PIP178:Multiple snapshots for transaction buffer #16042
Comments
|
Hi @liangyepianzhou this PIP NO. is the same to #15797 which was created 21 days ago. Would you like to choose another PIP NO.? Thank you |
|
The issue had no activity for 30 days, mark with Stale label. |
14 tasks
4 tasks
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Motivation
Transaction buffer stores aborted transaction IDs to filter messages which are aborted. In order to recover, the Transaction buffer will take snapshots to store the aborted transaction IDs in the bookkeeper, but the size of aborted transaction IDs is not limited. When the size of aborted transaction IDs is bigger than the size that a bookkeeper entry can store, the Transaction buffer needs to store multiple-snapshot into multiple entries to store aborted transaction IDs.

Challenges
Due to compression and incomplete sending, there are some challenges to achieve multiple-snapshot.

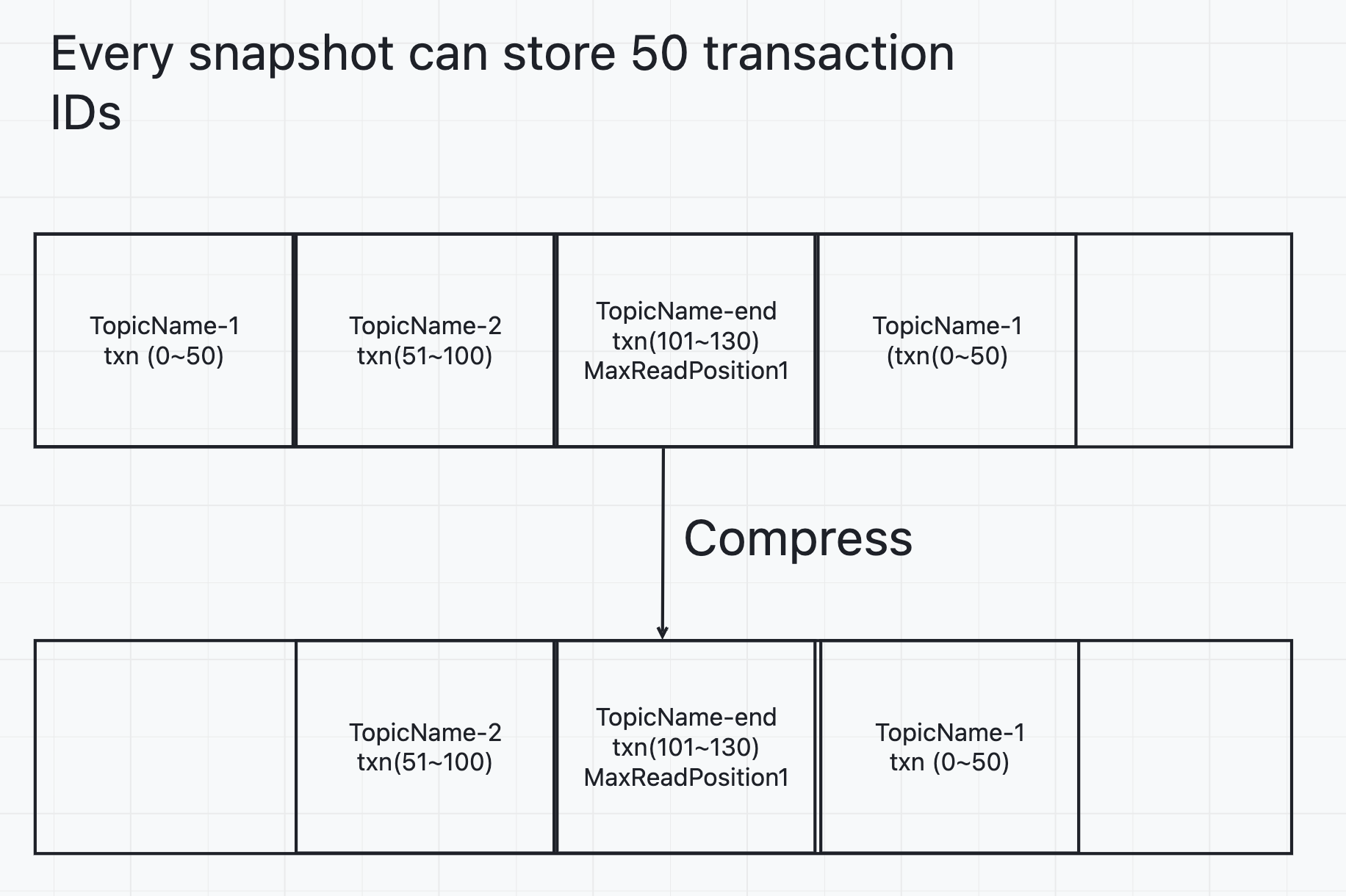
2. Due to compression, the new snapshot will cover the old snapshot with the same key. * eg. This will make a multiple-snapshot(1, 2 , 3) may have snapshot 1, 2 writed the second time, and snapshot writed the first time.Approach
Implement
Goal
Examples
Normal Flow
The first snapshot is taken when new a producer to send message, So there must be a snasphot with key (topicName-end) which has maxReadPosition to recover.

Write incompletely
When transaction IDs are sorted by the position of the aborted marker and transaction IDs have not been deleted from aborts, the txn IDs stored in snapshots are the same for the snapshot same key (Exclude key topicName-end).
Write incompletely and have transaction IDs been removed due to the ledger deleted
Because it is deleted in the order of the position of the aborted marker, no message will be lost when compressing with the new snapshot. There always is a valid maxReadPsoition that can be used to recover.

As you can see in the figure below, the ledger where txn0
25 is located has been deleted, and the corresponding txn025 have also been removed from aborts. But this does not affect the information in the snapshot.Code Implement
handleSnapshot
takeSnapshot
Reject Alternatives
Add a snapshotEntryCounts field in TransactionBufferSnapshot
Add a snapshotEntryCounts field for each transactionBufferSnapshot. For the normal transactionBufferSnapshot, snapshotEntryCount will be set to 1; for the multiple-snapshot, snapshotEntryCount will be set to the number of entries to store the snapshot.
marked multiple-snapshot with null field
For the multiple-snapshot, we only write the data of aborts and maxRead Position in the front entries without setting topicName . Only set topicName in the last entry. When the reader reads TopicName = null, it means the beginning of a multiple-snapshot, and read topicName! =null is the end of this multiple-snapshot.

API changes
Implement
The text was updated successfully, but these errors were encountered: