[TOC]
这是一份来自厦门人才网的企业招聘数据,采集日期为 2021-01-14,总计 100,077 条记录,大小为 122 M,包含 19 个字段。
使用 pandas 对数据进行清洗,主要包括:去重、缺失值填充、格式化、计算冗余字段。
# 数据重复处理: 删除重复值
# print(data[data.duplicated()])
data.drop_duplicates(inplace=True)
data.reset_index(drop=True, inplace=True)
# 缺失值查看、处理:
data.isnull().sum()
# 招聘人数处理:缺失值填 1 ,一般是一人; 若干人当成 3人
data['num'].unique()
data['num'].fillna(1, inplace=True)
data['num'].replace('若干', 3, inplace=True)
# 年龄要求:缺失值填 无限;格式化
data['age'].unique()
data['age'].fillna('不限', inplace=True)
data['age'] = data['age'].apply(lambda x: x.replace('岁至', '-').replace('岁', ''))
# 语言要求: 忽视精通程度,格式化
data['lang'].unique()
data['lang'].fillna('不限', inplace=True)
data['lang'] = data['lang'].apply(lambda x: x.split('水平')[0] )
data['lang'].replace('其他', '不限', inplace=True)
# 月薪: 格式化。根据一般经验取低值,比如 5000-6000, 取 5000
data['salary'].unique()
data['salary'] = data['salary'].apply(lambda x: x.replace('参考月薪: ', '') if '参考月薪: ' in str(x) else x)
data['salary'] = data['salary'].apply(lambda x: x.split('-', 1)[0] if '-' in str(x) else x )
data['salary'].fillna('0', inplace=True)
# 其它岗位说明:缺失值填无
data.fillna('其他', inplace=True)
# 工作年限格式化
def jobage_clean(x):
if x in ['应届生', '不限']:
return x
elif re.findall('\d+年', x):
return re.findall('(\d+)年', x)[0]
elif '年' in x:
x = re.findall('\S{1,2}年', x)[0]
x = re.sub('厂|验|年|,', '', x)
digit_map = {
'一': 1, '二': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十':10,
'十一': 11, '十二': 12, '十三': 13, '十四': 14, '十五': 15, '十六': 16, '两':2
}
return digit_map.get(x, x)
return '其它工作经验'
data['jobage'].unique()
data['jobage'] = data['jobage'].apply(jobage_clean)
# 性别格式化
data['sex'].unique()
data['sex'].replace('无', '不限', inplace=True)
# 工作类型格式化
data['job_type'].unique()
data['job_type'].replace('毕业生见习', '实习', inplace=True)
# 学历格式化
data['education'].unique()
data['education'] = data['education'].apply(lambda x: x[:2])
# 公司类型 格式化
def company_type_clean(x):
if len(x) > 100 or '其他' in x:
return '其他'
elif re.findall('私营|民营', x):
return '民营/私营'
elif re.findall('外资|外企代表处', x):
return '外资'
elif re.findall('合资', x):
return '合资'
return x
data['company_type'].unique()
data['company_type'] = data['company_type'].apply(company_type_clean)
# 行业 格式化。多个行业,取第一个并简单归类
def industry_clean(x):
if len(x) > 100 or '其他' in x:
return '其他'
industry_map = {
'IT互联网': '互联网|计算机|网络游戏', '房地产': '房地产', '电子技术': '电子技术', '建筑': '建筑|装潢',
'教育培训': '教育|培训', '批发零售': '批发|零售', '金融': '金融|银行|保险', '住宿餐饮': '餐饮|酒店|食品',
'农林牧渔': '农|林|牧|渔', '影视文娱': '影视|媒体|艺术|广告|公关|办公|娱乐', '医疗保健': '医疗|美容|制药',
'物流运输': '物流|运输', '电信通信': '电信|通信', '生活服务': '人力|中介'
}
for industry, keyword in industry_map.items():
if re.findall(keyword, x):
return industry
return x.split('、')[0].replace('/', '')
data['industry'].unique()
data['industry'] = data['industry'].apply(industry_clean)
# 工作时间格式化
data['worktime'].unique()
data['worktime_day'] = data['worktime'].apply(lambda x: x.split('小时')[0] if '小时' in x else 0)
data['worktime_week'] = data['worktime'].apply(lambda x: re.findall('\S*周', x)[0] if '周' in x else 0)
# 从工作要求中正则解析出:技能要求
data['skill'] = data['require'].apply(lambda x: '、'.join(re.findall('[a-zA-Z]+', x)))将清洗后的数据导入到 hive
CREATE TABLE `job`(
`position` string COMMENT '职位',
`num` string COMMENT '招聘人数',
`company` string COMMENT '公司',
`job_type` string COMMENT '职位类型',
`jobage` string COMMENT '工作年限',
`lang` string COMMENT '语言',
`age` string COMMENT '年龄',
`sex` string COMMENT '性别',
`education` string COMMENT '学历',
`workplace` string COMMENT '工作地点',
`worktime` string COMMENT '工作时间',
`salary` string COMMENT '薪资',
`welfare` string COMMENT '福利待遇',
`hr` string COMMENT '招聘人',
`phone` string COMMENT '联系电话',
`address` string COMMENT '联系地址',
`company_type` string COMMENT '公司类型',
`industry` string COMMENT '行业',
`require` string COMMENT '岗位要求',
`worktime_day` string COMMENT '工作时间(每天)',
`worktime_week` string COMMENT '工作时间(每周)',
`skill` string COMMENT '技能要求'
)
row format delimited
fields terminated by ','
lines terminated by '\n';
-- 加载数据
LOAD DATA INPATH '/tmp/job.csv' OVERWRITE INTO TABLE job;通过 hue 查看一下数据
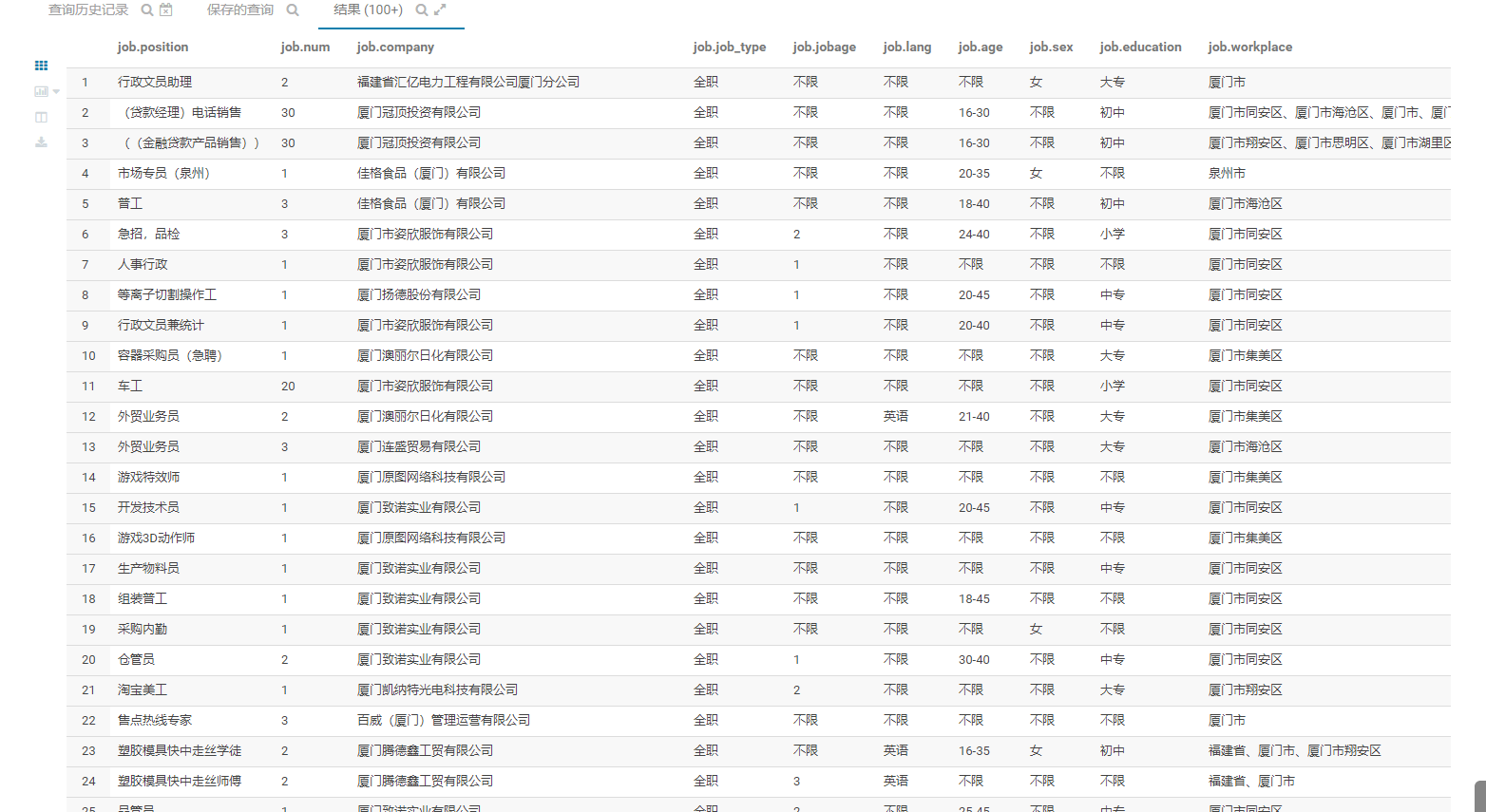
然后随便点击一条数据,可以看到,经过前面的清洗,现在的字段已经很好看了,后续的分析也会变得简单许多。
招聘企业数为 10093,在招的岗位数有 10 万个,总的招聘人数为 26 万人,平均工资为 5576 元。

各行业的招聘人数排行 TOP10 如下,可以看到 IT 互联网最缺人。
由于数据源的行业分类比较草率,很多公司的分类其实并不是很准确,所以这个结果仅供参考。

从招聘人数上来看,民营/私营的企业最缺人,事业单位的招聘人数最少。
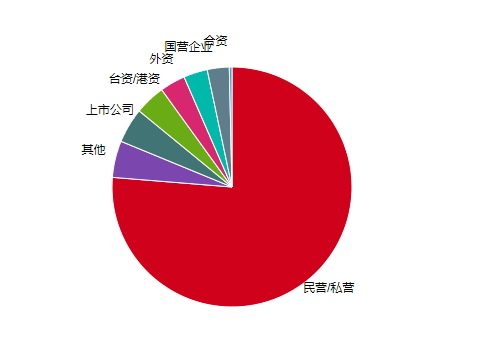
从薪资待遇来看,上市公司平均薪资最高 5983 元,而台资/港资则最少 4723 元。

最缺人的公司果然是人力资源公司,总的要招聘 2000 多个人,从详情来看,大多是代招一些流水线岗位。

平均薪资最高的公司 上海美莱投资管理有限公司 居然有 5 万多,一惊之下,查了下这家公司的招聘信息,可以看到该公司在招的都是高级岗,比如 集团片区总经理(副总裁级),这个岗位人数达到 20 人,岗位月薪 6 万,所以直接把平均薪资拉高了,而且工作地点也不在厦门。
由以上分析,可以得知根据招聘信息来推算平均工资,其实误差还是比较大的,仅供参考。


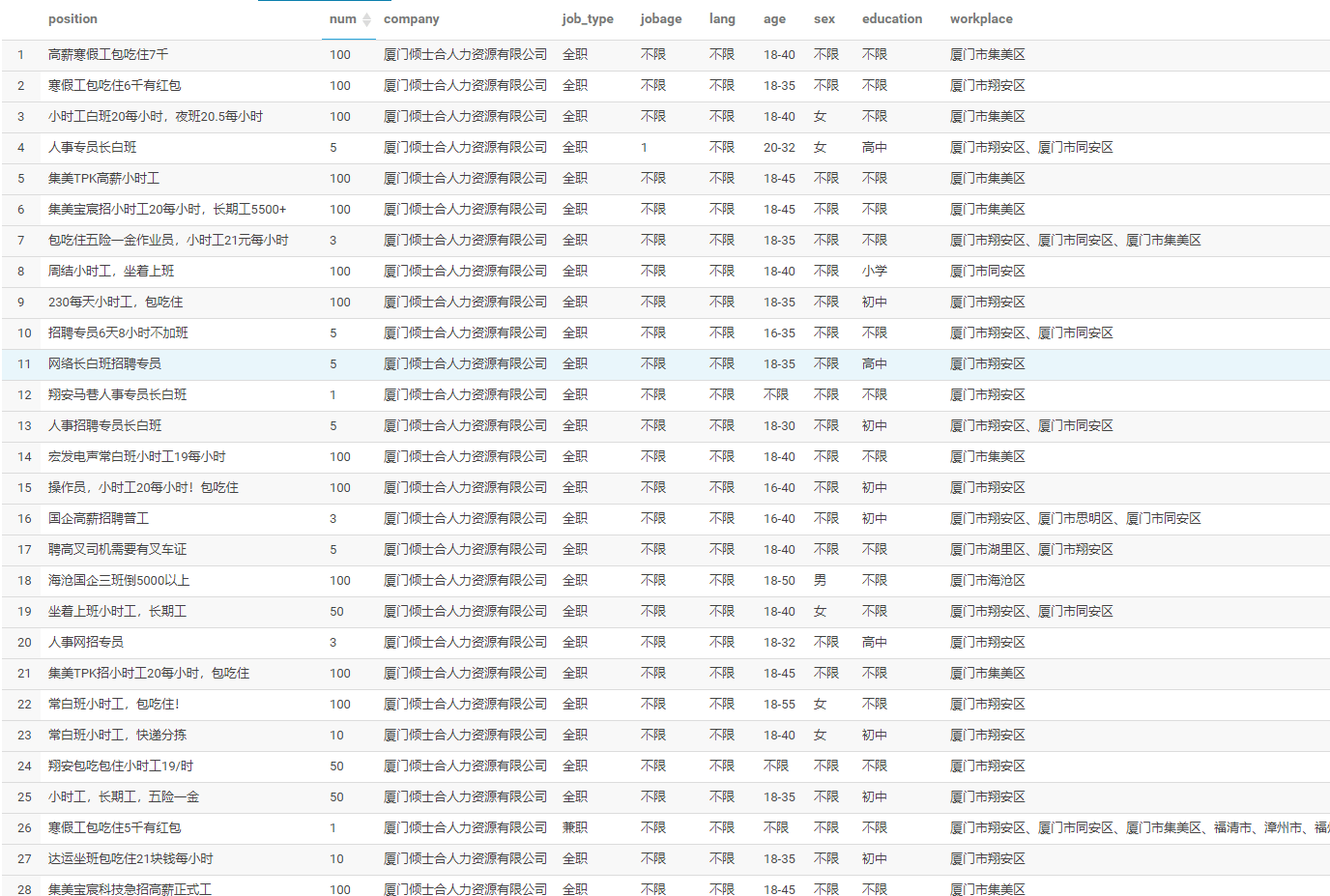
从每天工作时间占比 TOP 10 来看,大部分职位是 8 小时工作制,紧接着是 7.5 小时 和 7小时。还有一些每天上班时间要达到 12 小时,主要是 保安 和 普工 这类岗位。
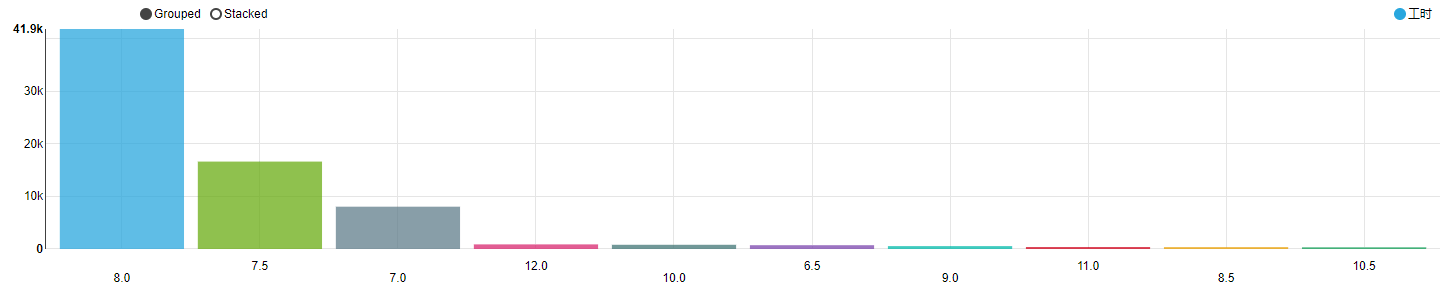
每周工作天数占比来看,大部分还是 5天/周的双休制,不过 6 天/周、5.5 天/周、大小周的占比也是相当高。
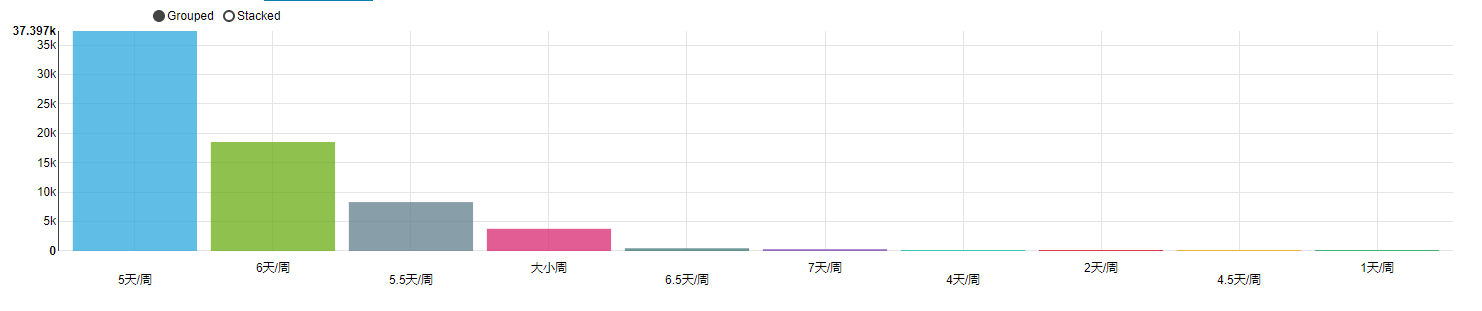
岗位数量的分布图,颜色越深代表数量越大,可以看到思明区的工作机会最多,其次是湖里、集美、同安、海沧、翔安。

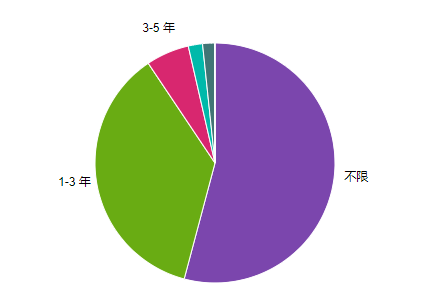
从岗位数量来看,一半以上的岗位对工作经验是没有要求的。在有经验要求的岗位里面,1-3 年工作经验的市场需求是最大的。
从平均工资来看,符合一般认知。工作经验越多,工资也越高,10 年以上的工作经验最高,平均工资为 13666 元;应届生最低,平均工资为 4587 元。
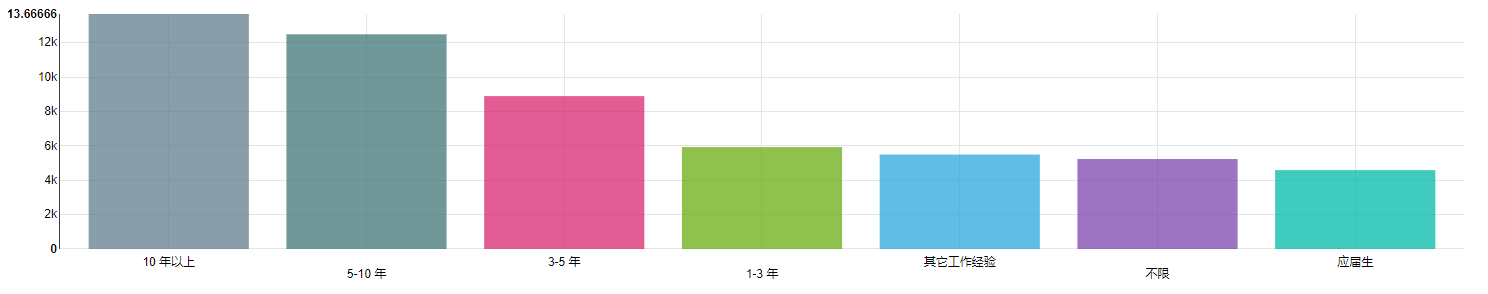
从岗位数来看,大部分岗位的学历要求为大专以上,换言之,在厦门,只要大专学历,就很好找工作了。
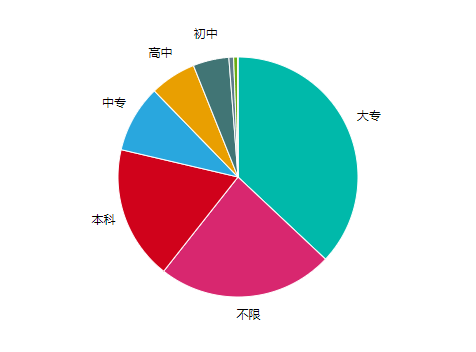
从平均工资来看,学历越高,工资越高,这也符合一般认知,谁说的读书无用论来着。
有趣的是,不限学历的平均工资居然排在了高中的前面,或许这是 九年义务教育的普及与大学扩招带来的内卷,在招聘方眼里,只有两大类:上过大学和没上过大学,从而导致大专以下的学历优势不再明显。

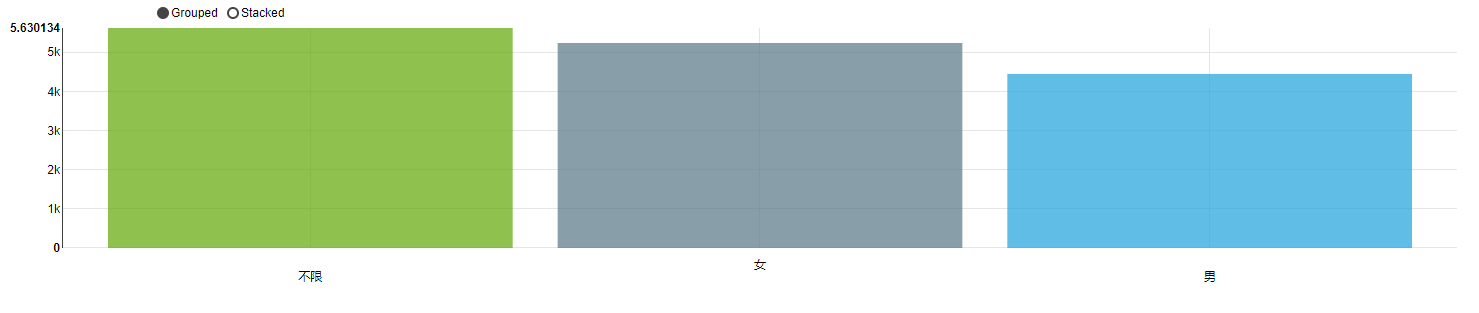
岗位数方面,有 6974 个岗位,明确要求性别为 女,仅有 575 个岗位要求性别为 男。
平均工资方面,女性岗位的平均工资为 5246 元,而男性则为 4454 元。
虽然绝大多数岗位都是不限制性别的,但是,不管是从岗位数量还是平均工资来看,在厦门,女性比男性似乎有更多的职场优势。
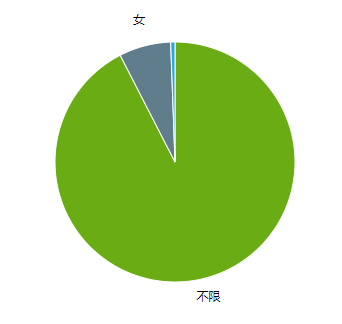
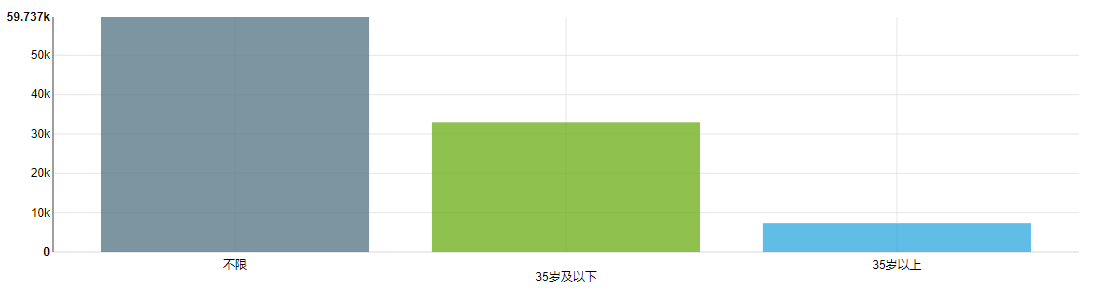
年龄要求一般有一个上限和下限,现在只考虑上限,并通过上限来分析一下,所谓 35 岁的危机。
岗位数量上来看,大多数岗位是不限制年龄的,有限制年龄的岗位里面,35 岁以后的岗位有 7327 个,35 岁及以下的岗位有 32967 个,
岗位数量上确实少了非常多。
从平均工资来看,35 岁以后的岗位 5095 元,35岁及以下的岗位 5489 元,薪资上少了 394 元。
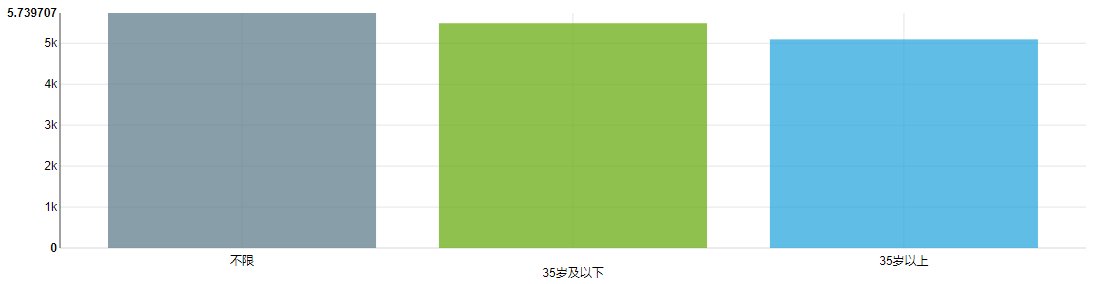
所以,单单考虑岗位的年龄上限,那么 35 岁以后的市场需求确实会变少。
但是,为什么会是这样的情况呢,个人认为,有可能是 35 岁 以后的职场人士,沉淀更多,进入了更高级的职位,更稳定,所以流动性比较低,自然市场上空出来的需求也会变少了,更不用说还有一部分人变成了创业者。
大部分岗位没有语言要求,在有语言要求的岗位里面,英语妥妥的是第一位。
值得一提的是,这边还有个闽南语,因为厦门地处闽南,本地的方言就是闽南语。
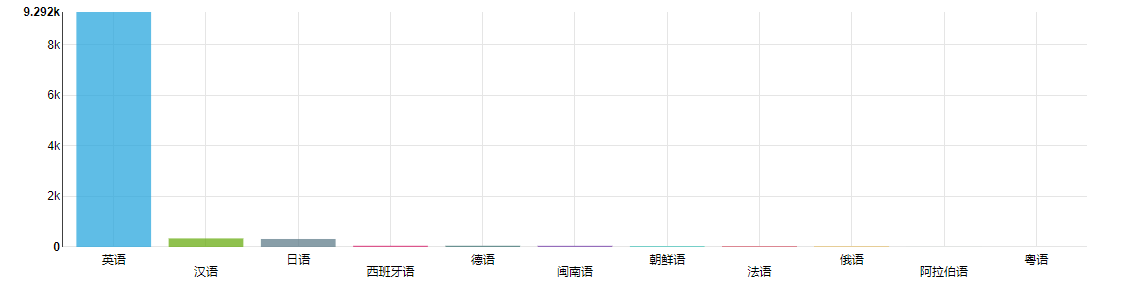
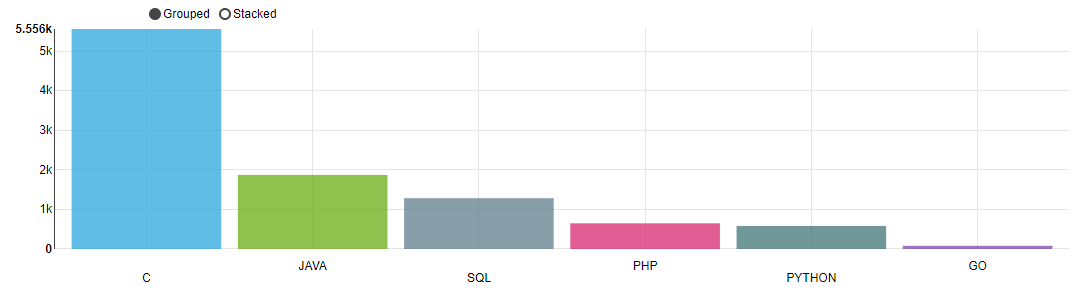
比较流行的编程语言里面,被岗位要求提到的次数排行如下 。可以看到,C 语言被提及的次数远大于其它语言,不亏是排行榜常年第一的语言。比较惊讶的是如今大火的 python 被提及的次数却很少,排在倒二。
这些语言的平均薪资排行,Python 最高为 8732 元。
我们知道影响工资待遇的因素有很多:学历、工作经验、年龄、招聘方的紧急程度、技能的稀缺性、行业的发展情况。。。等等。
所以,为了简化模型,就学历和工作经验两个维度进行模型训练,尝试做工资预测。
import pandas as pd
from sklearn.linear_model import LinearRegression
def predict(data, education):
"""
:param data: 训练数据
:param education: 学历
:return: 模型得分,10年工作预测
"""
train = data[data['education'] == education].to_numpy()
x = train[:, 1:2]
y = train[:, 2]
# model 训练
model = LinearRegression()
model.fit(x, y)
# model 预测
X = [[i] for i in range(11)]
return model.score(x, y), model.predict(X)
education_list = ['小学', '初中', '中专', '高中', '大专', '本科', '硕士', '博士']
data = pd.read_csv('train.csv')
scores, values = [], []
for education in education_list:
score, y = predict(data, education)
scores.append(score)
values.append(y)
result = pd.DataFrame()
result['学历'] = education_list
result['模型得分'] = scores
result['(1年经验)平均工资'] = [value[1] for value in values]
result['(3年经验)平均工资'] = [value[2] for value in values]
result['(5年经验)平均工资'] = [value[4] for value in values]
result['(10年经验)平均工资'] = [value[10] for value in values]
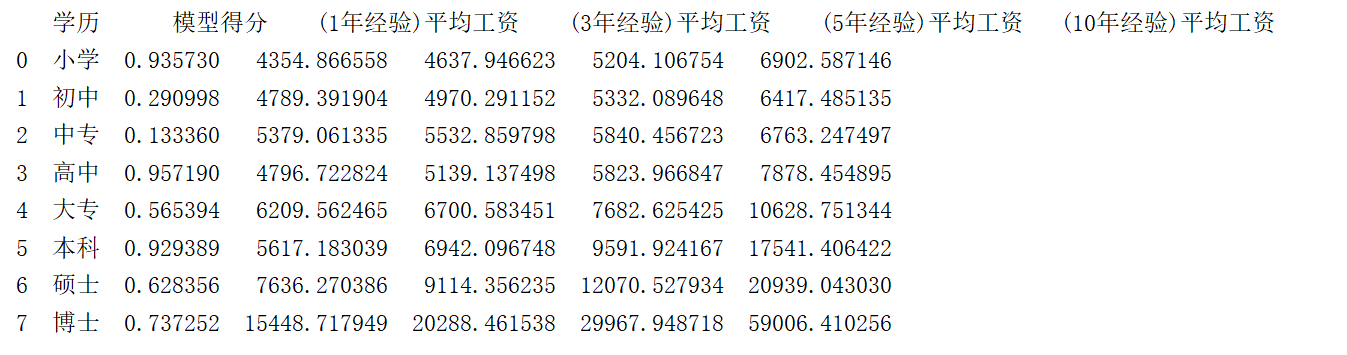
print(result)使用线性回归模型分学历进行预测,预测结果如下。