feat(ec2): multipart user data #11843
Conversation
|
|

|
I think this has to be work in progress for a moment (soft review is welcome) - I analysed integration test results and the approach with auto generating boundary is not perfect when the token is used inside part body, it can lead to different hashes used as boundary and change of user data in turn. |
|
I don't really understand the design. Why isn't it just a self-contained And generally the boundary is just a large pseudorandom number which we'll assume won't occur in the various parts. Getting a hash from the part contents seems unnecessarily complicated? Let's start by defining what parts there are. I assume you'll have a "commands" part (the "old" UserData, so to speak) and then a bunch of "attachments", right? Which are basically just files to stick somewhere on the filesystem? |
|
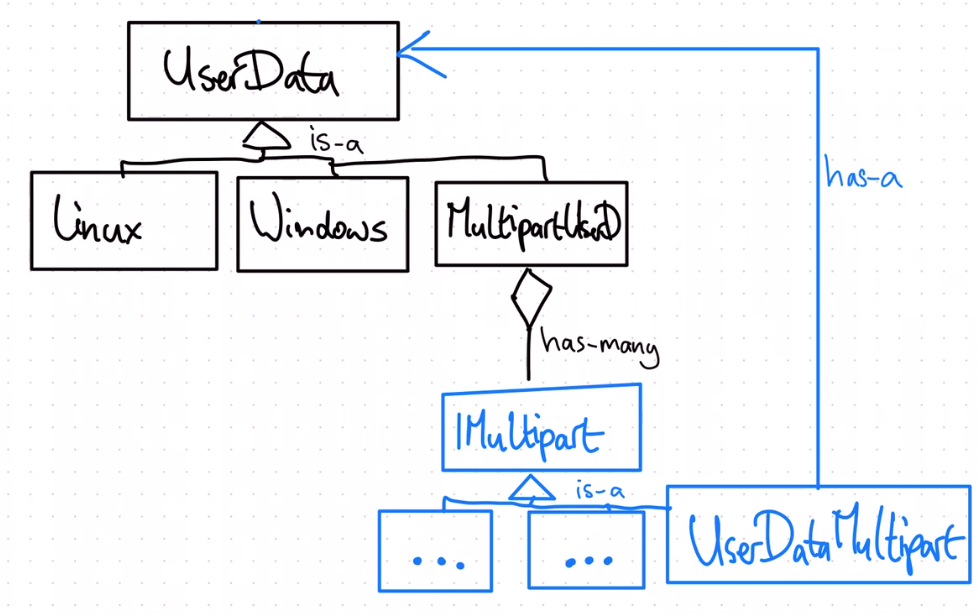
SeeHi Ricco, I got your point. I'll try to clarify some "whys" so maybe it will be better understable and we could go with this or something better. Let me start from last part. Multipart User Data is more like archive than a message with attachments. Each script is a separate part (attachment), executed during different phases. Many scripts can be executed for the same phase. (There's more kinds of attachments than script types). Thus I thought that the Multipart has to inherit from UserData, but it doesn't allow adding commands (to what part or type? it's just archive) In order to add parts and use existing classes (LinuxUserData) This allows reusing the current command like user data for Multipart user data. Let me give a use case: cloud-boothook - to reconfigure docker and increase size of docker volume So in this case Multipart will be archive for shell scripts, executed by cloud unit. (Worth of mentioning but not implementing now is that there's more types supported by cloud init: like part handlers, include url, and more - in future every such type could get own class implementing IMultipartUserDataPartProducer) So that's very nice to have good design review. |
I see. I don't mind that at all, I think you are right. But then we still have a couple of choices: UserData implements IMultipart
The different UserData implementations that can be reused implement IMultipart
There's an integration class that implements IMultipart
Out of these, I think the last one is most self-contained, so has my preference. There might be some syntactic overhead there, but we can hide that with convenience methods: multipart.addUserDataPart(new LinuxUserData());
class MultipartUserData {
public addPart(part: IMultipart) { ... }
public addUserDataPart(userData: UserData) {
this.addPart(new UserDataMultipart(userData));
}
}That way we don't need to pollute the existing |


|
Agree. The last idea is really good, instead of bloating code with interfaces just use adaptor. And later we could think how to solve separator issue - however fallback will be to specify separator as option to Multipart. |
|
Hi @rix0rrr can you check now? |
|
Thank you. And sorry for late answer I missed notification. I'll take a look at it. I think real life example could be setting size for Docker container disk in batch environment: https://aws.amazon.com/premiumsupport/knowledge-center/batch-job-failure-disk-space/ |
|
We have a similar requirement which is another real life example of using more than 1 part:
These changes would help us a lot in simplifying the user-data handling. |
|
I want to test it with Windows machines, too. I'm bit concerned about line ending characters. |
Add support for multiparat (MIME) user data for Linux environments. This type is more versatile type of user data, and some AWS service (i.e. AWS Batch) requires it in order to customize the launch behaviour. Change was tested in integ environment to check if all user data parts has been executed correctly and with proper charset encoding. fixes aws#8315
* Remove `IMultipartUserDataPartProducer` * Add `MultipartUserDataPart` & `IMultipart` * Concrete types to represent raw part and UserData wrapper can be created with `MultipartUserDataPart.fromUserData` & `MultipartUserDataPart.fromRawBody` * Removed auto-generation of separator (as with tokens hash codes can differ when tokens are not resolved)
- remove `MultipartContentType` - remove `MultipartUserDataPartWrapperOptions` - remove `IMultipart` - rename `MultipartUserDataPart` -> `MultipartBody` - other removals - restructure other classes - moved part rendering to part class - set default separator to hard codeded string - added validation of boundry
|
Hi @rix0rrr I made a bigger refactor of code, I removed few methods, and followed tips. I think it's more clean right now, please check. In context of Windows machines, I think multipart is not supported for Windows (at least I could not run any kind of multipart data on Windows, and documentation as well does not mention that multipart is supported for Windows EC2). Minor thing which concerns me. MIME RFC as it's telnet based suggests CRLF as new line, however cloud-init is fine with |
| protected static readonly DEFAULT_CONTENT_TYPE = 'text/x-shellscript; charset="utf-8"'; | ||
|
|
||
| /** The body of this MIME part. */ | ||
| public abstract get body(): string | undefined; |
There was a problem hiding this comment.
I think I'd prefer you don't declare these abstract members, and just implement renderBodyPart() twice--once for the two concrete types of classes.
It may feel like unnecessary duplication, but the actual amount of duplication won't be that bad and we'll have a good reduction in case analysis too (fewer ifs).
There was a problem hiding this comment.
Now I got the point. I thought that main concern was about options interfaces, so I moved towards abstracts getters and template method pattern.
Thanks, that's a good comment.
|
|
||
| return this; | ||
| } | ||
|
|
There was a problem hiding this comment.
Why get rid of the addUserDataPart(userData, contentType) here? I rather liked it as a convenience method.
(Of course it's not strictly necessary, but it reads nicer than the current alternative)
|
Thank you for contributing! Your pull request will be updated from master and then merged automatically (do not update manually, and be sure to allow changes to be pushed to your fork). |
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
|
Thank you for contributing! Your pull request will be updated from master and then merged automatically (do not update manually, and be sure to allow changes to be pushed to your fork). |
Add support for multiparat (MIME) user data for Linux environments. This
type is more versatile type of user data, and some AWS service
(i.e. AWS Batch) requires it in order to customize the launch
behaviour.
Change was tested in integ environment to check if all
user data parts has been executed correctly and with proper charset
encoding.
fixes #8315
By submitting this pull request, I confirm that my contribution is made under the terms of the Apache-2.0 license