P2P shuffling and queuing combined may cause high memory usage with dask.dataframe.merge
#7496
Comments
dask.dataframe.mergedask.dataframe.merge
|
Edit: Sorry, I believe I misread your comment. I thought you were suggesting that the topological sort is wrong
This is not what the topological sort suggests. Given two simple dataframes df = pd.DataFrame({
"A":[2001,2002,2003],
"B":['Apple','Banana','Coconut']
})
ddf1 = dd.from_pandas(df, 2)
ddf2 = dd.from_pandas(df, 3)
# This join is nonsense, of course but dask doesn't know that ;)
join = dd.merge(ddf1, ddf2, how="inner", shuffle='p2p')we can inspect the join (I used different partition sizes to allow us to distinguish the DFs in the graph
If we look at the ordering, we can clearly see that the first DF is transferred entirely, followed by the barrier and a single unpack. only then it starts to generate and transfer the second dataframe (right hand side). We can further see that once the second dataframe is transferred, the first unpack (18) will be merged by the previously unpacked partition of the first dataframe. from here on, the tasks will be unpacked in corresponding pairs.
If the unpack task pairs do not have the same worker assingment, this will require another data transfer, of course so I would be more interested in knowing how the worker assignment looks like for this case. FWIW I believe tasks with restrictions, i.e. the unpack tasks are not using queuing, yet so this may be a weird interaction between the queued root tasks and the not-queued unpack tasks |


|
This can be easily reproduced from dask.datasets import timeseries
ddf1 = timeseries(
"2020-01-01",
"2030-01-02",
)
ddf2 = timeseries(
"2020-01-01",
"2030-01-02",
)
ddf1.merge(ddf2, shuffle='p2p').compute()screenshot of the tipping point.
|

Sorry, I adjusted the description to be more precise. I skipped over the single unpack to focus on the important part: We should transfer all shuffle data before starting to read (a lot of) outputs.
Agreed, as I said, what happens without queueing is what the topological sort prescribes and what I would expect to happen. |
|
Interesting. I think this is happening because the output tasks use worker restrictions, so they can't be queued. Queuing would handle this graph structure fine. Both the But, because the (as @fjetter showed) here's the graph in priority order:
diff --git a/distributed/scheduler.py b/distributed/scheduler.py
index fa167efc..ec04b7f2 100644
--- a/distributed/scheduler.py
+++ b/distributed/scheduler.py
@@ -2211,7 +2211,10 @@ class SchedulerState:
# removed, there should only be one, which combines co-assignment and
# queuing. Eventually, special-casing root tasks might be removed entirely,
# with better heuristics.
- if math.isinf(self.WORKER_SATURATION):
+ if (
+ math.isinf(self.WORKER_SATURATION)
+ or ts.annotations.get("queue") is False
+ ):
if not (ws := self.decide_worker_rootish_queuing_disabled(ts)):
