| pplcv |
A high-performance image processing library of openPPL.
@@ -273,12 +278,14 @@ source ~/.bashrc
```
### Build MMDeploy
+
```bash
cd /the/root/path/of/MMDeploy
export MMDEPLOY_DIR=$(pwd)
```
#### Build Options Spec
+
@@ -356,6 +363,7 @@ Currently, The Model Converter supports torchscript, but SDK doesn't.
#### Build Model Converter
##### Build Custom Ops
+
If one of inference engines among ONNXRuntime, TensorRT, ncnn and libtorch is selected, you have to build the corresponding custom ops.
- **ONNXRuntime** Custom Ops
@@ -400,17 +408,20 @@ If one of inference engines among ONNXRuntime, TensorRT, ncnn and libtorch is se
cd ${MMDEPLOY_DIR}
pip install -e .
```
+
**Note**
- Some dependencies are optional. Simply running `pip install -e .` will only install the minimum runtime requirements.
To use optional dependencies, install them manually with `pip install -r requirements/optional.txt` or specify desired extras when calling `pip` (e.g. `pip install -e .[optional]`).
Valid keys for the extras field are: `all`, `tests`, `build`, `optional`.
+
#### Build SDK
MMDeploy provides two recipes as shown below for building SDK with ONNXRuntime and TensorRT as inference engines respectively.
You can also activate other engines after the model.
- cpu + ONNXRuntime
+
```Bash
cd ${MMDEPLOY_DIR}
mkdir -p build && cd build
@@ -427,6 +438,7 @@ You can also activate other engines after the model.
```
- cuda + TensorRT
+
```Bash
cd ${MMDEPLOY_DIR}
mkdir -p build && cd build
diff --git a/docs/en/build/windows.md b/docs/en/build/windows.md
index f84fa10239..f1c3c02586 100644
--- a/docs/en/build/windows.md
+++ b/docs/en/build/windows.md
@@ -16,19 +16,24 @@
- [Build Demo](#build-demo)
- [Note](#note)
----
+______________________________________________________________________
+
Currently, MMDeploy only provides build-from-source method for windows platform. Prebuilt package will be released in the future.
## Build From Source
+
All the commands listed in the following chapters are verified on **Windows 10**.
### Install Toolchains
+
1. Download and install [Visual Studio 2019](https://visualstudio.microsoft.com)
-2. Add the path of `cmake` to the environment variable `PATH`, i.e., "C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\Common7\IDE\CommonExtensions\Microsoft\CMake\CMake\bin"
+2. Add the path of `cmake` to the environment variable `PATH`, i.e., "C:\\Program Files (x86)\\Microsoft Visual Studio\\2019\\Community\\Common7\\IDE\\CommonExtensions\\Microsoft\\CMake\\CMake\\bin"
3. Install cuda toolkit if NVIDIA gpu is available. You can refer to the official [guide](https://developer.nvidia.com/cuda-downloads).
### Install Dependencies
+
#### Install Dependencies for Model Converter
+
@@ -71,6 +76,7 @@ pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/${cu_ve
#### Install Dependencies for SDK
You can skip this chapter if you are only interested in the model converter.
+
@@ -213,6 +219,7 @@ $env:MMDEPLOY_DIR="$pwd"
```
#### Build Options Spec
+
@@ -281,10 +288,10 @@ $env:MMDEPLOY_DIR="$pwd"
-
#### Build Model Converter
##### Build Custom Ops
+
If one of inference engines among ONNXRuntime, TensorRT and ncnn is selected, you have to build the corresponding custom ops.
- **ONNXRuntime** Custom Ops
@@ -378,4 +385,5 @@ $env:path = "$env:MMDEPLOY_DIR/build/install/bin;" + $env:path
```
### Note
- 1. Release / Debug libraries can not be mixed. If MMDeploy is built with Release mode, all its dependent thirdparty libraries have to be built in Release mode too and vice versa.
+
+1. Release / Debug libraries can not be mixed. If MMDeploy is built with Release mode, all its dependent thirdparty libraries have to be built in Release mode too and vice versa.
diff --git a/docs/en/codebases/mmcls.md b/docs/en/codebases/mmcls.md
index a1f958fe73..6e7b230faa 100644
--- a/docs/en/codebases/mmcls.md
+++ b/docs/en/codebases/mmcls.md
@@ -8,14 +8,14 @@ Please refer to [install.md](https://github.com/open-mmlab/mmclassification/blob
### List of MMClassification models supported by MMDeploy
-| Model | ONNX Runtime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
-| :----------- | :----------: | :------: | :---: | :---: | :------: | :----------------------------------------------------------------------------------------: |
-| ResNet | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/resnet) |
-| ResNeXt | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/resnext) |
-| SE-ResNet | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/seresnet) |
-| MobileNetV2 | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/mobilenet_v2) |
-| ShuffleNetV1 | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/shufflenet_v1) |
-| ShuffleNetV2 | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/shufflenet_v2) |
+| Model | ONNX Runtime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
+| :----------- | :----------: | :------: | :--: | :---: | :------: | :----------------------------------------------------------------------------------------: |
+| ResNet | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/resnet) |
+| ResNeXt | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/resnext) |
+| SE-ResNet | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/seresnet) |
+| MobileNetV2 | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/mobilenet_v2) |
+| ShuffleNetV1 | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/shufflenet_v1) |
+| ShuffleNetV2 | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/shufflenet_v2) |
### Reminder
diff --git a/docs/en/codebases/mmdet.md b/docs/en/codebases/mmdet.md
index f03bf7c60f..58c436ac1c 100644
--- a/docs/en/codebases/mmdet.md
+++ b/docs/en/codebases/mmdet.md
@@ -8,23 +8,23 @@ Please refer to [get_started.md](https://github.com/open-mmlab/mmdetection/blob/
### List of MMDetection models supported by MMDeploy
-| Model | Task | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
-| :----------------: | :------------------: | :---------: | :------: | :---: | :---: | :------: | :----------------------------------------------------------------------------------: |
-| ATSS | ObjectDetection | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/atss) |
-| FCOS | ObjectDetection | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fcos) |
-| FoveaBox | ObjectDetection | Y | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/foveabox) |
-| FSAF | ObjectDetection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fsaf) |
-| RetinaNet | ObjectDetection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/retinanet) |
-| SSD | ObjectDetection | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ssd) |
-| VFNet | ObjectDetection | N | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/vfnet) |
-| YOLOv3 | ObjectDetection | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolo) |
-| YOLOX | ObjectDetection | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolox) |
-| Cascade R-CNN | ObjectDetection | Y | Y | N | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn) |
-| Faster R-CNN | ObjectDetection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/faster_rcnn) |
-| Faster R-CNN + DCN | ObjectDetection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/faster_rcnn) |
-| GFL | ObjectDetection | Y | Y | N | ? | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/gfl) |
-| Cascade Mask R-CNN | InstanceSegmentation | Y | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn) |
-| Mask R-CNN | InstanceSegmentation | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn) |
+| Model | Task | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
+| :----------------: | :------------------: | :---------: | :------: | :--: | :---: | :------: | :----------------------------------------------------------------------------------: |
+| ATSS | ObjectDetection | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/atss) |
+| FCOS | ObjectDetection | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fcos) |
+| FoveaBox | ObjectDetection | Y | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/foveabox) |
+| FSAF | ObjectDetection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fsaf) |
+| RetinaNet | ObjectDetection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/retinanet) |
+| SSD | ObjectDetection | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ssd) |
+| VFNet | ObjectDetection | N | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/vfnet) |
+| YOLOv3 | ObjectDetection | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolo) |
+| YOLOX | ObjectDetection | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolox) |
+| Cascade R-CNN | ObjectDetection | Y | Y | N | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn) |
+| Faster R-CNN | ObjectDetection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/faster_rcnn) |
+| Faster R-CNN + DCN | ObjectDetection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/faster_rcnn) |
+| GFL | ObjectDetection | Y | Y | N | ? | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/gfl) |
+| Cascade Mask R-CNN | InstanceSegmentation | Y | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn) |
+| Mask R-CNN | InstanceSegmentation | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn) |
### Reminder
diff --git a/docs/en/codebases/mmdet3d.md b/docs/en/codebases/mmdet3d.md
index fdf1d4f5bc..a12141ed5b 100644
--- a/docs/en/codebases/mmdet3d.md
+++ b/docs/en/codebases/mmdet3d.md
@@ -20,11 +20,12 @@ python tools/deploy.py \
--device \
cuda:0
```
+
### List of MMDetection3d models supported by MMDeploy
-| Model | Task | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
-| :----------------: | :------------------: | :---------: | :------: | :---: | :---: | :------: | :------------------------------------------------------------------------------------------------------: |
-| PointPillars | VoxelDetection | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection3d/blob/master/configs/pointpillars) |
+| Model | Task | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
+| :----------: | :------------: | :---------: | :------: | :--: | :---: | :------: | :------------------------------------------------------------------------------------: |
+| PointPillars | VoxelDetection | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection3d/blob/master/configs/pointpillars) |
### Reminder
diff --git a/docs/en/codebases/mmedit.md b/docs/en/codebases/mmedit.md
index 78c5c1a54b..656082d5ad 100644
--- a/docs/en/codebases/mmedit.md
+++ b/docs/en/codebases/mmedit.md
@@ -8,16 +8,16 @@ Please refer to [official installation guide](https://mmediting.readthedocs.io/e
## MMEditing models support
-| Model | Task | ONNX Runtime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
-| :---------- | :--------------- | :----------: | :------: | :---: | :---: | :------: | :--------------------------------------------------------------------------------------------: |
-| SRCNN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srcnn) |
-| ESRGAN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/esrgan) |
-| ESRGAN-PSNR | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/esrgan) |
-| SRGAN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srresnet_srgan) |
-| SRResNet | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srresnet_srgan) |
-| Real-ESRGAN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/real_esrgan) |
-| EDSR | super-resolution | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/edsr) |
-| RDN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/rdn) |
+| Model | Task | ONNX Runtime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
+| :---------- | :--------------- | :----------: | :------: | :--: | :---: | :------: | :--------------------------------------------------------------------------------------------: |
+| SRCNN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srcnn) |
+| ESRGAN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/esrgan) |
+| ESRGAN-PSNR | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/esrgan) |
+| SRGAN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srresnet_srgan) |
+| SRResNet | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srresnet_srgan) |
+| Real-ESRGAN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/real_esrgan) |
+| EDSR | super-resolution | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/edsr) |
+| RDN | super-resolution | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/rdn) |
## Reminder
diff --git a/docs/en/codebases/mmocr.md b/docs/en/codebases/mmocr.md
index e96c233ff8..39c07e3f2d 100644
--- a/docs/en/codebases/mmocr.md
+++ b/docs/en/codebases/mmocr.md
@@ -8,12 +8,11 @@ Please refer to [install.md](https://mmocr.readthedocs.io/en/latest/install.html
### List of MMOCR models supported by MMDeploy
-| Model | Task | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
-| :---- | :--------------- | :---------: | :------: | :---: | :---: | :------: | :----------------------------------------------------------------------------: |
-| DBNet | text-detection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/dbnet) |
-| CRNN | text-recognition | Y | Y | Y | Y | N | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/crnn) |
-| SAR | text-recognition | Y | N | N | N | N | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/sar) |
-
+| Model | Task | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
+| :---- | :--------------- | :---------: | :------: | :--: | :---: | :------: | :----------------------------------------------------------------------------: |
+| DBNet | text-detection | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/dbnet) |
+| CRNN | text-recognition | Y | Y | Y | Y | N | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/crnn) |
+| SAR | text-recognition | Y | N | N | N | N | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/sar) |
### Reminder
diff --git a/docs/en/codebases/mmpose.md b/docs/en/codebases/mmpose.md
index 1dd0f9b404..b5f06f2cf8 100644
--- a/docs/en/codebases/mmpose.md
+++ b/docs/en/codebases/mmpose.md
@@ -9,7 +9,7 @@ Please refer to [official installation guide](https://mmpose.readthedocs.io/en/l
## MMPose models support
| Model | Task | ONNX Runtime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
-|:----------|:--------------|:------------:|:--------:|:----:|:-----:|:--------:|:-------------------------------------------------------------------------------------------:|
+| :-------- | :------------ | :----------: | :------: | :--: | :---: | :------: | :-----------------------------------------------------------------------------------------: |
| HRNet | PoseDetection | Y | Y | Y | N | Y | [config](https://mmpose.readthedocs.io/en/latest/papers/backbones.html#hrnet-cvpr-2019) |
| MSPN | PoseDetection | Y | Y | Y | N | Y | [config](https://mmpose.readthedocs.io/en/latest/papers/backbones.html#mspn-arxiv-2019) |
| LiteHRNet | PoseDetection | Y | Y | N | N | Y | [config](https://mmpose.readthedocs.io/en/latest/papers/backbones.html#litehrnet-cvpr-2021) |
diff --git a/docs/en/codebases/mmseg.md b/docs/en/codebases/mmseg.md
index 8cb30994b0..70520e4f87 100644
--- a/docs/en/codebases/mmseg.md
+++ b/docs/en/codebases/mmseg.md
@@ -8,41 +8,41 @@ Please refer to [get_started.md](https://github.com/open-mmlab/mmsegmentation/bl
### List of MMSegmentation models supported by MMDeploy
-| Model | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVino | Model config |
-|:----------------------------|:-----------:|:--------:|:----:|:-----:|:--------:|:----------------------------------------------------------------------------------------:|
-| FCN | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fcn) |
-| PSPNet[*](#static_shape) | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/pspnet) |
-| DeepLabV3 | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3) |
-| DeepLabV3+ | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3plus) |
-| Fast-SCNN[*](#static_shape) | Y | Y | N | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fastscnn) |
-| UNet | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/unet) |
-| ANN[*](#static_shape) | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ann) |
-| APCNet | Y | Y | Y | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/apcnet) |
-| BiSeNetV1 | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/bisenetv1) |
-| BiSeNetV2 | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/bisenetv2) |
-| CGNet | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/cgnet) |
-| DMNet | Y | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dmnet) |
-| DNLNet | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dnlnet) |
-| EMANet | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/emanet) |
-| EncNet | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/encnet) |
-| ERFNet | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/erfnet) |
-| FastFCN | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fastfcn) |
-| GCNet | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/gcnet) |
-| ICNet[*](#static_shape) | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/icnet) |
-| ISANet | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/isanet) |
-| NonLocal Net | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/nonlocal_net) |
-| OCRNet | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ocrnet) |
-| PointRend | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/point_rend) |
-| Semantic FPN | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/sem_fpn) |
-| STDC | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/stdc) |
-| UPerNet[*](#static_shape) | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/upernet) |
-| DANet | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/danet) |
-| Segmenter[*](#static_shape) | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/segmenter) |
-| SegFormer[*](#static_shape) | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/segformer) |
-| SETR | Y | N | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/setr) |
-| CCNet | N | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ccnet) |
-| PSANet | N | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/psanet) |
-| DPT | N | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dpt) |
+| Model | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVino | Model config |
+| :--------------------------- | :---------: | :------: | :--: | :---: | :------: | :--------------------------------------------------------------------------------------: |
+| FCN | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fcn) |
+| PSPNet[\*](#static_shape) | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/pspnet) |
+| DeepLabV3 | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3) |
+| DeepLabV3+ | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3plus) |
+| Fast-SCNN[\*](#static_shape) | Y | Y | N | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fastscnn) |
+| UNet | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/unet) |
+| ANN[\*](#static_shape) | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ann) |
+| APCNet | Y | Y | Y | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/apcnet) |
+| BiSeNetV1 | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/bisenetv1) |
+| BiSeNetV2 | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/bisenetv2) |
+| CGNet | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/cgnet) |
+| DMNet | Y | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dmnet) |
+| DNLNet | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dnlnet) |
+| EMANet | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/emanet) |
+| EncNet | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/encnet) |
+| ERFNet | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/erfnet) |
+| FastFCN | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fastfcn) |
+| GCNet | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/gcnet) |
+| ICNet[\*](#static_shape) | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/icnet) |
+| ISANet | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/isanet) |
+| NonLocal Net | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/nonlocal_net) |
+| OCRNet | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ocrnet) |
+| PointRend | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/point_rend) |
+| Semantic FPN | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/sem_fpn) |
+| STDC | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/stdc) |
+| UPerNet[\*](#static_shape) | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/upernet) |
+| DANet | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/danet) |
+| Segmenter[\*](#static_shape) | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/segmenter) |
+| SegFormer[\*](#static_shape) | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/segformer) |
+| SETR | Y | N | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/setr) |
+| CCNet | N | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ccnet) |
+| PSANet | N | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/psanet) |
+| DPT | N | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dpt) |
### Reminder
diff --git a/docs/en/faq.md b/docs/en/faq.md
index 14d621ea79..dec0174d3c 100644
--- a/docs/en/faq.md
+++ b/docs/en/faq.md
@@ -6,7 +6,7 @@
Fp16 mode requires a device with full-rate fp16 support.
-- "error: parameter check failed at: engine.cpp::setBindingDimensions::1046, condition: profileMinDims.d[i] <= dimensions.d[i]"
+- "error: parameter check failed at: engine.cpp::setBindingDimensions::1046, condition: profileMinDims.d\[i\] \<= dimensions.d\[i\]"
When building an `ICudaEngine` from an `INetworkDefinition` that has dynamically resizable inputs, users need to specify at least one optimization profile. Which can be set in deploy config:
@@ -25,33 +25,37 @@
The input tensor shape should be limited between `min_shape` and `max_shape`.
-- "error: [TensorRT] INTERNAL ERROR: Assertion failed: cublasStatus == CUBLAS_STATUS_SUCCESS"
+- "error: \[TensorRT\] INTERNAL ERROR: Assertion failed: cublasStatus == CUBLAS_STATUS_SUCCESS"
TRT 7.2.1 switches to use cuBLASLt (previously it was cuBLAS). cuBLASLt is the defaulted choice for SM version >= 7.0. You may need CUDA-10.2 Patch 1 (Released Aug 26, 2020) to resolve some cuBLASLt issues. Another option is to use the new TacticSource API and disable cuBLASLt tactics if you dont want to upgrade.
### Libtorch
+
- Error: `libtorch/share/cmake/Caffe2/Caffe2Config.cmake:96 (message):Your installed Caffe2 version uses cuDNN but I cannot find the cuDNN libraries. Please set the proper cuDNN prefixes and / or install cuDNN.`
May `export CUDNN_ROOT=/root/path/to/cudnn` to resolve the build error.
-
### Windows
+
- Error: similar like this `OSError: [WinError 1455] The paging file is too small for this operation to complete. Error loading "C:\Users\cx\miniconda3\lib\site-packages\torch\lib\cudnn_cnn_infer64_8.dll" or one of its dependencies`
Solution: according to this [post](https://stackoverflow.com/questions/64837376/how-to-efficiently-run-multiple-pytorch-processes-models-at-once-traceback), the issue may be caused by NVidia and will fix in *CUDA release 11.7*. For now one could use the [fixNvPe.py](https://gist.github.com/cobryan05/7d1fe28dd370e110a372c4d268dcb2e5) script to modify the nvidia dlls in the pytorch lib dir.
`python fixNvPe.py --input=C:\Users\user\AppData\Local\Programs\Python\Python38\lib\site-packages\torch\lib\*.dll`
- You can find your pytorch installation path with:
- ```python
- import torch
- print(torch.__file__)
- ```
+ You can find your pytorch installation path with:
+
+ ```python
+ import torch
+ print(torch.__file__)
+ ```
### Pip
+
- pip installed package but could not `import` them.
Make sure your are using conda pip.
+
```bash
$ which pip
# /path/to/.local/bin/pip
diff --git a/docs/en/get_started.md b/docs/en/get_started.md
index a151c2bb01..8179cf79ab 100644
--- a/docs/en/get_started.md
+++ b/docs/en/get_started.md
@@ -82,6 +82,7 @@ install
│ └── cpp
└── lib
```
+
where `include/c` and `include/cpp` correspond to C and C++ API respectively.
**Caution: The C++ API is highly volatile and not recommended at the moment.**
@@ -120,6 +121,7 @@ Download the checkpoint from this [link](https://download.openmmlab.com/mmdetect
#### Install MMDeploy and ONNX Runtime
Please run the following command in Anaconda environment to [install MMDeploy](./build.md).
+
```bash
conda activate openmmlab
@@ -130,11 +132,13 @@ pip install -e .
```
Once we have installed the MMDeploy, we should select an inference engine for model inference. Here we take ONNX Runtime as an example. Run the following command to [install ONNX Runtime](./backends/onnxruntime.md):
+
```bash
pip install onnxruntime==1.8.1
```
Then download the ONNX Runtime library to build the mmdeploy plugin for ONNX Runtime:
+
```bash
wget https://github.com/microsoft/onnxruntime/releases/download/v1.8.1/onnxruntime-linux-x64-1.8.1.tgz
@@ -186,6 +190,7 @@ If the script runs successfully, two images will display on the screen one by on
After model conversion, SDK Model is saved in directory ${work_dir}.
