Fine-Tuning with a small dataset #296
Comments
|
@OscarVanL Hi, great idea :D. I have some guidances for you to customized voice via fine-tuning bellow:
@ZDisket can you share some ur experiences when finetune a voice from female->male in ur small dataset :D . |
|
@OscarVanL @dathudeptrai |
|
Wow, thank you both for the detailed replies. That's really helpful! @dathudeptrai Thank you for offering to make a PR to help train selected layers. @ZDisket It's great to hear your success even with a limited dataset. Fortunately we have much more than 80 seconds of audio even in the worst cases. Could you explain the idea of a universal vocoder to me? How is it possible to get a customised voice using a universal vocoder without fine tuning? This is all very new to me, but very exciting. |
|
@OscarVanL Conventional text2speech works with a text2mel model, which converts text to spectrograms, and vocoder, which turns spectrograms into audio. Training a vocoder on many, many different voices can achieve a "universal vocoder" which can adapt to almost any speaker. I know the owner of vo.codes uses a (MelGAN) universal vocoder. You'll still have to finetune the text2mel though. |
|
Thank you for the explanation. So my understanding is that I will have to train a FastSpeech2 text2mel model to create patient-specific mel spectrograms. This will involve me taking a LJSpeech pretrained model, then fine-tuning as described by @dathudeptrai with patient voice data. After this, are there pre-trained MelGAN Universal Vocoders available to download that have already been trained on many voices, or is this something I would need to do myself? Finally, are Universal Vocoders tied to a specific text2mel architecture (Tacotron, FastSpeech, etc), or can a Universal Vocoder take any mel spectrogram generated by any text2mel architecture? |
There are three MelGANs: regular MelGAN (lowest quality), ditto + STFT loss (somewhat better), and Multi-Band (best quality and faster inference), you can hear the differences in the demo page. There's also ParallelWaveGAN, but it's too slow on CPU to consider. As for pretrained models, there are none trained natively with this repo on large multispeaker datasets(I have two trained on about 200 speakers, one 32KHz and other 48KHz, but it doesn't work well outside of them), but there are notebooks to convert trained models from kan-bayashi's repo: https://github.com/kan-bayashi/ParallelWaveGAN (which has a lot) to this one's. I forgot where they were, so you'll have to ask @dathudeptrai.
A mel spectrogram is a mel spectrogram no matter where it comes from, so yes, as long as the text2mel and vocoder's data is processed the same (same normalization method, mel frequency range, etc). |
|
Thank you once again for helping with my noob questions! I'll definitely check out that resource with trained models. |
