Artificial neural networks or short: ANN (german: Künstliches Neuronales Netzwerk).
ANNs are no new invention, to the contrary they are comparatively old, but the increasing computation power enables us to calculate bigger and bigger networks, which enables us to attack bigger and bigger problems.
Since a ANN is a network or collection of neurons, the question occurs "What is a neuron?".
A neuron is inspired by the structure of a neuron in a human brain. It receives one or more impulses and reacts by outputting a more or less intense signal.
A neuron is receiving an input-vector (the impulse):
After the neuron receives the input it starts to evaluate the input, by multiplying each input value with an internally saved Weight. When we create a new neural network we normally initialize the weights with random values.
After the input is evaluated the Offset (Bias) gets added, the offset is used as additional parameter to increase the efficiency of the network. The resulting value is the internal state z. When we create a new neural network we normally initialize each bias with the value zero (0).
This so calculated internal state gets then passed on to the activation function to calculate the Activation(y) of the Neuron.
In the end the so calculated Activation is passed on to other neurons, commonly of the next layer.
After we evaluate the input, we have a value that has no defined range. This value can be any real value (between
The most common activity functions are the Sigmoid function, the Hyperbolic Tangent and especially the ReLu (Rectifier Linear Unit) function (max(0,x)).

One of the simplest activation functions, that lets the Neuron only fire if the activation is bigger than zero.
- value range:
$[0, +\infty]$ - not differentiable everywhere
- continuous
Exponential modification of the Rectifier, so the Neuron also fires when negative values are given (but weaker).
- value range:
$[0, +\infty]$ - differentiable everywhere
Tries to perform a smooth approximation on the standard relu-functions.
- returns values in range:
$[0, +\infty]$ - everywhere differentiable
- value range:
$[-1, +1]$ - differentiable everywhere
One of the most spreaded activation functions and the standard activation function in combination with Backpropagation.
- value range:
$[0, 1]$ - differentiable everywhere
- value range:
$[-1, 1]$ - differentiable everywhere
A neural network consisting of only one neuron is called a Perceptron, but since such a neural network is limited in its use cases, we tend to use neural networks with several layers.
In general you can differ between three kinds of layers
- The input layer
This Layer is passive, doing nothing but passing the input vector on to the hidden layer.
- The hidden layer
Every layer that exist between the input layer and output layer is called hidden.
- The output layer.
This layer returns the values, that represent the output of the whole neural network, therefore the activation function doesn't get applied to this layer, because the evaluation if a neuron should fire or not is unimportant, since the output of the neuron is used as output for the whole network.
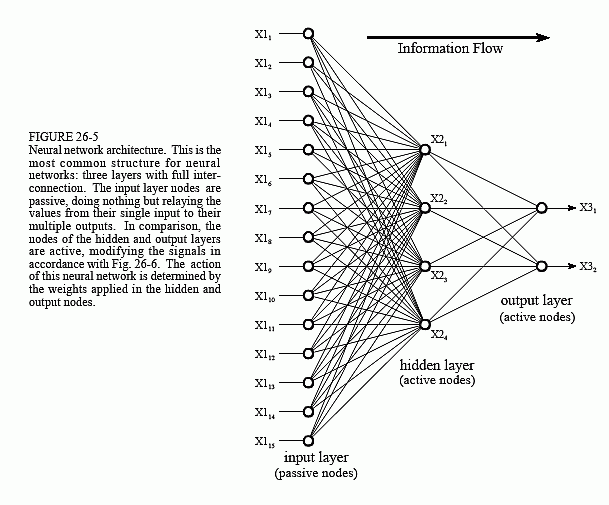
A normal neural network has only one input and one output layer, but you can use as many hidden layers as you want. Each additional layer raises the amount of CPU time needed to train and evaluate the network. If your network includes a large number number of layers (i.e., more than 10) it is called a Deep Neural Network.
In a simple artificial neural network each neuron of a layer is connected to every neuron of the next layer. These layers are called Fully Connected Layers.
It's also possible to integrate a case separation into a ANN, this option is common for the extraction of features from a data set. This case separation is called convolution and is realized through a simple function, but it turned out to be a really strong functionality. Such networks are named Convolutional Neural Networks (or short ConvNets)
We can pass values to our network and calculate an activation based on the random weights but we could do the same thing with a piece of paper and a few dies. But before we implement the most well known ability of an AI, namely to learn, we first need to know evaluate the correctness of the AI.
ANN can be used to sort inputs into different classes. A simple classification problem might only have two states (true or false). The ANN therefore either gets the class correct or not. To evaluate your AI you can just count how many correct predictions the AI made (the more the better).
For a classifier it's also useful to use a softmax function as the last layer to transform the actual activations of the previous layer into a probability (from 0 to 1).
This function is used to reduce a K-dimensional vector z of arbitrary real numbers:
to a K-dimensional vector of real values between [0, 1] that add up to one.
$$ \sigma(z) = \left(\begin{array}{c} \sigma(z){0}\ \sigma(z){1} \ ...\ \sigma(z)_{K}\end{array}\right) e.g.: \left(\begin{array}{c}0.5\ 0.05\0.05\ 0.4\end{array}\right) $$
In this case we expect our network to return an estimated or predicted response (mostly a value or a set of values). We need a different loss function for calculate the loss. Commonly we will therefore use L1 were we just use the difference between the expected and the returned output. Mostly to create a more neutral loss we take the square of the difference this loss function is then called L2. In some cases it can also become handy to use Cross Entropy as a loss function.
After we defined which cases our network got right or wrong, we can start to teach it. Note that you naturally have to first collect fitting training and test data for your network. After that you train your network by giving the network one set of your training data to process. Since we initialized the weights of the neurons with random values it is unlikely that the output is similar to the expected output. To change that we start to tune our network using our loss function. There are several different technics how to do that, I will introduce some of them in a different file.
It's possible to represent a neural network as sequence of matrices. We extract the weight-vectors of the neurons and assemble them in a matrix. Each column of these matrices represents the weights of one neuron. Each Bias gets extracted into a separate vector that gets added during the evaluation.
This principle can be applied to every hidden layer as well as the output layer.
The Elements of Statistical Learning by Trevor Hastie, Robert Tibshirani, Jerome Friedman
Neural Networks by Raul Rojas (available online)