generated from datatrail-jhu/DataTrail_Template
-
Notifications
You must be signed in to change notification settings - Fork 2
/
03_cleaning_data_08_project_organization.Rmd
278 lines (134 loc) · 20.1 KB
/
03_cleaning_data_08_project_organization.Rmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
```{r, include = FALSE}
ottrpal::set_knitr_image_path()
```
# Project Organization
As you are starting to see, data science projects involve lots of files. There are files of data, files for code, files for documentation, figures, documents to communicate with other people. A surprising amount of doing data science really well is just being good at managing and organizing all of these files so that they are:
* Easy to find
* Easy to share
* Easy to understand
* Easy to update
The reason that you need to make it easy to find and work with the files in your analysis is because data science is really closely related to communication. We use data is to understand the world and communicate that understanding. So when you are building a data science project, you should be thinking about who will be on the receiving end of your data analysis.
While you are actively working on a project it is often easy to find any file you need off the top of your head. But the audience of your data analysis is not you, right now. One audience is other people who you will share your work with. They don't know about all the different places you have stored data, or which piece of code to run first. You need to make it easy on them to be able to understand what you did.

Another audience that may surprise you when you are just starting, but will be familiar to any experienced data analyst is you. A twist on a [famous saying about data science](http://kbroman.org/Tools4RR/assets/lectures/01_intro.pdf) is:
> Your closest co-worker is you six months ago, but you don't reply to emails.
This is because it is really common for you to work on a data science project, present the results, and then move on to another project. But someone else is studying your results and might have questions and want you to make a change. So a few months later, when you've forgotten where everything is, they come back and ask you to make a minor change and you have to dive back in and figure out which files you need to look at.

While this all seems like something very simple and common sense, this is where the biggest problems in data science often happen. Let me give you two quick examples.
The first happened a few years ago. A research group from Duke university analyzed data about human genomes to try to develop a way to predict what chemotherapy each person should get based on their genetic code. They came up with what they thought was a good predictor and published it, then proceeded to start testing it in clinical studies.

Researchers at MD Anderson got so excited about the result that they tried to find the data and code and do the same analysis as a first step to trying the predictor on their patients. But there was a problem, they couldn't find the data or code. They tried getting it from the researchers at Duke, but it took months of back and forth getting a data set here, a file there, none of it too organized. Once they actually managed to get all of the files together and organized, they realized there were some major problems with the predictors that would probably put patients at risk!

Ultimately this discovery shut down the clinical studies and led to a major lawsuit. While there were a lot of problems with the original analysis, the reason there was so much trouble was that the files and code weren't organized so it took a _long_ time to figure out the problems that would put patients at risk.

Another famous example where file organization caused problems was with the scientific paper "Growth in a time of debt". This paper was written by two Harvard economists and suggested that countries with a high level of debt have slow economic growth.

Unlike most academic papers this paper had a big impact! Many countries used this research to justify austerity measures that impacted social and healthcare programs around the world.
But it turns out there were some choices the authors made that were questionable or changed their results. This mistake was so important that it was covered by popular shows like The Colbert Show on Comedy Central. The error was actually discovered by a student, but not until much much later. One reason it took so long is the data and analysis files weren't easily available to everyone and organized in a way that the error could be easily identified.

It isn't just because of errors that you'd want to have organized files and projects. Whether it's helping your future self, communicating a data science idea, or simply reducing your cognitive load, organizing projects from the start can save you a huge amount of time and hassle.
As Jenny Bryan, one of the most famous data scientists in the world, [says](https://github.com/kbroman/datasciquotes)
> File organization and naming are powerful weapons against chaos.

Another famous data scientist, Karl Broman, [suggests](http://kbroman.org/Tools4RR/assets/lectures/06_org_eda.pdf) that the best way to end up with a good file organization system has three steps.
* _Step 1_ slow down and make lots of notes for yourself.
* _Step 2_ have sympathy for your future self.
* _Step 3_ have a standard system that you understand
A key challenge is that its sometimes hard to feel like file organization is "real work". It isn't coding, or making plots, or writing final documents. Sometimes, when working under a deadline, you will feel pressure to skip file organization in favor of quickly producing results and handing them off. But this never pays off in the long run, the results of poorly organized work almost always fail at some point further down the line. As a general rule of thumb it makes sense to budget 10-20% of the time you will be working on a data science project just to organizing and documenting your work.
Keeping your project files organized has the following benefits:
- Easier collaboration: You will see that as a data scientist, you will have to work with teams of other data scientists most of the time. Organizing makes collaboration a lot easier.
- Lower likelihood of making mistakes: When you organize, it is easier for you and others to see where you might have made a mistake before it's too late.
- Easier recall: Going back to your analysis and understanding what you have done in 6 months or a year or even later will be a lot easier. If your project is not organized, it is very likely that you go back to your analysis and do not understand what you or your collaborator have previously done.
- More transparency and honesty on your part: This is because you make it easier for others to go through your files and replicate your analysis.
## Setting Up Data Science Project Folders
As you are working on your project, you will want to keep track of your files and iteratively return to how to organize and name the folders and files in that project.
Naming and organizing files seems very boring, but it one of the most important parts of any data science project! Not having the files or the data available is one of the most common reasons that errors are missed in data science projects.
### A project organization framework
We will set up data science projects on Posit Cloud. Open your web browser and navigate to the website [https://posit.cloud/](https://posit.cloud/).

Then log in and click on the project *my_first_project*.

You should now see a screen that looks like this where there are three windows. The window in the lower right hand corner of the screen is the part that shows all the files you have in your project. Right now there shouldn't be any files since we just created this project in the last lesson but didn't do anything in the project.

Each time you start a new project you will need to create a set of folders for that project. You can create a new folder by clicking on New Folder at the top of the file window.

Then you can type in the name of the folder you want to create. First let's create a folder called _data_.

You should now see a folder called data in the file window.
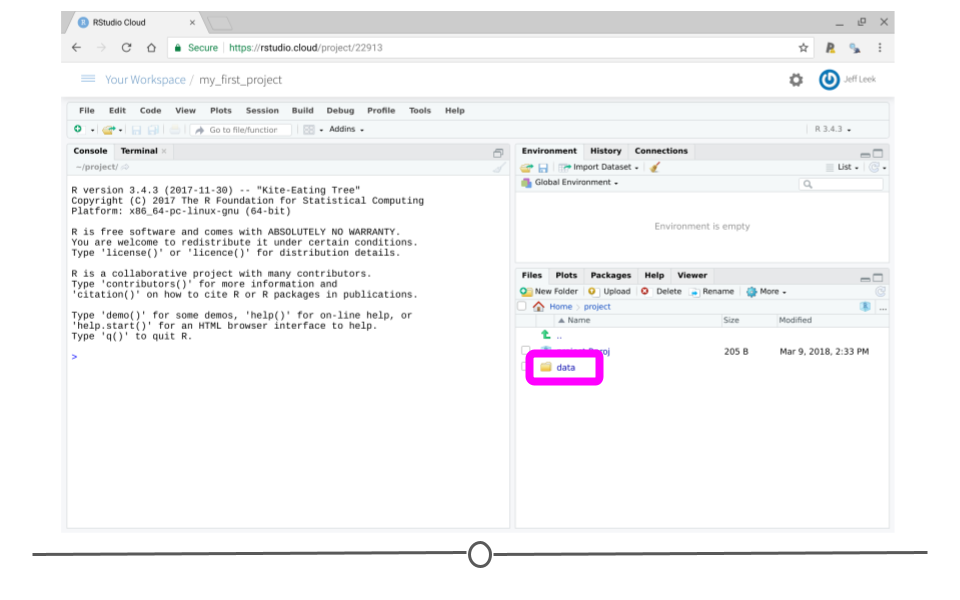
Next we will create a few more folders. For each one click the New Folder button, enter the name and click ok.
Different projects may call for different organization schemes and folder set ups. The rules we give you here may not fit **every** project you work on. But this organizational scheme is a good start that you can iteratively evaluate and change as needed as you continue to work on your project.
These folders represent the four parts of any data science project.
* _raw_data_ - is the folder where you will put all the raw versions of the data you have collected or been given to analyze.
* _tidy_data_ - is the folder where you will put cleaned versions of the data.
* _results_ - is where you will put plots, data pictures, and other results you have created from your data.
* _util_ - code that is not in Rmds, but is more background code that doesn't need to be referenced as much is kept here.
Now that we have these folders in place the next thing you need to create is a README file. This is a file where you will describe all of the data and projects you will be doing. Every project should have a README file so that you can keep notes on what you have done during your project. You will add to this README as your project expands.
To create the README file click _File_ at the top left hand part of Rstudio.

then over over _New File_ to show the types of new files you can create. Move the cursor down and click on _Text File_.

You should see a new screen open with the title _Untitled_ like this.

To save the file click on the disk icon in the top left hand corner of the screen.

Then you can title the file _README.md_ and click _Save_ to save it.

You should now see the README.md file in your file list on the bottom right of the screen.

The next thing to do is fill in the README file with the initial description of your project. For now you can copy this text and paste it into your README file, then click the save button.
```text
# This is the README file for my_first_project
The folders in this project are:
* _raw_data_ - all the raw versions of the data are kept here.
* _tidy_data_ - cleaned versions of the data are here.
* _results_ - results, figures and plots from our data are kept here
* _util_ - code that is not in Rmds, but is more background is kept here.
```
The README file can be used to describe both the high level organization as well as any important special cases about your project. It may be helpful to create additional README files in each subfolder to provide information specific to the files in that subfolder. You would want to link to them from the global README file you have just created.
### The next level of organization
This is the top level of the organization of a new data science project, but we will usually need to create a little more organization within each folder. For example if you click on the data folder you will see that it is empty.

You can see at the top of the file organization tab that you are inside the folder *data* which is inside of the folder *project*.

We need to create two new folders inside of the data folder, one for our raw data and one for our tidy data. You will learn a lot more about them later, but for now use the *New Folder* button

to create one folder called *raw_data* and another called *tidy_data*.

One way to write the folders we have now created is like this.
* data/
* raw_data/
* tidy_data/
* results/
* figures/
* tables/
* util/
Using the same steps we did for creating the folders inside of the *data* folder, you can create the rest of the folders you will need to organize your data science project. Every time you start a new project you will need to do these steps to set up the folders you will need to store all the files you will be creating. In the next lesson we will talk about how to name the files that will go in these folders.
### The README File
Once you have a file structure in place, it's best to write a README file. This file should explain how the code and data are organized as well as how they are related. In other words, explain what is what. For each filename, we recommend to have a short description of what the file is for. You can also have a description of how the data were obtained or collected including links or references to publication or other documentation. Mention people involved with the project, and provide contact information of at least one of the collaborators.
A good idea is to update the README file as you work. As you create new files and folders, add their descriptions to the README file so you can keep track of what you are working on.
You might also make a more detailed README file, which includes a list of variables, units of measurement of each variable, definition of code and symbols used to deal with missing data, Licenses or restrictions on the content of the project including the data, and information about how others should cite your analysis.
### Using Comments
Our next piece of advice is that use comments within your code. Commenting in R is done by adding the pound sign (#). If you add the pound sign at the beginning of each line, R will not read that line as code and will instead skip it. So you can add your explanations about each chunk of code using the pound sign. This is an example of commenting:
```r
# calculates the products of a vector and a matrix
# checks if they can be multiplied first
function (x, y){
if (dim(x)[2] != length(y)) {
stop("Can't multiply matrix%*%vector because the dimensions are wrong")
}
product <- matrix %*% vector
return(product)
}
```
Note that the first line describes what the function does. Commenting is helpful especially when the code is more complicated and harder to understand. Keep comments short and informative and avoid inserting comments for code that have an obvious purpose, i.e. don't add comment for a line of code that adds two variables).
### Write in a modular way
One mistake in writing code is to have everything in one file. This is bad practice since fixing bugs and replicating the analysis would be much harder. Therefore, it is recommended that you write code in a modular way so that each group of code that do similar things can be put in a single file and the master file calls these individual files. The result is a much cleaner and shorter master file.
### Follow a style guide
Just as it's dIsTraCTING 2 reAD A SENtenceTHAT hasWEird **spacing**, puncTUATION, SPELLING. The same is true for code. Code also is easier for yourself and others to read if it is consistent and follows conventions.
Style is not something you need to worry about as you are just starting to work on getting code working, but as you continue to polish a project it is something you will want to return to.
What style you follow is not particularly as important as it is to just follow a style guide in general.
Here's some suggested style guides you may want to use:
- [Google's R Style guide](https://web.stanford.edu/class/cs109l/unrestricted/resources/google-style.html)
- [The tidyverse style guide](https://style.tidyverse.org/)
There's also nifty packages that can automatically style your code for you like the [`styler` package](https://styler.r-lib.org/).