##Tutorial 2: Data Processing with Pig - Processing Baseball Stats With Pig
This tutorial is from the Hortonworks Sandbox 2.0 - a single-node Hadoop cluster running in a virtual machine. Download the Hortonworks Sandbox to run this and other tutorials in the series.
This tutorial was derived from one of the lab problems in the Hortonworks Developer training class. The developer training class covers uses of the tools in the Hortonworks Data Platform and how to develop applications and projects using the Hortonworks Data Platform. You can find more information about the course at Hadoop Training for Developers
Apache Pig (running time: about 12 minutes)
Pig is a high level scripting language that is used with Apache Hadoop. Pig excels at describing data analysis problems as data flows. Pig is complete in that you can do all the required data manipulations in Apache Hadoop with Pig. In addition through the User Defined Functions(UDF) facility in Pig you can have Pig invoke code in many languages like JRuby, Jython and Java. Conversely you can embed Pig scripts in other languages. The result is that you can use Pig as a component to build larger and more complex applications that tackle real business problems.
A good example of a Pig application is the ETL transaction model that describes how a process will extract data from a source, transform it according to a rule set and then load it into a datastore. Pig can ingest data from files, streams or other sources using the User Defined Functions(UDF). Once it has the data it can perform select, iteration, and other transforms over the data. Again the UDF feature allows passing the data to more complex algorithms for the transform. Finally Pig can store the results into the Hadoop Data File System.
Pig scripts are translated into a series of MapReduce jobs that are run on the Apache Hadoop cluster. As part of the translation the Pig interpreter does perform optimizations to speed execution on Apache Hadoop. We are going to write a Pig script that will do our data analysis task.
We are going to read in a baseball statistics file. We are going to compute the highest runs by a player for each year. This file has all the statistics from 1871-2011 and it contains over 90,000 rows. Once we have the highest runs we will extend the script to translate a player id field into the first and last names of the players.
The data file we are using comes from the site www.seanlahman.com. You can download the data file in csv zip form from:
http://s3.amazonaws.com/hw-sandbox/tutorial2/lahman591-csv.zip
Once you have the file you will need to unzip the file into a directory. We will be uploading just the master.csv and batting.csv files.
We start by selecting the File Browser from the top tool bar. The File Browser allows us to view the Hortonworks Data Platform(HDP) file store. This is separate from the local file system. In a Hadoop cluster this would be your view of the Hadoop Data File System(HDFS). For the Hortonworks Sandbox it will be part of the file system in the Hortonworks Sandbox VM.

Click on the Upload button to select the files we want to upload into the Hortonworks Sandbox environment.
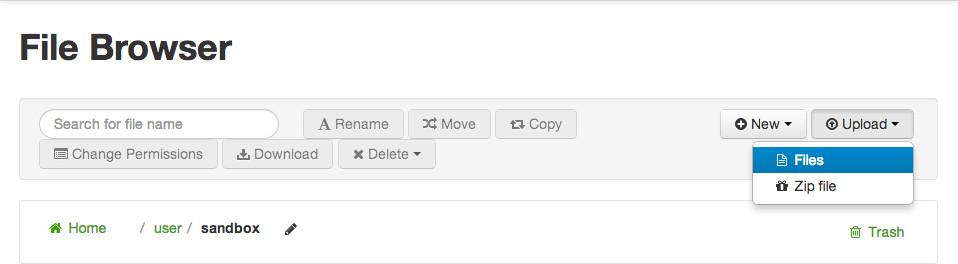
You want to select Files. Then you will get a dialog box.
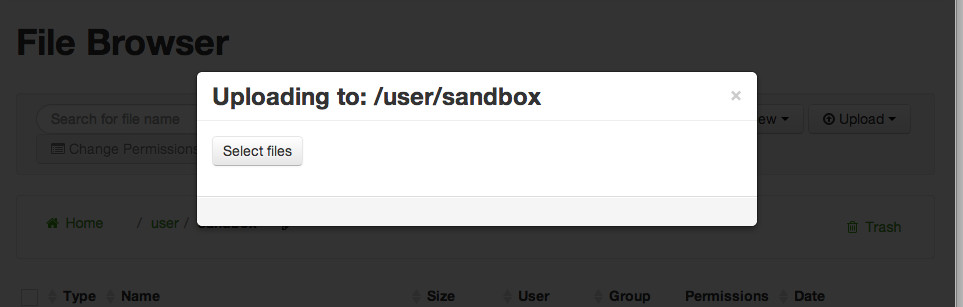
When you click on the Upload a file button you will get a dialog box. Navigate to where you stored the Batting.csv file on your local disk and select Batting.csv. Do the same thing for Master.csv. When you are done you will see there are two files in your directory.

Now that we have our data files we can start writing our Pig script. Click on the Pig icon at the top of the screen.

We see the Pig user interface in our browser window. On the left is a list of the saved scripts. On the right is the composition area where we will be writing our script. Below the composition area are buttons to Save, Execute, Explain and perform a Syntax check of the current script. At the very bottom are status boxes where we will see logs, error message and the output of our script.
To get started fill in a name for your script. You can not save it until we add our first line of code. The first thing we need to do is load the data. We use the load statement for this. The PigStorage function is what does the loading and we pass it a comma as the data delimiter. Our code is:
batting = load 'Batting.csv' using PigStorage(','); 
The next thing we want to do is name the fields. We will use a FOREACH statement to iterate through the batting data object. We can use Pig Helper that is at the bottom of the composition area to provide us with a template. We will click on Pig Helper, select Data processing functions and then click on the FOREACH template. We can then replace each element by hitting the tab key.
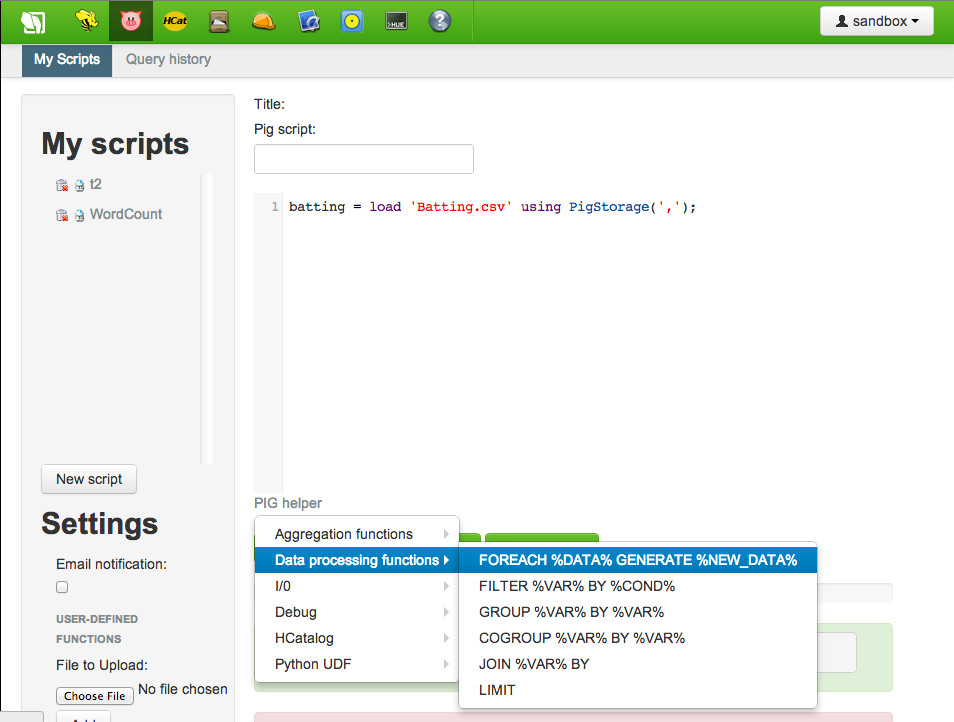
So the FOREACH statement will iterate through the batting data object and GENERATE pulls out selected fields and assigns them names. The new data object we are creating is then named runs. Our code will now be:
runs = FOREACH batting GENERATE $0 as playerID, $1 as year, $8 as runs;
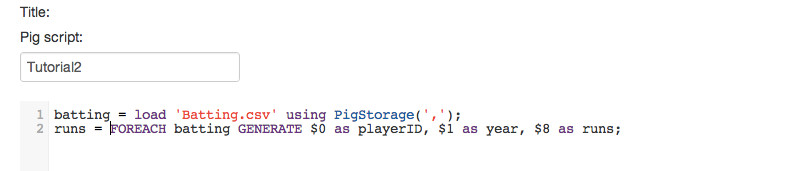
The next line of code is a group statement that groups the elements in runs by the year field. So the grp_data object will then be indexed by year. In the next statement as we iterate through grp_data we will go through year by year. Type in the code:
grp_data = GROUP runs by (year); 
In the next FOREACH statement we are going to find the maximum runs for each year. The code for this is:
max_runs = FOREACH grp_data GENERATE group as grp,MAX(runs.runs) as max_runs;

Now that we have the maximum runs we need to join this with the runs data object so we can pick up the player id. The result will be a dataset with Year, PlayerID and Max Run. At the end we dump the data to the output.
join_max_run = JOIN max_runs by ($0, max_runs), runs by (year,runs); join_data = FOREACH join_max_run GENERATE $0 as year, $2 as playerID, $1 as runs; dump join_data;
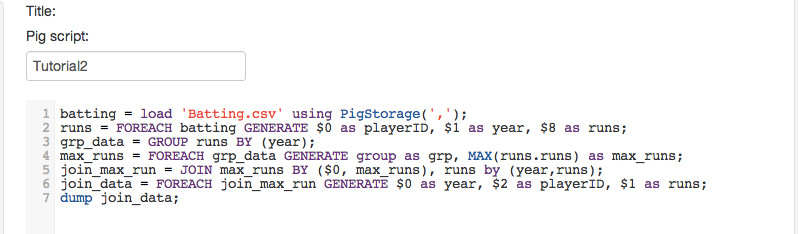
Let's take a look at our script. The first thing to notice is we never really address single rows of data to the left of the equals sign and on the right we just describe what we want to do for each row. We just assume things are applied to all the rows. We also have powerful operators like GROUP and JOIN to sort rows by a key and to build new data objects.
At this point we can save our script. Fill in a name in the box below
"Pig script:" if you haven't already. Click on the save button and the
your script will show up in the bar on the left.
We can execute our code by clicking on the execute button at the bottom of the composition area. As the jobs are run you will get a progress bar at the bottom.
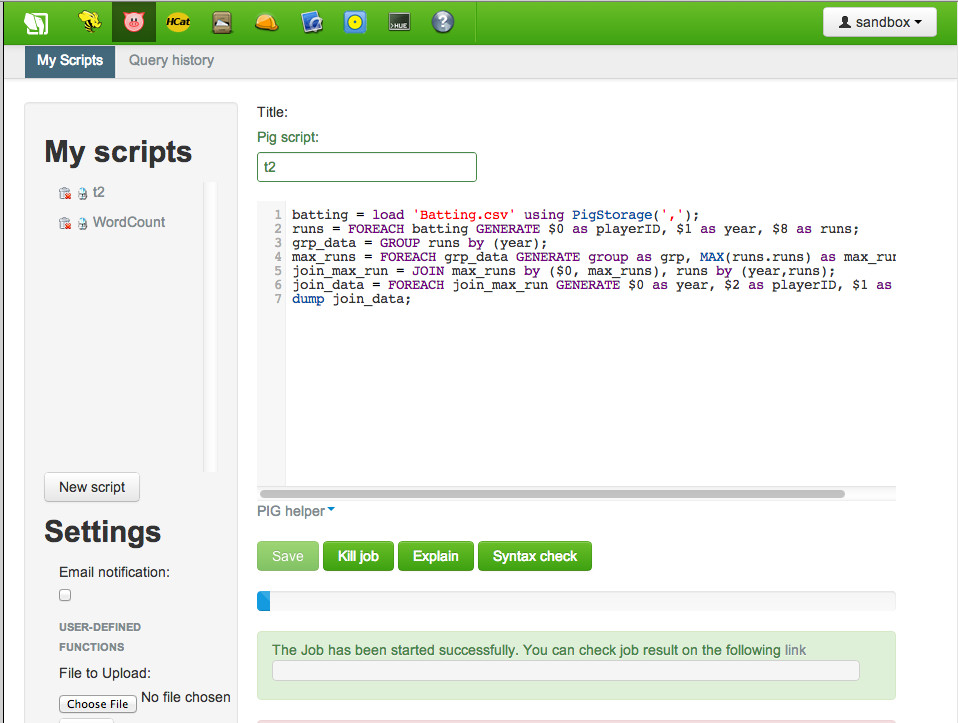
When the job completes the results are displaying in the green box at the bottom.
If you scroll down to the "Logs..." and click on the link you can see the log file of your jobs.

So we have created a simple Pig script that reads in some comma separated data. Once we have that set of records in Pig we pull out the playerID, year and runs fields from each row. We them sort them by year with one statement, GROUP. Then for each year we find the maximum runs. This is finally mapped to the playerID and we produce our final dataset.
As mentioned before Pig operates on data flows. We consider each group of rows together and we specify how we operate on them as a group. As the datasets get larger and/or add fields our Pig script will remain pretty much the same because it is concentrating on how we want to manipulate the data.
Feedback
We are eager to hear your feedback on this tutorial. Please let us know what you think. Click here to take survey