NovelAIの提案した学習手法、自動キャプションニング、タグ付け、Windows+VRAM 12GB(v1.4/1.5の場合)環境等に対応したfine tuningです。
Diffusersを用いてStable DiffusionのU-Netのfine tuningを行います。NovelAIの記事にある以下の改善に対応しています(Aspect Ratio BucketingについてはNovelAIのコードを参考にしましたが、最終的なコードはすべてオリジナルです)。
- CLIP(Text Encoder)の最後の層ではなく最後から二番目の層の出力を用いる。
- 正方形以外の解像度での学習(Aspect Ratio Bucketing) 。
- トークン長を75から225に拡張する。
- BLIPによるキャプショニング(キャプションの自動作成)、DeepDanbooruまたはWD14Taggerによる自動タグ付けを行う。
- Hypernetworkの学習にも対応する。
- Stable Diffusion v2.0(baseおよび768/v)に対応。
- VAEの出力をあらかじめ取得しディスクに保存しておくことで、学習の省メモリ化、高速化を図る。
デフォルトではText Encoderの学習は行いません。モデル全体のfine tuningではU-Netだけを学習するのが一般的なようです(NovelAIもそのようです)。オプション指定でText Encoderも学習対象とできます。
プロンプトを画像に反映するため、テキストの特徴量への変換を行うのがCLIP(Text Encoder)です。Stable DiffusionではCLIPの最後の層の出力を用いていますが、それを最後から二番目の層の出力を用いるよう変更できます。NovelAIによると、これによりより正確にプロンプトが反映されるようになるとのことです。 元のまま、最後の層の出力を用いることも可能です。 ※Stable Diffusion 2.0では最後から二番目の層をデフォルトで使います。clip_skipオプションを指定しないでください。
Stable Diffusionは512*512で学習されていますが、それに加えて256*1024や384*640といった解像度でも学習します。これによりトリミングされる部分が減り、より正しくプロンプトと画像の関係が学習されることが期待されます。 学習解像度はパラメータとして与えられた解像度の面積(=メモリ使用量)を超えない範囲で、64ピクセル単位で縦横に調整、作成されます。
機械学習では入力サイズをすべて統一するのが一般的ですが、特に制約があるわけではなく、実際は同一のバッチ内で統一されていれば大丈夫です。NovelAIの言うbucketingは、あらかじめ教師データを、アスペクト比に応じた学習解像度ごとに分類しておくことを指しているようです。そしてバッチを各bucket内の画像で作成することで、バッチの画像サイズを統一します。
Stable Diffusionでは最大75トークン(開始・終了を含むと77トークン)ですが、それを225トークンまで拡張します。 ただしCLIPが受け付ける最大長は75トークンですので、225トークンの場合、単純に三分割してCLIPを呼び出してから結果を連結しています。
※これが望ましい実装なのかどうかはいまひとつわかりません。とりあえず動いてはいるようです。特に2.0では何も参考になる実装がないので独自に実装してあります。
※Automatic1111氏のWeb UIではカンマを意識して分割、といったこともしているようですが、私の場合はそこまでしておらず単純な分割です。
このリポジトリのREADMEを参照してください。
学習させたい画像データを用意し、任意のフォルダに入れてください。リサイズ等の事前の準備は必要ありません。 ただし学習解像度よりもサイズが小さい画像については、超解像などで品質を保ったまま拡大しておくことをお勧めします。
複数の教師データフォルダにも対応しています。前処理をそれぞれのフォルダに対して実行する形となります。
たとえば以下のように画像を格納します。
キャプションを使わずタグだけで学習する場合はスキップしてください。
また手動でキャプションを用意する場合、キャプションは教師データ画像と同じディレクトリに、同じファイル名、拡張子.caption等で用意してください。各ファイルは1行のみのテキストファイルとします。
最新版ではBLIPのダウンロード、重みのダウンロード、仮想環境の追加は不要になりました。そのままで動作します。
finetuneフォルダ内のmake_captions.pyを実行します。
python finetune\make_captions.py --batch_size <バッチサイズ> <教師データフォルダ>
バッチサイズ8、教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
python finetune\make_captions.py --batch_size 8 ..\train_data
キャプションファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.captionで作成されます。
batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。 max_lengthオプションでキャプションの最大長を指定できます。デフォルトは75です。モデルをトークン長225で学習する場合には長くしても良いかもしれません。 caption_extensionオプションでキャプションの拡張子を変更できます。デフォルトは.captionです(.txtにすると後述のDeepDanbooruと競合します)。
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
なお、推論にランダム性があるため、実行するたびに結果が変わります。固定する場合には--seedオプションで「--seed 42」のように乱数seedを指定してください。
その他のオプションは--helpでヘルプをご参照ください(パラメータの意味についてはドキュメントがまとまっていないようで、ソースを見るしかないようです)。
デフォルトでは拡張子.captionでキャプションファイルが生成されます。
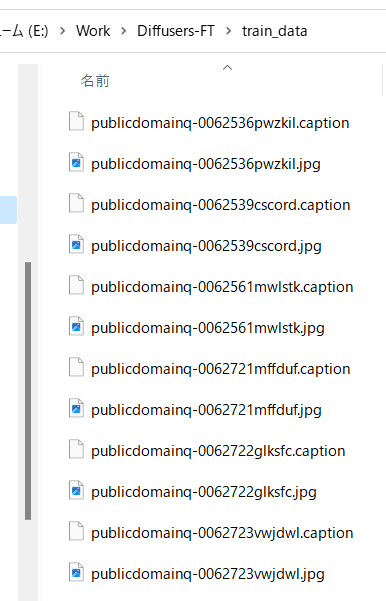
たとえば以下のようなキャプションが付きます。
danbooruタグのタグ付け自体を行わない場合は「キャプションとタグ情報の前処理」に進んでください。
タグ付けはDeepDanbooruまたはWD14Taggerで行います。WD14Taggerのほうが精度が良いようです。WD14Taggerでタグ付けする場合は、次の章へ進んでください。
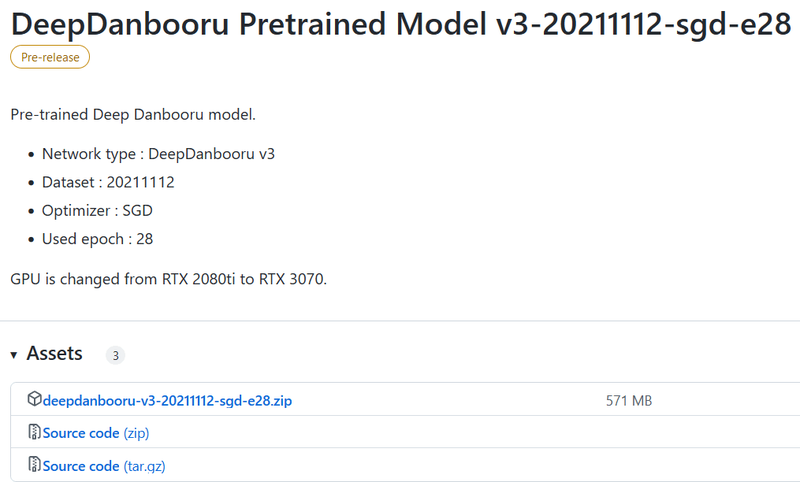
DeepDanbooru https://github.com/KichangKim/DeepDanbooru を作業フォルダにcloneしてくるか、zipをダウンロードして展開します。私はzipで展開しました。 またDeepDanbooruのReleasesのページ https://github.com/KichangKim/DeepDanbooru/releases の「DeepDanbooru Pretrained Model v3-20211112-sgd-e28」のAssetsから、deepdanbooru-v3-20211112-sgd-e28.zipをダウンロードしてきてDeepDanbooruのフォルダに展開します。
以下からダウンロードします。Assetsをクリックして開き、そこからダウンロードします。
以下のようなこういうディレクトリ構造にしてください
Diffusersの環境に必要なライブラリをインストールします。DeepDanbooruのフォルダに移動してインストールします(実質的にはtensorflow-ioが追加されるだけだと思います)。
pip install -r requirements.txt
続いてDeepDanbooru自体をインストールします。
pip install .
以上でタグ付けの環境整備は完了です。
DeepDanbooruのフォルダに移動し、deepdanbooruを実行してタグ付けを行います。
deepdanbooru evaluate <教師データフォルダ> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。1件ずつ処理されるためわりと遅いです。
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
以下のように生成されます。
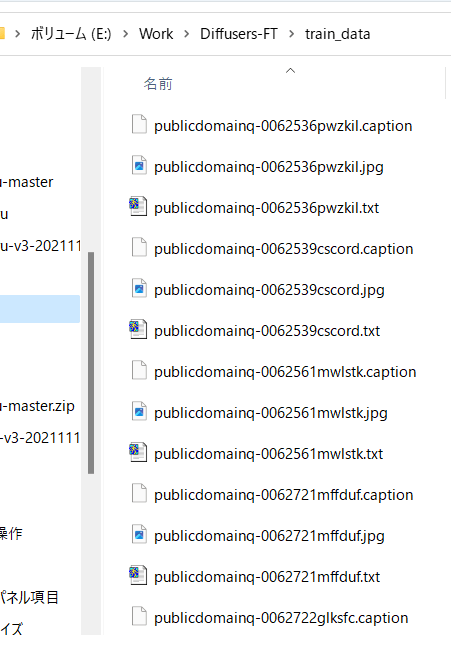
こんな感じにタグが付きます(すごい情報量……)。
DeepDanbooruの代わりにWD14Taggerを用いる手順です。
Automatic1111氏のWebUIで使用しているtaggerを利用します。こちらのgithubページ(https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger )の情報を参考にさせていただきました。
最初の環境整備で必要なモジュールはインストール済みです。また重みはHugging Faceから自動的にダウンロードしてきます。
スクリプトを実行してタグ付けを行います。
python tag_images_by_wd14_tagger.py --batch_size <バッチサイズ> <教師データフォルダ>
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
初回起動時にはモデルファイルがwd14_tagger_modelフォルダに自動的にダウンロードされます(フォルダはオプションで変えられます)。以下のようになります。
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。


threshオプションで、判定されたタグのconfidence(確信度)がいくつ以上でタグをつけるかが指定できます。デフォルトはWD14Taggerのサンプルと同じ0.35です。値を下げるとより多くのタグが付与されますが、精度は下がります。 batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。caption_extensionオプションでタグファイルの拡張子を変更できます。デフォルトは.txtです。 model_dirオプションでモデルの保存先フォルダを指定できます。 またforce_downloadオプションを指定すると保存先フォルダがあってもモデルを再ダウンロードします。
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
スクリプトから処理しやすいようにキャプションとタグをメタデータとしてひとつのファイルにまとめます。
キャプションをメタデータに入れるには、作業フォルダ内で以下を実行してください(キャプションを学習に使わない場合は実行不要です)(実際は1行で記述します、以下同様)。
python merge_captions_to_metadata.py <教師データフォルダ>
--in_json <読み込むメタデータファイル名>
<メタデータファイル名>
メタデータファイル名は任意の名前です。 教師データがtrain_data、読み込むメタデータファイルなし、メタデータファイルがmeta_cap.jsonの場合、以下のようになります。
python merge_captions_to_metadata.py train_data meta_cap.json
caption_extensionオプションでキャプションの拡張子を指定できます。
複数の教師データフォルダがある場合には、full_path引数を指定してください(メタデータにフルパスで情報を持つようになります)。そして、それぞれのフォルダに対して実行してください。
python merge_captions_to_metadata.py --full_path
train_data1 meta_cap1.json
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
train_data2 meta_cap2.json
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。
同様にタグもメタデータにまとめます(タグを学習に使わない場合は実行不要です)。
python merge_dd_tags_to_metadata.py <教師データフォルダ>
--in_json <読み込むメタデータファイル名>
<書き込むメタデータファイル名>
先と同じディレクトリ構成で、meta_cap.jsonを読み、meta_cap_dd.jsonに書きだす場合、以下となります。
python merge_dd_tags_to_metadata.py train_data --in_json meta_cap.json meta_cap_dd.json
複数の教師データフォルダがある場合には、full_path引数を指定してください。そして、それぞれのフォルダに対して実行してください。
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
train_data1 meta_cap_dd1.json
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
train_data2 meta_cap_dd2.json
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。