return {ts.key: "no-worker"}, {}, {}
else:
diff --git a/distributed/shuffle/_shuffle.py b/distributed/shuffle/_shuffle.py
index 2f07b56e..3fbf5336 100644
--- a/distributed/shuffle/_shuffle.py
+++ b/distributed/shuffle/_shuffle.py
@@ -135,7 +135,7 @@ class P2PShuffleLayer(SimpleShuffleLayer):
annotations: dict | None = None,
):
annotations = annotations or {}
- annotations.update({"shuffle": lambda key: key[1]})
+ annotations.update({"shuffle": lambda key: key[1], "queue": False})
super().__init__(
name,
column, |

We'd have to propagate the |
|
Yup, setting a I suppose we could write a HLG optimization to do this for you. This might even be the best option. Implementing the scheduling to make queueing work alongside task restrictions seems like a significant amount of work. |
|
While |
|
Unfortunately we can't do that. Because when a slot opens up on a worker, we just pop the first task off the queue. If that task in fact needs to run on a different worker, we can't use it. We'd end up having to search the queue for a task that can run on the worker. This is at least O(n) per task (sort plus linear search)! The whole design of queuing right now is around tasks being agnostic to which worker they run on (not just regarding restrictions; they don't even have dependencies we need to schedule near). Making queuing performant with tasks that are heterogeneous in any way will require some thought. |
|
@gjoseph92: Yeah, I feared that was the answer. Thanks for reminding me of the implementation! |
|
I'll note that worker restrictions are probably the easiest case of restrictions to add to queueing. Compared to arbitrary (combinations of) resource annotations, for example, worker-restricted tasks are pretty straightforward. You just need a queue per worker, and you don't need to worry about rebalancing those queues (except when restrictions on tasks are changed...). The trickier part is hooking it into the scheduling process. There are now multiple queues from which to source tasks. So you need to take the top K tasks from both queues. That's not hard with just 2 queues, but making it performant when expanding into other types of task restrictions (and potentially many queues) could be more complex. (The disappointing thing is that worker restrictions are probably the least-useful type of restriction for other purposes IMO. Resource restrictions are pretty useful and people actually use them sometimes, worker restrictions I imagine less so in both regards.) |
|
In an offline conversation with @hendrikmakait we discussed the possibility to implement a dedicated |
|
So basically, the This was something we came across a year ago with P2P. Also FYI, you can make this triangle-fused graph structure happen just by making the output tasks Blockwise. (This is desirable anyway, so they can fuse onto subsequent tasks.) Blockwise fusion will automatically create the structure you're looking for. A special However, it opens up a new problem, where a worker joins between when the first and second shuffle starts. Copied from an old internal ticket https://github.com/coiled/dask-engineering/issues/50:
|

I am aware. Using Blockwise might be an option but as you said this would introduce a different problem about worker assignments. I believe this can be avoided if we combine this into a single I also appreciate that Blockwise provides desired task fusing but I'd rather approach this topic in a dedicated step and solve this problem in isolation |
|
Apart from the worker assignment, we are currently using the custom layer also to make sure culling works as intended. (A culled layer generates a new token). If we split this layer up into
we wouldn't be able to regenerate this token IIUC There are also ways to deal with this w/out a custom layer but this is how it currently done |
FWIW, I think we may have already solved that problem: distributed/distributed/shuffle/_scheduler_extension.py Lines 94 to 95 in d74f500 For any of the output tasks, we check if it already has worker restrictions, and if so, we simply assign it to the first worker in there. This means that if we fuse the output tasks, the earlier shuffle initializes the restrictions on the output task, and the later shuffle makes use of the decisions made by the earlier one. |
Yup, it seems like that will do it! Nice.
Ah, makes sense. Switching to blockwise doesn't seem worthwhile then. |
|
I think this is a broader problem than just merges. Any binary operation between two shuffled DataFrames will cause high memory usage—merge is just one particular case of a binary op. Here I trigger it just by doing # run under jemalloc on macos:
# sudo DYLD_INSERT_LIBRARIES=$(brew --prefix jemalloc)/lib/libjemalloc.dylib python p2ptest.py
import dask
import distributed.diagnostics
from dask.datasets import timeseries
if __name__ == "__main__":
with dask.config.set(shuffle="p2p"):
df1_big = timeseries(
"2000-01-01", "2001-01-15", dtypes={str(i): float for i in range(10)}
)
df1_big["predicate"] = df1_big["0"] * 1e9
df1_big = df1_big.astype({"predicate": "int"})
df2_big = timeseries(
"2000-01-01", "2001-01-15", dtypes={str(i): float for i in range(10)}
)
df2_big["predicate"] = df2_big["0"] * 1e9
df2_big = df2_big.astype({"predicate": "int"})
df1_s = df1_big.shuffle("predicate") # probably `set_index` IRL
df2_s = df2_big.shuffle("predicate") # probably `set_index` IRL
binop = df1_s + df2_s
with distributed.Client(
n_workers=4, threads_per_worker=2, memory_limit="2GiB"
) as client:
ms = distributed.diagnostics.MemorySampler()
with ms.sample("queuing on"):
binop.size.compute()
client.run_on_scheduler(
lambda dask_scheduler: setattr(
dask_scheduler, "WORKER_SATURATION", float("inf")
)
)
client.restart()
with ms.sample("queuing off"):
binop.size.compute()
ms.plot(align=True).get_figure().savefig("p2p-binop-memory.png")
Re-setting the index on two dataframes in order to do an aligned binary operation between them is a valid and IMO common use case. I don't think the approach like a I think we'd have to either detect this via a custom graph optimization, and rewrite to the fused graph, or actually handle the worker-restriction case with queuing. |

|
@gjoseph92 your script on my machine produces this I do see the pattern of wrong scheduling but it barely has any effect on this example for me |

|
Interesting. I ran it again and still got the same result. Did you use jemalloc? (I'm using that in place of malloc_trim on macOS.) I can't even get it to complete without jemalloc (the p2p case runs out of memory and crashes). Possibly could also be an intel vs apple silicon difference? FWIW I had to try a few data sizes to get the graph I showed; at smaller data sizes, my results looked more like what you showed here. Also just kind of interesting—I'm realizing this issue is the scheduler equivalent of #6137. |
Yes, strongly suspect that's it. Doesn't matter a lot that my memory profile looks different. With OSX it is also entirely possible that the memory is just compressed well enough. The scheduling pattern is the harmful one and that's what matters. |
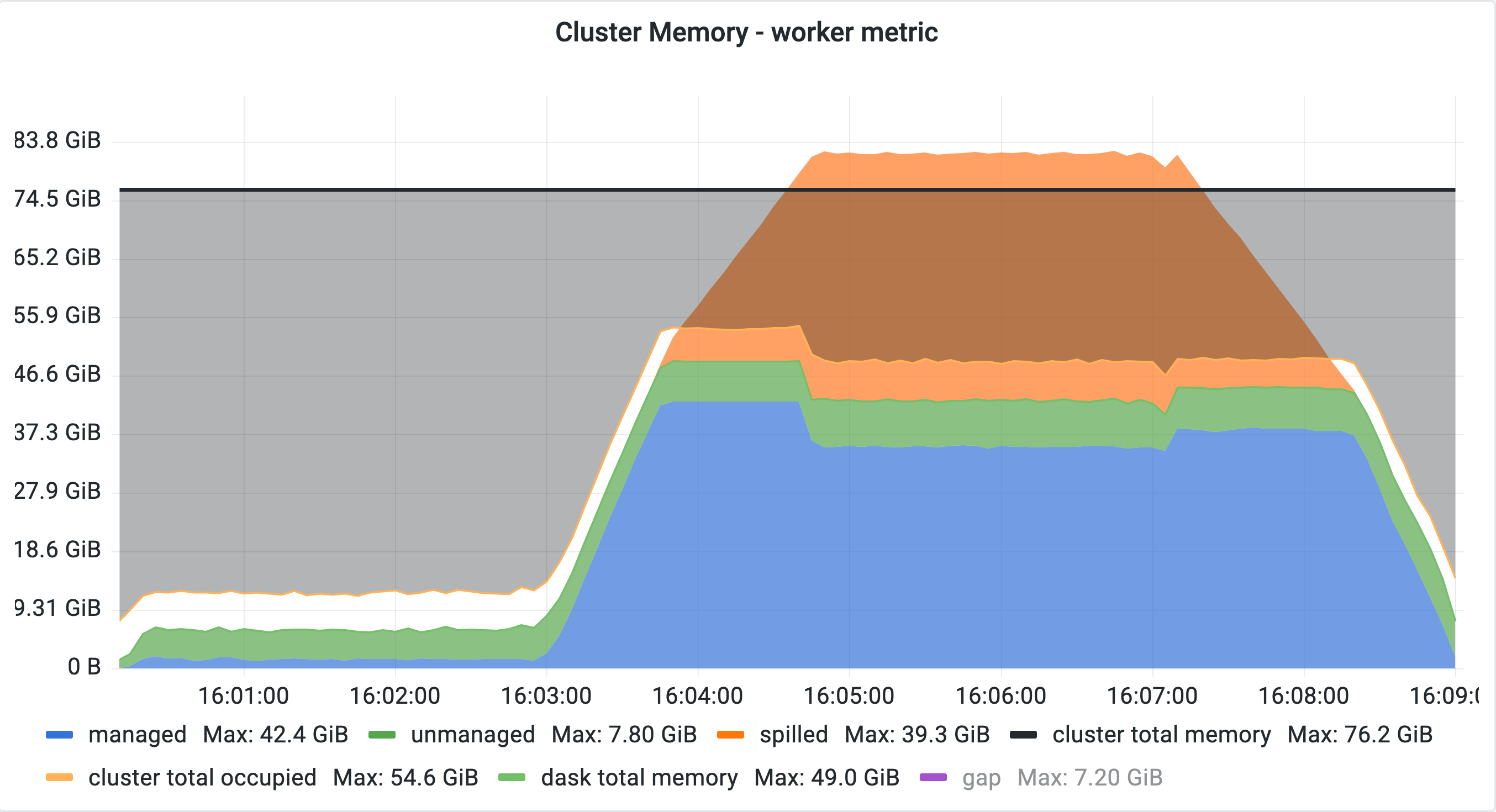
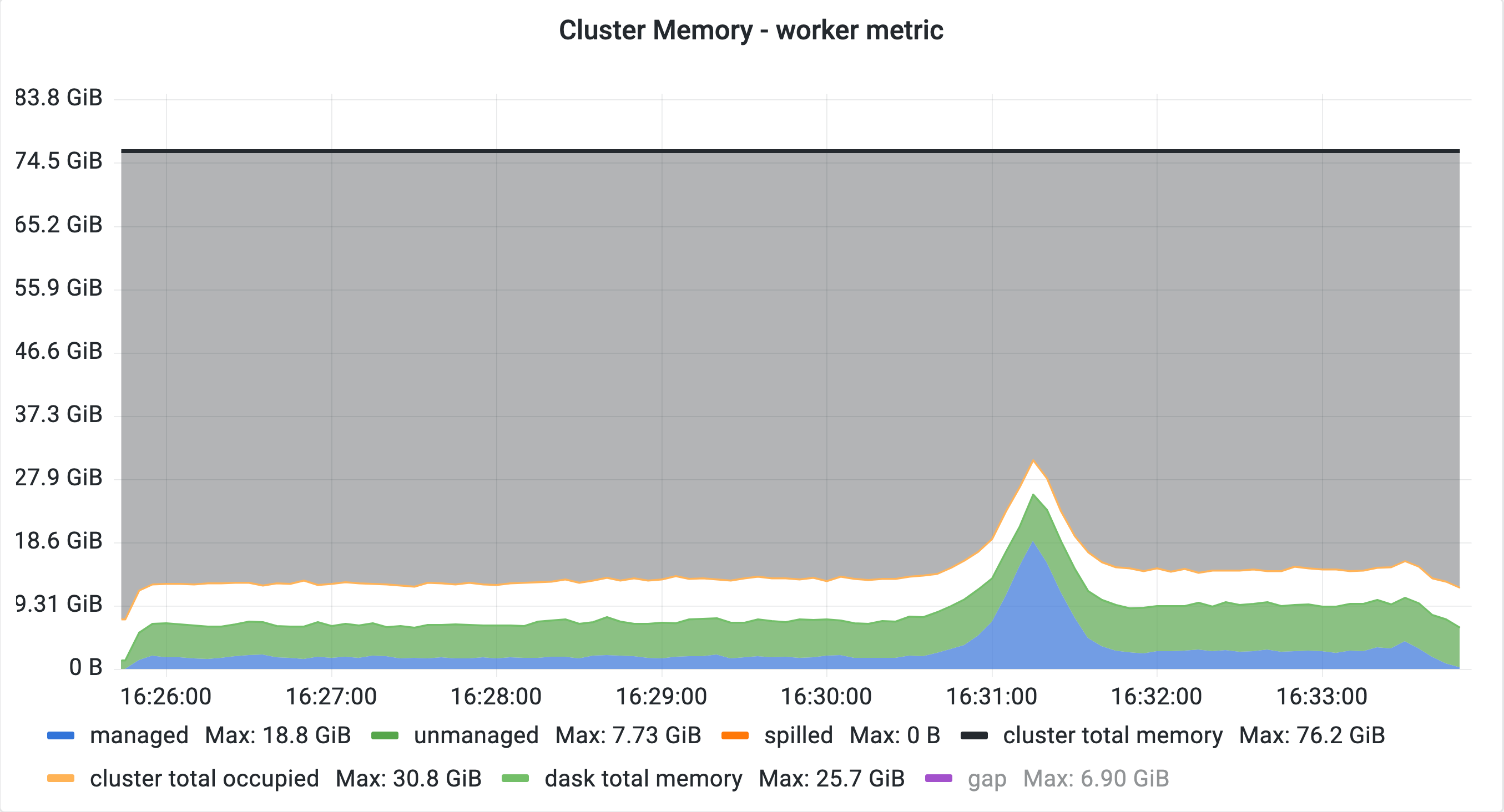
When P2P shuffling and queueing are used together in a workload where two dataframes are merged and both dataframes are generated by rootish tasks, they can cause unnecessarily high memory usage and spilling:
Queuing enabled:
Queuing disabled:
What I expect to happen
We should first finish all transfers of one shuffle as well as its barrier, followed by a single unpack and then the transfers of the second shuffle and the second barrier as prescribed by the topological sort. Once both shuffle barriers are finished, the individual output pairs of the shuffle get read from disk, merged and handed to downstream tasks.
This is what we see without queueing.
What happens instead
All upstream tasks of both shuffles are queued. This causes the scheduler to finish one shuffle transfer followed by its barrier and immediately materialize all of its outputs. The scheduler is forced to ignore the topological sort since the inputs of the second transfer are still queued and therefore ignored while other tasks - the output tasks of the shuffle - are available for execution.
With larger-than-cluster-memory data, this can cause significant spilling, excessive disk I/O, and consequently longer runtime.
Reproducer
The plots above were generated by running
test_join_bigfrom coiled/benchmarks#645 with a size factor of 1x the cluster memory using a cluster of 10 workers. Any workload generating two dataframes using rootish tasks (e.g. by generating random partitions or reading from Parquet) and then merging those two should work.The text was updated successfully, but these errors were encountered: