规模驱使机器学习前进
深度学习(神经网络)的许多想法已经存在几十年了。 为什么这些想法现在才火起来? 最近得以进步的最大驱动因素有两个:
- 数据可用性。 人们现在在数字设备(笔记本电脑,移动设备)上花费更多的时间。这些活动产生大量的数据,我们可以使用这些数据来训练和反馈我们的学习算法。
- 计算尺度。 我们几年前才开始能够训练足够大的神经网络,以利用我们现在拥有的巨大的数据集。
具体来说,即使你积累了更多的数据,通常传统学习算法(如逻辑回归)的性能表现“平稳”。这意味着它的学习曲线“平坦”,即使你给它更多的数据,算法也不会再有提升效果。

这就好像传统的算法不知道如何处理我们现在拥有的所有数据。 如果你在同一个监督学习任务上训练一个小的神经网络(NN),你可能会获得略好一点的性能:

这里,“小的神经网络”是指仅具有少量隐藏单位/层/参数的神经网络。 最后,如果你训练越来越大的神经网络,你可以获得更好的性能:[1]
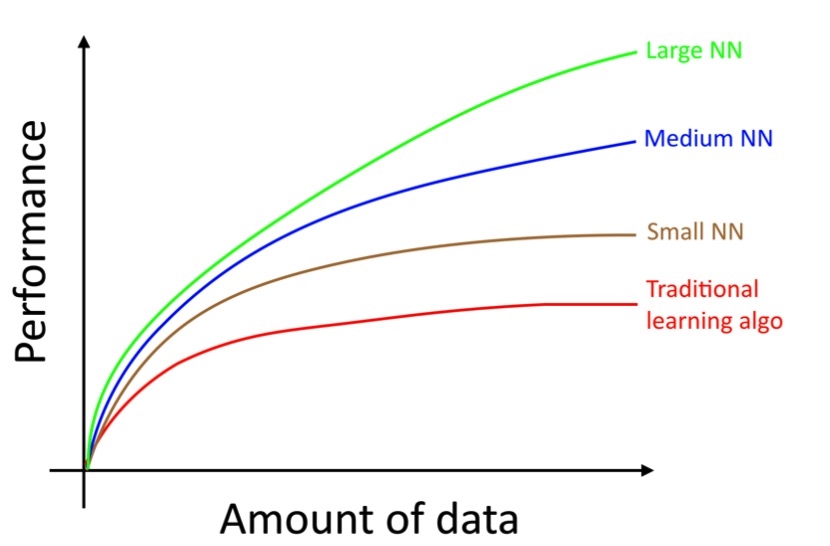
因此,当你做到下面两点的时候你会获得最佳的性能(i)训练一个非常大的神经网络,使其在上面的绿色曲线上; (ii)有大量的数据。 许多其他细节,如神经网络架构也很重要,这里已经有很多创新。 但是现在提高算法性能的更可靠的方法之一仍然是(i)训练更大的网络和(ii)获得更多的数据。 如何完成(i)和(ii)的方法是极其复杂的。 这本书将详细讨论细节。 我们将从对传统学习算法和神经网络都有用的一般策略开始,并建立构建深度学习系统所需的最先进策略。
————————————————————
[1]这个图表展示了NN在小数据集下做得更好。这种效果不如NNs在大数据集中表现良好的效果一致。 在小数据系统中,取决于特征是如何手工设计的,传统算法可能做的很好,也可能做得并不好。 例如,如果你有20个训练样本,那么使用逻辑回归还是神经网络可能并不重要; 手工特征的选择将比算法的选择产生更大的影响。 但如果你有100万的样本,我更倾向于神经网络。