|
that's interesting subject, |
|
@OscarVanL i just make a PR for custom trainable layers here (#299). @Zak-SA You can try to train universal vocoder or load the weight from pretrained model list then training as normal (follow README.). |
|
Amazing, thank you to both of you for going above and beyond to help! A few more questions as I didn't see any documentation on preparing the dataset, I'm looking to prepare some data for fine-tuning. Do I need to strip grammar from the text? Eg: ()`';"- Are there any other similar cases I should consider when preparing the transcriptions? Does the audio filetype matter? I have 44100Hz Signed 16-bit PCM WAVs. (Edit: These files produced no errors during preprocessing/normalisation, but they should be mono, not stereo) |
|
Some early observations going through the steps in
|
|
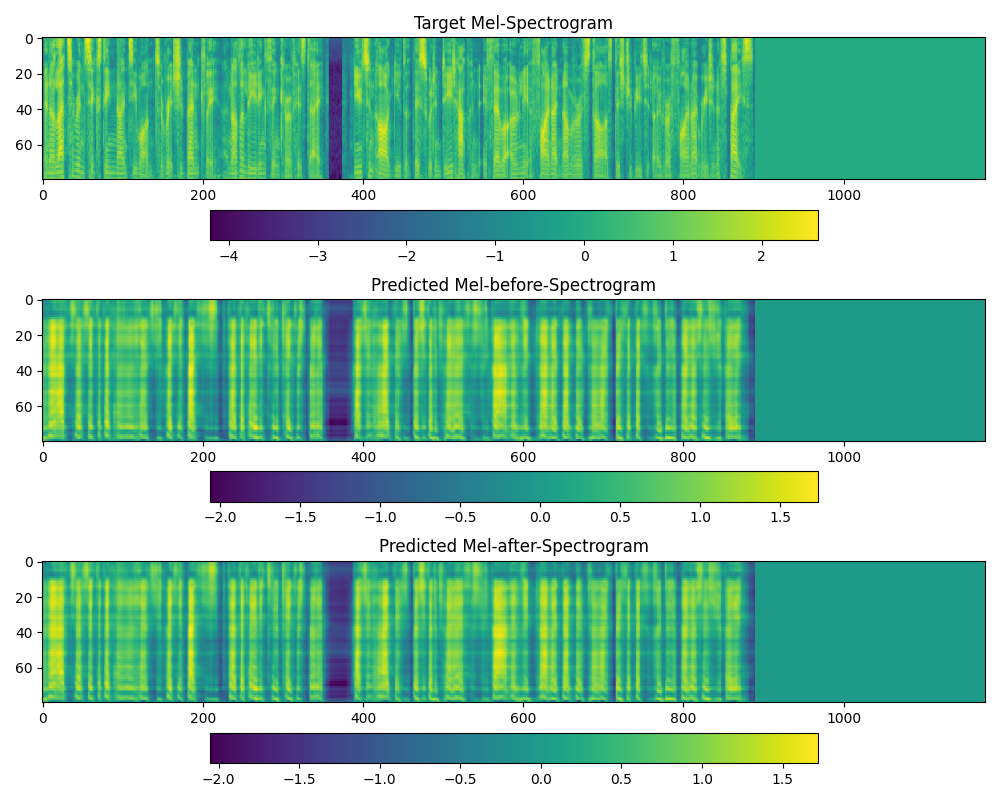
Hi, I've begun fine-tuning with the guidance given by @dathudeptrai :) I've taken the LJSpeech pretrained model "fastspeech2.v1" to fine-tune. I took the Here you can see the TensorBoard results for training the embedding layers... Using the At 5000 steps: audio, spectogram At 15000 steps: audio, spectogram At 80000 steps: audio, spectogram Obviously, this sounds bad because I have only trained embedding layers. I would now like to add some FC layers at the end, as you suggested, but am not sure how I do this. Based on my tensorboard results, how many steps do you think I should tune the embedding layers before I stop and begin to train the FC layers? Do you advise making any changes to the hyperparameters in |

|
@OscarVanL can you try to train all network ?, |
|
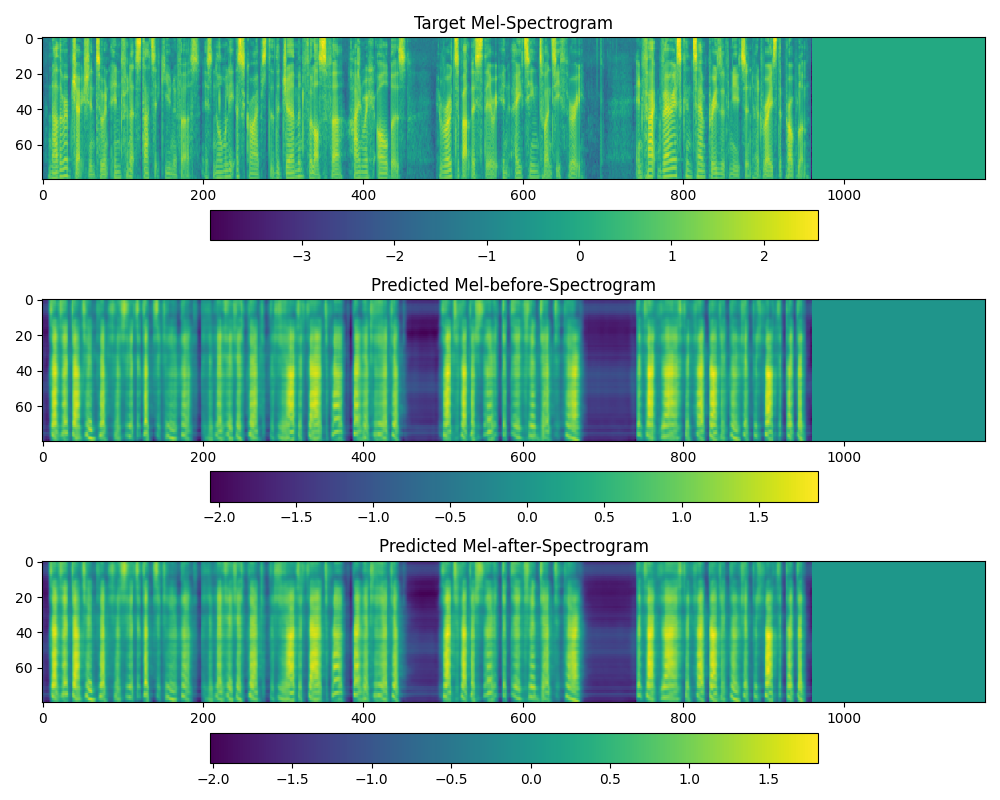
@dathudeptrai Here's my tensorboard with 120k steps with |

ok i can understand what is the problem with ur dataset :D. I want you try to train the model with
I do not know if it work or not because the pretrained u are using is charactor-based, you should find phoneme pretrained then you do not need fine-tune phoneme embeddings. @ZDisket do you have any FS2 phoneme pretrained ? |
|
Ok I will try that now 👍 Thanks! |
after that, maybe you should try hop_size is 240 for 24k audio and try again. MFA uses 10ms to calculate duration, so the hop_size should be 240 to match exactly with the duration extracted from MFA, if we use 300 or 256 then we should round the duration and this duration is not precise :D. |
I wanted to ask a question about mfa duration... My recordings are 44100Hz. For |
I think it is 44100 but we may need ask @machineko |
|
Either methods should works u just need to later change sample rate for calculation in preprocessing ( downsampling first should works better but results shouldnt be noticable as small diff in durations shouldnt affect fs2 according to paper ) |
1 vote for downsampling first :))) @OscarVanL |
|
I agree. I think downsampling first will avoid any confusion or mistakes. |
|
@dathudeptrai I have two phoneme LJSpeeches, 22KHz and (upsampled) 24KHz with LibriTTS preprocessing settings like in kan-bayashi repo. But the phoneme IDs might differ |
|
OK, I have downsampled to 24000Hz, redone all of the mfa extraction, preprocessing, normalisation, and changed |
|
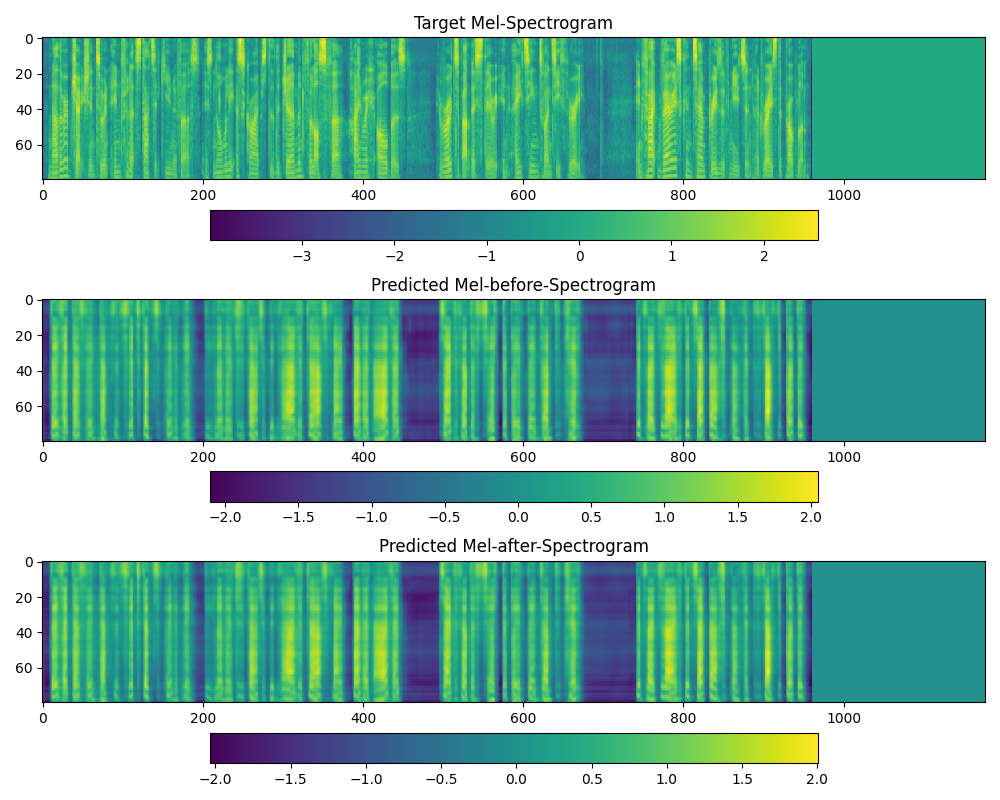
@dathudeptrai Here's my TensorBoard for that last attempt. |

the model overfits too much, in this case, i think you should pretrained ur model by libriTTS dataset then you do not need retrained embeddings layers. Seems in ur validation data, there are many words/phoneme that the model has not seen in the training data (you can check this statement), that is why the valid loss increase why training loss decrease. |
|
Yes that would probably help. I will have a look at which British speaker corpuses are available. I see "M-AILABS Queen's English corpus", however the Queen's English likely does not represent how normal British people actually speak 😆 |
|
Hi there, quick question about your speech inference. Where do you pass in the speaker_id? I am going through the colab and fastspeech2 notebooks and I can't see reference to it anywhere... |
|
@GavinStein1 mel_before, mel_outputs, duration_outputs, _, _ = fastspeech2.inference(
input_ids=tf.expand_dims(tf.convert_to_tensor(input_ids, dtype=tf.int32), 0),
speaker_ids=tf.convert_to_tensor([0], dtype=tf.int32),
speed_ratios=tf.convert_to_tensor([1], dtype=tf.float32),
f0_ratios =tf.convert_to_tensor([1.0], dtype=tf.float32),
energy_ratios =tf.convert_to_tensor([1.0], dtype=tf.float32)
)See the part speaker_ids=tf.convert_to_tensor([0], dtype=tf.int32), that number is changed to the speaker you desire. After processing your dataset (assuming you use LibriTTS), you will see |
I see what you are referring to, however when processing libriTTS, this |
|
Maybe you're looking in the wrong folder, the one in Instead, when you run the preprocessing stages, a new |
Now I feel embarrassed for not seeing that earlier... Thank you |
|
Happens to the best of us :) |
@ronggong I tried tuning only these layers, but now the model does not converge. After 3 hours there is no improvement and the model still sounds American. (red is tuning job, grey is the model I am tuning from 110k steps) I think I will retrain the LJSpeech model with a mixture of LibriTTS and some British speaker dataset (as machineko said), hopefully, this will help it generalise to my British speaker better. |

{kind=link}
{kind=link}
{kind=link}
@machineko's suggestion to use more British speakers was a great suggestion, because it led me to find LibriVox accents table and British Readers on LibriVox. As LibriTTS is based on LibriVox, I found nearly all these speakers within the Training on just these speakers did not give a great FS2 model, I think 17 hours may be too little, so I'll add in a 50:50 split of British and American LibriTTS speakers to match the good results I had with 34 hours of speech. Hopefully, this will make my speaker sound much better. |
|
I am really happy with the Britsh models I am getting from the dataset, I feel like I am getting some models I am really satisfied with now! 🤟 Fine-tuning the vocoder definitely helped reduce the buzzing, but didn't eliminate it, but at this point, I am happy with the results. It took 3 days 9 hours to reach 1M steps though 😴 Now to fine-tune it all over again with my British speakers 😅 |
@OscarVanL Well done! Great work. Are you in a position to share or publish your base British dataset, or trained model please? |
|
@vocajon I probably should not share my model because of academic integrity (this is for a University project), but I was just writing a Blog post about compiling the British speaker corpus I used. It is based entirely on speakers taken from the LibriTTS dataset, so in theory, it should be open source but I must check this :) I will let you know once it's published 😄 |
|
Here's the blog post. I created a repo with my LibriTTS British dataset. I only used the Edit: It looks like GitHub LFS is unsuitable for this purpose as it imposes bandwidth limits. I will have to look for alternatives. |
|
Great, thank you very much. Just curious, the purpose for your work is for patients before losing their voices right? What led to you excluding the Welsh/Scottish/Irish accents? You think it is unlikely any will appear as a patient in England? Or you think it is better to maintain 4 models (if enough data can be found for the others) and tune using the closest model? |
At the moment it's only a proof-of-concept phase. In regards to 1 vs 4 models, I suppose it would be a matter of experimenting to see what works. I have been training with a 50:50 split of English and American accents and it still allows me to clone a British voice well, so who knows, maybe a single mixed-accent model would work if there was enough of each accent in the training data. |
|
Hi @OscarVanL, Can I ask what model you used for pretraining? and did you end up training all layers or just some specific ones? and what processor did you end up using for inference after your PR? |
|
@GavinStein1 I trained all layers. I used this processor: You could also use the |
|
So if the processor is used for only the phoneme ids, how do you know what speaker id is your one when it is mixed in with libritts speakers? also how many speakers/hours of speaking did you find worked best for you? Edit: When I use that fastspeech.v1 model as a pretrained model, I cannot load weights on the following layers due to mismatch in number of weights:
Did you get this issue? and did you just ignore it as you wanted to retrain those layers anyway? |
Sorry if my reply was confusing, I meant the Processor only uses the phoneme IDs from the mapper json (as the processor is used for mapping text to phoneme IDs). You will of course need to also check your mapping for the correct speaker ID at inference :) I used 120 speakers, with 17 hours of British speakers and 17 hours of American speakers. My results were best when I picked the top 100 speakers by duration in the I got these errors loading the layers too, I also asked about this problem but got no reply. I just ignored the error and the model trained fine, but maybe you should ask one of the maintainers about this. |
you can load the weights like this: model.load_weights(path, by_name=True, skip_mismatch=True). f0/energy/duration must be retrain. |
|
I'm closing this as all the help I received helped me train a good model! 😄 To give a tl;dr of this thread, I found the best way to tune with a small speaker dataset is to merge it with a larger multi-speaker dataset (I used LibriTTS) and pass in the speaker ID at inference for the speaker I wished to clone. Some other tricks that helped:
|
|
Hi, thanks for this extremely useful thread. I am very new to TTS and want to train on a small dataset as discussed above. I had a few clarifications (they might be very basic/naive).
I wanted to know how do you combine FastSpeech2 with MB MelGAN. What is the default vocoder being used in the examples file, and how to change it. Can you share a pipeline script if possible @OscarVanL? Thanks a lot. |
|
@OscarVanL thanks for this great thread! You mentioned the aim of your project was to deploy onto low-end hardware, did you end up doing this? If so, what method did you use and how many mb was the model in the end? |
Hello!
I'm trying to evaluate ways to achieve TTS for individuals that have lost their ability to speak, the idea is to allow them to regain speech via TTS but using the voice they had prior to losing their voice. This could happen from various causes such as cancer of the larynx, motor neurone disease, etc.
These patients have recorded voice banks, a small dataset of phrases recorded prior to losing their ability to speak.
Conceptually, I wanted to take a pre-trained model and fine-tune it with the individual's voice bank data.
I'd love some guidance.
There are a few constraints:
I'd love your guidance on the steps required to achieve this, and any recommendations on which choices would give good results...
Do you have any tutorials or examples that show how to achieve a customised voice via fine-tuning?
The text was updated successfully, but these errors were encountered: