[TOC]
flink-sql 连接外部系统时,需要依赖特定的 jar 包,所以需要事先把这些 jar 包准备好。说明与下载入口
本项目使用到了以下的 jar 包 ,下载后直接放在了 flink/lib 里面。
需要注意的是 flink-sql 执行时,是转化为 flink-job 提交到集群执行的,所以 flink 集群的每一台机器都要添加以下的 jar 包。
| 外部 | 版本 | jar |
|---|---|---|
| kafka | 4.1 | flink-sql-connector-kafka_2.11-1.10.2.jar flink-json-1.10.2-sql-jar.jar |
| elasticsearch | 7.6 | flink-sql-connector-elasticsearch7_2.11-1.10.2.jar |
| mysql | 5.7 | flink-jdbc_2.11-1.10.2.jar mysql-connector-java-8.0.11.jar |
用户行为数据来源: 阿里云天池公开数据集
网盘:https://pan.baidu.com/s/1CPD5jpmvOUvg1LETAVETGw 提取码:m4mc
商品类目纬度数据来源: category.sql
数据生成器:datagen.py
有了数据文件之后,使用 python 读取文件数据,然后并发写入到 kafka。
修改生成器中的 kafka 地址配置,然后运行 以下命令,开始不断往 kafka 写数据
# 5000 并发
nohup python3 datagen.py 5000 & -
生成器往 kafka 写数据,会自动创建主题,无需事先创建
-
flink 往 elasticsearch 写数据,会自动创建索引,无需事先创建
-
Kibana 使用索引模式从 Elasticsearch 索引中检索数据,以实现诸如可视化等功能。
使用的逻辑为:创建索引模式 》Discover (发现) 查看索引数据 》visualize(可视化)创建可视化图表》dashboards(仪表板)创建大屏,即汇总多个可视化的图表
# 进入 flink-sql 客户端, 需要指定刚刚下载的 jar 包目录
./bin/sql-client.sh embedded -l lib-- 创建 kafka 表, 读取 kafka 数据
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts TIMESTAMP(3),
proctime as PROCTIME(),
WATERMARK FOR ts as ts - INTERVAL '5' SECOND
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'user_behavior',
'connector.startup-mode' = 'earliest-offset',
'connector.properties.zookeeper.connect' = '172.16.122.24:2181',
'connector.properties.bootstrap.servers' = '172.16.122.17:9092',
'format.type' = 'json'
);
SELECT * FROM user_behavior;CREATE TABLE buy_cnt_per_hour (
hour_of_day BIGINT,
buy_cnt BIGINT
) WITH (
'connector.type' = 'elasticsearch',
'connector.version' = '7',
'connector.hosts' = 'http://172.16.122.13:9200',
'connector.index' = 'buy_cnt_per_hour',
'connector.document-type' = 'user_behavior',
'connector.bulk-flush.max-actions' = '1',
'update-mode' = 'append',
'format.type' = 'json'
);INSERT INTO buy_cnt_per_hour
SELECT HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)), COUNT(*)
FROM user_behavior
WHERE behavior = 'buy'
GROUP BY TUMBLE(ts, INTERVAL '1' HOUR);CREATE TABLE cumulative_uv (
time_str STRING,
uv BIGINT
) WITH (
'connector.type' = 'elasticsearch',
'connector.version' = '7',
'connector.hosts' = 'http://172.16.122.13:9200',
'connector.index' = 'cumulative_uv',
'connector.document-type' = 'user_behavior',
'update-mode' = 'upsert',
'format.type' = 'json'
);CREATE VIEW uv_per_10min AS
SELECT
MAX(SUBSTR(DATE_FORMAT(ts, 'HH:mm'),1,4) || '0') OVER w AS time_str,
COUNT(DISTINCT user_id) OVER w AS uv
FROM user_behavior
WINDOW w AS (ORDER BY proctime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW);INSERT INTO cumulative_uv
SELECT time_str, MAX(uv)
FROM uv_per_10min
GROUP BY time_str;先在 mysql 创建一张商品类目的维表,然后配置 flink 读取 mysql。
CREATE TABLE category_dim (
sub_category_id BIGINT,
parent_category_name STRING
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://172.16.122.25:3306/flink',
'connector.table' = 'category',
'connector.driver' = 'com.mysql.jdbc.Driver',
'connector.username' = 'root',
'connector.password' = 'root',
'connector.lookup.cache.max-rows' = '5000',
'connector.lookup.cache.ttl' = '10min'
);CREATE TABLE top_category (
category_name STRING,
buy_cnt BIGINT
) WITH (
'connector.type' = 'elasticsearch',
'connector.version' = '7',
'connector.hosts' = 'http://172.16.122.13:9200',
'connector.index' = 'top_category',
'connector.document-type' = 'user_behavior',
'update-mode' = 'upsert',
'format.type' = 'json'
);CREATE VIEW rich_user_behavior AS
SELECT U.user_id, U.item_id, U.behavior, C.parent_category_name as category_name
FROM user_behavior AS U LEFT JOIN category_dim FOR SYSTEM_TIME AS OF U.proctime AS C
ON U.category_id = C.sub_category_id;INSERT INTO top_category
SELECT category_name, COUNT(*) buy_cnt
FROM rich_user_behavior
WHERE behavior = 'buy'
GROUP BY category_name;整个开发过程,只用到了 flink-sql ,无需写 java 或者其它代码,就完成了这样一个实时报表。
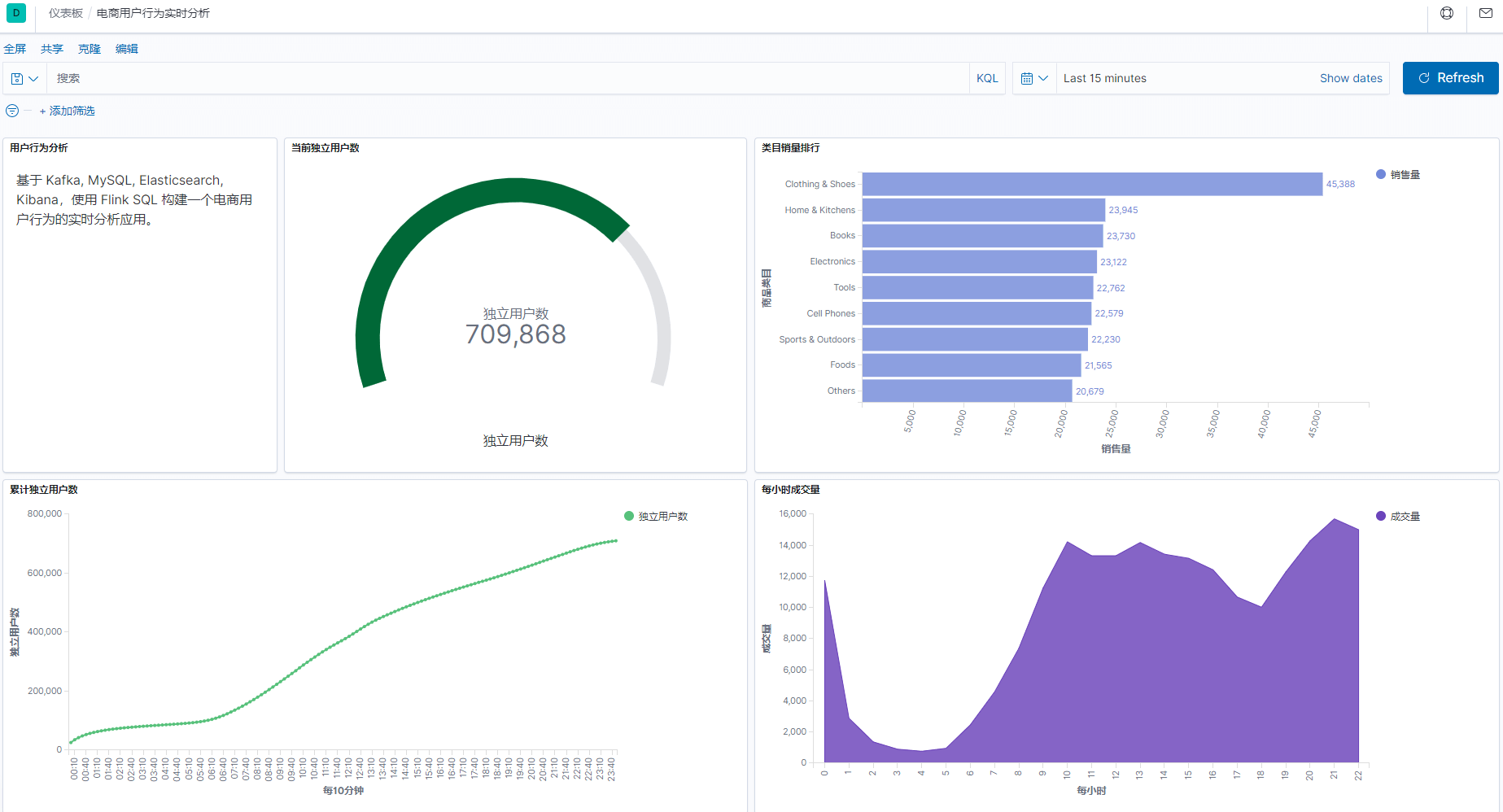
-
flink-sql 的 ddl 语句不会触发 flink-job , 同时创建的表、视图仅在会话级别有效。
-
对于连接表的 insert、select 等操作,则会触发相应的流 job, 并自动提交到 flink 集群,无限地运行下去,直到主动取消或者 job 报错。
-
flink-sql 客户端关闭后,对于已经提交到 flink 集群的 job 不会有任何影响。
本次开发,执行了 3 个 insert , 因此打开 flink 集群面板,可以看到有 3 个无限的流 job 。即使 kafka 数据全部写入完毕,关闭 flink-sql 客户端,这个 3 个 job 都不会停止。
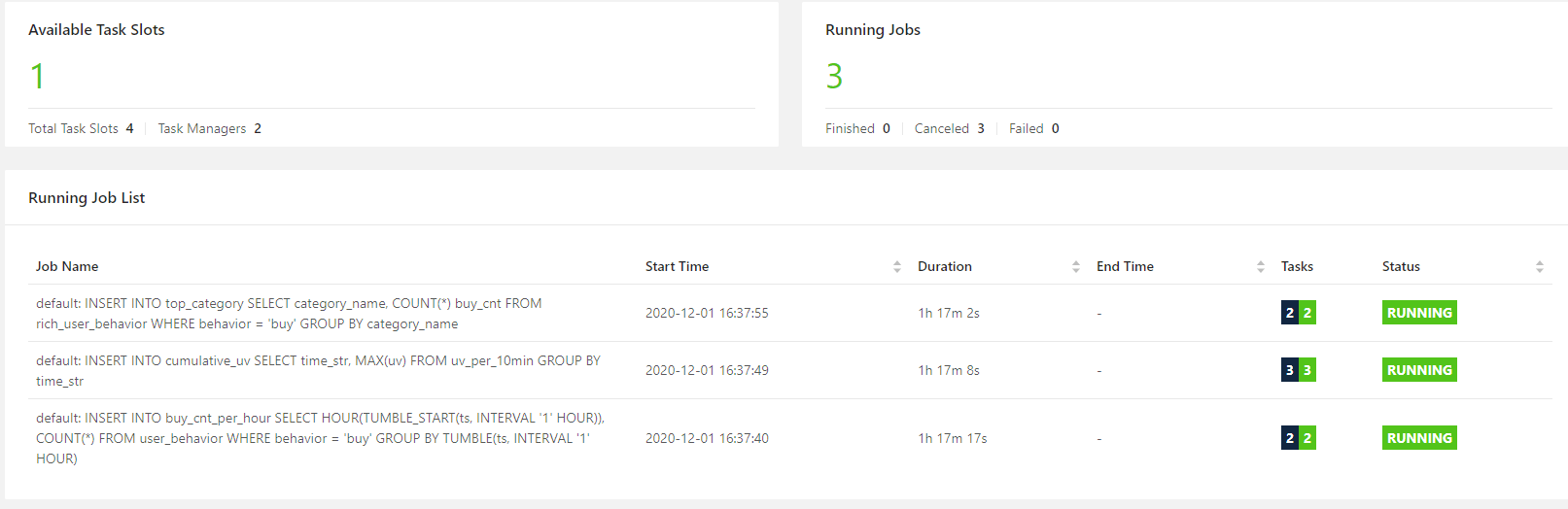
-
flnik 本身不存储业务数据,只作为流批一体的引擎存在,所以主要的用法为读取外部系统的数据,处理后,再写到外部系统。
-
flink 本身的元数据,包括表、函数等,默认情况下只是存放在内存里面,所以仅会话级别有效。但是,似乎可以存储到 Hive Metastore 中,关于这一点就留到以后再实践。
GitHub 地址:https://github.com/TurboWay/bigdata_analyse/blob/main/UserBehaviorFromTaobao_Stream/