-
任务简介
- 根据给定的术语-定义对,从文本中抽取相关定义,包含三个子任务,(1)句子分类;(2)序列标注;(3)关系抽取。
- 官网:https://competitions.codalab.org/competitions/22759#learn_the_details
-
时间:2019.8~2020.3
-
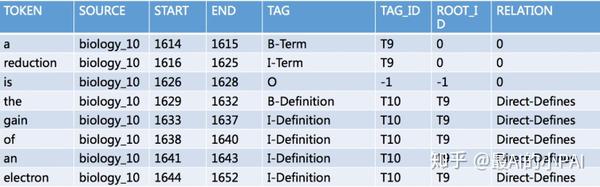
数据示例
- 句子分类:给定一个句子,判断该句子里是否包含定义
- 序列标注:根据给定的tag schema用BIO标记每个词。已知前四列,预测第五列Tag。
- 关系抽取:给定relation schema和序列标注结果,标记出tag之间的关系。已知前六列信息,预测Root_ID和relation。
- Token:句子里的单词
- Source:标识当前句子来源于哪篇文章
- Start/End:单词在文章中的起始位置
- Tag:tag schema中的标签,符合BIO标注格式
- Tag_ID:Tag标签的唯一标识,如果是O标签,则为-1
- Root_ID:当前Tag_ID所关联的Tag_ID
- Relation:relation schema中的关系
-
数据说明
数据总共有215个文件,包含26552个句子
train dev test 下载 80 68 67 √ -
竞赛方案
task1 方案 / rank F1 说明 代码 5 0.8444 Multi-task BERT × 6 0.8304 RoBERTa + Stochastic Weight Averaging × 12 0.8077 Joint classification and sequence labeling pre-trained model with MLP and CRF layer × 16 0.8007 BERT with two-step fine tuning × 18 0.7971 BERT with BiLSTM + attention × 26 0.7885 XLNet × 32 0.7772 RoBERTa with finetuning √ 40 0.7593 BERT with fine-tuned language model √ 41 0.7555 * √ 46 0.7109 FastText and ELMo embeddings with RNN ensemble × 47 0.6851 Concatenated GloVe and on-the-fly POS embeddings with BiLSTM and 1D-Conv + MaxPool layers × task2 方案 / rank Macro-F1 说明 代码 23 0.5233 BERT × 27 0.4968 CRF tagger √ 34 0.4589 XLNet - large × 37 0.4398 RoBERTa + CRF with finetuning √ 46 0.2577 * √ task3 方案 / rank Macro-F1 说明 代码 1(知乎 、paper ) 1.0 BERT + hand crafted rules × 4 0.9943 Random Forest × -
推荐资料