Retrieval is the process of returning the most relevant documents, based on a specific user query.
We have already introduced several solutions and algorithms to perform retrieval. But how can we objectively evaluate retrieval? Let's see some evaluation measures...
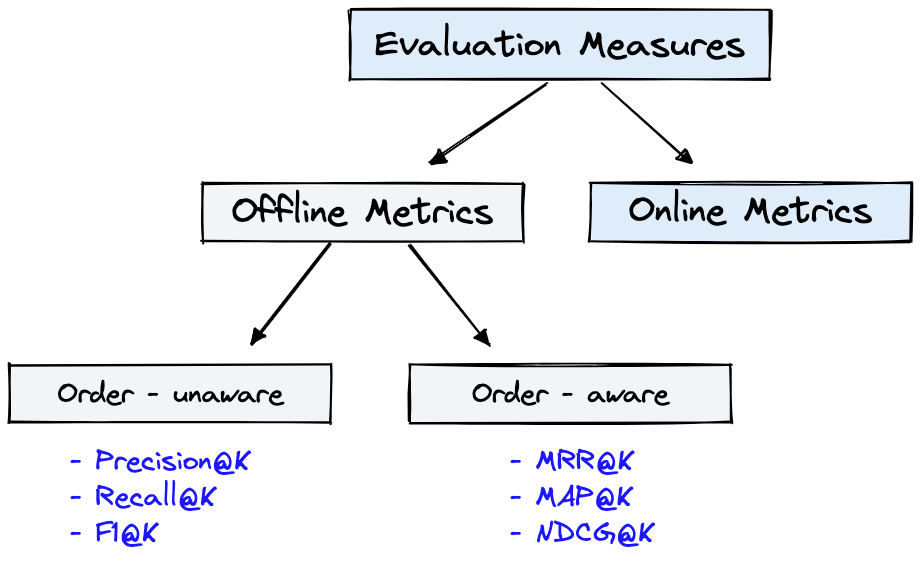
In this pill, I just want to list the most common retrieval metrics. You can find in-depth explanations in the suggested resources.
(Image by Pinecone, Laura Carnevali and James Briggs)
-
Precision@K:
it quantifies how many documents in the top-K results are relevant. The K refers to the number of items returned by the system.
-
Recall@K:
it measures how many relevant documents for the query are returned among all possible relevant results in the collection.
👍 Recall is simply interpretable,
👎 but it does not take the position of results into account.
-
Mean Reciprocal Rank (MRR):
this metric takes into account the position of the first correctly retrieved document.
👍 MRR is useful when only the rank of the first relevant result matters (for example, in chatbots);
👎 it's not a good metric if there can be multiple relevant results.
-
Mean Average Precision@K (MAP@K):
it takes into account the order of each item retrieved.
👍 MAP@K is suitable when we expect to return multiple relevant documents; it is very popular for evaluating recommender systems and search engines.
-
Normalized Discounted Cumulative Gain@K (NDCG@K):
it is a popular and newer retrieval metric. In this case, the documents are not simply considered relevant or not relevant: instead, we adopt a more nuanced rating scale.
It is simply explained in the scikit-learn docs as follows: "Sum the true scores ranked in the order induced by the predicted scores, after applying a logarithmic discount (=incorrect order penalty). Then divide by the best possible score (Ideal DCG, obtained for a perfect ranking) to obtain a score between 0 and 1."
- Evaluation Metrics For Information Retrieval: great and complete blogpost by Amit Chaudhary
- Evaluation Measures in Information Retrieval: from Pinecone blog, a very visual article by Laura Carnevali and James Briggs