Home
Make a common GPU ndarray(matrix/tensor or n dimensions) that can be reused by all project
This is in early development. So all what you read is discutable. If you have idea send them to the mailing list!
- Currently there is at least 4 different gpu array in python
- CudaNdarray(Theano), GPUArray(pycuda) and CUDAMatrix(cudamat), GPUArray(pyopencl), ...
- There is even more if we include other language.
- They are incompatible
- None have the same properties and interface
- All of them are a subset of numpy.ndarray on the gpu!
- Duplicate work
- GPU code is harder/slower to do correctly and fast than on the CPU/python
- Harder to port/reuse code
- Harder to find/distribute code
- Divides development work
- Start alone
- We need different people/groups to "adopt" the new GpuNdArray
- Too simple - other projects won't adopt
- Too general - other projects will implement "light" version... and not adopt
- Having an easy way to convert/check conditions as numpy could alleviate this.
The option choosed is to have a general version with easy check/conversion to allow supporting only a subset!
- Make it VERY similar to numpy.ndarray
- Easier to attract other peole from python community
- Have the base object in C to allow collaboration with more project.
- We want people from C, C++, ruby, R, ... all use the same base Gpu ndarray.
- Be compatible with CUDA and OpenCL
- No CPU code generated from the python interface(for PyOpenCL and PyCUDA) Gpu code are ok.
I will first implement the C and python back-end to have it used in Theano and PyCUDA. Then it will be probably be PyOpenCL. If you are interested to contribute to it, more could be done at the same time!
List of planned gpu operations.
This version of the sketch will request that the python header and library and numpy header are available if you want more then just the struct defined. We will remove the dependency of python and numpy later for part of the functionality. That way it you don't want to use python, you will still have some (part?) of the function available.
To make it easy to use for opencl and cuda, all code that call it go in the files {pygpu_language.h, pygpu_language_opencl.c, pygpu_language_cuda.cu}
Q: Where to put the binding to other library?
When done, it is marked, otherwise it is not done. If code already exist in theano, it is marked. So it could be ported without too much work.
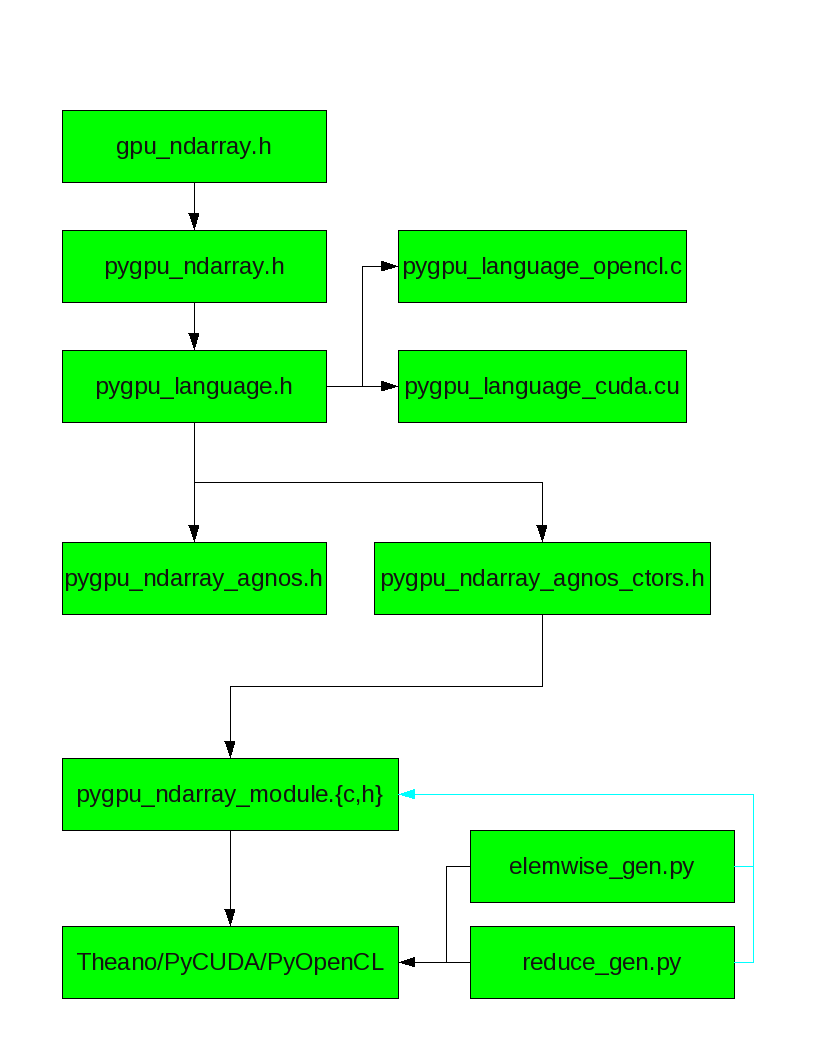
- gpu_ndarray.h(currently gpu_ndarray.cuh will be changed):
- Define the base struct GpuNdArray (done)
- pygpu_ndarray.h
- include gpu_ndarray.h
- Define the struct PyGpuNdArray and some numpy C interface function/macro.
- pygpu_language.h:
- This will define an interface between cuda/opencl and all function that are agnostic to them.
- include gpu_ndarray.h and pygpu_ndarray.h
- Header that define the signature for the following function
- device_malloc (done)
- device_free (done)
- PyGpuNdArray_CopyFromArray (done)
- outstanding_mallocs (done)
- PyGpuNdArray_CreateArrayObj (done)
- PyGpuNdArray_Copy (done)(first a simple version for nd array, there is optimization possible later)
- PyGpuNdArray_Gemm (in theano)(this can be moved elsewhere later, but we need it for now and seam the best place if we don't plan to add all blas function call)
- pygpu_language_cuda.cu
- include gpu_ndarray.h and pygpu_language.h
- Define function in pygpu_language.h
- Cuda implementation of the function in pygpu_language.h
- Done all except the copy.
- pygpu_language_opencl.cu
- as pygpu_language_cuda.cu for opencl.
- pygpu_ndarray_agnos.{c,h}
- It contain only function agnostic to cuda/opencl, but can use function in pygpu_language.h.
- implement the following function
- sub-ndarray(getitem, done)
- assignation(setitem, in theano)
- reshape(in theano)
- n dimensional transpose(in theano)
- dot(in theano)
- pygpu_ndarray_agnos_misc.{c,h}
- elemwise_dimensions_merge(no cuda/opencl code, in theano)
- reduce_dimensions_merge(no cuda/opencl code)
- deepcopy and view(done)
- pygpu_ndarray_agnos_ctor.{cu,cuh}
- Create empty, zeros, ones PyGpuNdArrayObject
- test_gpu_ndarray.py
- Test the python binding of this project.
- pygpu_module.{c,h}
- Define the module and the binding in python.
- include pygpu_language.h, pygpu_ndarray.h, pygpu_ndarray_agnos.h
- elemwise_gen.py
- include pygpu_ndarray.h and pygpu_language.h
- Can be used from pycuda to generate the kernel
- elemwise operation (with broadcasting, in theano)
- add, mul, ..., cos, ..., cast, ...
- can be used later to have
- Later: Could be used to generate a elemwise.cu file that allow to cast those function from C.(in theano)
- If someone else want the trouble he could change it to opencl
- Later: could be used to generate a more optimized copy that could be include in pygpu_language_{cuda,opencl}.cu
- reduce_gen.py
- reduce along all dimensions, along one axis or a list of dimensions
- sum(in Theano for all type of axis), prod, max, min, argmax, ...
- Later: In theano there is the boiller plate code to call it from C. So it could be also done to generate a reduce.cu file. But first it will be called to generate only the kernel to work with pycuda/pyopencl.
- Makefile
- Define two rules, cuda and opencl. They will include the cuda or the opencl implementation of the pygpu_language.h implementation.
PyGpuNdArray_CAPITAL: macro, (take dtype as an int) PyGpuNdArray_CamelCase: take basic type(int nd, int * dims,...) and PyGpuNdObject as input PyGpuNdArray_local_case_with_underscore: used for the python module interface. Will be called by python code.
I have the deadline of HPCS the June 13 or 14. I would like to be able to use this new interface in Theano and PyCUDA. I won't have the time to part all the Theano code to use the new systeme, but I would like to be able to use it for some of the function to show that Theano can also support other dtype.
At this tutoriel, I want to present the new way of implementing new gpu op in Theano. I define the that new way as being able to use PyCUDA to generate the gpu code AND be able to use that simply in a Theano op.
As I don't know what time you are ready to put on PyCUDA and as you seam busy for now, I have a simple plan to be able to use the current PyCUDA with it. We could simply take the gpu pointeur, dimensions and strides values and pass it as inputs (no array but by pointer and ints) to the gpu function. I think that this don't ask modification to the current PyCUDA.
- Is it ok that the C interface include python header? Need the python library? numpy header?