ここまででメタデータファイルにキャプションとDeepDanbooruのタグがまとめられています。ただ自動キャプショニングにしたキャプションは表記ゆれなどがあり微妙(※)ですし、タグにはアンダースコアが含まれていたりratingが付いていたりしますので(DeepDanbooruの場合)、エディタの置換機能などを用いてキャプションとタグのクリーニングをしたほうがいいでしょう。
※たとえばアニメ絵の少女を学習する場合、キャプションにはgirl/girls/woman/womenなどのばらつきがあります。また「anime girl」なども単に「girl」としたほうが適切かもしれません。
クリーニング用のスクリプトが用意してありますので、スクリプトの内容を状況に応じて編集してお使いください。
(教師データフォルダの指定は不要になりました。メタデータ内の全データをクリーニングします。)
python clean_captions_and_tags.py <読み込むメタデータファイル名> <書き込むメタデータファイル名>
--in_jsonは付きませんのでご注意ください。たとえば次のようになります。
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
以上でキャプションとタグの前処理は完了です。
学習を高速に進めるためあらかじめ画像の潜在表現を取得しディスクに保存しておきます。あわせてbucketing(教師データをアスペクト比に応じて分類する)を行います。
作業フォルダで以下のように入力してください。
python prepare_buckets_latents.py <教師データフォルダ>
<読み込むメタデータファイル名> <書き込むメタデータファイル名>
<fine tuningするモデル名またはcheckpoint>
--batch_size <バッチサイズ>
--max_resolution <解像度 幅,高さ>
--mixed_precision <精度>
モデルがmodel.ckpt、バッチサイズ4、学習解像度は512*512、精度no(float32)で、meta_clean.jsonからメタデータを読み込み、meta_lat.jsonに書き込む場合、以下のようになります。
python prepare_buckets_latents.py
train_data meta_clean.json meta_lat.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
教師データフォルダにnumpyのnpz形式でlatentsが保存されます。
Stable Diffusion 2.0のモデルを読み込む場合は--v2オプションを指定してください(--v_parameterizationは不要です)。
解像度の最小サイズを--min_bucket_resoオプションで、最大サイズを--max_bucket_resoで指定できます。デフォルトはそれぞれ256、1024です。たとえば最小サイズに384を指定すると、256*1024や320*768などの解像度は使わなくなります。 解像度を768*768のように大きくした場合、最大サイズに1280などを指定すると良いでしょう。
--flip_augオプションを指定すると左右反転のaugmentation(データ拡張)を行います。疑似的にデータ量を二倍に増やすことができますが、データが左右対称でない場合に指定すると(例えばキャラクタの外見、髪型など)学習がうまく行かなくなります。 (反転した画像についてもlatentsを取得し、*_flip.npzファイルを保存する単純な実装です。fline_tune.pyには特にオプション指定は必要ありません。_flip付きのファイルがある場合、flip付き・なしのファイルを、ランダムに読み込みます。)
バッチサイズはVRAM 12GBでももう少し増やせるかもしれません。 解像度は64で割り切れる数字で、"幅,高さ"で指定します。解像度はfine tuning時のメモリサイズに直結します。VRAM 12GBでは512,512が限界と思われます(※)。16GBなら512,704や512,768まで上げられるかもしれません。なお256,256等にしてもVRAM 8GBでは厳しいようです(パラメータやoptimizerなどは解像度に関係せず一定のメモリが必要なため)。
※batch size 1の学習で12GB VRAM、640,640で動いたとの報告もありました。
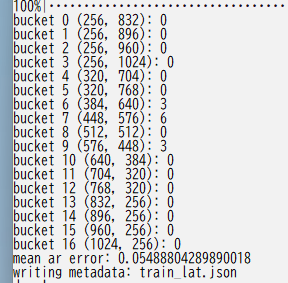
以下のようにbucketingの結果が表示されます。
複数の教師データフォルダがある場合には、full_path引数を指定してください。そして、それぞれのフォルダに対して実行してください。
python prepare_buckets_latents.py --full_path
train_data1 meta_clean.json meta_lat1.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
python prepare_buckets_latents.py --full_path
train_data2 meta_lat1.json meta_lat2.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
読み込み元と書き込み先を同じにすることも可能ですが別々の方が安全です。
※引数を都度書き換えて、別のメタデータファイルに書き込むと安全です。
たとえば以下のように実行します。以下は省メモリ化のための設定です。
accelerate launch --num_cpu_threads_per_process 1 fine_tune.py
--pretrained_model_name_or_path=model.ckpt