Here is a recipe for building & running object detection demo.
+
```Bash
cd build/install/example
@@ -204,14 +209,13 @@ export SPDLOG_LEVEL=warn
./object_detection cpu ${work_dirs} ${path/to/an/image}
```
+
If the demo runs successfully, an image named "output_detection.png" is supposed to be found showing detection objects.
### Add New Model Support?
If the models you want to deploy have not been supported yet in MMDeploy, you can try to support them by yourself. Here are some documents that may help you:
-- Read [how_to_support_new_models](./tutorials/how_to_support_new_models.md) to learn more about the rewriter.
-
-
+- Read [how_to_support_new_models](./tutorials/how_to_support_new_models.md) to learn more about the rewriter.
Finally, we welcome your PR!
diff --git a/docs/en/ops/ncnn.md b/docs/en/ops/ncnn.md
index e97f7287ae..749d6b5007 100644
--- a/docs/en/ops/ncnn.md
+++ b/docs/en/ops/ncnn.md
@@ -50,6 +50,7 @@ Expand has no parameters.
#### Outputs
+
- outputs[0]: T
- top_blob; The blob of ncnn.Mat which expanded by given shape and broadcast rule of ncnn.
@@ -67,9 +68,9 @@ Given the data and indice blob, gather entries of the axis dimension of data ind
#### Parameters
-| Type | Parameter | Description |
-| ------- | --------------------- | --------------------------------------------------------------------------------------------------------------------------------------- |
-| `int` | `axis` | Which axis to gather on. Default is 0.
+| Type | Parameter | Description |
+| ----- | --------- | -------------------------------------- |
+| `int` | `axis` | Which axis to gather on. Default is 0. |
#### Inputs
@@ -81,6 +82,7 @@ Given the data and indice blob, gather entries of the axis dimension of data ind
#### Outputs
+
- outputs[0]: T
- top_blob; The blob of ncnn.Mat which gathered by given data and indice blob.
@@ -108,6 +110,7 @@ Shape has no parameters.
#### Outputs
+
- outputs[0]: T
- top_blob; 1-D ncnn.Mat of shape (bottom_blob.dims,), `bottom_blob.dims` is the input blob dimensions.
@@ -126,7 +129,7 @@ Get the indices and value(optional) of largest or smallest k data among the axis
#### Parameters
| Type | Parameter | Description |
-|-------|-------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| ----- | ----------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `int` | `axis` | The axis of data which topk calculate on. Default is -1, indicates the last dimension. |
| `int` | `largest` | The binary value which indicates the TopK operator selects the largest or smallest K values. Default is 1, the TopK selects the largest K values. |
| `int` | `sorted` | The binary value of whether returning sorted topk value or not. If not, the topk returns topk values in any order. Default is 1, this operator returns sorted topk values. |
@@ -142,6 +145,7 @@ Get the indices and value(optional) of largest or smallest k data among the axis
#### Outputs
+
- outputs[0]: T
- top_blob[0]; If outputs has only 1 blob, outputs[0] is the indice blob of topk, if outputs has 2 blobs, outputs[0] is the value blob of topk. This blob is ncnn.Mat format with the shape of bottom_blob[0] or reduced shape of bottom_blob[0].
diff --git a/docs/en/ops/tensorrt.md b/docs/en/ops/tensorrt.md
index 6a06db314e..55a0e207dc 100644
--- a/docs/en/ops/tensorrt.md
+++ b/docs/en/ops/tensorrt.md
@@ -77,6 +77,7 @@ Batched NMS with a fixed number of output bounding boxes.
#### Outputs
+
- outputs[0]: T
- dets; 3-D tensor of shape (N, valid_num_boxes, 5), `valid_num_boxes` is the number of boxes after NMS. For each row `dets[i,j,:] = [x0, y0, x1, y1, score]`
@@ -158,7 +159,6 @@ y = scale * (x - mean) / sqrt(variance + epsilon) + B, where mean and variance a
- T:tensor(float32, Linear)
-
### MMCVModulatedDeformConv2d
#### Description
@@ -278,7 +278,7 @@ Perform RoIAlign on output feature, used in bbox_head of most two-stage detector
#### Description
-ScatterND takes three inputs `data` tensor of rank r >= 1, `indices` tensor of rank q >= 1, and `updates` tensor of rank q + r - indices.shape[-1] - 1. The output of the operation is produced by creating a copy of the input `data`, and then updating its value to values specified by updates at specific index positions specified by `indices`. Its output shape is the same as the shape of `data`. Note that `indices` should not have duplicate entries. That is, two or more updates for the same index-location is not supported.
+ScatterND takes three inputs `data` tensor of rank r >= 1, `indices` tensor of rank q >= 1, and `updates` tensor of rank q + r - indices.shape\[-1\] - 1. The output of the operation is produced by creating a copy of the input `data`, and then updating its value to values specified by updates at specific index positions specified by `indices`. Its output shape is the same as the shape of `data`. Note that `indices` should not have duplicate entries. That is, two or more updates for the same index-location is not supported.
The `output` is calculated via the following equation:
diff --git a/docs/en/supported_models.md b/docs/en/supported_models.md
index 06982b829c..e274fc8e3b 100644
--- a/docs/en/supported_models.md
+++ b/docs/en/supported_models.md
@@ -2,70 +2,70 @@
The table below lists the models that are guaranteed to be exportable to other backends.
-| Model | Codebase | TorchScript | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
-| :------------------------ | :--------------- | :---------: | :---------: | :------: | :---: | :---: | :------: | :--------------------------------------------------------------------------------------------: |
-| RetinaNet | MMDetection | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/retinanet) |
-| Faster R-CNN | MMDetection | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/faster_rcnn) |
-| YOLOv3 | MMDetection | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolo) |
-| YOLOX | MMDetection | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolox) |
-| FCOS | MMDetection | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fcos) |
-| FSAF | MMDetection | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fsaf) |
-| Mask R-CNN | MMDetection | Y | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn) |
-| SSD[*](#note) | MMDetection | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ssd) |
-| FoveaBox | MMDetection | Y | Y | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/foveabox) |
-| ATSS | MMDetection | N | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/atss) |
-| GFL | MMDetection | N | Y | Y | N | ? | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/gfl) |
-| Cascade R-CNN | MMDetection | N | Y | Y | N | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn) |
-| Cascade Mask R-CNN | MMDetection | N | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn) |
-| VFNet | MMDetection | N | N | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/vfnet) |
-| ResNet | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/resnet) |
-| ResNeXt | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/resnext) |
-| SE-ResNet | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/seresnet) |
-| MobileNetV2 | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/mobilenet_v2) |
-| ShuffleNetV1 | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/shufflenet_v1) |
-| ShuffleNetV2 | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/shufflenet_v2) |
-| FCN | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fcn) |
-| PSPNet[*static](#note) | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/pspnet) |
-| DeepLabV3 | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3) |
-| DeepLabV3+ | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3plus) |
-| Fast-SCNN[*static](#note) | MMSegmentation | Y | Y | Y | N | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fastscnn) |
-| UNet | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/unet) |
-| ANN[*](#note) | MMSegmentation | ? | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ann) |
-| APCNet | MMSegmentation | ? | Y | Y | Y | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/apcnet) |
-| BiSeNetV1 | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/bisenetv1) |
-| BiSeNetV2 | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/bisenetv2) |
-| CGNet | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/cgnet) |
-| DMNet | MMSegmentation | ? | Y | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dmnet) |
-| DNLNet | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dnlnet) |
-| EMANet | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/emanet) |
-| EncNet | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/encnet) |
-| ERFNet | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/erfnet) |
-| FastFCN | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fastfcn) |
-| GCNet | MMSegmentation | ? | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/gcnet) |
-| ICNet[*](#note) | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/icnet) |
-| ISANet | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/isanet) |
-| NonLocal Net | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/nonlocal_net) |
-| OCRNet | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ocrnet) |
-| PointRend | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/point_rend) |
-| Semantic FPN | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/sem_fpn) |
-| STDC | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/stdc) |
-| UPerNet[*](#note) | MMSegmentation | ? | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/upernet) |
-| DANet | MMSegmentation | ? | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/danet) |
-| SRCNN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srcnn) |
-| ESRGAN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/esrgan) |
-| SRGAN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srresnet_srgan) |
-| SRResNet | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srresnet_srgan) |
-| Real-ESRGAN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/real_esrgan) |
-| EDSR | MMEditing | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/edsr) |
-| RDN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/rdn) |
-| DBNet | MMOCR | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/dbnet) |
-| CRNN | MMOCR | Y | Y | Y | Y | Y | N | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/crnn) |
-| SAR | MMOCR | N | Y | N | N | N | N | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/sar) |
-| HRNet | MMPose | N | Y | Y | Y | N | Y | [config](https://mmpose.readthedocs.io/en/latest/papers/backbones.html#hrnet-cvpr-2019) |
-| MSPN | MMPose | N | Y | Y | Y | N | Y | [config](https://mmpose.readthedocs.io/en/latest/papers/backbones.html#mspn-arxiv-2019) |
-| LiteHRNet | MMPose | N | Y | Y | N | N | Y | [config](https://mmpose.readthedocs.io/en/latest/papers/backbones.html#litehrnet-cvpr-2021) |
-| PointPillars | MMDetection3d | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection3d/blob/master/configs/pointpillars) |
-| CenterPoint (pillar) | MMDetection3d | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection3d/blob/master/configs/centerpoint) |
+| Model | Codebase | TorchScript | OnnxRuntime | TensorRT | NCNN | PPLNN | OpenVINO | Model config |
+| :------------------------- | :--------------- | :---------: | :---------: | :------: | :--: | :---: | :------: | :--------------------------------------------------------------------------------------------: |
+| RetinaNet | MMDetection | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/retinanet) |
+| Faster R-CNN | MMDetection | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/faster_rcnn) |
+| YOLOv3 | MMDetection | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolo) |
+| YOLOX | MMDetection | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolox) |
+| FCOS | MMDetection | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fcos) |
+| FSAF | MMDetection | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fsaf) |
+| Mask R-CNN | MMDetection | Y | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn) |
+| SSD[\*](#note) | MMDetection | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ssd) |
+| FoveaBox | MMDetection | Y | Y | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/foveabox) |
+| ATSS | MMDetection | N | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/atss) |
+| GFL | MMDetection | N | Y | Y | N | ? | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/gfl) |
+| Cascade R-CNN | MMDetection | N | Y | Y | N | Y | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn) |
+| Cascade Mask R-CNN | MMDetection | N | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn) |
+| VFNet | MMDetection | N | N | N | N | N | Y | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/vfnet) |
+| ResNet | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/resnet) |
+| ResNeXt | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/resnext) |
+| SE-ResNet | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/seresnet) |
+| MobileNetV2 | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/mobilenet_v2) |
+| ShuffleNetV1 | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/shufflenet_v1) |
+| ShuffleNetV2 | MMClassification | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmclassification/tree/master/configs/shufflenet_v2) |
+| FCN | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fcn) |
+| PSPNet[\*static](#note) | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/pspnet) |
+| DeepLabV3 | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3) |
+| DeepLabV3+ | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3plus) |
+| Fast-SCNN[\*static](#note) | MMSegmentation | Y | Y | Y | N | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fastscnn) |
+| UNet | MMSegmentation | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/unet) |
+| ANN[\*](#note) | MMSegmentation | ? | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ann) |
+| APCNet | MMSegmentation | ? | Y | Y | Y | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/apcnet) |
+| BiSeNetV1 | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/bisenetv1) |
+| BiSeNetV2 | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/bisenetv2) |
+| CGNet | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/cgnet) |
+| DMNet | MMSegmentation | ? | Y | N | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dmnet) |
+| DNLNet | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dnlnet) |
+| EMANet | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/emanet) |
+| EncNet | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/encnet) |
+| ERFNet | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/erfnet) |
+| FastFCN | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/fastfcn) |
+| GCNet | MMSegmentation | ? | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/gcnet) |
+| ICNet[\*](#note) | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/icnet) |
+| ISANet | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/isanet) |
+| NonLocal Net | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/nonlocal_net) |
+| OCRNet | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/ocrnet) |
+| PointRend | MMSegmentation | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/point_rend) |
+| Semantic FPN | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/sem_fpn) |
+| STDC | MMSegmentation | ? | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/stdc) |
+| UPerNet[\*](#note) | MMSegmentation | ? | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/upernet) |
+| DANet | MMSegmentation | ? | Y | Y | N | N | N | [config](https://github.com/open-mmlab/mmsegmentation/tree/master/configs/danet) |
+| SRCNN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srcnn) |
+| ESRGAN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/esrgan) |
+| SRGAN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srresnet_srgan) |
+| SRResNet | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/srresnet_srgan) |
+| Real-ESRGAN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/real_esrgan) |
+| EDSR | MMEditing | Y | Y | Y | Y | N | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/edsr) |
+| RDN | MMEditing | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmediting/tree/master/configs/restorers/rdn) |
+| DBNet | MMOCR | Y | Y | Y | Y | Y | Y | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/dbnet) |
+| CRNN | MMOCR | Y | Y | Y | Y | Y | N | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/crnn) |
+| SAR | MMOCR | N | Y | N | N | N | N | [config](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/sar) |
+| HRNet | MMPose | N | Y | Y | Y | N | Y | [config](https://mmpose.readthedocs.io/en/latest/papers/backbones.html#hrnet-cvpr-2019) |
+| MSPN | MMPose | N | Y | Y | Y | N | Y | [config](https://mmpose.readthedocs.io/en/latest/papers/backbones.html#mspn-arxiv-2019) |
+| LiteHRNet | MMPose | N | Y | Y | N | N | Y | [config](https://mmpose.readthedocs.io/en/latest/papers/backbones.html#litehrnet-cvpr-2021) |
+| PointPillars | MMDetection3d | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection3d/blob/master/configs/pointpillars) |
+| CenterPoint (pillar) | MMDetection3d | ? | Y | Y | N | N | Y | [config](https://github.com/open-mmlab/mmdetection3d/blob/master/configs/centerpoint) |
### Note
diff --git a/docs/en/tutorials/how_to_evaluate_a_model.md b/docs/en/tutorials/how_to_evaluate_a_model.md
index 83f67b6fd2..f16f8cc553 100644
--- a/docs/en/tutorials/how_to_evaluate_a_model.md
+++ b/docs/en/tutorials/how_to_evaluate_a_model.md
@@ -27,20 +27,20 @@ ${MODEL_CFG} \
## Description of all arguments
-* `deploy_cfg`: The config for deployment.
-* `model_cfg`: The config of the model in OpenMMLab codebases.
-* `--model`: The backend model file. For example, if we convert a model to TensorRT, we need to pass the model file with ".engine" suffix.
-* `--out`: The path to save output results in pickle format. (The results will be saved only if this argument is given)
-* `--format-only`: Whether format the output results without evaluation or not. It is useful when you want to format the result to a specific format and submit it to the test server
-* `--metrics`: The metrics to evaluate the model defined in OpenMMLab codebases. e.g. "segm", "proposal" for COCO in mmdet, "precision", "recall", "f1_score", "support" for single label dataset in mmcls.
-* `--show`: Whether to show the evaluation result on the screen.
-* `--show-dir`: The directory to save the evaluation result. (The results will be saved only if this argument is given)
-* `--show-score-thr`: The threshold determining whether to show detection bounding boxes.
-* `--device`: The device that the model runs on. Note that some backends restrict the device. For example, TensorRT must run on cuda.
-* `--cfg-options`: Extra or overridden settings that will be merged into the current deploy config.
-* `--metric-options`: Custom options for evaluation. The key-value pair in xxx=yyy
-format will be kwargs for dataset.evaluate() function.
-* `--log2file`: log evaluation results (and speed) to file.
+- `deploy_cfg`: The config for deployment.
+- `model_cfg`: The config of the model in OpenMMLab codebases.
+- `--model`: The backend model file. For example, if we convert a model to TensorRT, we need to pass the model file with ".engine" suffix.
+- `--out`: The path to save output results in pickle format. (The results will be saved only if this argument is given)
+- `--format-only`: Whether format the output results without evaluation or not. It is useful when you want to format the result to a specific format and submit it to the test server
+- `--metrics`: The metrics to evaluate the model defined in OpenMMLab codebases. e.g. "segm", "proposal" for COCO in mmdet, "precision", "recall", "f1_score", "support" for single label dataset in mmcls.
+- `--show`: Whether to show the evaluation result on the screen.
+- `--show-dir`: The directory to save the evaluation result. (The results will be saved only if this argument is given)
+- `--show-score-thr`: The threshold determining whether to show detection bounding boxes.
+- `--device`: The device that the model runs on. Note that some backends restrict the device. For example, TensorRT must run on cuda.
+- `--cfg-options`: Extra or overridden settings that will be merged into the current deploy config.
+- `--metric-options`: Custom options for evaluation. The key-value pair in xxx=yyy
+ format will be kwargs for dataset.evaluate() function.
+- `--log2file`: log evaluation results (and speed) to file.
\* Other arguments in `tools/test.py` are used for speed test. They have no concern with evaluation.
@@ -57,4 +57,4 @@ python tools/test.py \
## Note
-* The performance of each model in [OpenMMLab](https://openmmlab.com/) codebases can be found in the document of each codebase.
+- The performance of each model in [OpenMMLab](https://openmmlab.com/) codebases can be found in the document of each codebase.
diff --git a/docs/en/tutorials/how_to_install_mmdeploy_on_jetsons.md b/docs/en/tutorials/how_to_install_mmdeploy_on_jetsons.md
index b36a81ed18..72d5ee5e2a 100644
--- a/docs/en/tutorials/how_to_install_mmdeploy_on_jetsons.md
+++ b/docs/en/tutorials/how_to_install_mmdeploy_on_jetsons.md
@@ -24,6 +24,7 @@ JetPack SDK provides a full development environment for hardware-accelerated AI-
All Jetson modules and developer kits are supported by JetPack SDK.
There are two major installation methods including,
+
1. SD Card Image Method
2. NVIDIA SDK Manager Method
diff --git a/docs/en/tutorials/how_to_measure_performance_of_models.md b/docs/en/tutorials/how_to_measure_performance_of_models.md
index 380bcb6a05..bebb3be5ab 100644
--- a/docs/en/tutorials/how_to_measure_performance_of_models.md
+++ b/docs/en/tutorials/how_to_measure_performance_of_models.md
@@ -21,13 +21,13 @@ ${MODEL_CFG} \
## Description of all arguments
-* `deploy_cfg`: The config for deployment.
-* `model_cfg`: The config of the model in OpenMMLab codebases.
-* `--model`: The backend model files. For example, if we convert a model to ncnn, we need to pass a ".param" file and a ".bin" file. If we convert a model to TensorRT, we need to pass the model file with ".engine" suffix.
-* `--log2file`: log evaluation results and speed to file.
-* `--speed-test`: Whether to activate speed test.
-* `--warmup`: warmup before counting inference elapse, require setting speed-test first.
-* `--log-interval`: The interval between each log, require setting speed-test first.
+- `deploy_cfg`: The config for deployment.
+- `model_cfg`: The config of the model in OpenMMLab codebases.
+- `--model`: The backend model files. For example, if we convert a model to ncnn, we need to pass a ".param" file and a ".bin" file. If we convert a model to TensorRT, we need to pass the model file with ".engine" suffix.
+- `--log2file`: log evaluation results and speed to file.
+- `--speed-test`: Whether to activate speed test.
+- `--warmup`: warmup before counting inference elapse, require setting speed-test first.
+- `--log-interval`: The interval between each log, require setting speed-test first.
\* Other arguments in `tools/test.py` are used for performance test. They have no concern with speed test.
diff --git a/docs/en/tutorials/how_to_support_new_backends.md b/docs/en/tutorials/how_to_support_new_backends.md
index c18cd86148..710fc960a2 100644
--- a/docs/en/tutorials/how_to_support_new_backends.md
+++ b/docs/en/tutorials/how_to_support_new_backends.md
@@ -6,9 +6,9 @@ MMDeploy supports a number of backend engines. We welcome the contribution of ne
Before contributing the codes, there are some requirements for the new backend that need to be checked:
-* The backend must support ONNX as IR.
-* If the backend requires model files or weight files other than a ".onnx" file, a conversion tool that converts the ".onnx" file to model files and weight files is required. The tool can be a Python API, a script, or an executable program.
-* It is highly recommended that the backend provides a Python interface to load the backend files and inference for validation.
+- The backend must support ONNX as IR.
+- If the backend requires model files or weight files other than a ".onnx" file, a conversion tool that converts the ".onnx" file to model files and weight files is required. The tool can be a Python API, a script, or an executable program.
+- It is highly recommended that the backend provides a Python interface to load the backend files and inference for validation.
