今回のデータ量が大きいですので、pre-trained modelを使ってなるべく学習時間を短縮してやっております。 VQAはVisual Question Answeringの略語です。画像についての質問に自然言語で答えることを目的としています。 VQAの前処理は主に二つ部分があります:画像処理と自然言語処理。 画像処理の部分は、baselineの元でResnet50のpre-trained modelを使っています。VQAの学習は通常、画像の前処理はあまりしていないのため、そのままpre-trained modelを使いました。 自然言語の部分は、文献調査して、BERTというmodelを決めました。しかし、より速い学習をしたいので、今回はTinyBERTを使います。
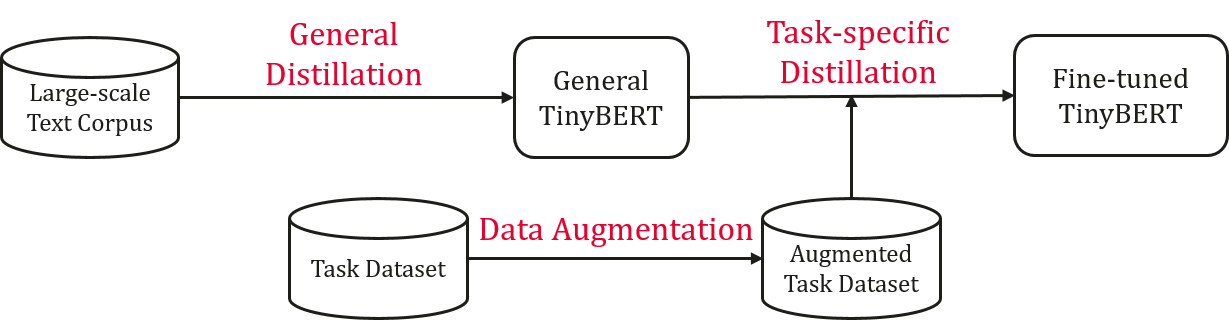
TinyBERTについて紹介します。 一般のBERT-base modelより7.5倍小さくて9.4倍速いです。今回の課題に対して適用すると思って実装に決めました。
参考論文:
Github:
今回は初めてOmnicampusの演習環境を使いました。 データdownloadとinputには特に問題がないですが、今回データ量が多くて、実行時間を短縮したいのため、Dataloaderを使いました。 Dataloaderはbatch processingできるので、inputの時間をだいぶ短縮しました。
参考:
https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
また、今回は学習を高速化するため、mixed precisionの方法も使いました。 この二つ方法を使って、学習時間をだいぶ短縮しました。
参考:
提出前にOmnicampusの環境に実行できない状況にも何回ありましたので、Colab Notebookにも環境配置しました。Google DriveのDefault storageは15GBしかないので、Colabに実行する際にはGoogle Oneが必要です。 Omnicampusに実行できない原因はまだ不明ですが、おそらくmixed precisionを実行する時問題が起こりました。
具体的には、
'warnings.warn("torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.")'が出て、Jupyter Notebookは繋がらないになりました。
BERT modelは前処理を必要ではないですが、baseline codeの自然言語前処理の部分を保留しました。 一番注意しなきゃいけない部分はdim数です。 TinyBERTのinput dimは768、out dimは312です。 また、ResNet50のout dimは2048です。
今回pre-trained modelの実装は初めてですので、dim数の問題で結構時間がかかりました。
残念ですが、今回はあまりいい結果を出していなかったです。 dropoutとAdamW(optimizer)を使いましたが、overfittingの現象を見ました。 それは、Fine-tuningにあまり経験がなくて、learning rateを0.001を設定したと思います。 lrを下げて、0.0001と0.00001を試すともっといい結果が出ると思います。
また、TinyBERTはVQA問題専門じゃないので、他のモデルを使うとよりいい結果を出ると思います。
今回は初めてGithubリポジトリを作成しました。自分の研究にもよくGithubを使うことがありますので、とても勉強になりました。
また、医薬系出身ですが、この三ヶ月の勉強で、Deep Learningの論文を読めできるになりました。実装とtuningにはまだまだ素人ですが、基礎概念を理解して、最初やる時と全然違う考え方になりました。
深層学習は自分の研究にとって非常に役立ちますので、これからも勉強を続けていきたいと思います。