source: https://arxiv.org/html/2412.09025v1 Advait Joglekar
- Abstract
- 1 Introduction
- 2 Where does Present-day MT fail?
- 3 Related Work
- 4 The Dataset
- 5 The Model
- 6 Translingua
- 7 Conclusion
- 8 Limitations
- Appendix A Source Document
- Appendix B Model Hyperparameters and Results
- Appendix C Translingua
Creating Multilingual Parallel Corpora for Neural Machine Translation (NMT)
Challenges:
- Limited exposure to scientific, technical, and educational domains in existing NMT datasets
- Struggles with tasks involving scientific understanding or technical jargon
- Performance is worse for low-resource Indian languages
- Difficulty finding a translation dataset that addresses these specific domains
Approach:
- Create a multilingual parallel corpus: English-to-Indic and Indic-to-Indic high-quality translation pairs
- Bitext mining human-translated transcriptions of NPTEL video lectures
Contributions:
- Released model and dataset via Hugging Face Co. (https://huggingface.co/SPRINGLab)
- Surpass all publicly available models on in-domain tasks for Indian languages
- Improve baseline by over 2 BLEU on average for out-of-domain translation tasks for these Indian languages on the Flores+ benchmark.
NPTEL (National Programme on Technology Enhanced Learning):
- Valuable resource for free, on-demand higher educational content across diverse disciplines
- Curated over 56,000 hours of video lectures, all made publicly available with audio transcriptions
- Supported Indian language transcriptions for over 12,000 hours of video content
- Translations primarily by subject-matter experts
Benefits:
- Provides access to university-level educational content in native tongues for a large audience of Indian students
- Helps accelerate the mission of providing accurate Indic subtitles for all NPTEL video lectures
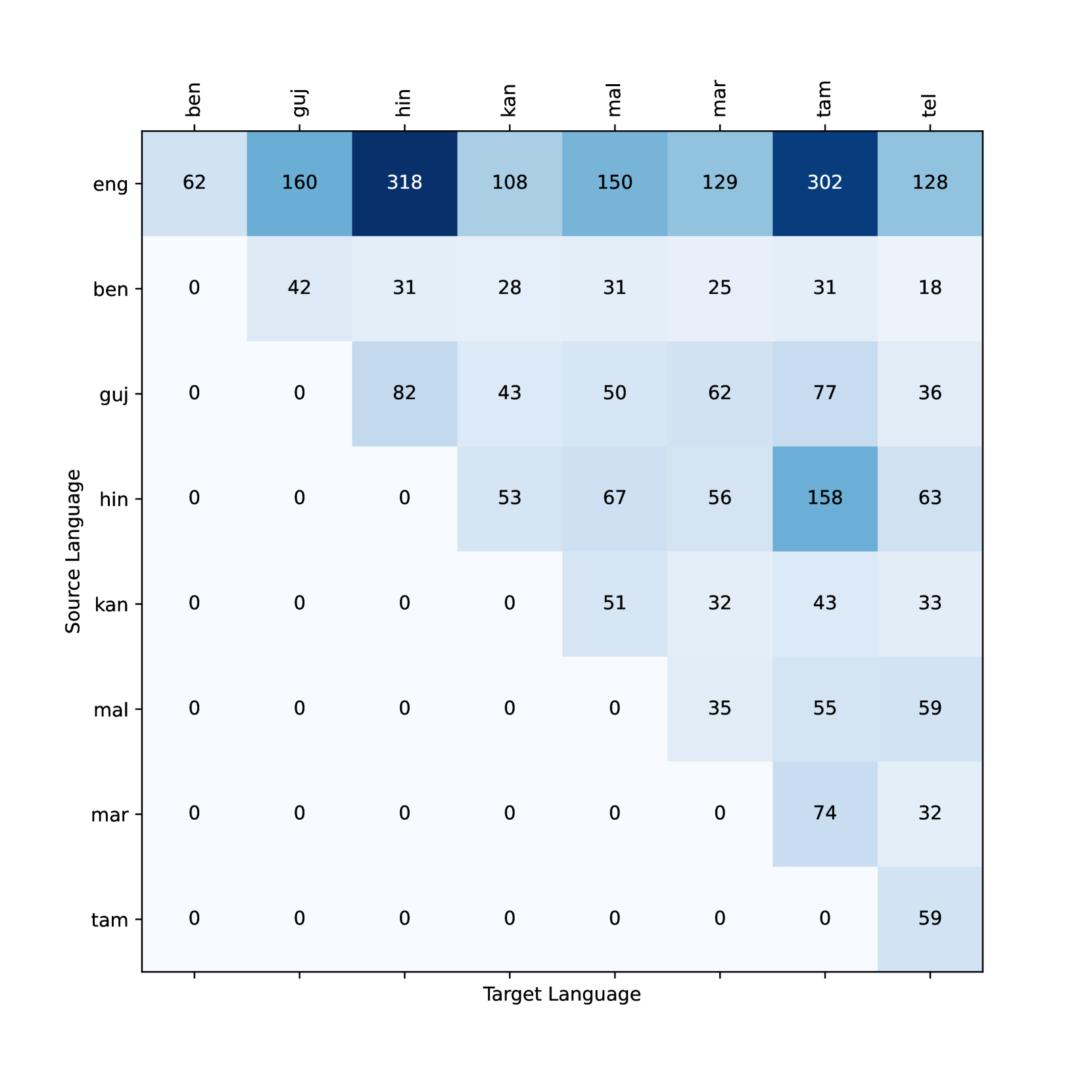
Translation Pair Counts (in thousands):
- Figure 1:
Example Translations from English to Hindi in the Scientific/Technical Domain:
- Table 1:
- Sentences marked with † are in-domain, while ‡ are out-of-domain
- Words in blue are terms with multiple meanings that tend to get translated incorrectly
- Words in green represent the correct, expected translation by the model for the blue word in the given context
- Words in red represent incorrect translations.

Performance of Machine Translation Models on Technical-Domain Tasks
- Google Translate and IndicTrans2 fail to accurately translate "I want to learn the rust language" (Rust programming language, not chemical phenomena) from English to Hindi:
- Google Translate: "I want to learn the language of war"
- IndicTrans2: incorrect translation as well
- Importance of understanding context in technical domains for accurate translations:
- Meaning can change with wrong choice of word
- Hindi word for "rust" has two meanings (phenomena and war)
- Current models prone to making mistakes in such situations.
- Paper aims to alleviate these shortcomings.
NPTEL as a Resource for Machine Translation (MT)
- Related works: Samanantar [^10] and IndicTrans2 [^5] identified NPTEL as useful MT resource
- Data mining: Mining for parallel sentence pairs using various internet sources, including NPTEL
- Exact quantity of mined sentence-pairs from NPTEL not precisely known
Issues with Data from Related Studies:
- Unfiltered artifacts: Significant portion of extracted sentence-pairs contained unfiltered artifacts like timestamps
- Misidentified code-mixed sentences: Some code-mixed sentences miscategorized as English, leading to poor alignment quality and underutilization of data
- Limited alignments: Alignments only included 1-1 sentence matchings, leaving room for better alignments with n-m translation pairs
- Directionality: Data solely in English-Indic direction, while significant potential exists for mining Indic-Indic translation pairs from this source
Addressing Shortcomings in This Work:
- Aim to improve upon issues found in related studies
- Figure 2 shows average LABSE score across language pairs. (Refer to caption)
We obtained 10,669 videos' raw data from NPTEL, including bilingual transcriptions in 8 languages (Bengali to Telugu) with English text interspersed. Refer to Appendix A for an example.
We created a Python script to extract meaningful text from these documents while removing timestamps. The script uses regex patterns and libraries like nltk and indic-nlp to separate English and Indic sentences into parallel document pairs. This creates a massive bitext corpus.
We use a well-established approach called Bitext mining to extract accurate sentence pairs from our parallel corpora. Recent work, such as Vecalign, uses multi-lingual embedding models to find similar sentences based on vector similarity. Our method, SentAlign, employs LABSE and optimized alignment algorithms to achieve high accuracy and efficiency, allowing us to also identify 1-n and n-1 sentence matches.
We collected bilingual sentence-pairs from lectures, creating a massive 2.8M pair dataset after removing duplicates.
Analysis of Dataset Quality and Quantity
- Dataset consists of 8 English-Indic and 28 Indic-Indic language pairs
- Common set of lectures among each pair provides inter-Indic alignments for all languages
- 48.6% are English-to-Indic language pairs due to multiple translations
- Primary measure: Average LABSE similarity scores (Figure 2)
- Strong consistency in scores across all languages despite differences in quantity
- Scores tending towards 0.8, never below 0.75
- Validates quality of source data and accuracy of alignments
- Results are in the form of /<chrf++> (Table 2)
- All models evaluated without beam-search or sampling.
We aim to evaluate our dataset's value by fine-tuning and testing a powerful MT base model against others. Our hypothesis is that our dataset can improve translation performance in the Technical domain.
We have limited options for a state-of-the-art multi-lingual model that can handle 36 language-pair combinations. We rule out IndicTrans2 as it offers separate models for different directions. NLLB-200 and MADLAD-400 are the remaining candidates, both being Transformer-based models with high potential. We choose NLLB-200 due to its superior performance on Indian languages according to the MADLAD paper's results.
Model Sizes and Experiments:
- NLLB-200 models available in various sizes: 600M to 54B parameters
- Choosing 3.3B parameter version for experiments as sweet spot
- Full Fine-Tuning (FFT) approach not feasible due to compute requirements and time
- Parameter-Efficient Fine Tuning (PEFT) method used: Low-Rank Adaptation (LoRA)
- Three approaches for training using LoRA with NLLB 3.3B:
- Training on own dataset only, in one direction
- Curriculum Learning (CL) using cleaned BPCC corpus and 8 Indian languages (4 million rows), then introducing own dataset
- Training on massive 12 million samples including both the cleaned BPCC corpus and own dataset in both directions
- All models trained on a node with 8 NVIDIA A100 40GB GPUs
- Evaluation results for all three models showed similar performance, with third approach performing slightly better.
Model Training Details:
- Three different approaches for model training: CL, own dataset only, and massive samples
- PEFT method used: Low-Rank Adaptation (LoRA)
- NLLB 3.3B model used in all experiments
- All models trained on a node with 8 NVIDIA A100 40GB GPUs
- Hyperparameters and detailed results available in Appendix B.
Model Evaluation:
- Compare third model (trained on 12 million rows) with baseline NLLB model and IndicTrans2
- In-domain test using top one thousand rows by LABSE score from held-out test set for each language
- Model outperforms rest, demonstrating efficacy in technical domain translations
- Tested on Flores+ devtest set:
- Able to generalize well as shown by improvements on baseline scores
- Close to IndicTrans2 which was trained on larger corpus than ours
- Results depicted in Table 2 above, language-wise comparison available in Appendix B.
Our models have been integrated into a tool called Translingua, used by human annotators in India to translate NPTEL lectures into multiple languages at high speed and accuracy.
We introduce Shiksha, a novel Indian language translation dataset and model focused on Scientific, Technical, and Educational domains. With 2.8 million high-quality parallel pairs across 8 languages, our approach improves accuracy and relevance. We fine-tuned state-of-the-art NMT models to achieve significant performance gains in-domain and out-of-domain. Our goal is to highlight the importance of domain-specific datasets for advancing NMT capabilities.
Limitations of the Translation Dataset and Model:
- Heavily skewed towards specific domains: The dataset is primarily sourced from NPTEL video lectures, focusing on scientific, technical, and educational domains. This may lead to degradation in translation quality for general tasks as standard benchmarks may not catch unexpected ways in which this can affect the model's performance.
- Lack of diversity: The dataset covers a narrow range of domains and lacks balance across various contexts. Adding diverse sources, including everyday conversational language, literature, social media, and news articles, is essential to ensure a more stable training process and enhance the system's robustness and accuracy.
- Limited testing on Indic languages: The research focused primarily on translating out of English, so the model's performance may not be optimal for Indic-English or Indic-Indic language directions.
- Dependency on original transcriptions: The quality of the translation dataset and models is heavily dependent upon the accuracy of the original NPTEL transcriptions. Any errors or inconsistencies in them can affect the training and evaluation process, requiring further human evaluation to ensure the quality of these translations.
A bilingual document contains multiple languages in one text.
Our third approach uses these hyperparameters. Previous approaches were trained for 10 epochs and 4 epochs respectively.
{kind=link}