XProlog.dll is a library that allows you to run Prolog code in your .NET applications. Prolog is particularly well suited for creating parsers for both computer and natural languages. Its DCG notation very much resembles BNF but is more powerful and allows for ambiguous, context-sensitive grammars.
Prolog is considered by many an 'artificial intelligence language' because unlike conventional programming languages it does not require the programmer to provide a recipe-style solution for a problem (take A, add B, put result into C); instead, a Prolog program is a collection of facts and rules describing the problem (such as the rules of the game of chess) and it is Prolog's task to figure out the solution for a goal set by the programmer (e.g. I want to place 8 queens on the chessboard so that none beats the others).
How does Prolog figure out the solution? You may feel a bit underwhelmed but the answer is very simple. It is just brute force search. It is one of the few things that computers are very good at. In fact, much, much better than us humans. A billion times better. True, it's very far from how humans think but for some problems brute force does get us from A to B, and sometimes even to such C's which we could never have thought of. Here's just a few examples of problems that Prolog has been used to solve:
-
Toy problems such as Sudoku, the N queens problem or the farmer, wolf, goat and cabbage problem.
-
Querying large datasets with constraints, i.e. the same task you use SQL for. Prolog and SQL are quite different syntactically but in essence they are not that dissimilar. SQL is also declarative in the sense that you specify what you want to get but don't tell it how. It is up to the database engine to decide which tables to query first, how to join the results, i.e. to build what database developers call an execution plan. In fact, there is a specialized version of Prolog for database programming called Datalog.
-
Text parsing (think regex, yacc or ANTLR).
It is the problem of natural language text parsing that brought XProlog to life.
See also this very informative thread on Prolog Real-Life Usages.
I was working on a natural language processing project and was looking for a tool
to parse natural language sentences. Prolog immediately sprung to mind as I had
done projects with it before. I have googled for the latest and greatest that was out there and ended up downloading
and installing SWI-Prolog. It had a workable IDE with a debugger and DCG syntax support, great stuff. I've tried
implementing a few natural language constructs and all went really well until I got hit by left recursion. You see,
some natural language constructs are naturally left-recursive
("my brother's best mate's birthday party") and any ISO-compliant Prolog is guaranteed to
crash with a stack overflow on such input. Another round of googling brought me a solution, see the section on
"Accommodating left recursion in top-down parsing" in the Wikipedia article on left recursion. The solution is to rewrite your grammar/Prolog program so that it is no longer left-recursive.
See also this nice article: Adding recursive rules where they say:
"[...] the [grammar rewriting] solution is satisfactory. But it leaves something to be desired from a linguistic perspective. The DCG that looped was at least faithful to the linguistic intuitions about the structure of sentences made using and , but , and or. The new DCG imposes an additional layer of structure that is motivated by processing rather than linguistic considerations; we are no longer simply turning grammars into Prolog."
Isn't that something that can be handled by the Prolog engine?
Why another Prolog? The (relatively niche) Prolog market is swarming with competing, incompatible implementations. Why add another?
The aim is to build a fully declarative Prolog. Why? The problem with the ISO Prolog and all compliant implementations is they try to mix both approaches, the 'logical' and the 'imperative' / procedural. If our Prolog is fully declarative, then
- the order of clauses does not matter;
- left recursion can be dealt with at the engine level;
- when used as a parser, Prolog is ideal as its solution tree can also be used as the parse tree; no extra processing, no grammar attributing or 'actions' are required. Existing implementations do not seem to provide this functionality of exposing the solution tree.
- in path-finding problems (such as the travelling salesman problem) there is no need to store the visited nodes; this again can be (and is, in XProlog) handled by the engine;
- if the program has no state or side effects, a lot of other optimizations become possible.
For these reasons, XProlog is intentionally not ISO Prolog compatible and does not use the Warren Abstract Machine.
-
Fully declarative and not tied to any particular execution engine.
- No cuts or fails.
- No predicates with side effects (e.g. writeln, assertz).
- Not using the Warren Abstract Machine at the moment. The WAM is a rigid execution model inherently incapable of handling left recursion. The WAM runtime can be added if/when compatibility with other Prolog implementations is required. This will be an additive change rather than a change in the existing execution engine. The system is modular and allows easy swapping of one execution engine for another.
-
Not trying to be an all-in-one development toolkit with a huge multi-purpose 'standard library'. It's just a DLL. A small DLL.
-
Use-case driven: every feature is there for a purpose.
Yet another parser? What about yacc and ANTLR and regex? And numerous others?
-
XProlog can parse ambiguous texts, i.e. texts that allow more than one interpretation, such as natural language texts. It is the state-of-the-art way of dealing with natural language ambigities: first you build all possible parse trees and then choose one based on its weight/probability score.
-
ANTLR and yacc are ‘parser generators’, i.e. they generate Java / C++ code that can only parse one grammar. XProlog removes this intermediate step from the pipeline.
Most of this project is done as series of unit tests. To get an idea of how to use the Prolog compiler, check out the test 'FarmerProblemHasTwoDistinctSolutions'.
You can also run up the IDE (Prolog.IDE.csproj) which currently features a simple debugger allowing you to step through your program while watching the solution tree being built.
You give it a grammar and a text file to parse and get back a parse tree. Example code:
Program program = new Prolog.Compiler ().Compile ("program.pl");
var solutions = new Runtime.Engine ().Run (program)
foreach (var solution in solutions)
{
Console.WriteLine (solution.ToString ());
}-
Compiles itself: the XProlog parser is written in XProlog!
-
Left recursion handling and infinite loop avoidance. Some natural language constructs are naturally left-recursive: my brother’s girlfriend’s roommate’s best friend. Standard Prolog is notoriously bad at handling left recursion. XProlog has a solution for that.
-
Walk the solution tree – see exactly how the Prolog engine arrived at a solution. Or if you are writing a parser, your solution tree will be your parse tree as well.
-
Seamless two-way .NET interoperability. Easily write your own predicates in a .NET language to query external databases or web services or simply do things that are best described imperatively. See
ExternalPredicateDeclaration,ExternalPredicateDefinition. -
Break/resume – once a solution is found, the .NET host can stop the Prolog engine or continue searching for more solutions.
-
Tracing. The Engline.Run method returns a stream of IDebugEvents. There are currently three types of events:
- Enter goal
- Leave goal
- Return solution
Enter and Leave are guaranteed to be symmetrical.
-
Full and native Unicode support.
-
Prolog code is independent of the hosting language / platform. Traditional parser generators (yacc and pre-v4 ANTLR) rely on 'actions' (snippets of Java or C++ code embedded into the grammar) to describe what processing is to be done on the parse tree, e.g. expression evaluation or building custom objects to represent the parse tree.
After 20 years of working on ANTLR, Terrence Parr decided to steer away from using actions:
Those embedded actions (raw Java code or whatever) locked the grammar into use with only one language. If we keep all of the actions out of the grammar and put them into external visitors, we can reuse the same grammar to generate code in any language for which we have an ANTLR target.
What we want to do is we want to separate the two tasks, building the syntax tree and using it. Prolog is ideally positioned for that as its default execution model involves building a solution tree and the same tree can be used as the abstract syntax tree. This approach has been tried and tested to implement the parser for XProlog. It worked great! There is however, one improvement that would be nice to have. Currently whenever you update the prolog program, you also need to update the code that walks the solution/parse tree as that code references nodes/predicates by their string names. It would be nice to have a tool to generate C# classes from your prolog program that the walking code can then use. Then any breaking change to prolog code would immediately pop up as a compile error in your C# code.
- Modular: only use the building blocks your project needs:
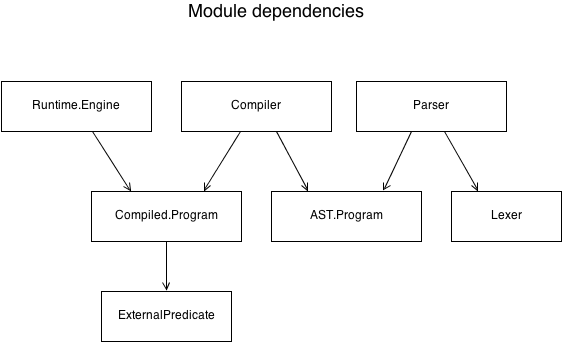
-
Extensible: any component (see the dependencies chart again) can be swapped for your own: if you don’t like the standard depth-first left-to-right engine, go ahead and write your own. There are plenty of possibilities to explore there: implement tabling (intermediate result caching), concurrency, best goal order detection...
-
Lean: XProlog runtime DLL is just 31K. That's all you need to run a compiled Prolog program. Compare this to ~ 700K of 'core' SWI-Prolog or XSB.
-
Thread safe:
- Any number of queries can be running against one prolog program at any time.
- Any number of Prolog programs can run independently at the same time.
- No global variables anywhere.
-
Unit test driven from inception.
-
Generate C# classes to represent the parse tree for easy and type-safe navigation.
-
Create a custom binary serializer for compiled Prolog. Currently BinaryFormatter is used that is
-
very chatty (about 30x more than it needs to be),
-
not version-safe (consider renaming a class) and
-
not cross-plaform.
-
-
Allow for the option to strip symbols from compiled Prolog. This will:
-
Reduce your program's binary footprint.
-
Protect your intellectual property.
-
-
More detailed compilation error reporting. Currently you just get a yes/no from the compiler.
-
Higher order programming support (pass predicates around as arguments to other predicates).
-
IDE (Eclipse plugin?). Like any program, a Prolog program needs to be written, run, tested, traced and debugged. Preferably, in a comfy IDE with syntax highlighting and code completion. Current status: there is currently a mini-debugger that shows the current solution tree and allows you to step through the program or skip to the next choice point.
-
Port the runtime to other languages, C++ and Java being at the top of the list.
-
Implement the anonymous variable (_) (#1).