### Support backend conversion
@@ -16,140 +16,140 @@ The backends in MMDeploy must support the ONNX. The backend loads the ".onnx" fi
1. Add backend constant in `mmdeploy/utils/constants.py` that denotes the name of the backend.
- **Example**:
+ **Example**:
- ```Python
- # mmdeploy/utils/constants.py
+ ```Python
+ # mmdeploy/utils/constants.py
- class Backend(AdvancedEnum):
- # Take TensorRT as an example
- TENSORRT = 'tensorrt'
- ```
+ class Backend(AdvancedEnum):
+ # Take TensorRT as an example
+ TENSORRT = 'tensorrt'
+ ```
2. Add a corresponding package (a folder with `__init__.py`) in `mmdeploy/backend/`. For example, `mmdeploy/backend/tensorrt`. In the `__init__.py`, there must be a function named `is_available` which checks if users have installed the backend library. If the check is passed, then the remaining files of the package will be loaded.
- **Example**:
+ **Example**:
- ```Python
- # mmdeploy/backend/tensorrt/__init__.py
+ ```Python
+ # mmdeploy/backend/tensorrt/__init__.py
- def is_available():
- return importlib.util.find_spec('tensorrt') is not None
+ def is_available():
+ return importlib.util.find_spec('tensorrt') is not None
- if is_available():
- from .utils import create_trt_engine, load_trt_engine, save_trt_engine
- from .wrapper import TRTWrapper
+ if is_available():
+ from .utils import create_trt_engine, load_trt_engine, save_trt_engine
+ from .wrapper import TRTWrapper
- __all__ = [
- 'create_trt_engine', 'save_trt_engine', 'load_trt_engine', 'TRTWrapper'
- ]
- ```
+ __all__ = [
+ 'create_trt_engine', 'save_trt_engine', 'load_trt_engine', 'TRTWrapper'
+ ]
+ ```
3. Create a config file in `configs/_base_/backends` (e.g., `configs/_base_/backends/tensorrt.py`). If the backend just takes the '.onnx' file as input, the new config can be simple. The config of the backend only consists of one field denoting the name of the backend (which should be same as the name in `mmdeploy/utils/constants.py`).
- **Example**:
+ **Example**:
- ```python
- backend_config = dict(type='onnxruntime')
- ```
+ ```python
+ backend_config = dict(type='onnxruntime')
+ ```
- If the backend requires other files, then the arguments for the conversion from ".onnx" file to backend files should be included in the config file.
+ If the backend requires other files, then the arguments for the conversion from ".onnx" file to backend files should be included in the config file.
- **Example:**
+ **Example:**
- ```Python
+ ```Python
- backend_config = dict(
- type='tensorrt',
- common_config=dict(
- fp16_mode=False, max_workspace_size=0))
- ```
+ backend_config = dict(
+ type='tensorrt',
+ common_config=dict(
+ fp16_mode=False, max_workspace_size=0))
+ ```
- After possessing a base backend config file, you can easily construct a complete deploy config through inheritance. Please refer to our [config tutorial](how_to_write_config.md) for more details. Here is an example:
+ After possessing a base backend config file, you can easily construct a complete deploy config through inheritance. Please refer to our [config tutorial](how_to_write_config.md) for more details. Here is an example:
- ```Python
- _base_ = ['../_base_/backends/onnxruntime.py']
+ ```Python
+ _base_ = ['../_base_/backends/onnxruntime.py']
- codebase_config = dict(type='mmcls', task='Classification')
- onnx_config = dict(input_shape=None)
- ```
+ codebase_config = dict(type='mmcls', task='Classification')
+ onnx_config = dict(input_shape=None)
+ ```
4. If the backend requires model files or weight files other than a ".onnx" file, create a `onnx2backend.py` file in the corresponding folder (e.g., create `mmdeploy/backend/tensorrt/onnx2tensorrt.py`). Then add a conversion function `onnx2backend` in the file. The function should convert a given ".onnx" file to the required backend files in a given work directory. There are no requirements on other parameters of the function and the implementation details. You can use any tools for conversion. Here are some examples:
- **Use Python script:**
+ **Use Python script:**
- ```Python
- def onnx2openvino(input_info: Dict[str, Union[List[int], torch.Size]],
- output_names: List[str], onnx_path: str, work_dir: str):
+ ```Python
+ def onnx2openvino(input_info: Dict[str, Union[List[int], torch.Size]],
+ output_names: List[str], onnx_path: str, work_dir: str):
- input_names = ','.join(input_info.keys())
- input_shapes = ','.join(str(list(elem)) for elem in input_info.values())
- output = ','.join(output_names)
+ input_names = ','.join(input_info.keys())
+ input_shapes = ','.join(str(list(elem)) for elem in input_info.values())
+ output = ','.join(output_names)
- mo_args = f'--input_model="{onnx_path}" '\
- f'--output_dir="{work_dir}" ' \
- f'--output="{output}" ' \
- f'--input="{input_names}" ' \
- f'--input_shape="{input_shapes}" ' \
- f'--disable_fusing '
- command = f'mo.py {mo_args}'
- mo_output = run(command, stdout=PIPE, stderr=PIPE, shell=True, check=True)
- ```
+ mo_args = f'--input_model="{onnx_path}" '\
+ f'--output_dir="{work_dir}" ' \
+ f'--output="{output}" ' \
+ f'--input="{input_names}" ' \
+ f'--input_shape="{input_shapes}" ' \
+ f'--disable_fusing '
+ command = f'mo.py {mo_args}'
+ mo_output = run(command, stdout=PIPE, stderr=PIPE, shell=True, check=True)
+ ```
- **Use executable program:**
+ **Use executable program:**
- ```Python
- def onnx2ncnn(onnx_path: str, work_dir: str):
- onnx2ncnn_path = get_onnx2ncnn_path()
- save_param, save_bin = get_output_model_file(onnx_path, work_dir)
- call([onnx2ncnn_path, onnx_path, save_param, save_bin])\
- ```
+ ```Python
+ def onnx2ncnn(onnx_path: str, work_dir: str):
+ onnx2ncnn_path = get_onnx2ncnn_path()
+ save_param, save_bin = get_output_model_file(onnx_path, work_dir)
+ call([onnx2ncnn_path, onnx_path, save_param, save_bin])\
+ ```
5. Define APIs in a new package in `mmdeploy/apis`.
- **Example:**
+ **Example:**
- ```Python
- # mmdeploy/apis/ncnn/__init__.py
+ ```Python
+ # mmdeploy/apis/ncnn/__init__.py
- from mmdeploy.backend.ncnn import is_available
+ from mmdeploy.backend.ncnn import is_available
- __all__ = ['is_available']
+ __all__ = ['is_available']
- if is_available():
- from mmdeploy.backend.ncnn.onnx2ncnn import (onnx2ncnn,
- get_output_model_file)
- __all__ += ['onnx2ncnn', 'get_output_model_file']
- ```
+ if is_available():
+ from mmdeploy.backend.ncnn.onnx2ncnn import (onnx2ncnn,
+ get_output_model_file)
+ __all__ += ['onnx2ncnn', 'get_output_model_file']
+ ```
- Then add the codes about conversion to `tools/deploy.py` using these APIs if necessary.
+ Then add the codes about conversion to `tools/deploy.py` using these APIs if necessary.
- **Example:**
+ **Example:**
- ```Python
- # tools/deploy.py
- # ...
- elif backend == Backend.NCNN:
- from mmdeploy.apis.ncnn import is_available as is_available_ncnn
+ ```Python
+ # tools/deploy.py
+ # ...
+ elif backend == Backend.NCNN:
+ from mmdeploy.apis.ncnn import is_available as is_available_ncnn
- if not is_available_ncnn():
- logging.error('ncnn support is not available.')
- exit(-1)
+ if not is_available_ncnn():
+ logging.error('ncnn support is not available.')
+ exit(-1)
- from mmdeploy.apis.ncnn import onnx2ncnn, get_output_model_file
+ from mmdeploy.apis.ncnn import onnx2ncnn, get_output_model_file
- backend_files = []
- for onnx_path in onnx_files:
- create_process(
- f'onnx2ncnn with {onnx_path}',
- target=onnx2ncnn,
- args=(onnx_path, args.work_dir),
- kwargs=dict(),
- ret_value=ret_value)
- backend_files += get_output_model_file(onnx_path, args.work_dir)
- # ...
- ```
+ backend_files = []
+ for onnx_path in onnx_files:
+ create_process(
+ f'onnx2ncnn with {onnx_path}',
+ target=onnx2ncnn,
+ args=(onnx_path, args.work_dir),
+ kwargs=dict(),
+ ret_value=ret_value)
+ backend_files += get_output_model_file(onnx_path, args.work_dir)
+ # ...
+ ```
6. Convert the models of OpenMMLab to backends (if necessary) and inference on backend engine. If you find some incompatible operators when testing, you can try to rewrite the original model for the backend following the [rewriter tutorial](how_to_support_new_models.md) or add custom operators.
@@ -161,71 +161,71 @@ Although the backend engines are usually implemented in C/C++, it is convenient
1. Add a file named `wrapper.py` to corresponding folder in `mmdeploy/backend/{backend}`. For example, `mmdeploy/backend/tensorrt/wrapper.py`. This module should implement and register a wrapper class that inherits the base class `BaseWrapper` in `mmdeploy/backend/base/base_wrapper.py`.
- **Example:**
+ **Example:**
- ```Python
- from mmdeploy.utils import Backend
- from ..base import BACKEND_WRAPPER, BaseWrapper
+ ```Python
+ from mmdeploy.utils import Backend
+ from ..base import BACKEND_WRAPPER, BaseWrapper
- @BACKEND_WRAPPER.register_module(Backend.TENSORRT.value)
- class TRTWrapper(BaseWrapper):
- ```
+ @BACKEND_WRAPPER.register_module(Backend.TENSORRT.value)
+ class TRTWrapper(BaseWrapper):
+ ```
2. The wrapper class can initialize the engine in `__init__` function and inference in `forward` function. Note that the `__init__` function must take a parameter `output_names` and pass it to base class to determine the orders of output tensors. The input and output variables of `forward` should be dictionaries denoting the name and value of the tensors.
3. For the convenience of performance testing, the class should define a "execute" function that only calls the inference interface of the backend engine. The `forward` function should call the "execute" function after preprocessing the data.
- **Example:**
+ **Example:**
- ```Python
- from mmdeploy.utils import Backend
- from mmdeploy.utils.timer import TimeCounter
- from ..base import BACKEND_WRAPPER, BaseWrapper
+ ```Python
+ from mmdeploy.utils import Backend
+ from mmdeploy.utils.timer import TimeCounter
+ from ..base import BACKEND_WRAPPER, BaseWrapper
- @BACKEND_WRAPPER.register_module(Backend.ONNXRUNTIME.value)
- class ORTWrapper(BaseWrapper):
+ @BACKEND_WRAPPER.register_module(Backend.ONNXRUNTIME.value)
+ class ORTWrapper(BaseWrapper):
- def __init__(self,
- onnx_file: str,
- device: str,
- output_names: Optional[Sequence[str]] = None):
- # Initialization
- # ...
- super().__init__(output_names)
+ def __init__(self,
+ onnx_file: str,
+ device: str,
+ output_names: Optional[Sequence[str]] = None):
+ # Initialization
+ # ...
+ super().__init__(output_names)
- def forward(self, inputs: Dict[str,
- torch.Tensor]) -> Dict[str, torch.Tensor]:
- # Fetch data
- # ...
+ def forward(self, inputs: Dict[str,
+ torch.Tensor]) -> Dict[str, torch.Tensor]:
+ # Fetch data
+ # ...
- self.__ort_execute(self.io_binding)
+ self.__ort_execute(self.io_binding)
- # Postprocess data
- # ...
+ # Postprocess data
+ # ...
- @TimeCounter.count_time()
- def __ort_execute(self, io_binding: ort.IOBinding):
- # Only do the inference
- self.sess.run_with_iobinding(io_binding)
- ```
+ @TimeCounter.count_time()
+ def __ort_execute(self, io_binding: ort.IOBinding):
+ # Only do the inference
+ self.sess.run_with_iobinding(io_binding)
+ ```
4. Add a default initialization method for the new wrapper in `mmdeploy/codebase/base/backend_model.py`
- **Example:**
-
- ```Python
- @staticmethod
- def _build_wrapper(backend: Backend,
- backend_files: Sequence[str],
- device: str,
- input_names: Optional[Sequence[str]] = None,
- output_names: Optional[Sequence[str]] = None):
- if backend == Backend.ONNXRUNTIME:
- from mmdeploy.backend.onnxruntime import ORTWrapper
- return ORTWrapper(
- onnx_file=backend_files[0],
- device=device,
- output_names=output_names)
- ```
+ **Example:**
+
+ ```Python
+ @staticmethod
+ def _build_wrapper(backend: Backend,
+ backend_files: Sequence[str],
+ device: str,
+ input_names: Optional[Sequence[str]] = None,
+ output_names: Optional[Sequence[str]] = None):
+ if backend == Backend.ONNXRUNTIME:
+ from mmdeploy.backend.onnxruntime import ORTWrapper
+ return ORTWrapper(
+ onnx_file=backend_files[0],
+ device=device,
+ output_names=output_names)
+ ```
5. Add docstring and unit tests for new code :).
diff --git a/docs/en/tutorials/how_to_test_rewritten_models.md b/docs/en/tutorials/how_to_test_rewritten_models.md
index 9f7f172885..a5fdf7f997 100644
--- a/docs/en/tutorials/how_to_test_rewritten_models.md
+++ b/docs/en/tutorials/how_to_test_rewritten_models.md
@@ -53,7 +53,7 @@ def test_baseclassfier_forward():
assert backend_output == 'simple_test'
```
- In this test function, we construct a derived class of `BaseClassifier` to test if the rewritten model would work in the rewrite context. We get outputs of the original model by directly calling `model(input)` and get the outputs of the rewritten model by calling `model(input)` in `RewriteContext`. Finally, we can check the outputs by asserting their value.
+In this test function, we construct a derived class of `BaseClassifier` to test if the rewritten model would work in the rewrite context. We get outputs of the original model by directly calling `model(input)` and get the outputs of the rewritten model by calling `model(input)` in `RewriteContext`. Finally, we can check the outputs by asserting their value.
## Test rewritten model with big changes
diff --git a/docs/en/tutorials/how_to_use_docker.md b/docs/en/tutorials/how_to_use_docker.md
index 1918cca439..e3743bf196 100644
--- a/docs/en/tutorials/how_to_use_docker.md
+++ b/docs/en/tutorials/how_to_use_docker.md
@@ -5,23 +5,28 @@ We provide two dockerfiles for CPU and GPU respectively. For CPU users, we insta
### Build docker image
For CPU users, we can build the docker image with the latest MMDeploy through:
+
```
cd mmdeploy
docker build docker/CPU/ -t mmdeploy:master-cpu
```
+
For GPU users, we can build the docker image with the latest MMDeploy through:
+
```
cd mmdeploy
docker build docker/GPU/ -t mmdeploy:master-gpu
```
For installing MMDeploy with a specific version, we can append `--build-arg VERSION=${VERSION}` to build command. GPU for example:
+
```
cd mmdeploy
docker build docker/GPU/ -t mmdeploy:0.1.0 --build-arg VERSION=0.1.0
```
For installing libs with the aliyun source, we can append `--build-arg USE_SRC_INSIDE=${USE_SRC_INSIDE}` to build command.
+
```
# GPU for example
cd mmdeploy
@@ -35,6 +40,7 @@ docker build docker/CPU/ -t mmdeploy:inside --build-arg USE_SRC_INSIDE=true
### Run docker container
After building the docker image succeed, we can use `docker run` to launch the docker service. GPU docker image for example:
+
```
docker run --gpus all -it -p 8080:8081 mmdeploy:master-gpu
```
@@ -43,14 +49,16 @@ docker run --gpus all -it -p 8080:8081 mmdeploy:master-gpu
1. CUDA error: the provided PTX was compiled with an unsupported toolchain:
- As described [here](https://forums.developer.nvidia.com/t/cuda-error-the-provided-ptx-was-compiled-with-an-unsupported-toolchain/185754), update the GPU driver to the latest one for your GPU.
-2. docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
- ```
- # Add the package repositories
- distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
- curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
- curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
-
- sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
- sudo systemctl restart docker
- ```
+ As described [here](https://forums.developer.nvidia.com/t/cuda-error-the-provided-ptx-was-compiled-with-an-unsupported-toolchain/185754), update the GPU driver to the latest one for your GPU.
+
+2. docker: Error response from daemon: could not select device driver "" with capabilities: \[\[gpu\]\].
+
+ ```
+ # Add the package repositories
+ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
+ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
+ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
+
+ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
+ sudo systemctl restart docker
+ ```
diff --git a/docs/en/useful_tools.md b/docs/en/useful_tools.md
index a1e05d6525..896a892637 100644
--- a/docs/en/useful_tools.md
+++ b/docs/en/useful_tools.md
@@ -81,7 +81,7 @@ python tools/onnx2pplnn.py \
- `onnx_path`: The path of the `ONNX` model to convert.
- `output_path`: The converted `PPLNN` algorithm path in json format.
- `device`: The device of the model during conversion.
-- `opt-shapes`: Optimal shapes for PPLNN optimization. The shape of each tensor should be wrap with "[]" or "()" and the shapes of tensors should be separated by ",".
+- `opt-shapes`: Optimal shapes for PPLNN optimization. The shape of each tensor should be wrap with "\[\]" or "()" and the shapes of tensors should be separated by ",".
- `--log-level`: To set log level which in `'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'`. If not specified, it will be set to `INFO`.
## onnx2tensorrt
diff --git a/docs/zh_cn/benchmark.md b/docs/zh_cn/benchmark.md
index 2a96884ac7..c63e5bb3d5 100644
--- a/docs/zh_cn/benchmark.md
+++ b/docs/zh_cn/benchmark.md
@@ -678,7 +678,6 @@ GPU: ncnn, TensorRT, PPLNN
用户可以直接通过[如何测试性能](tutorials/how_to_evaluate_a_model.md)获得想要的性能测试结果。下面是我们环境中的测试结果:
-
MMCls
diff --git a/docs/zh_cn/build.md b/docs/zh_cn/build.md
index 5a3c9edaa9..9886e90d7d 100644
--- a/docs/zh_cn/build.md
+++ b/docs/zh_cn/build.md
@@ -1,29 +1,28 @@
## 安装 MMdeploy
-
### 下载代码仓库 MMDeploy
- ```bash
- git clone -b master git@github.com:open-mmlab/mmdeploy.git MMDeploy
- cd MMDeploy
- git submodule update --init --recursive
- ```
+```bash
+git clone -b master git@github.com:open-mmlab/mmdeploy.git MMDeploy
+cd MMDeploy
+git submodule update --init --recursive
+```
- 提示:
+提示:
- 如果由于网络等原因导致拉取仓库子模块失败,可以尝试通过如下指令手动再次安装子模块:
- ```bash
- git clone git@github.com:NVIDIA/cub.git third_party/cub
- cd third_party/cub
- git checkout c3cceac115
-
- # 返回至 third_party 目录, 克隆 pybind11
- cd ..
- git clone git@github.com:pybind/pybind11.git pybind11
- cd pybind11
- git checkout 70a58c5
- ```
+ ```bash
+ git clone git@github.com:NVIDIA/cub.git third_party/cub
+ cd third_party/cub
+ git checkout c3cceac115
+
+ # 返回至 third_party 目录, 克隆 pybind11
+ cd ..
+ git clone git@github.com:pybind/pybind11.git pybind11
+ cd pybind11
+ git checkout 70a58c5
+ ```
- 如果以 `SSH` 方式 `git clone` 代码失败,您可以尝试使用 `HTTPS` 协议下载代码:
@@ -32,9 +31,12 @@
cd MMDeploy
git submodule update --init --recursive
```
+
### 编译 MMDeploy
+
根据您的目标平台,点击如下对应的链接,按照说明编译 MMDeploy
+
- [Linux-x86_64](build/linux.md)
- [Windows](build/windows.md)
- [Android-aarch64](build/android.md)
-- [NVIDIA Jetson](../en/tutorials/how_to_install_mmdeploy_on_jetsons.md)
+- [NVIDIA Jetson](https://mmdeploy.readthedocs.io/en/latest/tutorials/how_to_install_mmdeploy_on_jetsons.html)
diff --git a/docs/zh_cn/build/android.md b/docs/zh_cn/build/android.md
index 7c7a9f31fa..a156bbb774 100644
--- a/docs/zh_cn/build/android.md
+++ b/docs/zh_cn/build/android.md
@@ -1,16 +1,17 @@
# Android 下构建方式
-- [Android 下构建方式](#android-下构建方式)
- - [源码安装](#源码安装)
- - [安装构建和编译工具链](#安装构建和编译工具链)
- - [安装依赖包](#安装依赖包)
- - [安装 MMDeploy SDK 依赖](#安装-mmdeploy-sdk-依赖)
- - [编译 MMDeploy](#编译-mmdeploy)
- - [编译选项说明](#编译选项说明)
- - [编译 SDK](#编译-sdk)
- - [编译 Demo](#编译-demo)
-
----
+- [Android 下构建方式](#android-%E4%B8%8B%E6%9E%84%E5%BB%BA%E6%96%B9%E5%BC%8F)
+ - [源码安装](#%E6%BA%90%E7%A0%81%E5%AE%89%E8%A3%85)
+ - [安装构建和编译工具链](#%E5%AE%89%E8%A3%85%E6%9E%84%E5%BB%BA%E5%92%8C%E7%BC%96%E8%AF%91%E5%B7%A5%E5%85%B7%E9%93%BE)
+ - [安装依赖包](#%E5%AE%89%E8%A3%85%E4%BE%9D%E8%B5%96%E5%8C%85)
+ - [安装 MMDeploy SDK 依赖](#%E5%AE%89%E8%A3%85-mmdeploy-sdk-%E4%BE%9D%E8%B5%96)
+ - [编译 MMDeploy](#%E7%BC%96%E8%AF%91-mmdeploy)
+ - [编译选项说明](#%E7%BC%96%E8%AF%91%E9%80%89%E9%A1%B9%E8%AF%B4%E6%98%8E)
+ - [编译 SDK](#%E7%BC%96%E8%AF%91-sdk)
+ - [编译 Demo](#%E7%BC%96%E8%AF%91-demo)
+
+______________________________________________________________________
+
MMDeploy 为 android 平台提供交叉编译的构建方式.
MMDeploy converter 部分在 linux 平台上执行,SDK 部分在 android 平台上执行.
@@ -29,30 +30,31 @@ MMDeploy 的交叉编译分为两步:
- cmake
- **保证 cmake的版本 >= 3.14.0**. 如果不是,可以参考以下命令安装 3.20.0 版本. 如要获取其他版本,请参考 [这里](https://cmake.org/install)
+ **保证 cmake的版本 >= 3.14.0**. 如果不是,可以参考以下命令安装 3.20.0 版本. 如要获取其他版本,请参考 [这里](https://cmake.org/install)
- ```bash
- wget https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0-linux-x86_64.tar.gz
- tar -xzvf cmake-3.20.0-linux-x86_64.tar.gz
- sudo ln -sf $(pwd)/cmake-3.20.0-linux-x86_64/bin/* /usr/bin/
- ```
+ ```bash
+ wget https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0-linux-x86_64.tar.gz
+ tar -xzvf cmake-3.20.0-linux-x86_64.tar.gz
+ sudo ln -sf $(pwd)/cmake-3.20.0-linux-x86_64/bin/* /usr/bin/
+ ```
- ANDROID NDK 19+
- **保证 android ndk 的版本 >= 19.0**. 如果不是,可以参考以下命令安装 r23b 版本. 如要获取其他版本,请参考 [这里](https://developer.android.com/ndk/downloads)
+ **保证 android ndk 的版本 >= 19.0**. 如果不是,可以参考以下命令安装 r23b 版本. 如要获取其他版本,请参考 [这里](https://developer.android.com/ndk/downloads)
- ```bash
- wget https://dl.google.com/android/repository/android-ndk-r23b-linux.zip
- unzip android-ndk-r23b-linux.zip
- cd android-ndk-r23b
- export NDK_PATH=${PWD}
- ```
+ ```bash
+ wget https://dl.google.com/android/repository/android-ndk-r23b-linux.zip
+ unzip android-ndk-r23b-linux.zip
+ cd android-ndk-r23b
+ export NDK_PATH=${PWD}
+ ```
### 安装依赖包
#### 安装 MMDeploy SDK 依赖
如果您只对模型转换感兴趣,那么可以跳过本章节.
+
@@ -86,7 +88,7 @@ export OPENCV_ANDROID_SDK_DIR=${PWD}/OpenCV-android-sdk
-
+
| ncnn |
ncnn 是支持 android 平台的高效神经网络推理计算框架
@@ -107,7 +109,9 @@ make install
|
### 编译 MMDeploy
+
#### 编译选项说明
+
diff --git a/docs/zh_cn/build/linux.md b/docs/zh_cn/build/linux.md
index 627b0d75a3..a6b96e9e3b 100644
--- a/docs/zh_cn/build/linux.md
+++ b/docs/zh_cn/build/linux.md
@@ -1,24 +1,27 @@
# Linux-x86_64 下构建方式
-- [Linux-x86_64 下构建方式](#linux-x86_64-下构建方式)
- - [Dockerfile 方式 (推荐)](#dockerfile-方式-推荐)
- - [源码安装](#源码安装)
- - [安装构建和编译工具链](#安装构建和编译工具链)
- - [安装依赖包](#安装依赖包)
- - [安装 MMDeploy Converter 依赖](#安装-mmdeploy-converter-依赖)
- - [安装 MMDeploy SDK 依赖](#安装-mmdeploy-sdk-依赖)
- - [安装推理引擎](#安装推理引擎)
- - [编译 MMDeploy](#编译-mmdeploy)
- - [编译选项说明](#编译选项说明)
- - [编译安装 Model Converter](#编译安装-model-converter)
- - [编译自定义算子](#编译自定义算子)
- - [安装 Model Converter](#安装-model-converter)
- - [编译SDK](#编译sdk)
- - [编译 Demo](#编译-demo)
----
+- [Linux-x86_64 下构建方式](#linux-x86_64-%E4%B8%8B%E6%9E%84%E5%BB%BA%E6%96%B9%E5%BC%8F)
+ - [Dockerfile 方式 (推荐)](#dockerfile-%E6%96%B9%E5%BC%8F-%E6%8E%A8%E8%8D%90)
+ - [源码安装](#%E6%BA%90%E7%A0%81%E5%AE%89%E8%A3%85)
+ - [安装构建和编译工具链](#%E5%AE%89%E8%A3%85%E6%9E%84%E5%BB%BA%E5%92%8C%E7%BC%96%E8%AF%91%E5%B7%A5%E5%85%B7%E9%93%BE)
+ - [安装依赖包](#%E5%AE%89%E8%A3%85%E4%BE%9D%E8%B5%96%E5%8C%85)
+ - [安装 MMDeploy Converter 依赖](#%E5%AE%89%E8%A3%85-mmdeploy-converter-%E4%BE%9D%E8%B5%96)
+ - [安装 MMDeploy SDK 依赖](#%E5%AE%89%E8%A3%85-mmdeploy-sdk-%E4%BE%9D%E8%B5%96)
+ - [安装推理引擎](#%E5%AE%89%E8%A3%85%E6%8E%A8%E7%90%86%E5%BC%95%E6%93%8E)
+ - [编译 MMDeploy](#%E7%BC%96%E8%AF%91-mmdeploy)
+ - [编译选项说明](#%E7%BC%96%E8%AF%91%E9%80%89%E9%A1%B9%E8%AF%B4%E6%98%8E)
+ - [编译安装 Model Converter](#%E7%BC%96%E8%AF%91%E5%AE%89%E8%A3%85-model-converter)
+ - [编译自定义算子](#%E7%BC%96%E8%AF%91%E8%87%AA%E5%AE%9A%E4%B9%89%E7%AE%97%E5%AD%90)
+ - [安装 Model Converter](#%E5%AE%89%E8%A3%85-model-converter)
+ - [编译SDK](#%E7%BC%96%E8%AF%91sdk)
+ - [编译 Demo](#%E7%BC%96%E8%AF%91-demo)
+
+______________________________________________________________________
+
MMDeploy 为 Linux-x86_64 平台提供 2 种编译安装方式,分别是 Dockerfile 方式和源码方式
## Dockerfile 方式 (推荐)
+
请参考[how to use docker](../tutorials/how_to_use_docker.md)
## 源码安装
@@ -27,27 +30,29 @@ MMDeploy 为 Linux-x86_64 平台提供 2 种编译安装方式,分别是 Docke
- cmake
- **保证 cmake的版本 >= 3.14.0**。如果不是,可以参考以下命令安装 3.20.0 版本。如需获取其他版本,请参考[这里](https://cmake.org/install)。
+ **保证 cmake的版本 >= 3.14.0**。如果不是,可以参考以下命令安装 3.20.0 版本。如需获取其他版本,请参考[这里](https://cmake.org/install)。
- ```bash
- wget https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0-linux-x86_64.tar.gz
- tar -xzvf cmake-3.20.0-linux-x86_64.tar.gz
- sudo ln -sf $(pwd)/cmake-3.20.0-linux-x86_64/bin/* /usr/bin/
- ```
+ ```bash
+ wget https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0-linux-x86_64.tar.gz
+ tar -xzvf cmake-3.20.0-linux-x86_64.tar.gz
+ sudo ln -sf $(pwd)/cmake-3.20.0-linux-x86_64/bin/* /usr/bin/
+ ```
- GCC 7+
- MMDeploy SDK 使用了 C++17 特性,因此需要安装gcc 7+以上的版本。
- ```bash
- # 如果 Ubuntu 版本 < 18.04,需要加入仓库
- sudo add-apt-repository ppa:ubuntu-toolchain-r/test
- sudo apt-get update
- sudo apt-get install gcc-7
- sudo apt-get install g++-7
- ```
+ MMDeploy SDK 使用了 C++17 特性,因此需要安装gcc 7+以上的版本。
+
+ ```bash
+ # 如果 Ubuntu 版本 < 18.04,需要加入仓库
+ sudo add-apt-repository ppa:ubuntu-toolchain-r/test
+ sudo apt-get update
+ sudo apt-get install gcc-7
+ sudo apt-get install g++-7
+ ```
### 安装依赖包
-#### 安装 MMDeploy Converter 依赖
+
+#### 安装 MMDeploy Converter 依赖
@@ -90,6 +95,7 @@ pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/${cu_ve
#### 安装 MMDeploy SDK 依赖
如果您只对模型转换感兴趣,那么可以跳过本章节。
+
@@ -123,7 +129,7 @@ sudo apt-get install libopencv-dev
在 Ubuntu 16.04 中,需要源码安装 OpenCV。您可以参考此处.
-
+
| pplcv |
pplcv 是 openPPL 开发的高性能图像处理库。 此依赖项为可选项,只有在 cuda 平台下,才需安装。而且,目前必须使用 v0.6.2,且需要使用 git clone 的方式下载源码并编译安装
@@ -256,12 +262,14 @@ export LD_LIBRARY_PATH=$Torch_DIR/lib:$LD_LIBRARY_PATH
注意:
如果您想使上述环境变量永久有效,可以把它们加入~/.bashrc。以 ONNXRuntime 的环境变量为例,
+
```bash
echo '# set env for onnxruntime' >> ~/.bashrc
echo "export ONNXRUNTIME_DIR=${ONNXRUNTIME_DIR}" >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=$ONNXRUNTIME_DIR/lib:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
```
+
### 编译 MMDeploy
```bash
@@ -270,6 +278,7 @@ export MMDEPLOY_DIR=$(pwd)
```
#### 编译选项说明
+
@@ -346,6 +355,7 @@ export MMDEPLOY_DIR=$(pwd)
#### 编译安装 Model Converter
##### 编译自定义算子
+
如果您选择了ONNXRuntime,TensorRT,ncnn 和 torchscript 任一种推理后端,您需要编译对应的自定义算子库。
- **ONNXRuntime** 自定义算子
@@ -390,15 +400,18 @@ export MMDEPLOY_DIR=$(pwd)
cd ${MMDEPLOY_DIR}
pip install -e .
```
+
**注意**
- 有些依赖项是可选的。运行 `pip install -e .` 将进行最小化依赖安装。 如果需安装其他可选依赖项,请执行`pip install -r requirements/optional.txt`,
-或者 `pip install -e .[optional]`。其中,`[optional]`可以替换为:`all`、`tests`、`build` 或 `optional`。
+ 或者 `pip install -e .[optional]`。其中,`[optional]`可以替换为:`all`、`tests`、`build` 或 `optional`。
+
#### 编译SDK
下文展示2个构建SDK的样例,分别用 ONNXRuntime 和 TensorRT 作为推理引擎。您可以参考它们,激活其他的推理引擎。
- cpu + ONNXRuntime
+
```Bash
cd ${MMDEPLOY_DIR}
mkdir -p build && cd build
@@ -415,6 +428,7 @@ pip install -e .
```
- cuda + TensorRT
+
```Bash
cd ${MMDEPLOY_DIR}
mkdir -p build && cd build
diff --git a/docs/zh_cn/build/windows.md b/docs/zh_cn/build/windows.md
index 406f3300f7..3be4d5199b 100644
--- a/docs/zh_cn/build/windows.md
+++ b/docs/zh_cn/build/windows.md
@@ -1,33 +1,39 @@
# Windows 下构建方式
-- [Windows 下构建方式](#windows-下构建方式)
- - [源码安装](#源码安装)
- - [安装构建和编译工具链](#安装构建和编译工具链)
- - [安装依赖包](#安装依赖包)
- - [安装 MMDeploy Converter 依赖](#安装-mmdeploy-converter-依赖)
- - [安装 MMDeploy SDK 依赖](#安装-mmdeploy-sdk-依赖)
- - [安装推理引擎](#安装推理引擎)
- - [编译 MMDeploy](#编译-mmdeploy)
- - [编译选项说明](#编译选项说明)
- - [编译安装 Model Converter](#编译安装-model-converter)
- - [编译自定义算子](#编译自定义算子)
- - [安装 Model Converter](#安装-model-converter)
- - [编译 SDK](#编译-sdk)
- - [编译 Demo](#编译-demo)
- - [注意事项](#注意事项)
----
+- [Windows 下构建方式](#windows-%E4%B8%8B%E6%9E%84%E5%BB%BA%E6%96%B9%E5%BC%8F)
+ - [源码安装](#%E6%BA%90%E7%A0%81%E5%AE%89%E8%A3%85)
+ - [安装构建和编译工具链](#%E5%AE%89%E8%A3%85%E6%9E%84%E5%BB%BA%E5%92%8C%E7%BC%96%E8%AF%91%E5%B7%A5%E5%85%B7%E9%93%BE)
+ - [安装依赖包](#%E5%AE%89%E8%A3%85%E4%BE%9D%E8%B5%96%E5%8C%85)
+ - [安装 MMDeploy Converter 依赖](#%E5%AE%89%E8%A3%85-mmdeploy-converter-%E4%BE%9D%E8%B5%96)
+ - [安装 MMDeploy SDK 依赖](#%E5%AE%89%E8%A3%85-mmdeploy-sdk-%E4%BE%9D%E8%B5%96)
+ - [安装推理引擎](#%E5%AE%89%E8%A3%85%E6%8E%A8%E7%90%86%E5%BC%95%E6%93%8E)
+ - [编译 MMDeploy](#%E7%BC%96%E8%AF%91-mmdeploy)
+ - [编译选项说明](#%E7%BC%96%E8%AF%91%E9%80%89%E9%A1%B9%E8%AF%B4%E6%98%8E)
+ - [编译安装 Model Converter](#%E7%BC%96%E8%AF%91%E5%AE%89%E8%A3%85-model-converter)
+ - [编译自定义算子](#%E7%BC%96%E8%AF%91%E8%87%AA%E5%AE%9A%E4%B9%89%E7%AE%97%E5%AD%90)
+ - [安装 Model Converter](#%E5%AE%89%E8%A3%85-model-converter)
+ - [编译 SDK](#%E7%BC%96%E8%AF%91-sdk)
+ - [编译 Demo](#%E7%BC%96%E8%AF%91-demo)
+ - [注意事项](#%E6%B3%A8%E6%84%8F%E4%BA%8B%E9%A1%B9)
+
+______________________________________________________________________
+
目前,MMDeploy 在 Windows 平台下仅提供源码编译安装方式。未来会提供预编译包方式。
## 源码安装
+
下述安装方式,均是在 **Windows 10** 下进行
### 安装构建和编译工具链
+
1. 下载并安装 [Visual Studio 2019](https://visualstudio.microsoft.com) 。安装时请勾选 "使用C++的桌面开发, "Windows 10 SDK
-2. 把 cmake 路径加入到环境变量 PATH 中, "C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\Common7\IDE\CommonExtensions\Microsoft\CMake\CMake\bin"
-3. 如果系统中配置了 NVIDIA 显卡,根据[官网教程](https://developer.nvidia.com\/cuda-downloads),下载并安装 cuda toolkit。
+2. 把 cmake 路径加入到环境变量 PATH 中, "C:\\Program Files (x86)\\Microsoft Visual Studio\\2019\\Community\\Common7\\IDE\\CommonExtensions\\Microsoft\\CMake\\CMake\\bin"
+3. 如果系统中配置了 NVIDIA 显卡,根据[官网教程](https://developer.nvidia.com/cuda-downloads),下载并安装 cuda toolkit。
### 安装依赖包
+
#### 安装 MMDeploy Converter 依赖
+
@@ -65,9 +71,10 @@ pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/$env:cu
-
#### 安装 MMDeploy SDK 依赖
+
如果您只对模型转换感兴趣,那么可以跳过本章节。
+
@@ -121,9 +128,11 @@ cd ../..
#### 安装推理引擎
+
MMDeploy 的 Model Converter 和 SDK 共享推理引擎。您可以参考下文,选择自己感兴趣的推理引擎安装。
**目前,在 Windows 平台下,MMDeploy 支持 ONNXRuntime 和 TensorRT 两种推理引擎**。其他推理引擎尚未进行验证,或者验证未通过。后续将陆续予以支持
+
@@ -195,12 +204,14 @@ $env:path = "$env:CUDNN_DIR\bin;" + $env:path
### 编译 MMDeploy
+
```powershell
cd \the\root\path\of\MMDeploy
$env:MMDEPLOY_DIR="$pwd"
```
#### 编译选项说明
+
@@ -268,11 +279,14 @@ $env:MMDEPLOY_DIR="$pwd"
-
#### 编译安装 Model Converter
+
##### 编译自定义算子
+
如果您选择了ONNXRuntime,TensorRT 和 ncnn 任一种推理后端,您需要编译对应的自定义算子库。
+
- **ONNXRuntime** 自定义算子
+
```powershell
mkdir build -ErrorAction SilentlyContinue
cd build
@@ -294,13 +308,17 @@ cmake --build . --config Release -- /m
TODO
##### 安装 Model Converter
+
```powershell
cd $env:MMDEPLOY_DIR
pip install -e .
```
+
**注意**
+
- 有些依赖项是可选的。运行 `pip install -e .` 将进行最小化依赖安装。 如果需安装其他可选依赖项,请执行`pip install -r requirements/optional.txt`,
或者 `pip install -e .[optional]`。其中,`[optional]`可以替换为:`all`、`tests`、`build` 或 `optional`。
+
#### 编译 SDK
下文展示2个构建SDK的样例,分别用 ONNXRuntime 和 TensorRT 作为推理引擎。您可以参考它们,并结合前文 SDK 的编译选项说明,激活其他的推理引擎。
@@ -356,4 +374,5 @@ $env:path = "$env:MMDEPLOY_DIR/build/install/bin;" + $env:path
```
### 注意事项
- 1. Release / Debug 库不能混用。MMDeploy 要是编译 Release 版本,所有第三方依赖都要是 Release 版本。反之亦然。
+
+1. Release / Debug 库不能混用。MMDeploy 要是编译 Release 版本,所有第三方依赖都要是 Release 版本。反之亦然。
diff --git a/docs/zh_cn/get_started.md b/docs/zh_cn/get_started.md
index 78ac292a2e..21021acc18 100644
--- a/docs/zh_cn/get_started.md
+++ b/docs/zh_cn/get_started.md
@@ -210,6 +210,7 @@ export SPDLOG_LEVEL=warn
### 新模型的支持?
如果您希望使用的模型尚未被 MMDeploy 所支持,您可以尝试自己添加对应的支持。我们准备了如下的文档:
+
- 请阅读[如何支持新模型](https://mmdeploy.readthedocs.io/en/latest/tutorials/how_to_support_new_models.html)了解我们的模型重写机制。
最后,欢迎大家踊跃提PR。
diff --git a/docs/zh_cn/tutorials/chapter_01_introduction_to_model_deployment.md b/docs/zh_cn/tutorials/chapter_01_introduction_to_model_deployment.md
index 999867e01e..d09ff7fb77 100644
--- a/docs/zh_cn/tutorials/chapter_01_introduction_to_model_deployment.md
+++ b/docs/zh_cn/tutorials/chapter_01_introduction_to_model_deployment.md
@@ -16,10 +16,12 @@ OpenMMLab 的算法如何部署?这是很多社区用户的困惑。而[模型
在第一篇文章中,我们将部署一个简单的超分辨率模型,认识中间表示、推理引擎等模型部署中的概念。
## 初识模型部署
+
在软件工程中,部署指把开发完毕的软件投入使用的过程,包括环境配置、软件安装等步骤。类似地,对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。相比于软件部署,模型部署会面临更多的难题:
+
1. 运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
2. 深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
-因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线:
+ 因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线:

@@ -32,8 +34,10 @@ OpenMMLab 的算法如何部署?这是很多社区用户的困惑。而[模型
## 部署第一个模型
### 创建 PyTorch 模型
+
仿照 PyTorch 的官方[部署教程](https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html),让我们用 PyTorch 实现一个超分辨率模型,并把模型部署到 ONNX Runtime 这个推理引擎上。
首先,我们需要创建一个有 PyTorch 库的 Python 编程环境。如果你的 PyTorch 环境还没有装好,可以参考官方的[入门教程](https://pytorch.org/get-started/locally/)。我们强烈推荐使用 conda 来管理 Python 库。使用 conda 可以靠如下的命令初始化一个 PyTorch 环境:
+
```bash
# 创建预安装 Python 3.7 的名叫 deploy 虚拟环境
conda create -n deploy python=3.7 -y
@@ -44,18 +48,22 @@ conda install pytorch torchvision cpuonly -c pytorch
```
如果你的设备支持 cuda 编程,我们建议你在配置 cuda 环境后使用 gpu 上的 PyTorch。比如将上面安装 PyTorch 的命令改成:
+
```bash
# 安装 cuda 11.3 的 PyTorch
# 如果你用的是其他版本的 cuda,请参考上面 PyTorch 的官方安装教程选择安装命令
conda install pytorch torchvision cudatoolkit=11.3 -c pytorch
```
+
本教程会用到其他一些第三方库。你可以用以下命令来安装这些库:
+
```bash
# 安装 ONNX Runtime, ONNX, OpenCV
pip install onnxruntime onnx opencv-python
```
在一切都配置完毕后,用下面的代码来创建一个超分辨率模型。
+
```python
import os
@@ -128,6 +136,7 @@ torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
# Show image
cv2.imwrite("face_torch.png", torch_output)
```
+
在这份代码中,我们创建了一个经典的超分辨率网络 [SRCNN](https://arxiv.org/abs/1501.00092)。SRCNN 先把图像上采样到对应分辨率,再用 3 个卷积层处理图像。为了方便起见,我们跳过训练网络的步骤,直接下载模型权重(由于 MMEditing 中 SRCNN 的权重结构和我们定义的模型不太一样,我们修改了权重字典的 key 来适配我们定义的模型),同时下载好输入图片。为了让模型输出成正确的图片格式,我们把模型的输出转换成 HWC 格式,并保证每一通道的颜色值都在 0~255 之间。如果脚本正常运行的话,一幅超分辨率的人脸照片会保存在“face_torch.png”中。
在 PyTorch 模型测试正确后,我们来正式开始部署这个模型。我们下一步的任务是把 PyTorch 模型转换成用中间表示 ONNX 描述的模型。
@@ -147,6 +156,7 @@ cv2.imwrite("face_torch.png", torch_output)
ONNX (Open Neural Network Exchange)是 Facebook 和微软在2017年共同发布的,用于标准描述计算图的一种格式。目前,在数家机构的共同维护下,ONNX 已经对接了多种深度学习框架和多种推理引擎。因此,ONNX 被当成了深度学习框架到推理引擎的桥梁,就像编译器的中间语言一样。由于各框架兼容性不一,我们通常只用 ONNX 表示更容易部署的静态图。
让我们用下面的代码来把 PyTorch 的模型转换成 ONNX 格式的模型:
+
```python
x = torch.randn(1, 3, 256, 256)
@@ -165,6 +175,7 @@ with torch.no_grad():
剩下的参数中,opset_version 表示 ONNX 算子集的版本。深度学习的发展会不断诞生新算子,为了支持这些新增的算子,ONNX会经常发布新的算子集,目前已经更新15个版本。 我们令 opset_version = 11,即使用第11个 ONNX 算子集,是因为 SRCNN 中的 bicubic (双三次插值)在 opset11 中才得到支持。剩下的两个参数 input_names, output_names 是输入、输出 tensor 的名称,我们稍后会用到这些名称。
如果上述代码运行成功,目录下会新增一个"srcnn.onnx"的 ONNX 模型文件。我们可以用下面的脚本来验证一下模型文件是否正确。
+
```python
import onnx
@@ -182,7 +193,6 @@ else:

-
点击 input 或者 output,可以查看 ONNX 模型的基本信息,包括模型的版本信息,以及模型输入、输出的名称和数据类型。

@@ -190,8 +200,8 @@ else:
点击某一个算子节点,可以看到算子的具体信息。比如点击第一个 Conv 可以看到:

-
每个算子记录了算子属性、图结构、权重三类信息。
+
- 算子属性信息即图中 attributes 里的信息,对于卷积来说,算子属性包括了卷积核大小(kernel_shape)、卷积步长(strides)等内容。这些算子属性最终会用来生成一个具体的算子。
- 图结构信息指算子节点在计算图中的名称、邻边的信息。对于图中的卷积来说,该算子节点叫做 Conv_2,输入数据叫做 11,输出数据叫做 12。根据每个算子节点的图结构信息,就能完整地复原出网络的计算图。
- 权重信息指的是网络经过训练后,算子存储的权重信息。对于卷积来说,权重信息包括卷积核的权重值和卷积后的偏差值。点击图中 conv1.weight, conv1.bias 后面的加号即可看到权重信息的具体内容。
@@ -199,6 +209,7 @@ else:
现在,我们有了 SRCNN 的 ONNX 模型。让我们看看最后该如何把这个模型运行起来。
### 推理引擎——ONNX Runtime
+
**ONNX Runtime** 是由微软维护的一个跨平台机器学习推理加速器,也就是我们前面提到的”推理引擎“。ONNX Runtime 是直接对接 ONNX 的,即 ONNX Runtime 可以直接读取并运行 .onnx 文件, 而不需要再把 .onnx 格式的文件转换成其他格式的文件。也就是说,对于 PyTorch - ONNX - ONNX Runtime 这条部署流水线,只要在目标设备中得到 .onnx 文件,并在 ONNX Runtime 上运行模型,模型部署就算大功告成了。
通过刚刚的操作,我们把 PyTorch 编写的模型转换成了 ONNX 模型,并通过可视化检查了模型的正确性。最后,让我们用 ONNX Runtime 运行一下模型,完成模型部署的最后一步。
@@ -223,9 +234,11 @@ cv2.imwrite("face_ort.png", ort_output)
如果代码正常运行的话,另一幅超分辨率照片会保存在"face_ort.png"中。这幅图片和刚刚得到的"face_torch.png"是一模一样的。这说明 ONNX Runtime 成功运行了 SRCNN 模型,模型部署完成了!以后有用户想实现超分辨率的操作,我们只需要提供一个 "srcnn.onnx" 文件,并帮助用户配置好 ONNX Runtime 的 Python 环境,用几行代码就可以运行模型了。或者还有更简便的方法,我们可以利用 ONNX Runtime 编译出一个可以直接执行模型的应用程序。我们只需要给用户提供 ONNX 模型文件,并让用户在应用程序选择要执行的 ONNX 模型文件名就可以运行模型了。
## 总结
+
在这篇教程里,我们利用成熟的模型部署工具,轻松部署了一个初始版本的超分辨率模型 SRCNN。但在实际应用场景中,随着模型结构的复杂度不断加深,碰到的困难的也会越来越多。在下一篇教程里,我们将“升级”一下这个超分辨率模型,让它支持动态的输入。
看完这篇教程,是不是感觉知识太多一下消化不过来?没关系,模型部署本身有非常多的东西要学。为了举例的方便,这篇教程包含了许多未来才会讲到的知识点。事实上,读完这篇教程后,记下以下知识点就够了:
+
- 模型部署,指把训练好的模型在特定环境中运行的过程。模型部署要解决模型框架兼容性差和模型运行速度慢这两大问题。
- 模型部署的常见流水线是“深度学习框架-中间表示-推理引擎”。其中比较常用的一个中间表示是 ONNX。
- 深度学习模型实际上就是一个计算图。模型部署时通常把模型转换成静态的计算图,即没有控制流(分支语句、循环语句)的计算图。
diff --git a/docs/zh_cn/tutorials/chapter_02_challenges.md b/docs/zh_cn/tutorials/chapter_02_challenges.md
index 5e45bd7d91..cb5fb1111a 100644
--- a/docs/zh_cn/tutorials/chapter_02_challenges.md
+++ b/docs/zh_cn/tutorials/chapter_02_challenges.md
@@ -1,11 +1,11 @@
# 第二章:解决模型部署中的难题
-
在[第一章](https://mmdeploy.readthedocs.io/zh_CN/latest/tutorials/chapter_01_introduction_to_model_deployment.html)中,我们部署了一个简单的超分辨率模型,一切都十分顺利。但是,上一个模型还有一些缺陷——图片的放大倍数固定是 4,我们无法让图片放大任意的倍数。现在,我们来尝试部署一个支持动态放大倍数的模型,体验一下在模型部署中可能会碰到的困难。
## 模型部署中常见的难题
在之前的学习中,我们在模型部署上顺风顺水,没有碰到任何问题。这是因为 SRCNN 模型只包含几个简单的算子,而这些卷积、插值算子已经在各个中间表示和推理引擎上得到了完美支持。如果模型的操作稍微复杂一点,我们可能就要为兼容模型而付出大量的功夫了。实际上,模型部署时一般会碰到以下几类困难:
+
- 模型的动态化。出于性能的考虑,各推理框架都默认模型的输入形状、输出形状、结构是静态的。而为了让模型的泛用性更强,部署时需要在尽可能不影响原有逻辑的前提下,让模型的输入输出或是结构动态化。
- 新算子的实现。深度学习技术日新月异,提出新算子的速度往往快于 ONNX 维护者支持的速度。为了部署最新的模型,部署工程师往往需要自己在 ONNX 和推理引擎中支持新算子。
- 中间表示与推理引擎的兼容问题。由于各推理引擎的实现不同,对 ONNX 难以形成统一的支持。为了确保模型在不同的推理引擎中有同样的运行效果,部署工程师往往得为某个推理引擎定制模型代码,这为模型部署引入了许多工作量。
@@ -17,6 +17,7 @@
## 问题:实现动态放大的超分辨率模型
在原来的 SRCNN 中,图片的放大比例是写死在模型里的:
+
```python
class SuperResolutionNet(nn.Module):
def __init__(self, upscale_factor):
@@ -32,6 +33,7 @@ class SuperResolutionNet(nn.Module):
def init_torch_model():
torch_model = SuperResolutionNet(upscale_factor=3)
```
+
我们使用 upscale_factor 来控制模型的放大比例。初始化模型的时候,我们默认令 upscale_factor 为 3,生成了一个放大 3 倍的 PyTorch 模型。这个 PyTorch 模型最终被转换成了 ONNX 格式的模型。如果我们需要一个放大 4 倍的模型,需要重新生成一遍模型,再做一次到 ONNX 的转换。
现在,假设我们要做一个超分辨率的应用。我们的用户希望图片的放大倍数能够自由设置。而我们交给用户的,只有一个 .onnx 文件和运行超分辨率模型的应用程序。我们在不修改 .onnx 文件的前提下改变放大倍数。
@@ -171,7 +173,7 @@ with torch.no_grad():
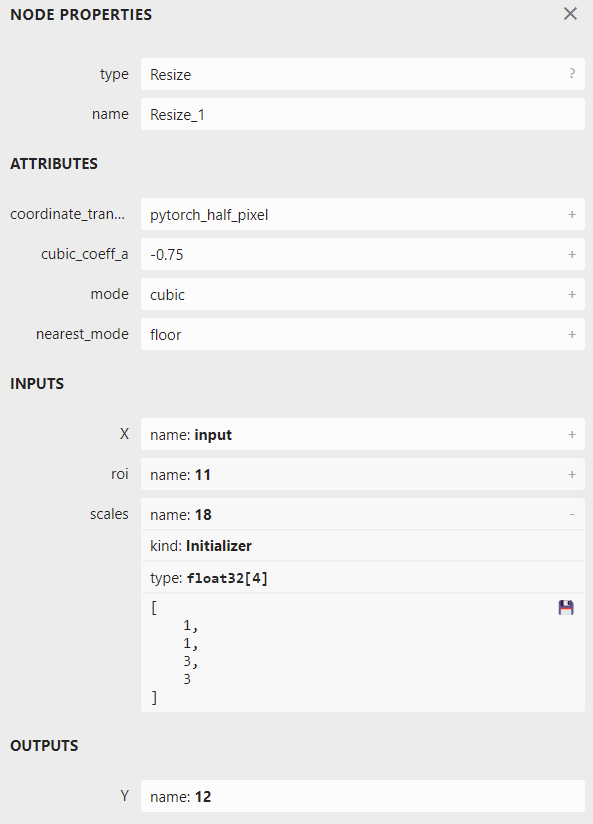
-其中,展开 scales,可以看到 scales 是一个长度为 4 的一维张量,其内容为 [1, 1, 3, 3], 表示 Resize 操作每一个维度的缩放系数;其类型为 Initializer,表示这个值是根据常量直接初始化出来的。如果我们能够自己生成一个 ONNX 的 Resize 算子,让 scales 成为一个可变量而不是常量,就像它上面的 X 一样,那这个超分辨率模型就能动态缩放了。
+其中,展开 scales,可以看到 scales 是一个长度为 4 的一维张量,其内容为 \[1, 1, 3, 3\], 表示 Resize 操作每一个维度的缩放系数;其类型为 Initializer,表示这个值是根据常量直接初始化出来的。如果我们能够自己生成一个 ONNX 的 Resize 算子,让 scales 成为一个可变量而不是常量,就像它上面的 X 一样,那这个超分辨率模型就能动态缩放了。
现有实现插值的 PyTorch 算子有一套规定好的映射到 ONNX Resize 算子的方法,这些映射出的 Resize 算子的 scales 只能是常量,无法满足我们的需求。我们得自己定义一个实现插值的 PyTorch 算子,然后让它映射到一个我们期望的 ONNX Resize 算子上。
@@ -292,9 +294,9 @@ class NewInterpolate(torch.autograd.Function):
align_corners=False)
```
-在具体介绍这个算子的实现前,让我们先理清一下思路。我们希望新的插值算子有两个输入,一个是被用于操作的图像,一个是图像的放缩比例。前面讲到,为了对接 ONNX 中 Resize 算子的 scales 参数,这个放缩比例是一个 [1, 1, x, x] 的张量,其中 x 为放大倍数。在之前放大3倍的模型中,这个参数被固定成了[1, 1, 3, 3]。因此,在插值算子中,我们希望模型的第二个输入是一个 [1, 1, w, h] 的张量,其中 w 和 h 分别是图片宽和高的放大倍数。
+在具体介绍这个算子的实现前,让我们先理清一下思路。我们希望新的插值算子有两个输入,一个是被用于操作的图像,一个是图像的放缩比例。前面讲到,为了对接 ONNX 中 Resize 算子的 scales 参数,这个放缩比例是一个 \[1, 1, x, x\] 的张量,其中 x 为放大倍数。在之前放大3倍的模型中,这个参数被固定成了\[1, 1, 3, 3\]。因此,在插值算子中,我们希望模型的第二个输入是一个 \[1, 1, w, h\] 的张量,其中 w 和 h 分别是图片宽和高的放大倍数。
-搞清楚了插值算子的输入,再看一看算子的具体实现。算子的推理行为由算子的 forward 方法决定。该方法的第一个参数必须为 ctx,后面的参数为算子的自定义输入,我们设置两个输入,分别为被操作的图像和放缩比例。为保证推理正确,需要把 [1, 1, w, h] 格式的输入对接到原来的 interpolate 函数上。我们的做法是截取输入张量的后两个元素,把这两个元素以 list 的格式传入 interpolate 的 scale_factor 参数。
+搞清楚了插值算子的输入,再看一看算子的具体实现。算子的推理行为由算子的 forward 方法决定。该方法的第一个参数必须为 ctx,后面的参数为算子的自定义输入,我们设置两个输入,分别为被操作的图像和放缩比例。为保证推理正确,需要把 \[1, 1, w, h\] 格式的输入对接到原来的 interpolate 函数上。我们的做法是截取输入张量的后两个元素,把这两个元素以 list 的格式传入 interpolate 的 scale_factor 参数。
接下来,我们要决定新算子映射到 ONNX 算子的方法。映射到 ONNX 的方法由一个算子的 symbolic 方法决定。symbolic 方法第一个参数必须是g,之后的参数是算子的自定义输入,和 forward 函数一样。ONNX 算子的具体定义由 g.op 实现。g.op 的每个参数都可以映射到 ONNX 中的算子属性:
@@ -346,9 +348,9 @@ cv2.imwrite("face_ort_3.png", ort_output)
通过学习前两篇教程,我们走完了整个部署流水线,成功部署了支持动态放大倍数的超分辨率模型。在这个过程中,我们既学会了如何简单地调用各框架的API实现模型部署,又学到了如何分析并尝试解决模型部署时碰到的难题。
同样,让我们总结一下本篇教程的知识点:
+
- 模型部署中常见的几类困难有:模型的动态化;新算子的实现;框架间的兼容。
- PyTorch 转 ONNX,实际上就是把每一个操作转化成 ONNX 定义的某一个算子。比如对于 PyTorch 中的 Upsample 和 interpolate,在转 ONNX 后最终都会成为 ONNX 的 Resize 算子。
- 通过修改继承自 torch.autograd.Function 的算子的 symbolic 方法,可以改变该算子映射到 ONNX 算子的行为。
-
至此,"部署第一个模型“的教程算是告一段落了。是不是觉得学到的知识还不够多?没关系,在接下来的几篇教程中,我们将结合 MMDeploy ,重点介绍 ONNX 中间表示和 ONNX Runtime/TensorRT 推理引擎的知识,让大家学会如何部署更复杂的模型。敬请期待!
diff --git a/docs/zh_cn/tutorials/chapter_03_pytorch2onnx.md b/docs/zh_cn/tutorials/chapter_03_pytorch2onnx.md
index e7f8d2ed99..d2587f6254 100644
--- a/docs/zh_cn/tutorials/chapter_03_pytorch2onnx.md
+++ b/docs/zh_cn/tutorials/chapter_03_pytorch2onnx.md
@@ -3,8 +3,11 @@ ONNX 是目前模型部署中最重要的中间表示之一。学懂了 ONNX 的
在把 PyTorch 模型转换成 ONNX 模型时,我们往往只需要轻松地调用一句`torch.onnx.export`就行了。这个函数的接口看上去简单,但它在使用上还有着诸多的“潜规则”。在这篇教程中,我们会详细介绍 PyTorch 模型转 ONNX 模型的原理及注意事项。除此之外,我们还会介绍 PyTorch 与 ONNX 的算子对应关系,以教会大家如何处理 PyTorch 模型转换时可能会遇到的算子支持问题。
## `torch.onnx.export` 细解
+
在这一节里,我们将详细介绍 PyTorch 到 ONNX 的转换函数—— torch.onnx.export。我们希望大家能够更加灵活地使用这个模型转换接口,并通过了解它的实现原理来更好地应对该函数的报错(由于模型部署的兼容性问题,部署复杂模型时该函数时常会报错)。
+
### 计算图导出方法
+
[TorchScript](https://pytorch.org/docs/stable/jit.html) 是一种序列化和优化 PyTorch 模型的格式,在优化过程中,一个`torch.nn.Module`模型会被转换成 TorchScript 的`torch.jit.ScriptModule`模型。现在, TorchScript 也被常当成一种中间表示使用。我们在[其他文章](https://zhuanlan.zhihu.com/p/486914187)中对 TorchScript 有详细的介绍,这里介绍 TorchScript 仅用于说明 PyTorch 模型转 ONNX的原理。
`torch.onnx.export`中需要的模型实际上是一个`torch.jit.ScriptModule`。而要把普通 PyTorch 模型转一个这样的 TorchScript 模型,有跟踪(trace)和脚本化(script)两种导出计算图的方法。如果给`torch.onnx.export`传入了一个普通 PyTorch 模型(`torch.nn.Module`),那么这个模型会默认使用跟踪的方法导出。这一过程如下图所示:
@@ -54,10 +57,13 @@ for model, model_name in zip(models, model_names):
而用脚本化的话,最终的 ONNX 模型用 `Loop` 节点来表示循环。这样哪怕对于不同的 `n`,ONNX 模型也有同样的结构。
由于推理引擎对静态图的支持更好,通常我们在模型部署时不需要显式地把 PyTorch 模型转成 TorchScript 模型,直接把 PyTorch 模型用 `torch.onnx.export` 跟踪导出即可。了解这部分的知识主要是为了在模型转换报错时能够更好地定位问题是否发生在 PyTorch 转 TorchScript 阶段。
+
### 参数讲解
+
了解完转换函数的原理后,我们来详细介绍一下该函数的主要参数的作用。我们主要会从应用的角度来介绍每个参数在不同的模型部署场景中应该如何设置,而不会去列出每个参数的所有设置方法。该函数详细的 API 文档可参考 [torch.onnx ‒ PyTorch 1.11.0 documentation](https://pytorch.org/docs/stable/onnx.html#functions)
`torch.onnx.export` 在 `torch.onnx.__init__.py`文件中的定义如下:
+
```python
def export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL,
input_names=None, output_names=None, aten=False, export_raw_ir=False,
@@ -66,20 +72,30 @@ def export(model, args, f, export_params=True, verbose=False, training=TrainingM
dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None,
enable_onnx_checker=True, use_external_data_format=False):
```
+
前三个必选参数为模型、模型输入、导出的 onnx 文件名,我们对这几个参数已经很熟悉了。我们来着重看一下后面的一些常用可选参数。
+
#### export_params
+
模型中是否存储模型权重。一般中间表示包含两大类信息:模型结构和模型权重,这两类信息可以在同一个文件里存储,也可以分文件存储。ONNX 是用同一个文件表示记录模型的结构和权重的。
我们部署时一般都默认这个参数为 True。如果 onnx 文件是用来在不同框架间传递模型(比如 PyTorch 到 Tensorflow)而不是用于部署,则可以令这个参数为 False。
+
#### input_names, output_names
+
设置输入和输出张量的名称。如果不设置的话,会自动分配一些简单的名字(如数字)。
ONNX 模型的每个输入和输出张量都有一个名字。很多推理引擎在运行 ONNX 文件时,都需要以“名称-张量值”的数据对来输入数据,并根据输出张量的名称来获取输出数据。在进行跟张量有关的设置(比如添加动态维度)时,也需要知道张量的名字。
在实际的部署流水线中,我们都需要设置输入和输出张量的名称,并保证 ONNX 和推理引擎中使用同一套名称。
+
#### opset_version
+
转换时参考哪个 ONNX 算子集版本,默认为9。后文会详细介绍 PyTorch 与 ONNX 的算子对应关系。
+
#### dynamic_axes
+
指定输入输出张量的哪些维度是动态的。
为了追求效率,ONNX 默认所有参与运算的张量都是静态的(张量的形状不发生改变)。但在实际应用中,我们又希望模型的输入张量是动态的,尤其是本来就没有形状限制的全卷积模型。因此,我们需要显式地指明输入输出张量的哪几个维度的大小是可变的。
我们来看一个`dynamic_axes`的设置例子:
+
```python
import torch
@@ -115,9 +131,11 @@ input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_0)
torch.onnx.export(model, dummy_input, model_names[2],
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_23)
```
+
首先,我们导出3个 ONNX 模型,分别为没有动态维度、第0维动态、第2第3维动态的模型。
在这份代码里,我们是用列表的方式表示动态维度,例如:
-```python
+
+````python
dynamic_axes_0 = {
'in' : [0],
'out' : [0]
@@ -129,10 +147,11 @@ dynamic_axes_0 = {
'in' : {0: 'batch'},
'out' : {0: 'batch'}
}
-```
+````
由于在这份代码里我们没有更多的对动态维度的操作,因此简单地用列表指定动态维度即可。
之后,我们用下面的代码来看一看动态维度的作用:
+
```python
import onnxruntime
import numpy as np
@@ -156,7 +175,9 @@ for model_name in model_names:
else:
print(f'Input[{i}] on model {model_name} succeed.')
```
+
我们在模型导出计算图时用的是一个形状为`(1, 3, 10, 10)`的张量。现在,我们来尝试以形状分别是`(1, 3, 10, 10), (2, 3, 10, 10), (1, 3, 20, 20)`为输入,用ONNX Runtime运行一下这几个模型,看看哪些情况下会报错,并保存对应的报错信息。得到的输出信息应该如下:
+
```python
Input[0] on model model_static.onnx succeed.
Input[1] on model model_static.onnx error.
@@ -168,7 +189,9 @@ Input[0] on model model_dynamic_23.onnx succeed.
Input[1] on model model_dynamic_23.onnx error.
Input[2] on model model_dynamic_23.onnx succeed.
```
+
可以看出,形状相同的`(1, 3, 10, 10)`的输入在所有模型上都没有出错。而对于batch(第0维)或者长宽(第2、3维)不同的输入,只有在设置了对应的动态维度后才不会出错。我们可以错误信息中找出是哪些维度出了问题。比如我们可以用以下代码查看`input[1]`在`model_static.onnx`中的报错信息:
+
```python
print(exceptions[(1, 'model_static.onnx')])
@@ -177,10 +200,15 @@ print(exceptions[(1, 'model_static.onnx')])
```
这段报错告诉我们名字叫`in`的输入的第0维不匹配。本来该维的长度应该为1,但我们的输入是2。实际部署中,如果我们碰到了类似的报错,就可以通过设置动态维度来解决问题。
+
### 使用技巧
+
通过学习之前的知识,我们基本掌握了 `torch.onnx.export` 函数的部分实现原理和参数设置方法,足以完成简单模型的转换了。但在实际应用中,使用该函数还会踩很多坑。这里我们模型部署团队把在实战中积累的一些经验分享给大家。
+
#### 使模型在 ONNX 转换时有不同的行为
+
有些时候,我们希望模型在直接用 PyTorch 推理时有一套逻辑,而在导出的ONNX模型中有另一套逻辑。比如,我们可以把一些后处理的逻辑放在模型里,以简化除运行模型之外的其他代码。`torch.onnx.is_in_onnx_export()`可以实现这一任务,该函数仅在执行 `torch.onnx.export()`时为真。以下是一个例子:
+
```python
import torch
@@ -196,9 +224,12 @@ class Model(torch.nn.Module):
return x
```
-这里,我们仅在模型导出时把输出张量的数值限制在[0, 1]之间。使用 `is_in_onnx_export` 确实能让我们方便地在代码中添加和模型部署相关的逻辑。但是,这些代码对只关心模型训练的开发者和用户来说很不友好,突兀的部署逻辑会降低代码整体的可读性。同时,`is_in_onnx_export` 只能在每个需要添加部署逻辑的地方都“打补丁”,难以进行统一的管理。我们之后会介绍如何使用 MMDeploy 的重写机制来规避这些问题。
+这里,我们仅在模型导出时把输出张量的数值限制在\[0, 1\]之间。使用 `is_in_onnx_export` 确实能让我们方便地在代码中添加和模型部署相关的逻辑。但是,这些代码对只关心模型训练的开发者和用户来说很不友好,突兀的部署逻辑会降低代码整体的可读性。同时,`is_in_onnx_export` 只能在每个需要添加部署逻辑的地方都“打补丁”,难以进行统一的管理。我们之后会介绍如何使用 MMDeploy 的重写机制来规避这些问题。
+
#### 利用中断张量跟踪的操作
+
PyTorch 转 ONNX 的跟踪导出法是不是万能的。如果我们在模型中做了一些很“出格”的操作,跟踪法会把某些取决于输入的中间结果变成常量,从而使导出的ONNX模型和原来的模型有出入。以下是一个会造成这种“跟踪中断”的例子:
+
```python
class Model(torch.nn.Module):
def __init__(self):
@@ -215,17 +246,24 @@ torch.onnx.export(model, dummy_input, 'a.onnx')
如果你尝试去导出这个模型,会得到一大堆 warning,告诉你转换出来的模型可能不正确。这也难怪,我们在这个模型里使用了`.item()`把 torch 中的张量转换成了普通的 Python 变量,还尝试遍历 torch 张量,并用一个列表新建一个 torch 张量。这些涉及张量与普通变量转换的逻辑都会导致最终的 ONNX 模型不太正确。
另一方面,我们也可以利用这个性质,在保证正确性的前提下令模型的中间结果变成常量。这个技巧常常用于模型的静态化上,即令模型中所有的张量形状都变成常量。在未来的教程中,我们会在部署实例中详细介绍这些“高级”操作。
-#### 使用张量为输入(PyTorch版本 < 1.9.0)
-正如我们第一篇教程所展示的,在较旧(< 1.9.0)的 PyTorch 中把 Python 数值作为 `torch.onnx.export()`的模型输入时会报错。出于兼容性的考虑,我们还是推荐以张量为模型转换时的模型输入。
+
+#### 使用张量为输入(PyTorch版本 \< 1.9.0)
+
+正如我们第一篇教程所展示的,在较旧(\< 1.9.0)的 PyTorch 中把 Python 数值作为 `torch.onnx.export()`的模型输入时会报错。出于兼容性的考虑,我们还是推荐以张量为模型转换时的模型输入。
+
## PyTorch 对 ONNX 的算子支持
+
在确保`torch.onnx.export()`的调用方法无误后,PyTorch 转 ONNX 时最容易出现的问题就是算子不兼容了。这里我们会介绍如何判断某个 PyTorch 算子在 ONNX 中是否兼容,以助大家在碰到报错时能更好地把错误归类。而具体添加算子的方法我们会在之后的文章里介绍。
在转换普通的`torch.nn.Module`模型时,PyTorch 一方面会用跟踪法执行前向推理,把遇到的算子整合成计算图;另一方面,PyTorch 还会把遇到的每个算子翻译成 ONNX 中定义的算子。在这个翻译过程中,可能会碰到以下情况:
+
- 该算子可以一对一地翻译成一个 ONNX 算子。
- 该算子在 ONNX 中没有直接对应的算子,会翻译成一至多个 ONNX 算子。
- 该算子没有定义翻译成 ONNX 的规则,报错。
那么,该如何查看 PyTorch 算子与 ONNX 算子的对应情况呢?由于 PyTorch 算子是向 ONNX 对齐的,这里我们先看一下 ONNX 算子的定义情况,再看一下 PyTorch 定义的算子映射关系。
+
### ONNX 算子文档
+
ONNX 算子的定义情况,都可以在官方的[算子文档](https://github.com/onnx/onnx/blob/main/docs/Operators.md)中查看。这份文档十分重要,我们碰到任何和 ONNX 算子有关的问题都得来”请教“这份文档。
@@ -235,7 +273,9 @@ ONNX 算子的定义情况,都可以在官方的[算子文档](https://github.
通过点击表格中的链接,我们可以查看某个算子的输入、输出参数规定及使用示例。比如上图是Relu在 ONNX 中的定义规则,这份定义表明 Relu 应该有一个输入和一个输入,输入输出的类型相同,均为 tensor。
+
### PyTorch 对 ONNX 算子的映射
+
在 PyTorch 中,和 ONNX 有关的定义全部放在 [torch.onnx 目录](https://github.com/pytorch/pytorch/tree/master/torch/onnx)中,如下图所示:
@@ -246,6 +286,7 @@ ONNX 算子的定义情况,都可以在官方的[算子文档](https://github.
之后,我们按照代码的调用逻辑,逐步跳转直到最底层的 ONNX 映射函数:
+
```python
upsample_bicubic2d = _interpolate("upsample_bicubic2d", 4, "cubic")
@@ -262,7 +303,9 @@ def _interpolate_helper(name, dim, interpolate_mode):
return symbolic_fn
```
+
最后,在`symbolic_fn`中,我们可以看到插值算子是怎么样被映射成多个 ONNX 算子的。其中,每一个`g.op`就是一个 ONNX 的定义。比如其中的 `Resize` 算子就是这样写的:
+
```python
return g.op("Resize",
input,
@@ -274,10 +317,14 @@ def _interpolate_helper(name, dim, interpolate_mode):
mode_s=interpolate_mode, # nearest, linear, or cubic
nearest_mode_s="floor") # only valid when mode="nearest"
```
+
通过在前面提到的 ONNX 算子文档中查找 [Resize 算子的定义](https://github.com/onnx/onnx/blob/main/docs/Operators.md#resize),我们就可以知道这每一个参数的含义了。用类似的方法,我们可以去查询其他 ONNX 算子的参数含义,进而知道 PyTorch 中的参数是怎样一步一步传入到每个 ONNX 算子中的。
掌握了如何查询 PyTorch 映射到 ONNX 的关系后,我们在实际应用时就可以在 `torch.onnx.export()`的`opset_version`中先预设一个版本号,碰到了问题就去对应的 PyTorch 符号表文件里去查。如果某算子确实不存在,或者算子的映射关系不满足我们的要求,我们就可能得用其他的算子绕过去,或者自定义算子了。
+
## 总结
+
在这篇教程中,我们系统地介绍了 PyTorch 转 ONNX 的原理。我们先是着重讲解了使用最频繁的 `torch.onnx.export`函数,又给出了查询 PyTorch 对 ONNX 算子支持情况的方法。通过本文,我们希望大家能够成功转换出大部分不需要添加新算子的 ONNX 模型,并在碰到算子问题时能够有效定位问题原因。具体而言,大家读完本文后应该了解以下的知识:
+
- 跟踪法和脚本化在导出带控制语句的计算图时有什么区别。
- `torch.onnx.export()`中该如何设置 i`nput_names, output_names, dynamic_axes`。
- 使用 `torch.onnx.is_in_onnx_export()`来使模型在转换到 ONNX 时有不同的行为。
@@ -286,9 +333,11 @@ def _interpolate_helper(name, dim, interpolate_mode):
- 如何判断 PyTorch 对某个 ONNX 算子是否支持,支持的方法是怎样的。
这期介绍的知识比较抽象,大家会不会觉得有点“水”?没关系,下一期教程中,我们将以给出代码实例的形式,介绍多种为 PyTorch 转 ONNX 添加算子支持的方法,为大家在 PyTorch 转 ONNX 这条路上扫除更多的障碍。敬请期待哦!
+
## 练习
+
1. Asinh 算子出现于第 9 个 ONNX 算子集。PyTorch 在 9 号版本的符号表文件中是怎样支持这个算子的?
2. BitShift 算子出现于第11个 ONNX 算子集。PyTorch 在 11 号版本的符号表文件中是怎样支持这个算子的?
-3. 在[第一篇教程](./chapter_01_introduction_to_model_deployment.md)中,我们讲过 PyTorch (截至第 11 号算子集)不支持在插值中设置动态的放缩系数。这个系数对应 `torch.onnx.symbolic_helper._interpolate_helper`的symbolic_fn的Resize算子映射关系中的哪个参数?我们是如何修改这一参数的?
+3. 在\[第一篇教程\](./chapter_01_introduction_to_model_deployment.md)中,我们讲过 PyTorch (截至第 11 号算子集)不支持在插值中设置动态的放缩系数。这个系数对应 `torch.onnx.symbolic_helper._interpolate_helper`的symbolic_fn的Resize算子映射关系中的哪个参数?我们是如何修改这一参数的?
练习的答案会在下期教程中揭晓。
diff --git a/docs/zh_cn/tutorials/how_to_convert_model.md b/docs/zh_cn/tutorials/how_to_convert_model.md
index 0a1b1a9f52..d58146ccf7 100644
--- a/docs/zh_cn/tutorials/how_to_convert_model.md
+++ b/docs/zh_cn/tutorials/how_to_convert_model.md
@@ -2,17 +2,17 @@
-- [如何转换模型](#如何转换模型)
- - [如何将模型从pytorch形式转换成其他后端形式](#如何将模型从pytorch形式转换成其他后端形式)
- - [准备工作](#准备工作)
- - [使用方法](#使用方法)
- - [参数描述](#参数描述)
- - [如何查找pytorch模型对应的部署配置文件](#如何查找pytorch模型对应的部署配置文件)
- - [示例](#示例)
- - [如何评测模型](#如何评测模型)
- - [各后端已支持导出的模型列表](#各后端已支持导出的模型列表)
- - [注意事项](#注意事项)
- - [问答](#问答)
+- [如何转换模型](#%E5%A6%82%E4%BD%95%E8%BD%AC%E6%8D%A2%E6%A8%A1%E5%9E%8B)
+ - [如何将模型从pytorch形式转换成其他后端形式](#%E5%A6%82%E4%BD%95%E5%B0%86%E6%A8%A1%E5%9E%8B%E4%BB%8Epytorch%E5%BD%A2%E5%BC%8F%E8%BD%AC%E6%8D%A2%E6%88%90%E5%85%B6%E4%BB%96%E5%90%8E%E7%AB%AF%E5%BD%A2%E5%BC%8F)
+ - [准备工作](#%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C)
+ - [使用方法](#%E4%BD%BF%E7%94%A8%E6%96%B9%E6%B3%95)
+ - [参数描述](#%E5%8F%82%E6%95%B0%E6%8F%8F%E8%BF%B0)
+ - [如何查找pytorch模型对应的部署配置文件](#%E5%A6%82%E4%BD%95%E6%9F%A5%E6%89%BEpytorch%E6%A8%A1%E5%9E%8B%E5%AF%B9%E5%BA%94%E7%9A%84%E9%83%A8%E7%BD%B2%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6)
+ - [示例](#%E7%A4%BA%E4%BE%8B)
+ - [如何评测模型](#%E5%A6%82%E4%BD%95%E8%AF%84%E6%B5%8B%E6%A8%A1%E5%9E%8B)
+ - [各后端已支持导出的模型列表](#%E5%90%84%E5%90%8E%E7%AB%AF%E5%B7%B2%E6%94%AF%E6%8C%81%E5%AF%BC%E5%87%BA%E7%9A%84%E6%A8%A1%E5%9E%8B%E5%88%97%E8%A1%A8)
+ - [注意事项](#%E6%B3%A8%E6%84%8F%E4%BA%8B%E9%A1%B9)
+ - [问答](#%E9%97%AE%E7%AD%94)
diff --git a/docs/zh_cn/tutorials/how_to_install_mmdeploy_on_jetsons.md b/docs/zh_cn/tutorials/how_to_install_mmdeploy_on_jetsons.md
index d500ec3d37..3ce0e484fe 100644
--- a/docs/zh_cn/tutorials/how_to_install_mmdeploy_on_jetsons.md
+++ b/docs/zh_cn/tutorials/how_to_install_mmdeploy_on_jetsons.md
@@ -1,6 +1,7 @@
# 如何在 Jetson 模组上安装 MMDeploy
本教程将介绍如何在 NVIDIA Jetson 平台上安装 MMDeploy。该方法已经在以下 3 种 Jetson 模组上进行了验证:
+
- Jetson Nano
- Jetson TX2
- Jetson AGX Xavier
@@ -17,6 +18,7 @@ JetPack SDK 为构建硬件加速的边缘 AI 应用提供了一个全面的开
其支持所有的 Jetson 模组及开发套件。
主要有两种安装 JetPack SDK 的方式:
+
1. 使用 SD 卡镜像方式,直接将镜像刻录到 SD 卡上
2. 使用 NVIDIA SDK Manager 进行安装
@@ -57,6 +59,7 @@ JetPack SDK 4+ 自带 python 3.6。我们强烈建议使用默认的 python 版
如果必须安装更高版本的 python, 可以选择安装 JetPack 5+,其提供 python 3.8。
```
+
### PyTorch
从[这里](https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-10-now-available/72048)下载 Jetson 的 PyTorch wheel 文件并保存在本地目录 `/opt` 中。
@@ -226,33 +229,34 @@ pip install -v -e .
1. 编译 SDK Libraries
- ```shell
- mkdir -p build && cd build
- cmake .. \
- -DMMDEPLOY_BUILD_SDK=ON \
- -DMMDEPLOY_BUILD_SDK_PYTHON_API=ON \
- -DMMDEPLOY_TARGET_DEVICES="cuda;cpu" \
- -DMMDEPLOY_TARGET_BACKENDS="trt" \
- -DMMDEPLOY_CODEBASES=all \
- -Dpplcv_DIR=${PPLCV_DIR}/cuda-build/install/lib/cmake/ppl
- make -j$(nproc) && make install
- ```
+ ```shell
+ mkdir -p build && cd build
+ cmake .. \
+ -DMMDEPLOY_BUILD_SDK=ON \
+ -DMMDEPLOY_BUILD_SDK_PYTHON_API=ON \
+ -DMMDEPLOY_TARGET_DEVICES="cuda;cpu" \
+ -DMMDEPLOY_TARGET_BACKENDS="trt" \
+ -DMMDEPLOY_CODEBASES=all \
+ -Dpplcv_DIR=${PPLCV_DIR}/cuda-build/install/lib/cmake/ppl
+ make -j$(nproc) && make install
+ ```
2. 编译 SDK demos
- ```shell
- cd ${MMDEPLOY_DIR}/build/install/example
- mkdir -p build && cd build
- cmake .. -DMMDeploy_DIR=${MMDEPLOY_DIR}/build/install/lib/cmake/MMDeploy
- make -j$(nproc)
- ```
+ ```shell
+ cd ${MMDEPLOY_DIR}/build/install/example
+ mkdir -p build && cd build
+ cmake .. -DMMDeploy_DIR=${MMDEPLOY_DIR}/build/install/lib/cmake/MMDeploy
+ make -j$(nproc)
+ ```
3. 运行 demo
- 以目标检测为例:
- ```shell
- ./object_detection cuda ${directory/to/the/converted/models} ${path/to/an/image}
- ```
+ 以目标检测为例:
+
+ ```shell
+ ./object_detection cuda ${directory/to/the/converted/models} ${path/to/an/image}
+ ```
## Troubleshooting
@@ -260,13 +264,14 @@ pip install -v -e .
- `pip install` 报错 `Illegal instruction (core dumped)`
- ```shell
+ ```shell
echo '# set env for pip' >> ~/.bashrc
echo 'export OPENBLAS_CORETYPE=ARMV8' >> ~/.bashrc
source ~/.bashrc
```
如果上述方法仍无法解决问题,检查是否正在使用镜像文件。如果是的,可尝试:
+
```shell
rm .condarc
conda clean -i
diff --git a/docs/zh_cn/tutorials/how_to_support_new_backends.md b/docs/zh_cn/tutorials/how_to_support_new_backends.md
index 07fd14c19f..b793ac0ca8 100644
--- a/docs/zh_cn/tutorials/how_to_support_new_backends.md
+++ b/docs/zh_cn/tutorials/how_to_support_new_backends.md
@@ -6,9 +6,9 @@ MMDeploy 支持了许多后端推理引擎,但我们依然非常欢迎新后
在对 MMDeploy 添加新的后端引擎之前,需要先检查所要支持的新后端是否符合一些要求:
-* 后端必须能够支持 ONNX 作为 IR。
-* 如果后端需要“.onnx”文件以外的模型文件或权重文件,则需要添加将“.onnx”文件转换为模型文件或权重文件的转换工具,该工具可以是 Python API、脚本或可执行程序。
-* 强烈建议新后端可提供 Python 接口来加载后端文件和推理以进行验证。
+- 后端必须能够支持 ONNX 作为 IR。
+- 如果后端需要“.onnx”文件以外的模型文件或权重文件,则需要添加将“.onnx”文件转换为模型文件或权重文件的转换工具,该工具可以是 Python API、脚本或可执行程序。
+- 强烈建议新后端可提供 Python 接口来加载后端文件和推理以进行验证。
### 支持后端转换
@@ -16,140 +16,140 @@ MMDeploy 中的后端必须支持 ONNX,因此后端能直接加载“.onnx”
1. 在 `mmdeploy/utils/constants.py` 文件中添加新推理后端变量,以表示支持的后端名称。
- **示例**:
+ **示例**:
- ```Python
- # mmdeploy/utils/constants.py
+ ```Python
+ # mmdeploy/utils/constants.py
- class Backend(AdvancedEnum):
- # 以现有的TensorRT为例
- TENSORRT = 'tensorrt'
- ```
+ class Backend(AdvancedEnum):
+ # 以现有的TensorRT为例
+ TENSORRT = 'tensorrt'
+ ```
2. 在 `mmdeploy/backend/` 目录下添加相应的库(一个包括 `__init__.py` 的文件夹),例如, `mmdeploy/backend/tensorrt` 。在 `__init__.py` 中,必须有一个名为 `is_available` 的函数检查用户是否安装了后端库。如果检查通过,则将加载库的剩余文件。
- **例子**:
+ **例子**:
- ```Python
- # mmdeploy/backend/tensorrt/__init__.py
+ ```Python
+ # mmdeploy/backend/tensorrt/__init__.py
- def is_available():
- return importlib.util.find_spec('tensorrt') is not None
+ def is_available():
+ return importlib.util.find_spec('tensorrt') is not None
- if is_available():
- from .utils import create_trt_engine, load_trt_engine, save_trt_engine
- from .wrapper import TRTWrapper
+ if is_available():
+ from .utils import create_trt_engine, load_trt_engine, save_trt_engine
+ from .wrapper import TRTWrapper
- __all__ = [
- 'create_trt_engine', 'save_trt_engine', 'load_trt_engine', 'TRTWrapper'
- ]
- ```
+ __all__ = [
+ 'create_trt_engine', 'save_trt_engine', 'load_trt_engine', 'TRTWrapper'
+ ]
+ ```
3. 在 `configs/_base_/backends` 目录中创建一个配置文件(例如, `configs/_base_/backends/tensorrt.py` )。如果新后端引擎只是将“.onnx”文件作为输入,那么新的配置可以很简单,对应配置只需包含一个表示后端名称的字段(但也应该与 `mmdeploy/utils/constants.py` 中的名称相同)。
- **例子**
+ **例子**
- ```python
- backend_config = dict(type='tensorrt')
- ```
+ ```python
+ backend_config = dict(type='tensorrt')
+ ```
- 但如果后端需要其他文件,则从“.onnx”文件转换为后端文件所需的参数也应包含在配置文件中。
+ 但如果后端需要其他文件,则从“.onnx”文件转换为后端文件所需的参数也应包含在配置文件中。
- **例子**
+ **例子**
- ```Python
+ ```Python
- backend_config = dict(
- type='tensorrt',
- common_config=dict(
- fp16_mode=False, max_workspace_size=0))
- ```
+ backend_config = dict(
+ type='tensorrt',
+ common_config=dict(
+ fp16_mode=False, max_workspace_size=0))
+ ```
- 在拥有一个基本的后端配置文件后,您已经可以通过继承轻松构建一个完整的部署配置。有关详细信息,请参阅我们的[配置教程](how_to_write_config.md)。下面是一个例子:
+ 在拥有一个基本的后端配置文件后,您已经可以通过继承轻松构建一个完整的部署配置。有关详细信息,请参阅我们的[配置教程](how_to_write_config.md)。下面是一个例子:
- ```Python
- _base_ = ['../_base_/backends/tensorrt.py']
+ ```Python
+ _base_ = ['../_base_/backends/tensorrt.py']
- codebase_config = dict(type='mmcls', task='Classification')
- onnx_config = dict(input_shape=None)
- ```
+ codebase_config = dict(type='mmcls', task='Classification')
+ onnx_config = dict(input_shape=None)
+ ```
4. 如果新后端需要模型文件或权重文件而不是“.onnx”文件,则需要在相应的文件夹中创建一个 `onnx2backend.py` 文件(例如,创建 `mmdeploy/backend/tensorrt/onnx2tensorrt.py` )。然后在文件中添加一个转换函数`onnx2backend`。该函数应将给定的“.onnx”文件转换为给定工作目录中所需的后端文件。对函数的其他参数和实现细节没有要求,您可以使用任何工具进行转换。下面有些例子:
- **使用python脚本**
+ **使用python脚本**
- ```Python
- def onnx2openvino(input_info: Dict[str, Union[List[int], torch.Size]],
- output_names: List[str], onnx_path: str, work_dir: str):
+ ```Python
+ def onnx2openvino(input_info: Dict[str, Union[List[int], torch.Size]],
+ output_names: List[str], onnx_path: str, work_dir: str):
- input_names = ','.join(input_info.keys())
- input_shapes = ','.join(str(list(elem)) for elem in input_info.values())
- output = ','.join(output_names)
+ input_names = ','.join(input_info.keys())
+ input_shapes = ','.join(str(list(elem)) for elem in input_info.values())
+ output = ','.join(output_names)
- mo_args = f'--input_model="{onnx_path}" '\
- f'--output_dir="{work_dir}" ' \
- f'--output="{output}" ' \
- f'--input="{input_names}" ' \
- f'--input_shape="{input_shapes}" ' \
- f'--disable_fusing '
- command = f'mo.py {mo_args}'
- mo_output = run(command, stdout=PIPE, stderr=PIPE, shell=True, check=True)
- ```
+ mo_args = f'--input_model="{onnx_path}" '\
+ f'--output_dir="{work_dir}" ' \
+ f'--output="{output}" ' \
+ f'--input="{input_names}" ' \
+ f'--input_shape="{input_shapes}" ' \
+ f'--disable_fusing '
+ command = f'mo.py {mo_args}'
+ mo_output = run(command, stdout=PIPE, stderr=PIPE, shell=True, check=True)
+ ```
- **使用可执行文件**
+ **使用可执行文件**
- ```Python
- def onnx2ncnn(onnx_path: str, work_dir: str):
- onnx2ncnn_path = get_onnx2ncnn_path()
- save_param, save_bin = get_output_model_file(onnx_path, work_dir)
- call([onnx2ncnn_path, onnx_path, save_param, save_bin])\
- ```
+ ```Python
+ def onnx2ncnn(onnx_path: str, work_dir: str):
+ onnx2ncnn_path = get_onnx2ncnn_path()
+ save_param, save_bin = get_output_model_file(onnx_path, work_dir)
+ call([onnx2ncnn_path, onnx_path, save_param, save_bin])\
+ ```
5. 在 `mmdeploy/apis` 中创建新后端库并声明对应 APIs
- **例子**
+ **例子**
- ```Python
- # mmdeploy/apis/ncnn/__init__.py
+ ```Python
+ # mmdeploy/apis/ncnn/__init__.py
- from mmdeploy.backend.ncnn import is_available
+ from mmdeploy.backend.ncnn import is_available
- __all__ = ['is_available']
+ __all__ = ['is_available']
- if is_available():
- from mmdeploy.backend.ncnn.onnx2ncnn import (onnx2ncnn,
- get_output_model_file)
- __all__ += ['onnx2ncnn', 'get_output_model_file']
- ```
+ if is_available():
+ from mmdeploy.backend.ncnn.onnx2ncnn import (onnx2ncnn,
+ get_output_model_file)
+ __all__ += ['onnx2ncnn', 'get_output_model_file']
+ ```
- 然后根据需要使用这些 APIs 为 `tools/deploy.py` 添加相关转换代码
+ 然后根据需要使用这些 APIs 为 `tools/deploy.py` 添加相关转换代码
- **例子**
+ **例子**
- ```Python
- # tools/deploy.py
- # ...
- elif backend == Backend.NCNN:
- from mmdeploy.apis.ncnn import is_available as is_available_ncnn
+ ```Python
+ # tools/deploy.py
+ # ...
+ elif backend == Backend.NCNN:
+ from mmdeploy.apis.ncnn import is_available as is_available_ncnn
- if not is_available_ncnn():
- logging.error('ncnn support is not available.')
- exit(-1)
+ if not is_available_ncnn():
+ logging.error('ncnn support is not available.')
+ exit(-1)
- from mmdeploy.apis.ncnn import onnx2ncnn, get_output_model_file
+ from mmdeploy.apis.ncnn import onnx2ncnn, get_output_model_file
- backend_files = []
- for onnx_path in onnx_files:
- create_process(
- f'onnx2ncnn with {onnx_path}',
- target=onnx2ncnn,
- args=(onnx_path, args.work_dir),
- kwargs=dict(),
- ret_value=ret_value)
- backend_files += get_output_model_file(onnx_path, args.work_dir)
- # ...
- ```
+ backend_files = []
+ for onnx_path in onnx_files:
+ create_process(
+ f'onnx2ncnn with {onnx_path}',
+ target=onnx2ncnn,
+ args=(onnx_path, args.work_dir),
+ kwargs=dict(),
+ ret_value=ret_value)
+ backend_files += get_output_model_file(onnx_path, args.work_dir)
+ # ...
+ ```
6. 将 OpenMMLab 的模型转换后(如有必要)并在后端引擎上进行推理。如果在测试时发现一些不兼容的算子,可以尝试按照[重写器教程](how_to_support_new_model.md)为后端重写原始模型或添加自定义算子。
@@ -161,71 +161,71 @@ MMDeploy 中的后端必须支持 ONNX,因此后端能直接加载“.onnx”
1. 添加一个名为 `wrapper.py` 的文件到 `mmdeploy/backend/{backend}` 中相应后端文件夹。例如, `mmdeploy/backend/tensorrt/wrapper` 。此模块应实现并注册一个封装类,该类继承 `mmdeploy/backend/base/base_wrapper.py` 中的基类 `BaseWrapper` 。
- **例子**
+ **例子**
- ```Python
- from mmdeploy.utils import Backend
- from ..base import BACKEND_WRAPPER, BaseWrapper
+ ```Python
+ from mmdeploy.utils import Backend
+ from ..base import BACKEND_WRAPPER, BaseWrapper
- @BACKEND_WRAPPER.register_module(Backend.TENSORRT.value)
- class TRTWrapper(BaseWrapper):
- ```
+ @BACKEND_WRAPPER.register_module(Backend.TENSORRT.value)
+ class TRTWrapper(BaseWrapper):
+ ```
2. 封装类可以在函数 `__init__` 中初始化引擎以及在 `forward` 函数中进行推理。请注意,该 `__init__` 函数必须接受一个参数 `output_names` 并将其传递给基类以确定输出张量的顺序。其中 `forward` 输入和输出变量应表示tensors的名称和值的字典。
3. 为了方便性能测试,该类应该定义一个 `execute` 函数,只调用后端引擎的推理接口。该 `forward` 函数应在预处理数据后调用 `execute` 函数。
- **例子**
+ **例子**
- ```Python
- from mmdeploy.utils import Backend
- from mmdeploy.utils.timer import TimeCounter
- from ..base import BACKEND_WRAPPER, BaseWrapper
+ ```Python
+ from mmdeploy.utils import Backend
+ from mmdeploy.utils.timer import TimeCounter
+ from ..base import BACKEND_WRAPPER, BaseWrapper
- @BACKEND_WRAPPER.register_module(Backend.ONNXRUNTIME.value)
- class ORTWrapper(BaseWrapper):
+ @BACKEND_WRAPPER.register_module(Backend.ONNXRUNTIME.value)
+ class ORTWrapper(BaseWrapper):
- def __init__(self,
- onnx_file: str,
- device: str,
- output_names: Optional[Sequence[str]] = None):
- # Initialization
- #
- # ...
- super().__init__(output_names)
+ def __init__(self,
+ onnx_file: str,
+ device: str,
+ output_names: Optional[Sequence[str]] = None):
+ # Initialization
+ #
+ # ...
+ super().__init__(output_names)
- def forward(self, inputs: Dict[str,
- torch.Tensor]) -> Dict[str, torch.Tensor]:
- # Fetch data
- # ...
+ def forward(self, inputs: Dict[str,
+ torch.Tensor]) -> Dict[str, torch.Tensor]:
+ # Fetch data
+ # ...
- self.__ort_execute(self.io_binding)
+ self.__ort_execute(self.io_binding)
- # Postprocess data
- # ...
+ # Postprocess data
+ # ...
- @TimeCounter.count_time()
- def __ort_execute(self, io_binding: ort.IOBinding):
- # Only do the inference
- self.sess.run_with_iobinding(io_binding)
- ```
+ @TimeCounter.count_time()
+ def __ort_execute(self, io_binding: ort.IOBinding):
+ # Only do the inference
+ self.sess.run_with_iobinding(io_binding)
+ ```
4. 为新封装装器添加默认初始化方法 `mmdeploy/codebase/base/backend_model.py`
- **例子**
-
- ```Python
- @staticmethod
- def _build_wrapper(backend: Backend,
- backend_files: Sequence[str],
- device: str,
- output_names: Optional[Sequence[str]] = None):
- if backend == Backend.ONNXRUNTIME:
- from mmdeploy.backend.onnxruntime import ORTWrapper
- return ORTWrapper(
- onnx_file=backend_files[0],
- device=device,
- output_names=output_names)
- ```
+ **例子**
+
+ ```Python
+ @staticmethod
+ def _build_wrapper(backend: Backend,
+ backend_files: Sequence[str],
+ device: str,
+ output_names: Optional[Sequence[str]] = None):
+ if backend == Backend.ONNXRUNTIME:
+ from mmdeploy.backend.onnxruntime import ORTWrapper
+ return ORTWrapper(
+ onnx_file=backend_files[0],
+ device=device,
+ output_names=output_names)
+ ```
5. 为新后端引擎代码添加相关注释和单元测试 :).
diff --git a/docs/zh_cn/tutorials/how_to_support_new_model.md b/docs/zh_cn/tutorials/how_to_support_new_model.md
index f873e90bda..228a178387 100644
--- a/docs/zh_cn/tutorials/how_to_support_new_model.md
+++ b/docs/zh_cn/tutorials/how_to_support_new_model.md
@@ -21,8 +21,8 @@ def repeat_static(ctx, input, *size):
使用函数重写器是十分容易的,只需添加一个带参数的装饰器即可:
- `func_name`是需要被重载的函数,它可以是其他PyTorch 的函数或者是自定义的函数。模块中的方法也可以通过工具进行重载。
-- `backend`是推理引擎。当模型被导入到引擎的时候,函数会被重载。如果没有给出,重载默认的参数就是重载的参数。如果后端的重载的参数不存在,将会按照预设的默认模式进行重载。
-当参数与原始的参数相同时,除了把上下文信息`ctx` 作为第一的参数外,上下文也提供了一些有用的信息,例如:部署的配置`ctx.cfg` 和原始的函数(已经被重载)`ctx.origin_func`。
+- `backend`是推理引擎。当模型被导入到引擎的时候,函数会被重载。如果没有给出,重载默认的参数就是重载的参数。如果后端的重载的参数不存在,将会按照预设的默认模式进行重载。
+ 当参数与原始的参数相同时,除了把上下文信息`ctx` 作为第一的参数外,上下文也提供了一些有用的信息,例如:部署的配置`ctx.cfg` 和原始的函数(已经被重载)`ctx.origin_func`。
### 模型重载器
diff --git a/docs/zh_cn/tutorials/how_to_use_docker.md b/docs/zh_cn/tutorials/how_to_use_docker.md
index 6c340adec8..e6150d0028 100644
--- a/docs/zh_cn/tutorials/how_to_use_docker.md
+++ b/docs/zh_cn/tutorials/how_to_use_docker.md
@@ -5,23 +5,28 @@
### 构建镜像
对于 CPU 用户,我们可以通过以下方式使用最新的 MMDeploy 构建 docker 镜像:
+
```
cd mmdeploy
docker build docker/CPU/ -t mmdeploy:master-cpu
```
+
对于 GPU 用户,我们可以通过以下方式使用最新的 MMDeploy 构建 docker 镜像:
+
```
cd mmdeploy
docker build docker/GPU/ -t mmdeploy:master-gpu
```
要安装具有特定版本的 MMDeploy,我们可以将 `--build-arg VERSION=${VERSION}` 附加到构建命令中。以 GPU 为例:
+
```
cd mmdeploy
docker build docker/GPU/ -t mmdeploy:0.1.0 --build-arg VERSION=0.1.0
```
要切换成阿里源安装依赖,我们可以将 `--build-arg USE_SRC_INSIDE=${USE_SRC_INSIDE}` 附加到构建命令中。
+
```
# 以 GPU 为例
cd mmdeploy
@@ -35,6 +40,7 @@ docker build docker/CPU/ -t mmdeploy:inside --build-arg USE_SRC_INSIDE=true
### 运行 docker 容器
构建 docker 镜像成功后,我们可以使用 `docker run` 启动 docker 服务。 GPU 镜像为例:
+
```
docker run --gpus all -it -p 8080:8081 mmdeploy:master-gpu
```
@@ -43,15 +49,16 @@ docker run --gpus all -it -p 8080:8081 mmdeploy:master-gpu
1. CUDA error: the provided PTX was compiled with an unsupported toolchain:
- 如 [这里](https://forums.developer.nvidia.com/t/cuda-error-the-provided-ptx-was-compiled-with-an-unsupported-toolchain/185754)所说,更新 GPU 的驱动到您的GPU能使用的最新版本。
+ 如 [这里](https://forums.developer.nvidia.com/t/cuda-error-the-provided-ptx-was-compiled-with-an-unsupported-toolchain/185754)所说,更新 GPU 的驱动到您的GPU能使用的最新版本。
+
+2. docker: Error response from daemon: could not select device driver "" with capabilities: \[\[gpu\]\].
-2. docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
- ```
- # Add the package repositories
- distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
- curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
- curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
+ ```
+ # Add the package repositories
+ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
+ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
+ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
- sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
- sudo systemctl restart docker
- ```
+ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
+ sudo systemctl restart docker
+ ```
diff --git a/docs/zh_cn/tutorials/how_to_write_config.md b/docs/zh_cn/tutorials/how_to_write_config.md
index 200acd5c70..de99472f0a 100644
--- a/docs/zh_cn/tutorials/how_to_write_config.md
+++ b/docs/zh_cn/tutorials/how_to_write_config.md
@@ -1,27 +1,28 @@
# 如何编写配置文件
+
这篇教程介绍了如何编写模型转换和部署的配置文件。部署配置文件由`ONNX配置信息`, `代码库配置信息`, `推理框架配置信息`组成。
-- [如何编写配置文件](#如何编写配置文件)
- - [1. 如何编写ONNX配置信息](#1-如何编写onnx配置信息)
- - [ONNX配置信息参数说明](#onnx配置信息参数说明)
- - [示例](#示例)
- - [动态尺寸输入和输出配置](#动态尺寸输入和输出配置)
- - [示例](#示例-1)
- - [2. 如何编写代码库配置信息](#2-如何编写代码库配置信息)
- - [代码库配置信息参数说明](#代码库配置信息参数说明)
- - [示例](#示例-2)
- - [3. 如何编写推理框架配置信息](#3-如何编写推理框架配置信息)
- - [示例](#示例-3)
- - [4. 部署配置信息完整示例](#4-部署配置信息完整示例)
- - [5. 部署配置文件命名规则](#5-部署配置文件命名规则)
- - [示例](#示例-4)
- - [6. 如何编写模型配置文件](#6-如何编写模型配置文件)
- - [7. 注意事项](#7-注意事项)
- - [8. 常见问题](#8-常见问题)
+- [如何编写配置文件](#%E5%A6%82%E4%BD%95%E7%BC%96%E5%86%99%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6)
+ - [1. 如何编写ONNX配置信息](#1-%E5%A6%82%E4%BD%95%E7%BC%96%E5%86%99onnx%E9%85%8D%E7%BD%AE%E4%BF%A1%E6%81%AF)
+ - [ONNX配置信息参数说明](#onnx%E9%85%8D%E7%BD%AE%E4%BF%A1%E6%81%AF%E5%8F%82%E6%95%B0%E8%AF%B4%E6%98%8E)
+ - [示例](#%E7%A4%BA%E4%BE%8B)
+ - [动态尺寸输入和输出配置](#%E5%8A%A8%E6%80%81%E5%B0%BA%E5%AF%B8%E8%BE%93%E5%85%A5%E5%92%8C%E8%BE%93%E5%87%BA%E9%85%8D%E7%BD%AE)
+ - [示例](#%E7%A4%BA%E4%BE%8B-1)
+ - [2. 如何编写代码库配置信息](#2-%E5%A6%82%E4%BD%95%E7%BC%96%E5%86%99%E4%BB%A3%E7%A0%81%E5%BA%93%E9%85%8D%E7%BD%AE%E4%BF%A1%E6%81%AF)
+ - [代码库配置信息参数说明](#%E4%BB%A3%E7%A0%81%E5%BA%93%E9%85%8D%E7%BD%AE%E4%BF%A1%E6%81%AF%E5%8F%82%E6%95%B0%E8%AF%B4%E6%98%8E)
+ - [示例](#%E7%A4%BA%E4%BE%8B-2)
+ - [3. 如何编写推理框架配置信息](#3-%E5%A6%82%E4%BD%95%E7%BC%96%E5%86%99%E6%8E%A8%E7%90%86%E6%A1%86%E6%9E%B6%E9%85%8D%E7%BD%AE%E4%BF%A1%E6%81%AF)
+ - [示例](#%E7%A4%BA%E4%BE%8B-3)
+ - [4. 部署配置信息完整示例](#4-%E9%83%A8%E7%BD%B2%E9%85%8D%E7%BD%AE%E4%BF%A1%E6%81%AF%E5%AE%8C%E6%95%B4%E7%A4%BA%E4%BE%8B)
+ - [5. 部署配置文件命名规则](#5-%E9%83%A8%E7%BD%B2%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6%E5%91%BD%E5%90%8D%E8%A7%84%E5%88%99)
+ - [示例](#%E7%A4%BA%E4%BE%8B-4)
+ - [6. 如何编写模型配置文件](#6-%E5%A6%82%E4%BD%95%E7%BC%96%E5%86%99%E6%A8%A1%E5%9E%8B%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6)
+ - [7. 注意事项](#7-%E6%B3%A8%E6%84%8F%E4%BA%8B%E9%A1%B9)
+ - [8. 常见问题](#8-%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98)
@@ -32,14 +33,20 @@ ONNX 配置信息描述了如何将PyTorch模型转换为ONNX模型。
### ONNX配置信息参数说明
- `type`: 配置信息类型。 默认为 `onnx`。
+
- `export_params`: 如果指定,将导出模型所有参数。如果您只想导出未训练模型将此项设置为 False。
+
- `keep_initializers_as_inputs`:
-如果为 True,则所有初始化器(通常对应为参数)也将作为输入导出,添加到计算图中。 如果为 False,则初始化器不会作为输入导出,不添加到计算图中,仅将非参数输入添加到计算图中。
+ 如果为 True,则所有初始化器(通常对应为参数)也将作为输入导出,添加到计算图中。 如果为 False,则初始化器不会作为输入导出,不添加到计算图中,仅将非参数输入添加到计算图中。
- `opset_version`: ONNX的算子集版本,默认为11。
+
- `save_file`: 输出ONNX模型文件。
+
- `input_names`: 模型计算图中输入节点的名称。
+
- `output_names`: 模型计算图中输出节点的名称。
+
- `input_shape`: 模型输入张量的高度和宽度。
#### 示例
diff --git a/setup.cfg b/setup.cfg
index f2dac821a1..f973c5e47f 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -17,3 +17,10 @@ known_first_party = mmdeploy
known_third_party = h5py,m2r,mmcls,mmcv,mmdeploy_python,mmdet,mmedit,mmocr,mmseg,ncnn,numpy,onnx,onnxruntime,packaging,pyppeteer,pyppl,pytest,pytorch_sphinx_theme,recommonmark,setuptools,sphinx,tensorrt,torch,torchvision
no_lines_before = STDLIB,LOCALFOLDER
default_section = THIRDPARTY
+
+# ignore-words-list needs to be lowercase format. For example, if we want to
+# ignore word "BA", then we need to append "ba" to ignore-words-list rather
+# than "BA"
+[codespell]
+quiet-level = 3
+ignore-words-list = inout,hist,ba
| |
 -
### Major features
- **Fully support OpenMMLab models**
We provide a unified model deployment toolbox for the codebases in OpenMMLab. The supported codebases are listed as below, and more will be added in the future
+
- [x] MMClassification
- [x] MMDetection
- [x] MMSegmentation
@@ -53,6 +53,7 @@ a part of the [OpenMMLab](https://openmmlab.com/) project.
- **Multiple inference backends are available**
Models can be exported and run in different backends. The following ones are supported, and more will be taken into consideration
+
- [x] ONNX Runtime
- [x] TensorRT
- [x] PPLNN
@@ -61,7 +62,7 @@ a part of the [OpenMMLab](https://openmmlab.com/) project.
- **Efficient and highly scalable SDK Framework by C/C++**
- All kinds of modules in SDK can be extensible, such as `Transform` for image processing, `Net` for Neural Network inference, `Module` for postprocessing and so on
+ All kinds of modules in SDK can be extensible, such as `Transform` for image processing, `Net` for Neural Network inference, `Module` for postprocessing and so on
## License
@@ -93,6 +94,7 @@ We appreciate all contributions to improve MMDeploy. Please refer to [CONTRIBUTI
## Acknowledgement
We would like to sincerely thank the following teams for their contributions to [MMDeploy](https://github.com/open-mmlab/mmdeploy):
+
- [OpenPPL](https://github.com/openppl-public)
- [OpenVINO](https://github.com/openvinotoolkit/openvino)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index fd5018b025..0c3d726517 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -41,6 +41,7 @@ MMDeploy 是一个开源深度学习模型部署工具箱,它是 [OpenMMLab](h
- **全面支持 OpenMMLab 模型的部署**
我们为 OpenMMLab 各算法库提供了统一的模型部署工具箱。已支持的算法库如下所示,未来将支持更多的算法库
+
- [x] MMClassification
- [x] MMDetection
- [x] MMSegmentation
@@ -51,6 +52,7 @@ MMDeploy 是一个开源深度学习模型部署工具箱,它是 [OpenMMLab](h
- **支持多种推理后端**
模型可以导出为多种推理引擎文件,并在对应的后端上进行推理。 如下后端已经支持,后续将支持更多的后端。
+
- [x] ONNX Runtime
- [x] TensorRT
- [x] PPLNN
diff --git a/demo/README.md b/demo/README.md
index 73f7439068..aad0cbb5b5 100644
--- a/demo/README.md
+++ b/demo/README.md
@@ -1,16 +1,21 @@
## Demo
+
We provide a demo showing what our mmdeploy can do for general model deployment.
In `demo_rewrite.py`, a resnet18 model from `torchvision` is rewritten through mmdeploy tool. In our rewritten model, the forward function of resnet gets modified to only down sample the original input to 4x. Original onnx model of resnet18 and its rewritten are visualized through [netron](https://netron.app/).
### Prerequisite
+
Before we run `demp_rewrite.py`, we need to install `pyppeteer` through:
+
```
pip install pyppeteer
```
### Demo results
+
The original resnet18 model and its modified one are visualized as follows. The left model is the original resnet18 while the right model is exported after rewritten.
-Original resnet18 | Rewritten model
-:-------------------------:|:-------------------------:
- | 
+
+| Original resnet18 | Rewritten model |
+| :-------------------------: | :--------------------------: |
+|  |  |
diff --git a/docs/en/backends/ncnn.md b/docs/en/backends/ncnn.md
index 18db4bf2f7..9818f92f33 100644
--- a/docs/en/backends/ncnn.md
+++ b/docs/en/backends/ncnn.md
@@ -8,44 +8,48 @@ MMDeploy now supports ncnn version == 1.0.20220216
- Download VulkanTools for the compilation of ncnn.
- ```bash
- wget https://sdk.lunarg.com/sdk/download/1.2.176.1/linux/vulkansdk-linux-x86_64-1.2.176.1.tar.gz?Human=true -O vulkansdk-linux-x86_64-1.2.176.1.tar.gz
- tar -xf vulkansdk-linux-x86_64-1.2.176.1.tar.gz
- export VULKAN_SDK=$(pwd)/1.2.176.1/x86_64
- export LD_LIBRARY_PATH=$VULKAN_SDK/lib:$LD_LIBRARY_PATH
- ```
+ ```bash
+ wget https://sdk.lunarg.com/sdk/download/1.2.176.1/linux/vulkansdk-linux-x86_64-1.2.176.1.tar.gz?Human=true -O vulkansdk-linux-x86_64-1.2.176.1.tar.gz
+ tar -xf vulkansdk-linux-x86_64-1.2.176.1.tar.gz
+ export VULKAN_SDK=$(pwd)/1.2.176.1/x86_64
+ export LD_LIBRARY_PATH=$VULKAN_SDK/lib:$LD_LIBRARY_PATH
+ ```
- Check your gcc version.
-You should ensure your gcc satisfies `gcc >= 6`.
+ You should ensure your gcc satisfies `gcc >= 6`.
- Install Protocol Buffers through:
+
+ ```bash
+ apt-get install libprotobuf-dev protobuf-compiler
+ ```
+
+- Prepare ncnn Framework
+
+ - Download ncnn source code
+
```bash
- apt-get install libprotobuf-dev protobuf-compiler
+ git clone -b 20220216 git@github.com:Tencent/ncnn.git
```
-- Prepare ncnn Framework
+ - Make install ncnn library
- - Download ncnn source code
- ```bash
- git clone -b 20220216 git@github.com:Tencent/ncnn.git
- ```
-
- - Make install ncnn library
- ```bash
- cd ncnn
- export NCNN_DIR=$(pwd)
- git submodule update --init
- mkdir -p build && cd build
- cmake -DNCNN_VULKAN=ON -DNCNN_SYSTEM_GLSLANG=ON -DNCNN_BUILD_EXAMPLES=ON -DNCNN_PYTHON=ON -DNCNN_BUILD_TOOLS=ON -DNCNN_BUILD_BENCHMARK=ON -DNCNN_BUILD_TESTS=ON ..
- make install
- ```
-
- - Install pyncnn module
- ```bash
- cd ${NCNN_DIR} # To NCNN root directory
- cd python
- pip install -e .
- ```
+ ```bash
+ cd ncnn
+ export NCNN_DIR=$(pwd)
+ git submodule update --init
+ mkdir -p build && cd build
+ cmake -DNCNN_VULKAN=ON -DNCNN_SYSTEM_GLSLANG=ON -DNCNN_BUILD_EXAMPLES=ON -DNCNN_PYTHON=ON -DNCNN_BUILD_TOOLS=ON -DNCNN_BUILD_BENCHMARK=ON -DNCNN_BUILD_TESTS=ON ..
+ make install
+ ```
+
+ - Install pyncnn module
+
+ ```bash
+ cd ${NCNN_DIR} # To NCNN root directory
+ cd python
+ pip install -e .
+ ```
#### Build custom ops
@@ -70,11 +74,10 @@ If you haven't installed NCNN in the default path, please add `-Dncnn_DIR` flag
- This follows the tutorial on [How to convert model](../tutorials/how_to_convert_model.md).
- The converted model has two files: `.param` and `.bin`, as model structure file and weight file respectively.
-
### List of supported custom ops
| Operator | CPU | MMDeploy Releases |
-|:--------------------------------|:---:|:------------------|
+| :------------------------------ | :-: | :---------------- |
| [Expand](../ops/ncnn.md#expand) | Y | master |
| [Gather](../ops/ncnn.md#gather) | Y | master |
| [Shape](../ops/ncnn.md#shape) | Y | master |
@@ -88,11 +91,11 @@ If you haven't installed NCNN in the default path, please add `-Dncnn_DIR` flag
1. When running ncnn models for inference with custom ops, it fails and shows the error message like:
- ```bash
- TypeError: register mm custom layers(): incompatible function arguments. The following argument types are supported:
- 1.(ar0: ncnn:Net) -> int
+ ```bash
+ TypeError: register mm custom layers(): incompatible function arguments. The following argument types are supported:
+ 1.(ar0: ncnn:Net) -> int
- Invoked with:
-
### Major features
- **Fully support OpenMMLab models**
We provide a unified model deployment toolbox for the codebases in OpenMMLab. The supported codebases are listed as below, and more will be added in the future
+
- [x] MMClassification
- [x] MMDetection
- [x] MMSegmentation
@@ -53,6 +53,7 @@ a part of the [OpenMMLab](https://openmmlab.com/) project.
- **Multiple inference backends are available**
Models can be exported and run in different backends. The following ones are supported, and more will be taken into consideration
+
- [x] ONNX Runtime
- [x] TensorRT
- [x] PPLNN
@@ -61,7 +62,7 @@ a part of the [OpenMMLab](https://openmmlab.com/) project.
- **Efficient and highly scalable SDK Framework by C/C++**
- All kinds of modules in SDK can be extensible, such as `Transform` for image processing, `Net` for Neural Network inference, `Module` for postprocessing and so on
+ All kinds of modules in SDK can be extensible, such as `Transform` for image processing, `Net` for Neural Network inference, `Module` for postprocessing and so on
## License
@@ -93,6 +94,7 @@ We appreciate all contributions to improve MMDeploy. Please refer to [CONTRIBUTI
## Acknowledgement
We would like to sincerely thank the following teams for their contributions to [MMDeploy](https://github.com/open-mmlab/mmdeploy):
+
- [OpenPPL](https://github.com/openppl-public)
- [OpenVINO](https://github.com/openvinotoolkit/openvino)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index fd5018b025..0c3d726517 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -41,6 +41,7 @@ MMDeploy 是一个开源深度学习模型部署工具箱,它是 [OpenMMLab](h
- **全面支持 OpenMMLab 模型的部署**
我们为 OpenMMLab 各算法库提供了统一的模型部署工具箱。已支持的算法库如下所示,未来将支持更多的算法库
+
- [x] MMClassification
- [x] MMDetection
- [x] MMSegmentation
@@ -51,6 +52,7 @@ MMDeploy 是一个开源深度学习模型部署工具箱,它是 [OpenMMLab](h
- **支持多种推理后端**
模型可以导出为多种推理引擎文件,并在对应的后端上进行推理。 如下后端已经支持,后续将支持更多的后端。
+
- [x] ONNX Runtime
- [x] TensorRT
- [x] PPLNN
diff --git a/demo/README.md b/demo/README.md
index 73f7439068..aad0cbb5b5 100644
--- a/demo/README.md
+++ b/demo/README.md
@@ -1,16 +1,21 @@
## Demo
+
We provide a demo showing what our mmdeploy can do for general model deployment.
In `demo_rewrite.py`, a resnet18 model from `torchvision` is rewritten through mmdeploy tool. In our rewritten model, the forward function of resnet gets modified to only down sample the original input to 4x. Original onnx model of resnet18 and its rewritten are visualized through [netron](https://netron.app/).
### Prerequisite
+
Before we run `demp_rewrite.py`, we need to install `pyppeteer` through:
+
```
pip install pyppeteer
```
### Demo results
+
The original resnet18 model and its modified one are visualized as follows. The left model is the original resnet18 while the right model is exported after rewritten.
-Original resnet18 | Rewritten model
-:-------------------------:|:-------------------------:
- | 
+
+| Original resnet18 | Rewritten model |
+| :-------------------------: | :--------------------------: |
+|  |  |
diff --git a/docs/en/backends/ncnn.md b/docs/en/backends/ncnn.md
index 18db4bf2f7..9818f92f33 100644
--- a/docs/en/backends/ncnn.md
+++ b/docs/en/backends/ncnn.md
@@ -8,44 +8,48 @@ MMDeploy now supports ncnn version == 1.0.20220216
- Download VulkanTools for the compilation of ncnn.
- ```bash
- wget https://sdk.lunarg.com/sdk/download/1.2.176.1/linux/vulkansdk-linux-x86_64-1.2.176.1.tar.gz?Human=true -O vulkansdk-linux-x86_64-1.2.176.1.tar.gz
- tar -xf vulkansdk-linux-x86_64-1.2.176.1.tar.gz
- export VULKAN_SDK=$(pwd)/1.2.176.1/x86_64
- export LD_LIBRARY_PATH=$VULKAN_SDK/lib:$LD_LIBRARY_PATH
- ```
+ ```bash
+ wget https://sdk.lunarg.com/sdk/download/1.2.176.1/linux/vulkansdk-linux-x86_64-1.2.176.1.tar.gz?Human=true -O vulkansdk-linux-x86_64-1.2.176.1.tar.gz
+ tar -xf vulkansdk-linux-x86_64-1.2.176.1.tar.gz
+ export VULKAN_SDK=$(pwd)/1.2.176.1/x86_64
+ export LD_LIBRARY_PATH=$VULKAN_SDK/lib:$LD_LIBRARY_PATH
+ ```
- Check your gcc version.
-You should ensure your gcc satisfies `gcc >= 6`.
+ You should ensure your gcc satisfies `gcc >= 6`.
- Install Protocol Buffers through:
+
+ ```bash
+ apt-get install libprotobuf-dev protobuf-compiler
+ ```
+
+- Prepare ncnn Framework
+
+ - Download ncnn source code
+
```bash
- apt-get install libprotobuf-dev protobuf-compiler
+ git clone -b 20220216 git@github.com:Tencent/ncnn.git
```
-- Prepare ncnn Framework
+ - Make install ncnn library
- - Download ncnn source code
- ```bash
- git clone -b 20220216 git@github.com:Tencent/ncnn.git
- ```
-
- - Make install ncnn library
- ```bash
- cd ncnn
- export NCNN_DIR=$(pwd)
- git submodule update --init
- mkdir -p build && cd build
- cmake -DNCNN_VULKAN=ON -DNCNN_SYSTEM_GLSLANG=ON -DNCNN_BUILD_EXAMPLES=ON -DNCNN_PYTHON=ON -DNCNN_BUILD_TOOLS=ON -DNCNN_BUILD_BENCHMARK=ON -DNCNN_BUILD_TESTS=ON ..
- make install
- ```
-
- - Install pyncnn module
- ```bash
- cd ${NCNN_DIR} # To NCNN root directory
- cd python
- pip install -e .
- ```
+ ```bash
+ cd ncnn
+ export NCNN_DIR=$(pwd)
+ git submodule update --init
+ mkdir -p build && cd build
+ cmake -DNCNN_VULKAN=ON -DNCNN_SYSTEM_GLSLANG=ON -DNCNN_BUILD_EXAMPLES=ON -DNCNN_PYTHON=ON -DNCNN_BUILD_TOOLS=ON -DNCNN_BUILD_BENCHMARK=ON -DNCNN_BUILD_TESTS=ON ..
+ make install
+ ```
+
+ - Install pyncnn module
+
+ ```bash
+ cd ${NCNN_DIR} # To NCNN root directory
+ cd python
+ pip install -e .
+ ```
#### Build custom ops
@@ -70,11 +74,10 @@ If you haven't installed NCNN in the default path, please add `-Dncnn_DIR` flag
- This follows the tutorial on [How to convert model](../tutorials/how_to_convert_model.md).
- The converted model has two files: `.param` and `.bin`, as model structure file and weight file respectively.
-
### List of supported custom ops
| Operator | CPU | MMDeploy Releases |
-|:--------------------------------|:---:|:------------------|
+| :------------------------------ | :-: | :---------------- |
| [Expand](../ops/ncnn.md#expand) | Y | master |
| [Gather](../ops/ncnn.md#gather) | Y | master |
| [Shape](../ops/ncnn.md#shape) | Y | master |
@@ -88,11 +91,11 @@ If you haven't installed NCNN in the default path, please add `-Dncnn_DIR` flag
1. When running ncnn models for inference with custom ops, it fails and shows the error message like:
- ```bash
- TypeError: register mm custom layers(): incompatible function arguments. The following argument types are supported:
- 1.(ar0: ncnn:Net) -> int
+ ```bash
+ TypeError: register mm custom layers(): incompatible function arguments. The following argument types are supported:
+ 1.(ar0: ncnn:Net) -> int
- Invoked with: