You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
# 查询 method=put 且 code=200 的请求量SELECT*from http_requests_total WHERE code=”200” AND method=”put” AND created_at BETWEEN 1495435700AND1495435710;
# 查询 handler=prometheus 且 method=post 的请求量SELECT*from http_requests_total WHERE handler=”prometheus” AND method=”post” AND created_at BETWEEN 1495435700AND1495435710;
# 查询 instance=10.59.8.110 且 handler 以 query 开头 的请求量SELECT*from http_requests_total WHERE handler=”query” AND instance=”10.59.8.110” AND created_at BETWEEN 1495435700AND1495435710;
# 聚合 url="/home" 的数据
sum(increase(credit_insight_spl_id_all_pv{url="/home"}[1d])) by (url)
# 得出结果:
credit_insight_spl_id_all_pv{url="/home"} 899 # 所有 channel 中 /home 页访问量累加值
# 聚合所有的 url 则可以这样写:
sum(increase(credit_insight_spl_id_all_pv{}[1d])) by (url)
# 得出结果:
credit_insight_spl_id_all_pv{url="/home"} 899
credit_insight_spl_id_all_pv{url="/error"} 7
# 等价于 mysql
SELECT url, COUNT(*) AS total FROM credit_insight_spl_id_all_pv
WHERE create_time between <now() - 1d> and <now()>
GROUP BY url;
指标时序曲线
以上的所有例子的查询数值,其实都是最近时间点的数值,
而我们更关注的是一个时间段的数值变化。
要实现这个原理也很简单,只需要在历史的每个时间点都执行一次指标查询,
# 假如今天7号
# 6号到7号的一天访问量
sum(increase(credit_insight_spl_id_all_pv{}[1d] )) by (url)
# 5号到6号的一天访问量 offset 1d
sum(increase(credit_insight_spl_id_all_pv{}[1d] offset 1d)) by (url)
# 4号到5号的一天访问量
sum(increase(credit_insight_spl_id_all_pv{}[1d] offset 2d)) by (url)
而 Prometheus 已经内置了时间段查询功能,并对此优化处理。
可通过 /api/v1/query_range 接口进行查询,获的 grpah:
Prometheus 查询瓶颈
数据存储:
指标数据有 “Writes are vertical,reads are horizontal” 的(垂直写,水平读)模式:
“Writes are vertical,reads are horizontal” 的意思是 tsdb 通常按固定的时间间隔收集指标并写入,会 “垂直” 地写入最近所有时间序列的数据,而读取操作往往面向一定时间范围的一个或多个时间序列,“横向” 地跨越时间进行查询
但如果搜的是过去 90m 的数据,163698 * 90 * 4 = 58931280,超过了 5000w,你就发现数据请求异常: Error executing query: query processing would load too many samples into memory in query execution
所以,目测可得一个图的查询时序点数量公式是:total = n * time / step, time 和 step 的时间单位必须一致,total 必须不超过 5000w。
反推一下得出,time < 5000w / n * step 。要扩大搜索时间范围,增大 step ,或者降低 n 即可做到。
step 不变, 降低 n 【指定label值可减少搜索条件的结果数】 : credit_insight_spl_id_all_pv{systemType="Android", systemVersion="10"},n = 18955
增大 step 到 30s, n 不变:
当然,一般情况下,我们的 n 值只有几百,而 step 基本是大于 60s 的,所以一般情况下都能查询 2 个多月以上的数据图。
为什么需要指标监控告警
一个复杂的应用,往往由很多个模块组成,而且往往会存在各种各样奇奇怪怪的使用场景,谁也不能保证自己维护的服务永远不会出问题,等用户投诉才发现问题再去处理问题就为时已晚,损失已无法挽回。
所以,通过数据指标来衡量一个服务的稳定性和处理效率,是否正常运作,监控指标曲线的状态,指标出现异常时及时主动告警,这一套工具就十分重要。
常见的一些指标,包括但不限于:
举个例子,假如一个服务:
又或者一个前端单页面应用:
这到底是人性的扭曲还是道德的沦丧一旦应用存在某些缺陷导致这些问题,通过服务日志,很难直观快速地察觉到这些指标的变化波动。
而对于前端,则很可能根本无法感知到用户的行为,只能通过埋点进行一定程度地监控。
通过监控和告警手段可以有效地覆盖了「发现」和「定位」问题,从而更有效率地排查和解决问题。
指标监控系统:Prometheus
Prometheus 是一个开源的服务监控系统和时间序列数据库。
工作流可以简化为:
具体的架构设计如下:
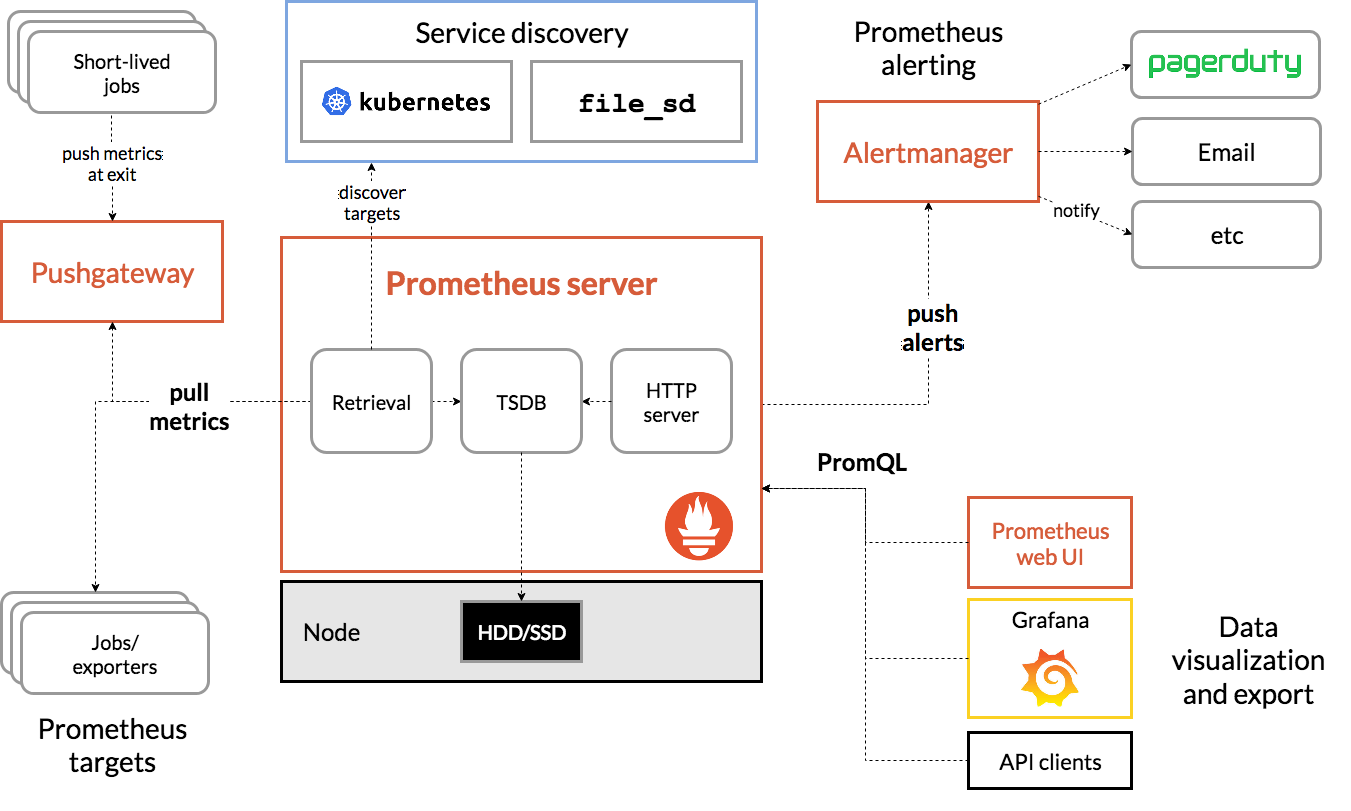
为什么不用 mysql 存储?
Prometheus 用的是自己设计的时序数据库(TSDB),那么为什么不用我们更加熟悉,更加常用的 mysql, 或者其他关系型数据库呢?
假设需要监控 WebServerA 每个API的请求量为例,需要监控的维度包括:服务名(job)、实例IP(instance)、API名(handler)、方法(method)、返回码(code)、请求量(value)。
如果以SQL为例,演示常见的查询操作:
通过以上示例可以看出,在常用查询和统计方面,日常监控多用于根据监控的维度进行查询与时间进行组合查询。如果监控100个服务,平均每个服务部署10个实例,每个服务有20个API,4个方法,30秒收集一次数据,保留60天。那么总数据条数为:
100(服务)* 10(实例)* 20(API)* 4(方法)* 86400(1天秒数)* 60(天) / 30(秒)= 138.24 亿条数据,写入、存储、查询如此量级的数据是不可能在Mysql类的关系数据库上完成的。 因此 Prometheus 使用 TSDB 作为 存储引擎。时序数据库(Time Series Database/TSDB)
时序数据库主要用于指处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时序数据。
对于 prometheus 来说,每个时序点结构如下:
假如用传统的关系型数据库来表示时序数据,就是以下结构:
__metric_name__指标 request_total{path="/home"} 在 2020-10-01 00:01:00 时的 qps = (160 - 100)/60 = 1 , 同理,
指标 request_total{path="/error"} 在 2020-10-01 00:01:00 时的 qps = 1/60
相比于 MySQL,时序数据库核心在于时序,其查询时间相关的数据消耗的资源相对较低,效率相对较高,而恰好指标监控数据带有明显的时序特性,所以采用时序数据库作为存储层
数据类型
nodejs 指标采集与数据拉取
/metrics的controller/metrics接口,获得当前数据快照
promQL
promQL 是 prometheus 的查询语言,语法十分简单
基本查询
查询指标最新的值:
区间时间段查询
查询过去一分钟内的数据
时间偏移查询
查询一个小时前的数据。
promQL 查询函数
根据以上的查询语法,我们可以简单组合出一些指标数据:
例如,查询最近一天内的 /home 页请求数
那么实际上面这个写法很明显比较不简洁,我们可使用内置 increase 函数来替换:
除了 increase 外,还有很多其他好用的函数,例如,
rate 函数计算 QPS
指标聚合查询
除了上述基础查询外,我们可能还需要聚合查询
假如我们有以下数据指标:
将所有指标数据以某个维度进行聚合查询时,例如:查询 url="/home" 最近一天的访问量,channel 是 none还是mepage 的 /home 访问量都包括在内。
我们理所当然地会写出:
但实际上我们会得出这样的两条指标结果:
并非我们预期中的:
而要是我们想要得到这样的聚合查询结果,就需要用到 sum by
指标时序曲线
以上的所有例子的查询数值,其实都是最近时间点的数值,
而我们更关注的是一个时间段的数值变化。
要实现这个原理也很简单,只需要在历史的每个时间点都执行一次指标查询,
而 Prometheus 已经内置了时间段查询功能,并对此优化处理。
可通过

/api/v1/query_range接口进行查询,获的 grpah:Prometheus 查询瓶颈
而 Prometheus 的默认查询 sample 上限是 5000w
所以,如果指标的时序图数量过大,允许查询的时间区间相对就会较小了。
一个图表查询时序数量的影响因素有 3 个,分别是:
以

credit_insight_spl_id_all_pv指标为例,该指标总共大约有 n = 163698 种时序,假如 step = 15s,如果搜索该指标过去 time = 60m 的全部时序图,那么,需要搜索的例子要
163698 * 60 * (60/15) = 39287520,将近 4kw,是可以搜出来的。但如果搜的是过去 90m 的数据,

163698 * 90 * 4 = 58931280,超过了 5000w,你就发现数据请求异常:Error executing query: query processing would load too many samples into memory in query execution所以,目测可得一个图的查询时序点数量公式是:total = n * time / step, time 和 step 的时间单位必须一致,total 必须不超过 5000w。
反推一下得出,time < 5000w / n * step 。要扩大搜索时间范围,增大 step ,或者降低 n 即可做到。
step 不变, 降低 n 【指定label值可减少搜索条件的结果数】 :

credit_insight_spl_id_all_pv{systemType="Android", systemVersion="10"},n = 18955增大 step 到 30s, n 不变:

当然,一般情况下,我们的 n 值只有几百,而 step 基本是大于 60s 的,所以一般情况下都能查询 2 个多月以上的数据图。
可视化平台: Grafana
grafana 是一个开源的,高度可配置的数据图表分析,监控,告警的平台,也是一款前端可视化的产品。
自定义图表
grafana 内置提供多种图表模板,具体是以下类型:
Prometheus 作为数据源的情况下,一般用的 graph 类型画时序图比较多。
对于一些基础的数据大盘监控,这些图表类型已经足够满足我们的需求。
但对于复杂的需求,这些类型无法满足我们的需要时,我们安装 pannel 插件,来更新可用的图表类型,也可以根据官方文档 build a panel plugin 开发自己的前端图表 panel。
图表配置
在时序图表配置场景下,我们需要核心关注配置的有:
一条曲线的数据点数量 = 图表时长 / 采样间隔。例如查看最近24小时的数据,采样 间隔5min,数据点数量=24*60/5=288。
采集间隔时间越短,采样率越大,图表数据量越大,曲线越平滑。 采集间隔默认自动计算生成,也可以自定义配置。
以QPS为例,图表上每个时间点的数据的意义是:在这时间点上,过去n秒间的访问量。
从上图可以看到,
自定义变量
为了实现一些常用的筛选过滤场景,grafana 提供了变量功能
变量配置:变量配置有多种方式(Type),可以自定义选项,也可以根据prometheus 指标的 label 动态拉取。

变量使用:变量通过

$xxx形式去引用。告警
除了 Prometheus 本身可以配置告警表达式之外:
grafana 也可以配置告警:
数据源
Prometheus 通常用于后端应用的指标数据实时上报,主要用于异常告警,问题排查,所以数据存在时效性,我们不会关注几个月前的一个已经被排查并 fixed 的指标异常波动告警。
但是,要是我们将 Prometheus 用于业务指标监控,那么我们可能会关注更久远的数据。
例如我们可能想要看过去一个季度的环比同比增长,用 Prometheus 作为数据源就不合适,因为 Prometheus 是时序数据库,更多关注实时数据,数据量大,当前数据保存的时效设定只有 3 个月。
那么这个时候可能我们要维护一个长期的统计数据,可能就需要存储在 mysql 或者其他存储方式。
grafana 不是 Prometheus 的专属产品,还支持多种数据源,包括但不限于:
如果没有自己需要的数据源配置,还可以安装 REST API Datasource Plugin, 通过 http 接口查询作为数据源
总结
了解 grafana 的高度可配置性设计后,有值得思考的几点:
等等这些,其实都是值得我们去思考的。
此外,Prometheus 和 grafana 都有些进阶的玩法,大家有兴趣也可以去探索下。
参考文章
The text was updated successfully, but these errors were encountered: