:
Abnormal lung auscultation:
text: Abnormal lung auscultation
meaning: HP:0030829
Abnormality of taste sensation:
text: Abnormality of taste sensation
meaning: HP:0000223
Ageusia (complete loss of taste):
text: Ageusia (complete loss of taste)
meaning: HP:0041051
is_a: Abnormality of taste sensation
The text property isn't necessary if spelled out as the object's key label too.
The LinkML development team is working on a command line option for precompiling selected ontology terms or branches into schema enumerations that will immediately appear as picklist options in DataHarmoizer. There is the potential for live lookup of such terms but occasionally online lookup services are unreliable.
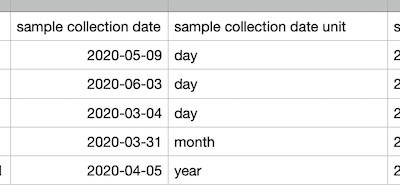
Often the date or date and time of an event such as sample collection is recorded to some degree of precision. However database date and datetime types usually don't have any formal way of incorporating that precision information. We have provided one way of enabling precision to be specified which also causes entered dates to be normalized to some extent on loading of a dataset. The mechanism is fairly simple: if a specification supplies an ISO 8601 date field, like "sample collection date" then if one also includes the same field with a " unit" suffix, i.e. "sample collection date unit", then DH will take this as a signal to apply the following normalization mechanism:
The image below shows that date formatting is being normalized row-by-row to the YYYY-01-01 or YYYY-MM-01 or YYYY-MM-DD degree of precision based on other field's " precision" setting. This approach supports dates destined for database date fields, that need date comparison for order at least, and in a sense matching granularity, e.g. year entries will match perfectly, month ones will too, etc.
Here is the spreadsheet data before it gets opened in DataHarmonizer:
When it is opened in DH, the dates get adjusted to match granularity:
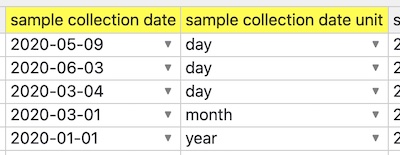
As well if some dates can't be matched to granularity (say month is missing but that's the granularity set) then DH will currently put an "__" underscore value in appropriate position in date so that validation trips and user is drawn to specify the desired granularity. For example if "month" is granularity unit, but given date is just year "2020", then entry will be converted to "2020-__-01", thus triggering validation error.
If one simply name the "date ... unit" field to have a different suffix, like "... precision", then the whole automatic normalization (to first day of month, or first month) process is skipped:
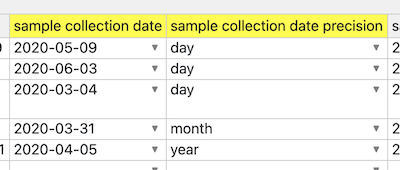
Code portions of this solution involve the setDateChange() function. This doesn't currently handle time precision however.
Often there is a need to specify a number specifically, such as an age at time of sample collection, but at the same time offer a range of bin entries for the same datum, for data normalization between databases or for preserving privacy through aggregation. DataHarmonizer has a mechanism for simplifying the data entry involved in such work by allowing a numeric field, such as "age", to be followed by an optional "unit" (such as a pulldown menu including "month" and "year"), followed by a select menu of numeric ranges, each of which is a string of text containing leading and tailing integers that can be parsed into the ranges that the single numeric field can be validated within. On dataset load, and on data entry, the bin will be updated in accordance with the numeric field and unit field entries automatically.
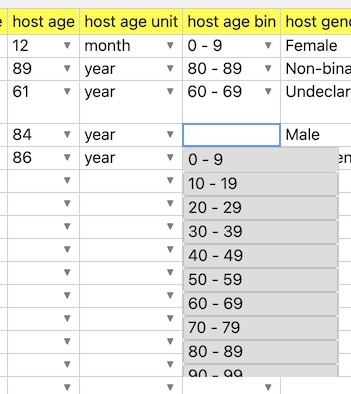
The key to activating this functionality is in the field names. Given a field name "X", having special field names "X unit", and "X bin" will trigger this function. The unit field is optional, and is a bit of a hack. If one includes "month" in it, then the numeric field entry will be multiplied by 12 (months) in order to find the right bin to fit it in. In the future a better way of providing semantics and field connectivity will be offered.
A number of templates are hard-coded into the DataHarmonizer menu system (see /web/templates/menu.json). Currently, compiling new ones into the menu requires either the "yarn dev" command for browser testing, or "yarn build:web" command for packaging into a stand-alone DH app. We aim to add a function soon to allow development and testing of a schema.yaml template without having to recompile via a browser URL parameter.