--in_json meta_lat.json
--train_data_dir=train_data
--output_dir=fine_tuned
--shuffle_caption
--train_batch_size=1 --learning_rate=5e-6 --max_train_steps=10000
--use_8bit_adam --xformers --gradient_checkpointing
--mixed_precision=bf16
--save_every_n_epochs=4
accelerateのnum_cpu_threads_per_processには通常は1を指定するとよいようです。
pretrained_model_name_or_pathに学習対象のモデルを指定します(Stable DiffusionのcheckpointかDiffusersのモデル)。Stable Diffusionのcheckpointは.ckptと.safetensorsに対応しています(拡張子で自動判定)。
in_jsonにlatentをキャッシュしたときのメタデータファイルを指定します。
train_data_dirに教師データのフォルダを、output_dirに学習後のモデルの出力先フォルダを指定します。
shuffle_captionを指定すると、キャプション、タグをカンマ区切りされた単位でシャッフルして学習します(Waifu Diffusion v1.3で行っている手法です)。 (先頭のトークンのいくつかをシャッフルせずに固定できます。その他のオプションのkeep_tokensをご覧ください。)
train_batch_sizeにバッチサイズを指定します。VRAM 12GBでは1か2程度を指定してください。解像度によっても指定可能な数は変わってきます。 学習に使用される実際のデータ量は「バッチサイズ×ステップ数」です。バッチサイズを増やした時には、それに応じてステップ数を下げることが可能です。
learning_rateに学習率を指定します。たとえばWaifu Diffusion v1.3は5e-6のようです。 max_train_stepsにステップ数を指定します。
use_8bit_adamを指定すると8-bit Adam Optimizerを使用します。省メモリ化、高速化されますが精度は下がる可能性があります。
xformersを指定するとCrossAttentionを置換して省メモリ化、高速化します。 ※11/9時点ではfloat32の学習ではxformersがエラーになるため、bf16/fp16を使うか、代わりにmem_eff_attnを指定して省メモリ版CrossAttentionを使ってください(速度はxformersに劣ります)。
gradient_checkpointingで勾配の途中保存を有効にします。速度は遅くなりますが使用メモリ量が減ります。
mixed_precisionで混合精度を使うか否かを指定します。"fp16"または"bf16"を指定すると省メモリになりますが精度は劣ります。 "fp16"と"bf16"は使用メモリ量はほぼ同じで、bf16の方が学習結果は良くなるとの話もあります(試した範囲ではあまり違いは感じられませんでした)。 "no"を指定すると使用しません(float32になります)。
※bf16で学習したcheckpointをAUTOMATIC1111氏のWeb UIで読み込むとエラーになるようです。これはデータ型のbfloat16がWeb UIのモデルsafety checkerでエラーとなるためのようです。save_precisionオプションを指定してfp16またはfloat32形式で保存してください。またはsafetensors形式で保管しても良さそうです。
save_every_n_epochsを指定するとそのエポックだけ経過するたびに学習中のモデルを保存します。
Hugging Faceのstable-diffusion-2-baseを使う場合は--v2オプションを、stable-diffusion-2または768-v-ema.ckptを使う場合は--v2と--v_parameterizationの両方のオプションを指定してください。
まずgradient_checkpointingを外すと速度が上がります。ただし設定できるバッチサイズが減りますので、精度と速度のバランスを見ながら設定してください。
バッチサイズを増やすと速度、精度が上がります。メモリが足りる範囲で、1データ当たりの速度を確認しながら増やしてください(メモリがぎりぎりになるとかえって速度が落ちることがあります)。
clip_skipオプションに2を指定すると、後ろから二番目の層の出力を用います。1またはオプション省略時は最後の層を用います。 学習したモデルはAutomatic1111氏のWeb UIで推論できるはずです。
※SD2.0はデフォルトで後ろから二番目の層を使うため、SD2.0の学習では指定しないでください。
学習対象のモデルがもともと二番目の層を使うように学習されている場合は、2を指定するとよいでしょう。
そうではなく最後の層を使用していた場合はモデル全体がそれを前提に学習されています。そのため改めて二番目の層を使用して学習すると、望ましい学習結果を得るにはある程度の枚数の教師データ、長めの学習が必要になるかもしれません。
max_token_lengthに150または225を指定することでトークン長を拡張して学習できます。 学習したモデルはAutomatic1111氏のWeb UIで推論できるはずです。
clip_skipと同様に、モデルの学習状態と異なる長さで学習するには、ある程度の教師データ枚数、長めの学習時間が必要になると思われます。
logging_dirオプションにログ保存先フォルダを指定してください。TensorBoard形式のログが保存されます。
たとえば--logging_dir=logsと指定すると、作業フォルダにlogsフォルダが作成され、その中の日時フォルダにログが保存されます。 また--log_prefixオプションを指定すると、日時の前に指定した文字列が追加されます。「--logging_dir=logs --log_prefix=fine_tune_style1」などとして識別用にお使いください。
TensorBoardでログを確認するには、別のコマンドプロンプトを開き、作業フォルダで以下のように入力します(tensorboardはDiffusersのインストール時にあわせてインストールされると思いますが、もし入っていないならpip install tensorboardで入れてください)。
tensorboard --logdir=logs
別の記事で解説予定です。
full_fp16オプションを指定すると勾配を通常のfloat32からfloat16(fp16)に変更して学習します(mixed precisionではなく完全なfp16学習になるようです)。これによりSD1.xの512512サイズでは8GB未満、SD2.xの512512サイズで12GB未満のVRAM使用量で学習できるようです。
あらかじめaccelerate configでfp16を指定し、オプションでmixed_precision="fp16"としてください(bf16では動作しません)。
メモリ使用量を最小化するためには、xformers、use_8bit_adam、gradient_checkpointingの各オプションを指定し、train_batch_sizeを1としてください。 (余裕があるようならtrain_batch_sizeを段階的に増やすと若干精度が上がるはずです。)
PyTorchのソースにパッチを当てて無理やり実現しています(PyTorch 1.12.1と1.13.0で確認)。精度はかなり落ちますし、途中で学習失敗する確率も高くなります。学習率やステップ数の設定もシビアなようです。それらを認識したうえで自己責任でお使いください。
数値を指定するとキャプションの先頭から、指定した数だけのトークン(カンマ区切りの文字列)をシャッフルせず固定します。
キャプションとタグが両方ある場合、学習時のプロンプトは「キャプション,タグ1,タグ2……」のように連結されますので、「--keep_tokens=1」とすれば、学習時にキャプションが必ず先頭に来るようになります。
データセットの枚数が極端に少ない場合、epochがすぐに終わってしまうため(epochの区切りで少し時間が掛かります)、数値を指定してデータを何倍かしてepochを長めにしてください。
Text Encoderも学習対象とします。メモリ使用量が若干増加します。
通常のfine tuningではText Encoderは学習対象としませんが(恐らくText Encoderの出力に従うようにU-Netを学習するため)、学習データ数が少ない場合には、DreamBoothのようにText Encoder側に学習させるのも有効的なようです。
checkpoint保存時のデータ形式をfloat、fp16、bf16から指定できます(未指定時は学習中のデータ形式と同じ)。ディスク容量が節約できますがモデルによる生成結果は変わってきます。またfloatやfp16を指定すると、1111氏のWeb UIでも読めるようになるはずです。
※VAEについては元のcheckpointのデータ形式のままになりますので、fp16でもモデルサイズが2GB強まで小さくならない場合があります。
モデルの保存形式を指定します。ckpt、safetensors、diffusers、diffusers_safetensorsのいずれかを指定してください。
Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
このオプションを指定するとsafetensors形式でcheckpointを保存します。保存形式はデフォルト(読み込んだ形式と同じ)になります。
save_stateオプションで、途中保存時および最終保存時に、checkpointに加えてoptimizer等の学習状態をフォルダに保存します。これにより中断してから学習再開したときの精度低下が避けられます(optimizerは状態を持ちながら最適化をしていくため、その状態がリセットされると再び初期状態から最適化を行わなくてはなりません)。なお、Accelerateの仕様でステップ数は保存されません。
スクリプト起動時、resumeオプションで状態の保存されたフォルダを指定すると再開できます。
学習状態は一回の保存あたり5GB程度になりますのでディスク容量にご注意ください。
指定したステップ数だけまとめて勾配を更新します。バッチサイズを増やすのと同様の効果がありますが、メモリを若干消費します。
※Accelerateの仕様で学習モデルが複数の場合には対応していないとのことですので、Text Encoderを学習対象にして、このオプションに2以上の値を指定するとエラーになるかもしれません。
lr_schedulerオプションで学習率のスケジューラをlinear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmupから選べます。デフォルトはconstantです。
lr_warmup_stepsでスケジューラのウォームアップ(だんだん学習率を変えていく)ステップ数を指定できます。詳細については各自お調べください。
スクリプト独自のxformers置換機能ではなくDiffusersのxformers機能を利用します。Hypernetworkの学習はできなくなります。