IMPORTANT: This is the documentation for the latest SNAPSHOT version. Please refer to the website at http://getquill.io for the latest release's documentation.

Compile-time Language Integrated Query for Scala


Quill provides a Quoted Domain Specific Language (QDSL) to express queries in Scala and execute them in a target language. The library's core is designed to support multiple target languages, currently featuring specializations for Structured Query Language (SQL) and Cassandra Query Language (CQL).
ProtoQuill provides Scala 3 support for Quill rebuilding on top of new metaprogramming capabilities from the ground > up! It is published to maven-central as the
quill-<module>_3line of artifacts.
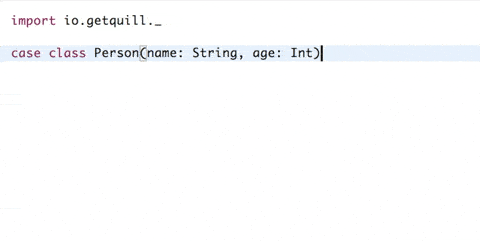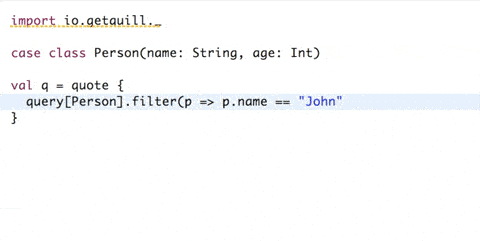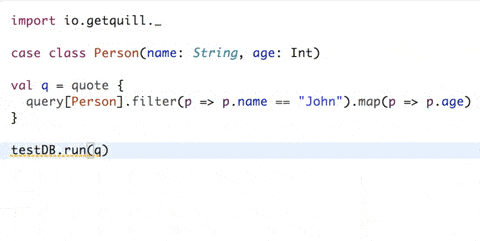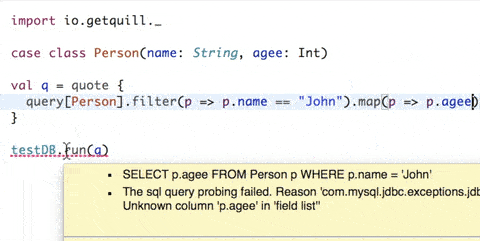
- Boilerplate-free mapping: The database schema is mapped using simple case classes.
- Quoted DSL: Queries are defined inside a
quoteblock. Quill parses each quoted block of code (quotation) at compile time and translates them to an internal Abstract Syntax Tree (AST) - Compile-time query generation: The
ctx.runcall reads the quotation's AST and translates it to the target language at compile time, emitting the query string as a compilation message. As the query string is known at compile time, the runtime overhead is very low and similar to using the database driver directly. - Compile-time query validation: If configured, the query is verified against the database at compile time and the compilation fails if it is not valid. The query validation does not alter the database state.
Note: The GIF example uses Eclipse, which shows compilation messages to the user.
Scastie is a great tool to try out Quill without having to prepare a local environment. It works with mirror contexts, see this snippet as an example.
Quill has integrations with many libraries. If you are using a regular RDBMS e.g. PostgreSQL and want to use Quill to query it with an asychronous, non-blocking, reactive application, the easiest way to get started is by using an awesome library called ZIO.
A simple ZIO + Quill application looks like this:
case class Person(name: String, age: Int)
object QuillContext extends PostgresZioJdbcContext(SnakeCase)
object DataService {
import QuillContext._
def getPeople = run(query[Person])
}
object Main extends App {
override def run(args: List[String]) =
DataService.getPeople
.inject(DataSourceLayer.fromPrefix("myDatabaseConfig").orDie)
.debug("Results")
.exitCode
}Add the following to build.sbt:
libraryDependencies ++= Seq(
"io.getquill" %% "quill-jdbc-zio" % "3.12.0",
"io.github.kitlangton" %% "zio-magic" % "0.3.11",
"org.postgresql" % "postgresql" % "42.3.1"
)You can find this code (with some more examples) complete with a docker-provided Postgres database here.
Choose the quill module that works for you!
- If you are starting from scratch with a regular RDBMS try using the
quill-jdbc-ziomodule as shown above. - If you are developing a legacy Java project and don't want/need reactive, use
quill-jdbc. - If you are developing a project with Cats and/or Monix, try
quill-jdbc-monix. - If you like to "live dangerously" and want to try a socket-level async library, try
quill-jasync-postgresorquill-jasync-mysql. - If you are using Cassandra, Spark, or OrientDB, try the corresponding modules for each of them.
The QDSL allows the user to write plain Scala code, leveraging Scala's syntax and type system. Quotations are created using the quote method and can contain any excerpt of code that uses supported operations. To create quotations, first create a context instance. Please see the context section for more details on the different context available.
For this documentation, a special type of context that acts as a mirror is used:
import io.getquill._
val ctx = new SqlMirrorContext(MirrorSqlDialect, Literal)The context instance provides all the types, methods, and encoders/decoders needed for quotations:
import ctx._A quotation can be a simple value:
val pi = quote(3.14159)And be used within another quotation:
case class Circle(radius: Float)
val areas = quote {
query[Circle].map(c => pi * c.radius * c.radius)
}Quotations can also contain high-order functions and inline values:
val area = quote {
(c: Circle) => {
val r2 = c.radius * c.radius
pi * r2
}
}val areas = quote {
query[Circle].map(c => area(c))
}Quill's normalization engine applies reduction steps before translating the quotation to the target language. The correspondent normalized quotation for both versions of the areas query is:
val areas = quote {
query[Circle].map(c => 3.14159 * c.radius * c.radius)
}Scala doesn't have support for high-order functions with type parameters. It's possible to use a method type parameter for this purpose:
def existsAny[T] = quote {
(xs: Query[T]) => (p: T => Boolean) =>
xs.filter(p(_)).nonEmpty
}
val q = quote {
query[Circle].filter { c1 =>
existsAny(query[Circle])(c2 => c2.radius > c1.radius)
}
}You can also use implicit classes to extend things in quotations.
implicit class Ext(q: Query[Person]) {
def olderThan(age: Int) = quote {
query[Person].filter(p => p.age > lift(age))
}
}
run(query[Person].olderThan(44))(see implicit-extensions for additional information.)
Quotations are both compile-time and runtime values. Quill uses a type refinement to store the quotation's AST as an annotation available at compile-time and the q.ast method exposes the AST as runtime value.
It is important to avoid giving explicit types to quotations when possible. For instance, this quotation can't be read at compile-time as the type refinement is lost:
// Avoid type widening (Quoted[Query[Circle]]), or else the quotation will be dynamic.
val q: Quoted[Query[Circle]] = quote {
query[Circle].filter(c => c.radius > 10)
}
ctx.run(q) // Dynamic queryQuill falls back to runtime normalization and query generation if the quotation's AST can't be read at compile-time. Please refer to dynamic queries for more information.
Quoting is implicit when writing a query in a run statement.
ctx.run(query[Circle].map(_.radius))
// SELECT r.radius FROM Circle rQuotations are designed to be self-contained, without references to runtime values outside their scope. There are two mechanisms to explicitly bind runtime values to a quotation execution.
A runtime value can be lifted to a quotation through the method lift:
def biggerThan(i: Float) = quote {
query[Circle].filter(r => r.radius > lift(i))
}
ctx.run(biggerThan(10)) // SELECT r.radius FROM Circle r WHERE r.radius > ?Note that literal-constants do not need to be lifted, they can be used in queries directly. Literal constants are supported starting Scala 2.12.
final val minAge = 21 // This is the same as: final val minAge: 21 = 21
ctx.run(query[Person].filter(p => p.age > minAge)) // SELECT p.name, p.age FROM Person p WHERE p.name > 21A Iterable instance can be lifted as a Query. There are two main usages for lifted queries:
def find(radiusList: List[Float]) = quote {
query[Circle].filter(r => liftQuery(radiusList).contains(r.radius))
}
ctx.run(find(List(1.1F, 1.2F)))
// SELECT r.radius FROM Circle r WHERE r.radius IN (?)def insertValues(circles: List[Circle]) = quote {
liftQuery(circles).foreach(c => query[Circle].insertValue(c))
}
ctx.run(insertValues(List(Circle(1.1F), Circle(1.2F))))
// INSERT INTO Circle (radius) VALUES (?)The database schema is represented by case classes. By default, quill uses the class and field names as the database identifiers:
case class Circle(radius: Float)
val q = quote {
query[Circle].filter(c => c.radius > 1)
}
ctx.run(q) // SELECT c.radius FROM Circle c WHERE c.radius > 1Alternatively, the identifiers can be customized:
val circles = quote {
querySchema[Circle]("circle_table", _.radius -> "radius_column")
}
val q = quote {
circles.filter(c => c.radius > 1)
}
ctx.run(q)
// SELECT c.radius_column FROM circle_table c WHERE c.radius_column > 1If multiple tables require custom identifiers, it is good practice to define a schema object with all table queries to be reused across multiple queries:
case class Circle(radius: Int)
case class Rectangle(length: Int, width: Int)
object schema {
val circles = quote {
querySchema[Circle](
"circle_table",
_.radius -> "radius_column")
}
val rectangles = quote {
querySchema[Rectangle](
"rectangle_table",
_.length -> "length_column",
_.width -> "width_column")
}
}Database generated values can be returned from an insert query by using .returningGenerated. These properties
will also be excluded from the insertion since they are database generated.
case class Product(id: Int, description: String, sku: Long)
val q = quote {
query[Product].insertValue(lift(Product(0, "My Product", 1011L))).returningGenerated(_.id)
}
val returnedIds = ctx.run(q) //: List[Int]
// INSERT INTO Product (description,sku) VALUES (?, ?) -- NOTE that 'id' is not being inserted.Multiple properties can be returned in a Tuple or Case Class and all of them will be excluded from insertion.
NOTE: Using multiple properties is currently supported by Postgres, Oracle and SQL Server
// Assuming sku is generated by the database.
val q = quote {
query[Product].insertValue(lift(Product(0, "My Product", 1011L))).returningGenerated(r => (id, sku))
}
val returnedIds = ctx.run(q) //: List[(Int, Long)]
// INSERT INTO Product (description) VALUES (?) RETURNING id, sku -- NOTE that 'id' and 'sku' are not being inserted.In certain situations, we might want to return fields that are not auto generated as well. In this case we do not want
the fields to be automatically excluded from the insertion. The returning method is used for that.
val q = quote {
query[Product].insertValue(lift(Product(0, "My Product", 1011L))).returning(r => (id, description))
}
val returnedIds = ctx.run(q) //: List[(Int, String)]
// INSERT INTO Product (id, description, sku) VALUES (?, ?, ?) RETURNING id, descriptionWait a second! Why did we just insert id into the database? That is because returning does not exclude values
from the insertion! We can fix this situation by manually specifying the columns to insert:
val q = quote {
query[Product].insert(_.description -> "My Product", _.sku -> 1011L))).returning(r => (id, description))
}
val returnedIds = ctx.run(q) //: List[(Int, String)]
// INSERT INTO Product (description, sku) VALUES (?, ?) RETURNING id, descriptionWe can also fix this situation by using an insert-meta.
implicit val productInsertMeta = insertMeta[Product](_.id)
val q = quote {
query[Product].insertValue(lift(Product(0L, "My Product", 1011L))).returning(r => (id, description))
}
val returnedIds = ctx.run(q) //: List[(Int, String)]
// INSERT INTO Product (description, sku) VALUES (?, ?) RETURNING id, descriptionreturning can also be used after updateValue:
val q = quote {
query[Product].updateValue(lift(Product(42, "Updated Product", 2022L))).returning(r => (r.id, r.description))
}
val updated = ctx.run(q) //: List[(Int, String)]
// UPDATE Product SET id = ?, description = ?, sku = ? RETURNING id, descriptionor even after delete:
val q = quote {
query[Product].delete.returning(r => (r.id, r.description))
}
val deleted = ctx.run(q) //: List[(Int, String)]
// DELETE FROM Product RETURNING id, descriptionValues returned can be further customized in some databases.
The returning and returningGenerated methods also support arithmetic operations, SQL UDFs and
even entire queries. These are inserted directly into the SQL RETURNING clause.
Assuming this basic query:
val q = quote {
query[Product].insert(_.description -> "My Product", _.sku -> 1011L)
}Add 100 to the value of id:
ctx.run(q.returning(r => r.id + 100)) //: List[Int]
// INSERT INTO Product (description, sku) VALUES (?, ?) RETURNING id + 100Pass the value of id into a UDF:
val udf = quote { (i: Long) => infix"myUdf($i)".as[Int] }
ctx.run(q.returning(r => udf(r.id))) //: List[Int]
// INSERT INTO Product (description, sku) VALUES (?, ?) RETURNING myUdf(id)Use the return value of sku to issue a query:
case class Supplier(id: Int, clientSku: Long)
ctx.run {
q.returning(r => query[Supplier].filter(s => s.sku == r.sku).map(_.id).max)
} //: List[Option[Long]]
// INSERT INTO Product (description,sku) VALUES ('My Product', 1011) RETURNING (SELECT MAX(s.id) FROM Supplier s WHERE s.sku = clientSku)As is typically the case with Quill, you can use all of these features together.
ctx.run {
q.returning(r =>
(r.id + 100, udf(r.id), query[Supplier].filter(s => s.sku == r.sku).map(_.id).max)
)
} // List[(Int, Int, Option[Long])]
// INSERT INTO Product (description,sku) VALUES ('My Product', 1011)
// RETURNING id + 100, myUdf(id), (SELECT MAX(s.id) FROM Supplier s WHERE s.sku = sku)NOTE: Queries used inside of return clauses can only return a single row per insert. Otherwise, Postgres will throw:
ERROR: more than one row returned by a subquery used as an expression. This is why is it strongly recommended that you use aggregators such asmaxormininside of quill returning-clause queries. In the case that this is impossible (e.g. when using Postgres booleans), you can use the.valuemethod:q.returning(r => query[Supplier].filter(s => s.sku == r.sku).map(_.id).value).
The returning and returningGenerated methods are more restricted when using SQL Server; they only support
arithmetic operations. These are inserted directly into the SQL OUTPUT INSERTED.* or OUTPUT DELETED.* clauses.
Assuming the query:
val q = quote {
query[Product].insert(_.description -> "My Product", _.sku -> 1011L)
}Add 100 to the value of id:
ctx.run(q.returning(r => id + 100)) //: List[Int]
// INSERT INTO Product (description, sku) OUTPUT INSERTED.id + 100 VALUES (?, ?)Update returning:
val q = quote {
query[Product].update(_.description -> "Updated Product", _.sku -> 2022L).returning(r => (r.id, r.description))
}
val updated = ctx.run(q)
// UPDATE Product SET description = 'Updated Product', sku = 2022 OUTPUT INSERTED.id, INSERTED.descriptionDelete returning:
val q = quote {
query[Product].delete.returning(r => (r.id, r.description))
}
val updated = ctx.run(q)
// DELETE FROM Product OUTPUT DELETED.id, DELETED.descriptionQuill supports nested Embedded case classes:
case class Contact(phone: String, address: String) extends Embedded
case class Person(id: Int, name: String, contact: Contact)
ctx.run(query[Person])
// SELECT x.id, x.name, x.phone, x.address FROM Person xNote that default naming behavior uses the name of the nested case class properties. It's possible to override this default behavior using a custom schema:
case class Contact(phone: String, address: String) extends Embedded
case class Person(id: Int, name: String, homeContact: Contact, workContact: Option[Contact])
val q = quote {
querySchema[Person](
"Person",
_.homeContact.phone -> "homePhone",
_.homeContact.address -> "homeAddress",
_.workContact.map(_.phone) -> "workPhone",
_.workContact.map(_.address) -> "workAddress"
)
}
ctx.run(q)
// SELECT x.id, x.name, x.homePhone, x.homeAddress, x.workPhone, x.workAddress FROM Person xThe overall abstraction of quill queries uses database tables as if they were in-memory collections. Scala for-comprehensions provide syntactic sugar to deal with these kinds of monadic operations:
case class Person(id: Int, name: String, age: Int)
case class Contact(personId: Int, phone: String)
val q = quote {
for {
p <- query[Person] if(p.id == 999)
c <- query[Contact] if(c.personId == p.id)
} yield {
(p.name, c.phone)
}
}
ctx.run(q)
// SELECT p.name, c.phone FROM Person p, Contact c WHERE (p.id = 999) AND (c.personId = p.id)Quill normalizes the quotation and translates the monadic joins to applicative joins, generating a database-friendly query that avoids nested queries.
Any of the following features can be used together with the others and/or within a for-comprehension:
val q = quote {
query[Person].filter(p => p.age > 18)
}
ctx.run(q)
// SELECT p.id, p.name, p.age FROM Person p WHERE p.age > 18val q = quote {
query[Person].map(p => p.name)
}
ctx.run(q)
// SELECT p.name FROM Person pval q = quote {
query[Person].filter(p => p.age > 18).flatMap(p => query[Contact].filter(c => c.personId == p.id))
}
ctx.run(q)
// SELECT c.personId, c.phone FROM Person p, Contact c WHERE (p.age > 18) AND (c.personId = p.id)// similar to `flatMap` but for transformations that return a traversable instead of `Query`
val q = quote {
query[Person].concatMap(p => p.name.split(" "))
}
ctx.run(q)
// SELECT UNNEST(SPLIT(p.name, " ")) FROM Person pval q1 = quote {
query[Person].sortBy(p => p.age)
}
ctx.run(q1)
// SELECT p.id, p.name, p.age FROM Person p ORDER BY p.age ASC NULLS FIRST
val q2 = quote {
query[Person].sortBy(p => p.age)(Ord.descNullsLast)
}
ctx.run(q2)
// SELECT p.id, p.name, p.age FROM Person p ORDER BY p.age DESC NULLS LAST
val q3 = quote {
query[Person].sortBy(p => (p.name, p.age))(Ord(Ord.asc, Ord.desc))
}
ctx.run(q3)
// SELECT p.id, p.name, p.age FROM Person p ORDER BY p.name ASC, p.age DESCval q = quote {
query[Person].drop(2).take(1)
}
ctx.run(q)
// SELECT x.id, x.name, x.age FROM Person x LIMIT 1 OFFSET 2val q = quote {
query[Person].groupBy(p => p.age).map {
case (age, people) =>
(age, people.size)
}
}
ctx.run(q)
// SELECT p.age, COUNT(*) FROM Person p GROUP BY p.ageval q = quote {
query[Person].filter(p => p.age > 18).union(query[Person].filter(p => p.age > 60))
}
ctx.run(q)
// SELECT x.id, x.name, x.age FROM (SELECT id, name, age FROM Person p WHERE p.age > 18
// UNION SELECT id, name, age FROM Person p1 WHERE p1.age > 60) xval q = quote {
query[Person].filter(p => p.age > 18).unionAll(query[Person].filter(p => p.age > 60))
}
ctx.run(q)
// SELECT x.id, x.name, x.age FROM (SELECT id, name, age FROM Person p WHERE p.age > 18
// UNION ALL SELECT id, name, age FROM Person p1 WHERE p1.age > 60) x
val q2 = quote {
query[Person].filter(p => p.age > 18) ++ query[Person].filter(p => p.age > 60)
}
ctx.run(q2)
// SELECT x.id, x.name, x.age FROM (SELECT id, name, age FROM Person p WHERE p.age > 18
// UNION ALL SELECT id, name, age FROM Person p1 WHERE p1.age > 60) xval r = quote {
query[Person].map(p => p.age)
}
ctx.run(r.min) // SELECT MIN(p.age) FROM Person p
ctx.run(r.max) // SELECT MAX(p.age) FROM Person p
ctx.run(r.avg) // SELECT AVG(p.age) FROM Person p
ctx.run(r.sum) // SELECT SUM(p.age) FROM Person p
ctx.run(r.size) // SELECT COUNT(p.age) FROM Person pval q = quote {
query[Person].filter{ p1 =>
query[Person].filter(p2 => p2.id != p1.id && p2.age == p1.age).isEmpty
}
}
ctx.run(q)
// SELECT p1.id, p1.name, p1.age FROM Person p1 WHERE
// NOT EXISTS (SELECT * FROM Person p2 WHERE (p2.id <> p1.id) AND (p2.age = p1.age))
val q2 = quote {
query[Person].filter{ p1 =>
query[Person].filter(p2 => p2.id != p1.id && p2.age == p1.age).nonEmpty
}
}
ctx.run(q2)
// SELECT p1.id, p1.name, p1.age FROM Person p1 WHERE
// EXISTS (SELECT * FROM Person p2 WHERE (p2.id <> p1.id) AND (p2.age = p1.age))val q = quote {
query[Person].filter(p => liftQuery(Set(1, 2)).contains(p.id))
}
ctx.run(q)
// SELECT p.id, p.name, p.age FROM Person p WHERE p.id IN (?, ?)
val q1 = quote { (ids: Query[Int]) =>
query[Person].filter(p => ids.contains(p.id))
}
ctx.run(q1(liftQuery(List(1, 2))))
// SELECT p.id, p.name, p.age FROM Person p WHERE p.id IN (?, ?)
val peopleWithContacts = quote {
query[Person].filter(p => query[Contact].filter(c => c.personId == p.id).nonEmpty)
}
val q2 = quote {
query[Person].filter(p => peopleWithContacts.contains(p.id))
}
ctx.run(q2)
// SELECT p.id, p.name, p.age FROM Person p WHERE p.id IN (SELECT p1.* FROM Person p1 WHERE EXISTS (SELECT c.* FROM Contact c WHERE c.personId = p1.id))val q = quote {
query[Person].map(p => p.age).distinct
}
ctx.run(q)
// SELECT DISTINCT p.age FROM Person pval q = quote {
query[Person].filter(p => p.name == "John").nested.map(p => p.age)
}
ctx.run(q)
// SELECT p.age FROM (SELECT p.age FROM Person p WHERE p.name = 'John') pJoins are arguably the largest source of complexity in most SQL queries. Quill offers a few different syntaxes so you can choose the right one for your use-case!
case class A(id: Int)
case class B(fk: Int)
// Applicative Joins:
quote {
query[A].join(query[B]).on(_.id == _.fk)
}
// Implicit Joins:
quote {
for {
a <- query[A]
b <- query[B] if (a.id == b.fk)
} yield (a, b)
}
// Flat Joins:
quote {
for {
a <- query[A]
b <- query[B].join(_.fk == a.id)
} yield (a, b)
}Let's see them one by one assuming the following schema:
case class Person(id: Int, name: String)
case class Address(street: String, zip: Int, fk: Int)(Note: If your use case involves lots and lots of joins, both inner and outer. Skip right to the flat-joins section!)
Applicative joins are useful for joining two tables together, they are straightforward to understand, and typically look good on one line. Quill supports inner, left-outer, right-outer, and full-outer (i.e. cross) applicative joins.
// Inner Join
val q = quote {
query[Person].join(query[Address]).on(_.id == _.fk)
}
ctx.run(q) //: List[(Person, Address)]
// SELECT x1.id, x1.name, x2.street, x2.zip, x2.fk
// FROM Person x1 INNER JOIN Address x2 ON x1.id = x2.fk
// Left (Outer) Join
val q = quote {
query[Person].leftJoin(query[Address]).on((p, a) => p.id == a.fk)
}
ctx.run(q) //: List[(Person, Option[Address])]
// Note that when you use named-variables in your comprehension, Quill does its best to honor them in the query.
// SELECT p.id, p.name, a.street, a.zip, a.fk
// FROM Person p LEFT JOIN Address a ON p.id = a.fk
// Right (Outer) Join
val q = quote {
query[Person].rightJoin(query[Address]).on((p, a) => p.id == a.fk)
}
ctx.run(q) //: List[(Option[Person], Address)]
// SELECT p.id, p.name, a.street, a.zip, a.fk
// FROM Person p RIGHT JOIN Address a ON p.id = a.fk
// Full (Outer) Join
val q = quote {
query[Person].fullJoin(query[Address]).on((p, a) => p.id == a.fk)
}
ctx.run(q) //: List[(Option[Person], Option[Address])]
// SELECT p.id, p.name, a.street, a.zip, a.fk
// FROM Person p FULL JOIN Address a ON p.id = a.fkWhat about joining more than two tables with the applicative syntax? Here's how to do that:
case class Company(zip: Int)
// All is well for two tables but for three or more, the nesting mess begins:
val q = quote {
query[Person]
.join(query[Address]).on({case (p, a) => p.id == a.fk}) // Let's use `case` here to stay consistent
.join(query[Company]).on({case ((p, a), c) => a.zip == c.zip})
}
ctx.run(q) //: List[((Person, Address), Company)]
// (Unfortunately when you use `case` statements, Quill can't help you with the variables names either!)
// SELECT x01.id, x01.name, x11.street, x11.zip, x11.fk, x12.name, x12.zip
// FROM Person x01 INNER JOIN Address x11 ON x01.id = x11.fk INNER JOIN Company x12 ON x11.zip = x12.zipNo worries though, implicit joins and flat joins have your other use-cases covered!
Quill's implicit joins use a monadic syntax making them pleasant to use for joining many tables together. They look a lot like Scala collections when used in for-comprehensions making them familiar to a typical Scala developer. What's the catch? They can only do inner-joins.
val q = quote {
for {
p <- query[Person]
a <- query[Address] if (p.id == a.fk)
} yield (p, a)
}
run(q) //: List[(Person, Address)]
// SELECT p.id, p.name, a.street, a.zip, a.fk
// FROM Person p, Address a WHERE p.id = a.fkNow, this is great because you can keep adding more and more joins without having to do any pesky nesting.
val q = quote {
for {
p <- query[Person]
a <- query[Address] if (p.id == a.fk)
c <- query[Company] if (c.zip == a.zip)
} yield (p, a, c)
}
run(q) //: List[(Person, Address, Company)]
// SELECT p.id, p.name, a.street, a.zip, a.fk, c.name, c.zip
// FROM Person p, Address a, Company c WHERE p.id = a.fk AND c.zip = a.zipWell that looks nice but wait! What If I need to inner, and outer join lots of tables nicely? No worries, flat-joins are here to help!
Flat Joins give you the best of both worlds! In the monadic syntax, you can use both inner joins, and left-outer joins together without any of that pesky nesting.
// Inner Join
val q = quote {
for {
p <- query[Person]
a <- query[Address].join(a => a.fk == p.id)
} yield (p,a)
}
ctx.run(q) //: List[(Person, Address)]
// SELECT p.id, p.name, a.street, a.zip, a.fk
// FROM Person p INNER JOIN Address a ON a.fk = p.id
// Left (Outer) Join
val q = quote {
for {
p <- query[Person]
a <- query[Address].leftJoin(a => a.fk == p.id)
} yield (p,a)
}
ctx.run(q) //: List[(Person, Option[Address])]
// SELECT p.id, p.name, a.street, a.zip, a.fk
// FROM Person p LEFT JOIN Address a ON a.fk = p.idNow you can keep adding both right and left joins without nesting!
val q = quote {
for {
p <- query[Person]
a <- query[Address].join(a => a.fk == p.id)
c <- query[Company].leftJoin(c => c.zip == a.zip)
} yield (p,a,c)
}
ctx.run(q) //: List[(Person, Address, Option[Company])]
// SELECT p.id, p.name, a.street, a.zip, a.fk, c.name, c.zip
// FROM Person p
// INNER JOIN Address a ON a.fk = p.id
// LEFT JOIN Company c ON c.zip = a.zipCan't figure out what kind of join you want to use? Who says you have to choose?
With Quill the following multi-join queries are equivalent, use them according to preference:
case class Employer(id: Int, personId: Int, name: String)
val qFlat = quote {
for{
(p,e) <- query[Person].join(query[Employer]).on(_.id == _.personId)
c <- query[Contact].leftJoin(_.personId == p.id)
} yield(p, e, c)
}
val qNested = quote {
for{
((p,e),c) <-
query[Person].join(query[Employer]).on(_.id == _.personId)
.leftJoin(query[Contact]).on(
_._1.id == _.personId
)
} yield(p, e, c)
}
ctx.run(qFlat)
ctx.run(qNested)
// SELECT p.id, p.name, p.age, e.id, e.personId, e.name, c.id, c.phone
// FROM Person p INNER JOIN Employer e ON p.id = e.personId LEFT JOIN Contact c ON c.personId = p.idNote that in some cases implicit and flat joins cannot be used together, for example, the following query will fail.
val q = quote {
for {
p <- query[Person]
p1 <- query[Person] if (p1.name == p.name)
c <- query[Contact].leftJoin(_.personId == p.id)
} yield (p, c)
}
// ctx.run(q)
// java.lang.IllegalArgumentException: requirement failed: Found an `ON` table reference of a table that is
// not available: Set(p). The `ON` condition can only use tables defined through explicit joins.This happens because an explicit join typically cannot be done after an implicit join in the same query.
A good guideline is in any query or subquery, choose one of the following:
- Use flat-joins + applicative joins or
- Use implicit joins
Also, note that not all Option operations are available on outer-joined tables (i.e. tables wrapped in an Option object),
only a specific subset. This is mostly due to the inherent limitations of SQL itself. For more information, see the
'Optional Tables' section.
Note that the behavior of Optionals has recently changed to include stricter null-checks. See the orNull / getOrNull section for more details.
Option objects are used to encode nullable fields. Say you have the following schema:
CREATE TABLE Person(
id INT NOT NULL PRIMARY KEY,
name VARCHAR(255) -- This is nullable!
);
CREATE TABLE Address(
fk INT, -- This is nullable!
street VARCHAR(255) NOT NULL,
zip INT NOT NULL,
CONSTRAINT a_to_p FOREIGN KEY (fk) REFERENCES Person(id)
);
CREATE TABLE Company(
name VARCHAR(255) NOT NULL,
zip INT NOT NULL
)This would encode to the following:
case class Person(id:Int, name:Option[String])
case class Address(fk:Option[Int], street:String, zip:Int)
case class Company(name:String, zip:Int)Some important notes regarding Optionals and nullable fields.
In many cases, Quill tries to rely on the null-fallthrough behavior that is ANSI standard:
null == null := falsenull == [true | false] := falseThis allows the generated SQL for most optional operations to be simple. For example, the expression
Option[String].map(v => v + "foo")can be expressed as the SQLv || 'foo'as opposed toCASE IF (v is not null) v || 'foo' ELSE null ENDso long as the concatenation operator||"falls-through" and returnsnullwhen the input is null. This is not true of all databases (e.g. Oracle), forcing Quill to return the longer expression with explicit null-checking. Also, if there are conditionals inside of an Option operation (e.g.o.map(v => if (v == "x") "y" else "z")) this creates SQL with case statements, which will never fall-through when the input value is null. This forces Quill to explicitly null-check such statements in every SQL dialect.
Let's go through the typical operations of optionals.
The isDefined method is generally a good way to null-check a nullable field:
val q = quote {
query[Address].filter(a => a.fk.isDefined)
}
ctx.run(q)
// SELECT a.fk, a.street, a.zip FROM Address a WHERE a.fk IS NOT NULLThe isEmpty method works the same way:
val q = quote {
query[Address].filter(a => a.fk.isEmpty)
}
ctx.run(q)
// SELECT a.fk, a.street, a.zip FROM Address a WHERE a.fk IS NULLThis method is typically used for inspecting nullable fields inside of boolean conditions, most notably joining!
val q = quote {
query[Person].join(query[Address]).on((p, a)=> a.fk.exists(_ == p.id))
}
ctx.run(q)
// SELECT p.id, p.name, a.fk, a.street, a.zip FROM Person p INNER JOIN Address a ON a.fk = p.idNote that in the example above, the exists method does not cause the generated
SQL to do an explicit null-check in order to express the False case. This is because Quill relies on the
typical database behavior of immediately falsifying a statement that has null on one side of the equation.
Use this method in boolean conditions that should succeed in the null case.
val q = quote {
query[Person].join(query[Address]).on((p, a) => a.fk.forall(_ == p.id))
}
ctx.run(q)
// SELECT p.id, p.name, a.fk, a.street, a.zip FROM Person p INNER JOIN Address a ON a.fk IS NULL OR a.fk = p.idTypically this is useful when doing negative conditions, e.g. when a field is not some specified value (e.g. "Joe").
Being null in this case is typically a matching result.
val q = quote {
query[Person].filter(p => p.name.forall(_ != "Joe"))
}
ctx.run(q)
// SELECT p.id, p.name FROM Person p WHERE p.name IS NULL OR p.name <> 'Joe'As in regular Scala code, performing any operation on an optional value typically requires using the map function.
val q = quote {
for {
p <- query[Person]
} yield (p.id, p.name.map("Dear " + _))
}
ctx.run(q)
// SELECT p.id, 'Dear ' || p.name FROM Person p
// * In Dialects where `||` does not fall-through for nulls (e.g. Oracle):
// * SELECT p.id, CASE WHEN p.name IS NOT NULL THEN 'Dear ' || p.name ELSE null END FROM Person pAdditionally, this method is useful when you want to get a non-optional field out of an outer-joined table
(i.e. a table wrapped in an Option object).
val q = quote {
query[Company].leftJoin(query[Address])
.on((c, a) => c.zip == a.zip)
.map {case(c,a) => // Row type is (Company, Option[Address])
(c.name, a.map(_.street), a.map(_.zip)) // Use `Option.map` to get `street` and `zip` fields
}
}
run(q)
// SELECT c.name, a.street, a.zip FROM Company c LEFT JOIN Address a ON c.zip = a.zipFor more details about this operation (and some caveats), see the 'Optional Tables' section.
Use these when the Option.map functionality is not sufficient. This typically happens when you need to manipulate
multiple nullable fields in a way which would otherwise result in Option[Option[T]].
val q = quote {
for {
a <- query[Person]
b <- query[Person] if (a.id > b.id)
} yield (
// If this was `a.name.map`, resulting record type would be Option[Option[String]]
a.name.flatMap(an =>
b.name.map(bn =>
an+" comes after "+bn)))
}
ctx.run(q) //: List[Option[String]]
// SELECT (a.name || ' comes after ') || b.name FROM Person a, Person b WHERE a.id > b.id
// * In Dialects where `||` does not fall-through for nulls (e.g. Oracle):
// * SELECT CASE WHEN a.name IS NOT NULL AND b.name IS NOT NULL THEN (a.name || ' comes after ') || b.name ELSE null END FROM Person a, Person b WHERE a.id > b.id
// Alternatively, you can use `flatten`
val q = quote {
for {
a <- query[Person]
b <- query[Person] if (a.id > b.id)
} yield (
a.name.map(an =>
b.name.map(bn =>
an + " comes after " + bn)).flatten)
}
ctx.run(q) //: List[Option[String]]
// SELECT (a.name || ' comes after ') || b.name FROM Person a, Person b WHERE a.id > b.idThis is also very useful when selecting from outer-joined tables i.e. where the entire table
is inside of an Option object. Note how below we get the fk field from Option[Address].
val q = quote {
query[Person].leftJoin(query[Address])
.on((p, a) => a.fk.exists(_ == p.id))
.map {case (p /*Person*/, a /*Option[Address]*/) => (p.name, a.flatMap(_.fk))}
}
ctx.run(q) //: List[(Option[String], Option[Int])]
// SELECT p.name, a.fk FROM Person p LEFT JOIN Address a ON a.fk = p.idThe orNull method can be used to convert an Option-enclosed row back into a regular row.
Since Option[T].orNull does not work for primitive types (e.g. Int, Double, etc...),
you can use the getOrNull method inside of quoted blocks to do the same thing.
Note that since the presence of null columns can cause queries to break in some data sources (e.g. Spark), so use this operation very carefully.
val q = quote {
query[Person].join(query[Address])
.on((p, a) => a.fk.exists(_ == p.id))
.filter {case (p /*Person*/, a /*Option[Address]*/) =>
a.fk.getOrNull != 123 } // Exclude a particular value from the query.
// Since we already did an inner-join on this value, we know it is not null.
}
ctx.run(q) //: List[(Address, Person)]
// SELECT p.id, p.name, a.fk, a.street, a.zip FROM Person p INNER JOIN Address a ON a.fk IS NOT NULL AND a.fk = p.id WHERE a.fk <> 123In certain situations, you may wish to pretend that a nullable-field is not actually nullable and perform regular operations
(e.g. arithmetic, concatenation, etc...) on the field. You can use a combination of Option.apply and orNull (or getOrNull where needed)
in order to do this.
val q = quote {
query[Person].map(p => Option(p.name.orNull + " suffix"))
}
ctx.run(q)
// SELECT p.name || ' suffix' FROM Person p
// i.e. same as the previous behaviorIn all other situations, since Quill strictly checks nullable values, and case.. if conditionals will work correctly in all Optional constructs.
However, since they may introduce behavior changes in your codebase, the following warning has been introduced:
Conditionals inside of Option.[map | flatMap | exists | forall] will create a
CASEstatement in order to properly null-check the sub-query (...)
val q = quote {
query[Person].map(p => p.name.map(n => if (n == "Joe") "foo" else "bar").getOrElse("baz"))
}
// Information:(16, 15) Conditionals inside of Option.map will create a `CASE` statement in order to properly null-check the sub-query: `p.name.map((n) => if(n == "Joe") "foo" else "bar")`.
// Expressions like Option(if (v == "foo") else "bar").getOrElse("baz") will now work correctly, but expressions that relied on the broken behavior (where "bar" would be returned instead) need to be modified (see the "orNull / getOrNull" section of the documentation of more detail).
ctx.run(a)
// Used to be this:
// SELECT CASE WHEN CASE WHEN p.name = 'Joe' THEN 'foo' ELSE 'bar' END IS NOT NULL THEN CASE WHEN p.name = 'Joe' THEN 'foo' ELSE 'bar' END ELSE 'baz' END FROM Person p
// Now is this:
// SELECT CASE WHEN p.name IS NOT NULL AND CASE WHEN p.name = 'Joe' THEN 'foo' ELSE 'bar' END IS NOT NULL THEN CASE WHEN p.name = 'Joe' THEN 'foo' ELSE 'bar' END ELSE 'baz' END FROM Person p
The ==, !=, and .equals methods can be used to compare regular types as well Option types in a scala-idiomatic way.
That is to say, either T == T or Option[T] == Option[T] is supported and the following "truth-table" is observed:
| Left | Right | Equality | Result |
|---|---|---|---|
a |
b |
== |
a == b |
Some[T](a) |
Some[T](b) |
== |
a == b |
Some[T](a) |
None |
== |
false |
None |
Some[T](b) |
== |
false |
None |
None |
== |
true |
Some[T] |
Some[R] |
== |
Exception thrown. |
a |
b |
!= |
a != b |
Some[T](a) |
Some[T](b) |
!= |
a != b |
Some[T](a) |
None |
!= |
true |
None |
Some[T](b) |
!= |
true |
Some[T] |
Some[R] |
!= |
Exception thrown. |
None |
None |
!= |
false |
case class Node(id:Int, status:Option[String], otherStatus:Option[String])
val q = quote { query[Node].filter(n => n.id == 123) }
ctx.run(q)
// SELECT n.id, n.status, n.otherStatus FROM Node n WHERE p.id = 123
val q = quote { query[Node].filter(r => r.status == r.otherStatus) }
ctx.run(q)
// SELECT r.id, r.status, r.otherStatus FROM Node r WHERE r.status IS NULL AND r.otherStatus IS NULL OR r.status = r.otherStatus
val q = quote { query[Node].filter(n => n.status == Option("RUNNING")) }
ctx.run(q)
// SELECT n.id, n.status, n.otherStatus FROM node n WHERE n.status IS NOT NULL AND n.status = 'RUNNING'
val q = quote { query[Node].filter(n => n.status != Option("RUNNING")) }
ctx.run(q)
// SELECT n.id, n.status, n.otherStatus FROM node n WHERE n.status IS NULL OR n.status <> 'RUNNING'If you would like to use an equality operator that follows that ansi-idiomatic approach, failing
the comparison if either side is null as well as the principle that null = null := false, you can import === (and =!=)
from Context.extras. These operators work across T and Option[T] allowing comparisons like T === Option[T],
Option[T] == T etc... to be made. You can use also ===
directly in Scala code and it will have the same behavior, returning false when other the left-hand
or right-hand side is None. This is particularity useful in paradigms like Spark where
you will typically transition inside and outside of Quill code.
When using
a === bora =!= bsometimes you will see the extraa IS NOT NULL AND b IS NOT NULLcomparisons and sometimes you will not. This depends onequalityBehaviorinSqlIdiomwhich determines whether the given SQL dialect already does ansi-idiomatic comparison toa, andbwhen an=operator is used, this allows us to omit the extraa IS NOT NULL AND b IS NOT NULL.
import ctx.extras._
// === works the same way inside of a quotation
val q = run( query[Node].filter(n => n.status === "RUNNING") )
// SELECT n.id, n.status FROM node n WHERE n.status IS NOT NULL AND n.status = 'RUNNING'
// as well as outside
(nodes:List[Node]).filter(n => n.status === "RUNNING")As we have seen in the examples above, only the map and flatMap methods are available on outer-joined tables
(i.e. tables wrapped in an Option object).
Since you cannot use Option[Table].isDefined, if you want to null-check a whole table
(e.g. if a left-join was not matched), you have to map to a specific field on which you can do the null-check.
val q = quote {
query[Company].leftJoin(query[Address])
.on((c, a) => c.zip == a.zip) // Row type is (Company, Option[Address])
.filter({case(c,a) => a.isDefined}) // You cannot null-check a whole table!
}Instead, map the row-variable to a specific field and then check that field.
val q = quote {
query[Company].leftJoin(query[Address])
.on((c, a) => c.zip == a.zip) // Row type is (Company, Option[Address])
.filter({case(c,a) => a.map(_.street).isDefined}) // Null-check a non-nullable field instead
}
ctx.run(q)
// SELECT c.name, c.zip, a.fk, a.street, a.zip
// FROM Company c
// LEFT JOIN Address a ON c.zip = a.zip
// WHERE a.street IS NOT NULLFinally, it is worth noting that a whole table can be wrapped into an Option object. This is particularly
useful when doing a union on table-sets that are both right-joined and left-joined together.
val aCompanies = quote {
for {
c <- query[Company] if (c.name like "A%")
a <- query[Address].join(_.zip == c.zip)
} yield (c, Option(a)) // change (Company, Address) to (Company, Option[Address])
}
val bCompanies = quote {
for {
c <- query[Company] if (c.name like "A%")
a <- query[Address].leftJoin(_.zip == c.zip)
} yield (c, a) // (Company, Option[Address])
}
val union = quote {
aCompanies union bCompanies
}
ctx.run(union)
// SELECT x.name, x.zip, x.fk, x.street, x.zip FROM (
// (SELECT c.name name, c.zip zip, x1.zip zip, x1.fk fk, x1.street street
// FROM Company c INNER JOIN Address x1 ON x1.zip = c.zip WHERE c.name like 'A%')
// UNION
// (SELECT c1.name name, c1.zip zip, x2.zip zip, x2.fk fk, x2.street street
// FROM Company c1 LEFT JOIN Address x2 ON x2.zip = c1.zip WHERE c1.name like 'A%')
// ) xCase Classes can also be used inside quotations as output values:
case class Person(id: Int, name: String, age: Int)
case class Contact(personId: Int, phone: String)
case class ReachablePerson(name:String, phone: String)
val q = quote {
for {
p <- query[Person] if(p.id == 999)
c <- query[Contact] if(c.personId == p.id)
} yield {
ReachablePerson(p.name, c.phone)
}
}
ctx.run(q)
// SELECT p.name, c.phone FROM Person p, Contact c WHERE (p.id = 999) AND (c.personId = p.id)As well as in general:
case class IdFilter(id:Int)
val q = quote {
val idFilter = new IdFilter(999)
for {
p <- query[Person] if(p.id == idFilter.id)
c <- query[Contact] if(c.personId == p.id)
} yield {
ReachablePerson(p.name, c.phone)
}
}
ctx.run(q)
// SELECT p.name, c.phone FROM Person p, Contact c WHERE (p.id = 999) AND (c.personId = p.id)Note however that this functionality has the following restrictions:
- The Ad-Hoc Case Class can only have one constructor with one set of parameters.
- The Ad-Hoc Case Class must be constructed inside the quotation using one of the following methods:
- Using the
newkeyword:new Person("Joe", "Bloggs") - Using a companion object's apply method:
Person("Joe", "Bloggs") - Using a companion object's apply method explicitly:
Person.apply("Joe", "Bloggs")
- Using the
- Any custom logic in a constructor/apply-method of an Ad-Hoc case class will not be invoked when it is 'constructed' inside a quotation. To construct an Ad-Hoc case class with custom logic inside a quotation, you can use a quoted method.
Query probing validates queries against the database at compile time, failing the compilation if it is not valid. The query validation does not alter the database state.
This feature is disabled by default. To enable it, mix the QueryProbing trait to the database configuration:
object myContext extends YourContextType with QueryProbing
The context must be created in a separate compilation unit in order to be loaded at compile time. Please use this guide that explains how to create a separate compilation unit for macros, that also serves to the purpose of defining a query-probing-capable context. context could be used instead of macros as the name of the separate compilation unit.
The configurations correspondent to the config key must be available at compile time. You can achieve it by adding this line to your project settings:
unmanagedClasspath in Compile += baseDirectory.value / "src" / "main" / "resources"
If your project doesn't have a standard layout, e.g. a play project, you should configure the path to point to the folder that contains your config file.
Database actions are defined using quotations as well. These actions don't have a collection-like API but rather a custom DSL to express inserts, deletes, and updates.
val a = quote(query[Contact].insertValue(lift(Contact(999, "+1510488988"))))
ctx.run(a) // = 1 if the row was inserted 0 otherwise
// INSERT INTO Contact (personId,phone) VALUES (?, ?)val a = quote {
query[Contact].insert(_.personId -> lift(999), _.phone -> lift("+1510488988"))
}
ctx.run(a)
// INSERT INTO Contact (personId,phone) VALUES (?, ?)val a = quote {
liftQuery(List(Person(0, "John", 31),Person(2, "name2", 32))).foreach(e => query[Person].insertValue(e))
}
ctx.run(a) //: List[Long] size = 2. Contains 1 @ positions, where row was inserted E.g List(1,1)
// INSERT INTO Person (id,name,age) VALUES (?, ?, ?)val a = quote {
query[Person].filter(_.id == 999).updateValue(lift(Person(999, "John", 22)))
}
ctx.run(a) // = Long number of rows updated
// UPDATE Person SET id = ?, name = ?, age = ? WHERE id = 999val a = quote {
query[Person].filter(p => p.id == lift(999)).update(_.age -> lift(18))
}
ctx.run(a)
// UPDATE Person SET age = ? WHERE id = ?val a = quote {
query[Person].filter(p => p.id == lift(999)).update(p => p.age -> (p.age + 1))
}
ctx.run(a)
// UPDATE Person SET age = (age + 1) WHERE id = ?val a = quote {
liftQuery(List(Person(1, "name", 31),Person(2, "name2", 32))).foreach { person =>
query[Person].filter(_.id == person.id).update(_.name -> person.name, _.age -> person.age)
}
}
ctx.run(a) // : List[Long] size = 2. Contains 1 @ positions, where row was inserted E.g List(1,0)
// UPDATE Person SET name = ?, age = ? WHERE id = ?val a = quote {
query[Person].filter(p => p.name == "").delete
}
ctx.run(a) // = Long the number of rows deleted
// DELETE FROM Person WHERE name = ''Upsert is supported by Postgres, SQLite, MySQL and H2 onConflictIgnore only (since v1.4.200 in PostgreSQL compatibility mode)
val a = quote {
query[Product].insert(_.id -> 1, _.sku -> 10).onConflictIgnore
}
// INSERT INTO Product AS t (id,sku) VALUES (1, 10) ON CONFLICT DO NOTHINGIgnore conflict by explicitly setting conflict target
val a = quote {
query[Product].insert(_.id -> 1, _.sku -> 10).onConflictIgnore(_.id)
}
// INSERT INTO Product AS t (id,sku) VALUES (1, 10) ON CONFLICT (id) DO NOTHINGMultiple properties can be used as well.
val a = quote {
query[Product].insert(_.id -> 1, _.sku -> 10).onConflictIgnore(_.id, _.description)
}
// INSERT INTO Product (id,sku) VALUES (1, 10) ON CONFLICT (id,description) DO NOTHINGResolve conflict by updating existing row if needed. In onConflictUpdate(target)((t, e) => assignment): target refers to
conflict target, t - to existing row and e - to excluded, e.g. row proposed for insert.
val a = quote {
query[Product]
.insert(_.id -> 1, _.sku -> 10)
.onConflictUpdate(_.id)((t, e) => t.sku -> (t.sku + e.sku))
}
// INSERT INTO Product AS t (id,sku) VALUES (1, 10) ON CONFLICT (id) DO UPDATE SET sku = (t.sku + EXCLUDED.sku)Multiple properties can be used with onConflictUpdate as well.
val a = quote {
query[Product]
.insert(_.id -> 1, _.sku -> 10)
.onConflictUpdate(_.id, _.description)((t, e) => t.sku -> (t.sku + e.sku))
}
INSERT INTO Product AS t (id,sku) VALUES (1, 10) ON CONFLICT (id,description) DO UPDATE SET sku = (t.sku + EXCLUDED.sku)Ignore any conflict, e.g. insert ignore
val a = quote {
query[Product].insert(_.id -> 1, _.sku -> 10).onConflictIgnore
}
// INSERT IGNORE INTO Product (id,sku) VALUES (1, 10)Ignore duplicate key conflict by explicitly setting it
val a = quote {
query[Product].insert(_.id -> 1, _.sku -> 10).onConflictIgnore(_.id)
}
// INSERT INTO Product (id,sku) VALUES (1, 10) ON DUPLICATE KEY UPDATE id=idResolve duplicate key by updating existing row if needed. In onConflictUpdate((t, e) => assignment): t refers to
existing row and e - to values, e.g. values proposed for insert.
val a = quote {
query[Product]
.insert(_.id -> 1, _.sku -> 10)
.onConflictUpdate((t, e) => t.sku -> (t.sku + e.sku))
}
// INSERT INTO Product (id,sku) VALUES (1, 10) ON DUPLICATE KEY UPDATE sku = (sku + VALUES(sku))The translate method is used to convert a Quill query into a string which can then be printed.
val str = ctx.translate(query[Person])
println(str)
// SELECT x.id, x.name, x.age FROM Person xInsert queries can also be printed:
val str = ctx.translate(query[Person].insertValue(lift(Person(0, "Joe", 45))))
println(str)
// INSERT INTO Person (id,name,age) VALUES (0, 'Joe', 45)As well as batch insertions:
val q = quote {
liftQuery(List(Person(0, "Joe",44), Person(1, "Jack",45)))
.foreach(e => query[Person].insertValue(e))
}
val strs: List[String] = ctx.translate(q)
strs.map(println)
// INSERT INTO Person (id, name,age) VALUES (0, 'Joe', 44)
// INSERT INTO Person (id, name,age) VALUES (1, 'Jack', 45)The translate method is available in every Quill context as well as the Cassandra and OrientDB contexts,
the latter two, however, do not support Insert and Batch Insert query printing.
Quill provides an IO monad that allows the user to express multiple computations and execute them separately. This mechanism is also known as a free monad, which provides a way of expressing computations as referentially-transparent values and isolates the unsafe IO operations into a single operation. For instance:
// this code using Future
case class Person(id: Int, name: String, age: Int)
val p = Person(0, "John", 22)
ctx.run(query[Person].insertValue(lift(p))).flatMap { _ =>
ctx.run(query[Person])
}
// isn't referentially transparent because if you refactor the second database
// interaction into a value, the result will be different:
val allPeople = ctx.run(query[Person])
ctx.run(query[Person].insertValue(lift(p))).flatMap { _ =>
allPeople
}
// this happens because `ctx.run` executes the side-effect (database IO) immediately// The IO monad doesn't perform IO immediately, so both computations:
val p = Person(0, "John", 22)
val a =
ctx.runIO(query[Person].insertValue(lift(p))).flatMap { _ =>
ctx.runIO(query[Person])
}
val allPeople = ctx.runIO(query[Person])
val b =
ctx.runIO(query[Person].insertValue(lift(p))).flatMap { _ =>
allPeople
}
// produce the same result when executed
performIO(a) == performIO(b)The IO monad has an interface similar to Future; please refer to the class for more information regarding the available operations.
The return type of performIO varies according to the context. For instance, async contexts return Futures while JDBC returns values synchronously.
NOTE: Avoid using the variable name io since it conflicts with Quill's package io.getquill, otherwise you will get the following error.
recursive value io needs type
IO also provides the transactional method that delimits a transaction:
val a =
ctx.runIO(query[Person].insertValue(lift(p))).flatMap { _ =>
ctx.runIO(query[Person])
}
performIO(a.transactional) // note: transactional can be used outside of `performIO`Quill JDBC Contexts allow you to use prepare in order to get a low-level ResultSet that is useful
for interacting with legacy APIs. This function returns a f: (Connection) => (PreparedStatement)
closure as opposed to a PreparedStatement in order to guarantee that JDBC Exceptions are not
thrown until you can wrap them into the appropriate Exception-handling mechanism (e.g.
try/catch, Try etc...).
val q = quote {
query[Product].filter(_.id == 1)
}
val preparer: (Connection) => (PreparedStatement) = ctx.prepare(q)
// SELECT x1.id, x1.description, x1.sku FROM Product x1 WHERE x1.id = 1
// Use ugly stateful code, bracketed effects, or try-with-resources here:
var preparedStatement: PreparedStatement = _
var resultSet: ResultSet = _
try {
preparedStatement = preparer(myCustomDataSource.getConnection)
resultSet = preparedStatement.executeQuery()
} catch {
case e: Exception =>
// Close the preparedStatement and catch possible exceptions
// Close the resultSet and catch possible exceptions
}The prepare function can also be used with insertValue, and updateValue actions.
val q = quote {
query[Product].insertValue(lift(Product(1, "Desc", 123))
}
val preparer: (Connection) => (PreparedStatement) = ctx.prepare(q)
// INSERT INTO Product (id,description,sku) VALUES (?, ?, ?)As well as with batch queries.
Make sure to first quote your batch query and then pass the result into the
preparefunction (as is done in the example below) or the Scala compiler may not type the output correctly #1518.
val q = quote {
liftQuery(products).foreach(e => query[Product].insertValue(e))
}
val preparers: Connection => List[PreparedStatement] = ctx.prepare(q)
val preparedStatement: List[PreparedStatement] = preparers(jdbcConf.dataSource.getConnection)The IO monad tracks the effects that a computation performs in its second type parameter:
val a: IO[ctx.RunQueryResult[Person], Effect.Write with Effect.Read] =
ctx.runIO(query[Person].insertValue(lift(p))).flatMap { _ =>
ctx.runIO(query[Person])
}This mechanism is useful to limit the kind of operations that can be performed. See this blog post as an example.
Quill provides implicit conversions from case class companion objects to query[T] through an additional trait:
val ctx = new SqlMirrorContext(MirrorSqlDialect, Literal) with ImplicitQuery
import ctx._
val q = quote {
for {
p <- Person if(p.id == 999)
c <- Contact if(c.personId == p.id)
} yield {
(p.name, c.phone)
}
}
ctx.run(q)
// SELECT p.name, c.phone FROM Person p, Contact c WHERE (p.id = 999) AND (c.personId = p.id)Note the usage of Person and Contact instead of query[Person] and query[Contact].
Some operations are SQL-specific and not provided with the generic quotation mechanism. The SQL contexts provide implicit classes for this kind of operation:
val ctx = new SqlMirrorContext(MirrorSqlDialect, Literal)
import ctx._val q = quote {
query[Person].filter(p => p.name like "%John%")
}
ctx.run(q)
// SELECT p.id, p.name, p.age FROM Person p WHERE p.name like '%John%'val q = quote {
query[Person].filter(p => p.name == "Mary").forUpdate()
}
ctx.run(q)
// SELECT p.id, p.name, p.age FROM Person p WHERE p.name = 'Mary' FOR UPDATEQuill provides SQL Arrays support. In Scala we represent them as any collection that implements Seq:
import java.util.Date
case class Book(id: Int, notes: List[String], pages: Vector[Int], history: Seq[Date])
ctx.run(query[Book])
// SELECT x.id, x.notes, x.pages, x.history FROM Book xNote that not all drivers/databases provides such feature hence only PostgresJdbcContext and
PostgresAsyncContext support SQL Arrays.
val ctx = new CassandraMirrorContext(Literal)
import ctx._The Cassandra context provides List, Set, and Map encoding:
case class Book(id: Int, notes: Set[String], pages: List[Int], history: Map[Int, Boolean])
ctx.run(query[Book])
// SELECT id, notes, pages, history FROM BookThe cassandra context provides encoding of UDT (user-defined types).
case class Name(firstName: String, lastName: String) extends UdtTo encode the UDT and bind it into the query (insert/update queries), the context needs to retrieve UDT metadata from
the cluster object. By default, the context looks for UDT metadata within the currently logged keyspace, but it's also possible to specify a
concrete keyspace with udtMeta:
implicit val nameMeta = udtMeta[Name]("keyspace2.my_name")When a keyspace is not set in udtMeta then the currently logged one is used.
Since it's possible to create a context without specifying a keyspace, (e.g. the keyspace parameter is null and the session is not bound to any keyspace), the UDT metadata will be resolved throughout the entire cluster.
It is also possible to rename UDT columns with udtMeta:
implicit val nameMeta = udtMeta[Name]("name", _.firstName -> "first", _.lastName -> "last")The cassandra context also provides a few additional operations:
val q = quote {
query[Person].filter(p => p.age > 10).allowFiltering
}
ctx.run(q)
// SELECT id, name, age FROM Person WHERE age > 10 ALLOW FILTERINGval q = quote {
query[Person].insert(_.age -> 10, _.name -> "John").ifNotExists
}
ctx.run(q)
// INSERT INTO Person (age,name) VALUES (10, 'John') IF NOT EXISTSval q = quote {
query[Person].filter(p => p.name == "John").delete.ifExists
}
ctx.run(q)
// DELETE FROM Person WHERE name = 'John' IF EXISTSval q1 = quote {
query[Person].insert(_.age -> 10, _.name -> "John").usingTimestamp(99)
}
ctx.run(q1)
// INSERT INTO Person (age,name) VALUES (10, 'John') USING TIMESTAMP 99
val q2 = quote {
query[Person].usingTimestamp(99).update(_.age -> 10)
}
ctx.run(q2)
// UPDATE Person USING TIMESTAMP 99 SET age = 10val q1 = quote {
query[Person].insert(_.age -> 10, _.name -> "John").usingTtl(11)
}
ctx.run(q1)
// INSERT INTO Person (age,name) VALUES (10, 'John') USING TTL 11
val q2 = quote {
query[Person].usingTtl(11).update(_.age -> 10)
}
ctx.run(q2)
// UPDATE Person USING TTL 11 SET age = 10
val q3 = quote {
query[Person].usingTtl(11).filter(_.name == "John").delete
}
ctx.run(q3)
// DELETE FROM Person USING TTL 11 WHERE name = 'John'val q1 = quote {
query[Person].insert(_.age -> 10, _.name -> "John").using(ts = 99, ttl = 11)
}
ctx.run(q1)
// INSERT INTO Person (age,name) VALUES (10, 'John') USING TIMESTAMP 99 AND TTL 11
val q2 = quote {
query[Person].using(ts = 99, ttl = 11).update(_.age -> 10)
}
ctx.run(q2)
// UPDATE Person USING TIMESTAMP 99 AND TTL 11 SET age = 10
val q3 = quote {
query[Person].using(ts = 99, ttl = 11).filter(_.name == "John").delete
}
ctx.run(q3)
// DELETE FROM Person USING TIMESTAMP 99 AND TTL 11 WHERE name = 'John'val q1 = quote {
query[Person].update(_.age -> 10).ifCond(_.name == "John")
}
ctx.run(q1)
// UPDATE Person SET age = 10 IF name = 'John'
val q2 = quote {
query[Person].filter(_.name == "John").delete.ifCond(_.age == 10)
}
ctx.run(q2)
// DELETE FROM Person WHERE name = 'John' IF age = 10val q = quote {
query[Person].map(p => p.age).delete
}
ctx.run(q)
// DELETE p.age FROM Personrequires allowFiltering
val q = quote {
query[Book].filter(p => p.pages.contains(25)).allowFiltering
}
ctx.run(q)
// SELECT id, notes, pages, history FROM Book WHERE pages CONTAINS 25 ALLOW FILTERINGrequires allowFiltering
val q = quote {
query[Book].filter(p => p.history.contains(12)).allowFiltering
}
ctx.run(q)
// SELECT id, notes, pages, history FROM book WHERE history CONTAINS 12 ALLOW FILTERINGrequires allowFiltering
val q = quote {
query[Book].filter(p => p.history.containsValue(true)).allowFiltering
}
ctx.run(q)
// SELECT id, notes, pages, history FROM book WHERE history CONTAINS true ALLOW FILTERINGQuill's default operation mode is compile-time, but there are queries that have their structure defined only at runtime. Quill automatically falls back to runtime normalization and query generation if the query's structure is not static. Example:
val ctx = new SqlMirrorContext(MirrorSqlDialect, Literal)
import ctx._
sealed trait QueryType
case object Minor extends QueryType
case object Senior extends QueryType
def people(t: QueryType): Quoted[Query[Person]] =
t match {
case Minor => quote {
query[Person].filter(p => p.age < 18)
}
case Senior => quote {
query[Person].filter(p => p.age > 65)
}
}
ctx.run(people(Minor))
// SELECT p.id, p.name, p.age FROM Person p WHERE p.age < 18
ctx.run(people(Senior))
// SELECT p.id, p.name, p.age FROM Person p WHERE p.age > 65Additionally, Quill provides a separate query API to facilitate the creation of dynamic queries. This API allows users to easily manipulate quoted values instead of working only with quoted transformations.
Important: A few of the dynamic query methods accept runtime string values. It's important to keep in mind that these methods could be a vector for SQL injection.
Let's use the filter transformation as an example. In the regular API, this method has no implementation since it's an abstract member of a trait:
def filter(f: T => Boolean): EntityQuery[T]
In the dynamic API, filter is has a different signature and a body that is executed at runtime:
def filter(f: Quoted[T] => Quoted[Boolean]): DynamicQuery[T] =
transform(f, Filter)
It takes a Quoted[T] as input and produces a Quoted[Boolean]. The user is free to use regular scala code within the transformation:
def people(onlyMinors: Boolean) =
dynamicQuery[Person].filter(p => if(onlyMinors) quote(p.age < 18) else quote(true))In order to create a dynamic query, use one of the following methods:
dynamicQuery[Person]
dynamicQuerySchema[Person]("people", alias(_.name, "pname"))It's also possible to transform a Quoted into a dynamic query:
val q = quote {
query[Person]
}
q.dynamic.filter(p => quote(p.name == "John"))The dynamic query API is very similar to the regular API but has a few differences:
Queries
// schema queries use `alias` instead of tuples
dynamicQuerySchema[Person]("people", alias(_.name, "pname"))
// this allows users to use a dynamic list of aliases
val aliases = List(alias[Person](_.name, "pname"), alias[Person](_.age, "page"))
dynamicQuerySchema[Person]("people", aliases:_*)
// a few methods have an overload with the `Opt` suffix,
// which apply the transformation only if the option is defined:
def people(minAge: Option[Int]) =
dynamicQuery[Person].filterOpt(minAge)((person, minAge) => quote(person.age >= minAge))
def people(maxRecords: Option[Int]) =
dynamicQuery[Person].takeOpt(maxRecords)
def people(dropFirst: Option[Int]) =
dynamicQuery[Person].dropOpt(dropFirst)
// method with `If` suffix, for better chaining
def people(userIds: Seq[Int]) =
dynamicQuery[Person].filterIf(userIds.nonEmpty)(person => quote(liftQuery(userIds).contains(person.id)))Actions
// actions use `set`
dynamicQuery[Person].filter(_.id == 1).update(set(_.name, quote("John")))
// or `setValue` if the value is not quoted
dynamicQuery[Person].insert(setValue(_.name, "John"))
// or `setOpt` that will be applied only the option is defined
dynamicQuery[Person].insert(setOpt(_.name, Some("John")))
// it's also possible to use a runtime string value as the column name
dynamicQuery[Person].filter(_.id == 1).update(set("name", quote("John")))
// to insert or update a case class instance, use `insertValue`/`updateValue`
val p = Person(0, "John", 21)
dynamicQuery[Person].insertValue(p)
dynamicQuery[Person].filter(_.id == 1).updateValue(p)Quill is super fast for static queries (almost zero runtime overhead compared to directly sql executing).
But there is significant impact for dynamic queries.
Normalization caching was introduced to improve the situation, which will speedup dynamic queries significantly. It is enabled by default.
To disable dynamic normalization caching, pass following property to sbt during compile time
sbt -Dquill.query.cacheDaynamic=false
Infix is a very flexible mechanism to use non-supported features without having to use plain queries in the target language. It allows the insertion of arbitrary strings within quotations.
For instance, quill doesn't support the FOR UPDATE SQL feature. It can still be used through infix and implicit classes:
implicit class ForUpdate[T](q: Query[T]) {
def forUpdate = quote(infix"$q FOR UPDATE".as[Query[T]])
}
val a = quote {
query[Person].filter(p => p.age < 18).forUpdate
}
ctx.run(a)
// SELECT p.name, p.age FROM person p WHERE p.age < 18 FOR UPDATEThe forUpdate quotation can be reused for multiple queries.
Queries that contain infix will generally not be flattened since it is not assumed that the contents
of the infix are a pure function.
Since SQL is typically less performant when there are many nested queries, be careful with the use of
infixin queries that have multiplemap+filterclauses.
case class Data(id: Int)
case class DataAndRandom(id: Int, value: Int)
// This should be alright:
val q = quote {
query[Data].map(e => DataAndRandom(e.id, infix"RAND()".as[Int])).filter(r => r.value <= 10)
}
run(q)
// SELECT e.id, e.value FROM (SELECT RAND() AS value, e.id AS id FROM Data e) AS e WHERE e.value <= 10
// This might not be:
val q = quote {
query[Data]
.map(e => DataAndRandom(e.id, infix"SOME_UDF(${e.id})".as[Int]))
.filter(r => r.value <= 10)
.map(e => DataAndRandom(e.id, infix"SOME_OTHER_UDF(${e.value})".as[Int]))
.filter(r => r.value <= 100)
}
// Produces too many layers of nesting!
run(q)
// SELECT e.id, e.value FROM (
// SELECT SOME_OTHER_UDF(e.value) AS value, e.id AS id FROM (
// SELECT SOME_UDF(e.id) AS value, e.id AS id FROM Data e
// ) AS e WHERE e.value <= 10
// ) AS e WHERE e.value <= 100If you are sure that the the content of your infix is a pure function, you canse use the pure method
in order to indicate to Quill that the infix clause can be copied in the query. This gives Quill much
more leeway to flatten your query, possibly improving performance.
val q = quote {
query[Data]
.map(e => DataAndRandom(e.id, infix"SOME_UDF(${e.id})".pure.as[Int]))
.filter(r => r.value <= 10)
.map(e => DataAndRandom(e.id, infix"SOME_OTHER_UDF(${e.value})".pure.as[Int]))
.filter(r => r.value <= 100)
}
// Copying SOME_UDF and SOME_OTHER_UDF allows the query to be completely flattened.
run(q)
// SELECT e.id, SOME_OTHER_UDF(SOME_UDF(e.id)) FROM Data e
// WHERE SOME_UDF(e.id) <= 10 AND SOME_OTHER_UDF(SOME_UDF(e.id)) <= 100Use infix"...".asCondition to express an infix that represents a conditional expression.
When synthesizing queries for databases which do not have proper boolean-type support (e.g. SQL Server,
Oracle etc...) boolean infix clauses inside projections must become values.
Typically this requires a CASE WHERE ... END.
Take the following example:
case class Node(name: String, isUp: Boolean, uptime:Long)
case class Status(name: String, allowed: Boolean)
val allowedStatus:Boolean = getState
quote {
query[Node].map(n => Status(n.name, n.isUp == lift(allowedStatus)))
}
run(q)
// This is invalid in most databases:
// SELECT n.name, n.isUp = ?, uptime FROM Node n
// It will be converted to this:
// SELECT n.name, CASE WHEN (n.isUp = ?) THEN 1 ELSE 0, uptime FROM Node nHowever, in certain cases, infix clauses that express conditionals should actually represent boolean expressions for example:
case class Node(name: String, isUp: Boolean)
val maxUptime:Boolean = getState
quote {
query[Node].filter(n => infix"${n.uptime} > ${lift(maxUptime)}".as[Boolean])
}
run(q)
// Should be this:
// SELECT n.name, n.isUp, n.uptime WHERE n.uptime > ?
// However since infix"...".as[Boolean] is treated as a Boolean Value (as opposed to an expression) it will be converted to this:
// SELECT n.name, n.isUp, n.uptime WHERE 1 == n.uptime > ?In order to avoid this problem, use infix"...".asCondition so that Quill understands that the boolean is an expression:
quote {
query[Node].filter(n => infix"${n.uptime} > ${lift(maxUptime)}".asCondition)
}
run(q) // SELECT n.name, n.isUp, n.uptime WHERE n.uptime > ?Infix supports runtime string values through the #$ prefix. Example:
def test(functionName: String) =
ctx.run(query[Person].map(p => infix"#$functionName(${p.name})".as[Int]))You can use implicit extensions in quill in several ways.
NOTE. In ProtoQuill extensions must be written using the Scala 3
extensionsyntax and implicit class extensions are not supported. Please see Extensions in ProtoQuill/Scala3 below for more info.
implicit class Ext(q: Query[Person]) {
def olderThan(age: Int) = quote {
query[Person].filter(p => p.age > lift(age))
}
}
run(query[Person].olderThan(44))
// SELECT p.name, p.age FROM Person p WHERE p.age > ?implicit class Ext(q: Query[Person]) {
def olderThan = quote {
(age: Int) =>
query[Person].filter(p => p.age > lift(age))
}
}
run(query[Person].olderThan(44))
// SELECT p.name, p.age FROM Person p WHERE p.age > 44
run(query[Person].olderThan(lift(44)))
// SELECT p.name, p.age FROM Person p WHERE p.age > ?The advantage of this approach is that you can choose to either lift or use a constant.
Just as Query can be extended, scalar values can be similarly extended.
implicit class Ext(i: Int) {
def between = quote {
(a: Int, b:Int) =>
i > a && i < b
}
}
run(query[Person].filter(p => p.age.between(33, 44)))
// SELECT p.name, p.age FROM Person p WHERE p.age > 33 AND p.age < 44In ProtoQuill, the implicit class pattern for extensions is not supported. Please switch to using Scala 3 extension methods combined with inline definitions to achieve the same functionality.
extension (q: Query[Person]) {
inline def olderThan(inline age: Int) = quote {
query[Person].filter(p => p.age > lift(age))
}
}
run(query[Person].olderThan(44))
// SELECT p.name, p.age FROM Person p WHERE p.age > ?You can also use infix to port raw SQL queries to Quill and map it to regular Scala tuples.
val rawQuery = quote {
(id: Int) => infix"""SELECT id, name FROM my_entity WHERE id = $id""".as[Query[(Int, String)]]
}
ctx.run(rawQuery(1))
//SELECT x._1, x._2 FROM (SELECT id AS "_1", name AS "_2" FROM my_entity WHERE id = 1) xNote that in this case the result query is nested.
It's required since Quill is not aware of a query tree and cannot safely unnest it.
This is different from the example above because infix starts with the query infix"$q... where its tree is already compiled
A custom database function can also be used through infix:
val myFunction = quote {
(i: Int) => infix"MY_FUNCTION($i)".as[Int]
}
val q = quote {
query[Person].map(p => myFunction(p.age))
}
ctx.run(q)
// SELECT MY_FUNCTION(p.age) FROM Person pYou can implement comparison operators by defining implicit conversion and using infix.
import java.util.Date
implicit class DateQuotes(left: Date) {
def >(right: Date) = quote(infix"$left > $right".as[Boolean])
def <(right: Date) = quote(infix"$left < $right".as[Boolean])
}implicit class OnDuplicateKeyIgnore[T](q: Insert[T]) {
def ignoreDuplicate = quote(infix"$q ON DUPLICATE KEY UPDATE id=id".as[Insert[T]])
}
ctx.run(
liftQuery(List(
Person(1, "Test1", 30),
Person(2, "Test2", 31)
)).foreach(row => query[Person].insertValue(row).ignoreDuplicate)
)Quill uses Encoders to encode query inputs and Decoders to read values returned by queries. The library provides a few built-in encodings and two mechanisms to define custom encodings: mapped encoding and raw encoding.
If the correspondent database type is already supported, use MappedEncoding. In this example, String is already supported by Quill and the UUID encoding from/to String is defined through mapped encoding:
import ctx._
import java.util.UUID
implicit val encodeUUID = MappedEncoding[UUID, String](_.toString)
implicit val decodeUUID = MappedEncoding[String, UUID](UUID.fromString(_))A mapped encoding also can be defined without a context instance by importing io.getquill.MappedEncoding:
import io.getquill.MappedEncoding
import java.util.UUID
implicit val encodeUUID = MappedEncoding[UUID, String](_.toString)
implicit val decodeUUID = MappedEncoding[String, UUID](UUID.fromString(_))Note that can it be also used to provide mapping for element types of collection (SQL Arrays or Cassandra Collections).
If the database type is not supported by Quill, it is possible to provide "raw" encoders and decoders:
trait UUIDEncodingExample {
val jdbcContext: PostgresJdbcContext[Literal] // your context should go here
import jdbcContext._
implicit val uuidDecoder: Decoder[UUID] =
decoder((index, row) =>
UUID.fromString(row.getObject(index).toString)) // database-specific implementation
implicit val uuidEncoder: Encoder[UUID] =
encoder(java.sql.Types.OTHER, (index, value, row) =>
row.setObject(index, value, java.sql.Types.OTHER)) // database-specific implementation
// Only for postgres
implicit def arrayUUIDEncoder[Col <: Seq[UUID]]: Encoder[Col] = arrayRawEncoder[UUID, Col]("uuid")
implicit def arrayUUIDDecoder[Col <: Seq[UUID]](implicit bf: CBF[UUID, Col]): Decoder[Col] =
arrayRawDecoder[UUID, Col]
}Quill automatically encodes AnyVals (value classes):
case class UserId(value: Int) extends AnyVal
case class User(id: UserId, name: String)
val q = quote {
for {
u <- query[User] if u.id == lift(UserId(1))
} yield u
}
ctx.run(q)
// SELECT u.id, u.name FROM User u WHERE (u.id = 1)The meta DSL allows the user to customize how Quill handles column/table naming and behavior.
You can change how Quill queries handle table and column names for a record case class.
def example = {
implicit val personSchemaMeta = schemaMeta[Person]("people", _.id -> "person_id")
ctx.run(query[Person])
// SELECT x.person_id, x.name, x.age FROM people x
}By default, quill expands query[Person] to querySchema[Person]("Person"). It's possible to customize this behavior using an implicit instance of SchemaMeta:
You can exclude columns (e.g. Auto-Generated ones) from insertion in q.insertValue(...) by using an InsertMeta.
implicit val personInsertMeta = insertMeta[Person](_.id)
ctx.run(query[Person].insertValue(lift(Person(-1, "John", 22))))
// INSERT INTO Person (name,age) VALUES (?, ?)Note that the parameter of insertMeta is called exclude, but it isn't possible to use named parameters for macro invocations.
You can exclude columns (e.g. Auto-Generated ones) from updates in q.insertValue(...) by using an UpdateMeta.
implicit val personUpdateMeta = updateMeta[Person](_.id)
ctx.run(query[Person].filter(_.id == 1).updateValue(lift(Person(1, "John", 22))))
// UPDATE Person SET name = ?, age = ? WHERE id = 1Note that the parameter of updateMeta is called exclude, but it isn't possible to use named parameters for macro invocations.
The QueryMeta customizes the expansion of query types and extraction of the final value. For instance, it's possible to use this feature to normalize values before reading them from the database:
implicit val personQueryMeta =
queryMeta(
(q: Query[Person]) =>
q.map(p => (p.id, infix"CONVERT(${p.name} USING utf8)".as[String], p.age))
) {
case (id, name, age) =>
Person(id, name, age)
}The query meta definition is open and allows the user to even join values from other tables before reading the final value. This kind of usage is not encouraged.
Contexts represent the database and provide an execution interface for queries.
Quill provides a mirror context for testing purposes. Instead of running the query, the mirror context returns a structure with the information that would be used to run the query. There are three mirror context instances:
io.getquill.MirrorContext: Mirrors the quotation ASTio.getquill.SqlMirrorContext: Mirrors the SQL queryio.getquill.CassandraMirrorContext: Mirrors the CQL query
The context instance provides all methods and types to interact with quotations and the database. Depending on how the context import happens, Scala won't be able to infer that the types are compatible.
For instance, this example will not compile:
class MyContext extends SqlMirrorContext(MirrorSqlDialect, Literal)
case class MySchema(c: MyContext) {
import c._
val people = quote {
querySchema[Person]("people")
}
}
case class MyDao(c: MyContext, schema: MySchema) {
def allPeople =
c.run(schema.people)
// ERROR: [T](quoted: MyDao.this.c.Quoted[MyDao.this.c.Query[T]])MyDao.this.c.QueryResult[T]
cannot be applied to (MyDao.this.schema.c.Quoted[MyDao.this.schema.c.EntityQuery[Person]]{def quoted: io.getquill.ast.ConfiguredEntity; def ast: io.getquill.ast.ConfiguredEntity; def id1854281249(): Unit; val bindings: Object})
}
In ProtoQuill/Scala3 the above pattern will work as expected because the types Quoted, EntityQuery, etc... are no longer path dependent. Have a look at the following scastie example.
One way to compose applications with this kind of context is to use traits with an abstract context variable:
class MyContext extends SqlMirrorContext(MirrorSqlDialect, Literal)
trait MySchema {
val c: MyContext
import c._
val people = quote {
querySchema[Person]("people")
}
}
case class MyDao(c: MyContext) extends MySchema {
import c._
def allPeople =
c.run(people)
}Another simple way to modularize Quill code is by extending Context as a self-type and applying mixins. Using this strategy,
it is possible to create functionality that is fully portable across databases and even different types of databases
(e.g. creating common queries for both Postgres and Spark).
For example, create the following abstract context:
trait ModularContext[I <: Idiom, N <: NamingStrategy] { this: Context[I, N] =>
def peopleOlderThan = quote {
(age:Int, q:Query[Person]) => q.filter(p => p.age > age)
}
}Let's see how this can be used across different kinds of databases and Quill contexts.
// Note: In some cases need to explicitly specify [MirrorSqlDialect, Literal].
val ctx =
new SqlMirrorContext[MirrorSqlDialect, Literal](MirrorSqlDialect, Literal)
with ModularContext[MirrorSqlDialect, Literal]
import ctx._
println( run(peopleOlderThan(22, query[Person])).string )val ctx =
new PostgresJdbcContext[Literal](Literal, ds)
with ModularContext[PostgresDialect, Literal]
import ctx._
val results = run(peopleOlderThan(22, query[Person]))object CustomQuillSparkContext extends QuillSparkContext
with ModularContext[SparkDialect, Literal]
val results = run(peopleOlderThan(22, liftQuery(dataset)))Quill provides a fully type-safe way to use Spark's highly-optimized SQL engine. It's an alternative to Dataset's weakly-typed API.
libraryDependencies ++= Seq(
"io.getquill" %% "quill-spark" % "3.16.4-SNAPSHOT"
)
Unlike the other modules, the Spark context is a companion object. Also, it does not depend on a spark session. To use it, add the following import:
import org.apache.spark.sql.SparkSession
// Create your Spark Context
val session =
SparkSession.builder()
.master("local")
.appName("spark test")
.getOrCreate()
// The Spark SQL Context must be provided by the user through an implicit value:
implicit val sqlContext = session
import sqlContext.implicits._ // Also needed...
// Import the Quill Spark Context
import io.getquill.QuillSparkContext._Note Unlike the other modules, the Spark context is a companion object. Also, it does not depend on a spark session.
Also Note: Quill decoders and meta instances are not used by the quill-spark module, Spark's
Encoders are used instead.
The run method returns a Dataset transformed by the Quill query using the SQL engine.
// Typically you start with some type dataset.
val peopleDS: Dataset[Person] = spark.read.parquet("path/to/people")
val addressesDS: Dataset[Address] = spark.read.parquet("path/to/addresses")
// The liftQuery method converts Datasets to Quill queries:
val people: Query[Person] = quote { liftQuery(peopleDS) }
val addresses: Query[Address] = quote { liftQuery(addressesDS) }
val people: Query[(Person] = quote {
people.join(addresses).on((p, a) => p.id == a.ownerFk)
}
val peopleAndAddressesDS: Dataset[(Person, Address)] = run(people)Since the run method allows for Quill queries to be specified directly, and liftQuery can be used inside
of any Quoted block, you can shorten various steps of the above workflow:
val peopleDS: Dataset[Person] = spark.read.parquet("path/to/people")
val addressesDS: Dataset[Address] = spark.read.parquet("path/to/addresses")
val peopleAndAddressesDS: Dataset[(Person, Address)] = run {
liftQuery(peopleDS)
.join(liftQuery(addressesDS))
.on((p, a) => p.id == a.ownerFk)
}Here is an example of a Dataset being converted into Quill, filtered, and then written back out.
import org.apache.spark.sql.Dataset
def filter(myDataset: Dataset[Person], name: String): Dataset[Int] =
run {
liftQuery(myDataset).filter(_.name == lift(name)).map(_.age)
}
// SELECT x1.age _1 FROM (?) x1 WHERE x1.name = ?Due to the design of Quill-Spark, it can be used interchangeably throughout your Spark workflow:
- Lift a Dataset to Query to do some filtering and sub-selecting (with Predicate and Filter Pushdown!).
- Then covert it back to a Dataset to do Spark-Specific operations.
- Then convert it back to a Query to use Quills great Join DSL...
- Then convert it back to a Dataset to write it to a file or do something else with it...
TODO UDFs and UDAFs
Spark only supports using top-level classes as record types. That means that
when using quill-spark you can only use a top-level case class for T in Query[T].
TODO Get the specific error
The queries printed from run(myQuery) during compile time escape question marks via a backslash them in order to
be able to substitute liftings properly. They are then returned back to their original form before running.
import org.apache.spark.sql.Dataset
def filter(myDataset: Dataset[Person]): Dataset[Int] =
run {
liftQuery(myDataset).filter(_.name == "?").map(_.age)
}
// This is generated during compile time:
// SELECT x1.age _1 FROM (?) x1 WHERE x1.name = '\?'
// It is reverted upon run-time:
// SELECT x1.age _1 FROM (ds1) x1 WHERE x1.name = '?'Example:
lazy val ctx = new MysqlJdbcContext(SnakeCase, "ctx")The SQL dialect parameter defines the specific database dialect to be used. Some context types are specific to a database and thus not require it.
Quill has five built-in dialects:
io.getquill.H2Dialectio.getquill.MySQLDialectio.getquill.PostgresDialectio.getquill.SqliteDialectio.getquill.SQLServerDialectio.getquill.OracleDialect
The naming strategy parameter defines the behavior when translating identifiers (table and column names) to SQL.
| strategy | example |
|---|---|
io.getquill.naming.Literal |
some_ident -> some_ident |
io.getquill.naming.Escape |
some_ident -> "some_ident" |
io.getquill.naming.UpperCase |
some_ident -> SOME_IDENT |
io.getquill.naming.LowerCase |
SOME_IDENT -> some_ident |
io.getquill.naming.SnakeCase |
someIdent -> some_ident |
io.getquill.naming.CamelCase |
some_ident -> someIdent |
io.getquill.naming.MysqlEscape |
some_ident -> `some_ident` |
io.getquill.naming.PostgresEscape |
$some_ident -> $some_ident |
Multiple transformations can be defined using NamingStrategy(). For instance, the naming strategy
NamingStrategy(SnakeCase, UpperCase)
produces the following transformation:
someIdent -> SOME_IDENT
The transformations are applied from left to right.
The string passed to the context is used as the key in order to obtain configurations using the typesafe config library.
Additionally, the contexts provide multiple constructors. For instance, with JdbcContext it's possible to specify a DataSource directly, without using the configuration:
def createDataSource: javax.sql.DataSource with java.io.Closeable = ???
lazy val ctx = new MysqlJdbcContext(SnakeCase, createDataSource)The quill-jdbc module provides a simple blocking JDBC context for standard use-cases. For transactions, the JDBC connection is kept in a thread-local variable.
Quill uses HikariCP for connection pooling. Please refer to HikariCP's documentation for a detailed explanation of the available configurations.
Note that there are dataSource configurations, that go under dataSource, like user and password, but some pool settings may go under the root config, like connectionTimeout.
The JdbcContext provides thread-local transaction support:
ctx.transaction {
ctx.run(query[Person].delete)
// other transactional code
}
The body of transaction can contain calls to other methods and multiple run calls since the transaction is propagated through a thread-local.
libraryDependencies ++= Seq(
"mysql" % "mysql-connector-java" % "8.0.17",
"io.getquill" %% "quill-jdbc" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new MysqlJdbcContext(SnakeCase, "ctx")ctx.dataSourceClassName=com.mysql.cj.jdbc.MysqlDataSource
ctx.dataSource.url=jdbc:mysql://host/database
ctx.dataSource.user=root
ctx.dataSource.password=root
ctx.dataSource.cachePrepStmts=true
ctx.dataSource.prepStmtCacheSize=250
ctx.dataSource.prepStmtCacheSqlLimit=2048
ctx.connectionTimeout=30000
libraryDependencies ++= Seq(
"org.postgresql" % "postgresql" % "42.2.8",
"io.getquill" %% "quill-jdbc" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new PostgresJdbcContext(SnakeCase, "ctx")ctx.dataSourceClassName=org.postgresql.ds.PGSimpleDataSource
ctx.dataSource.user=root
ctx.dataSource.password=root
ctx.dataSource.databaseName=database
ctx.dataSource.portNumber=5432
ctx.dataSource.serverName=host
ctx.connectionTimeout=30000
libraryDependencies ++= Seq(
"org.xerial" % "sqlite-jdbc" % "3.28.0",
"io.getquill" %% "quill-jdbc" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new SqliteJdbcContext(SnakeCase, "ctx")ctx.driverClassName=org.sqlite.JDBC
ctx.jdbcUrl=jdbc:sqlite:/path/to/db/file.db
libraryDependencies ++= Seq(
"com.h2database" % "h2" % "1.4.199",
"io.getquill" %% "quill-jdbc" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new H2JdbcContext(SnakeCase, "ctx")ctx.dataSourceClassName=org.h2.jdbcx.JdbcDataSource
ctx.dataSource.url=jdbc:h2:mem:yourdbname
ctx.dataSource.user=sa
libraryDependencies ++= Seq(
"com.microsoft.sqlserver" % "mssql-jdbc" % "7.4.1.jre8",
"io.getquill" %% "quill-jdbc" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new SqlServerJdbcContext(SnakeCase, "ctx")Quill supports Oracle version 12c and up although due to licensing restrictions, version 18c XE is used for testing.
Note that the latest Oracle JDBC drivers are not publicly available. In order to get them, you will need to connect to Oracle's private maven repository as instructed here. Unfortunately, this procedure currently does not work for SBT. There are various workarounds available for this situation here.
libraryDependencies ++= Seq(
"com.oracle.jdbc" % "ojdbc8" % "18.3.0.0.0",
"io.getquill" %% "quill-jdbc" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new OracleJdbcContext(SnakeCase, "ctx")ctx.dataSourceClassName=com.microsoft.sqlserver.jdbc.SQLServerDataSource
ctx.dataSource.user=user
ctx.dataSource.password=YourStrongPassword
ctx.dataSource.databaseName=database
ctx.dataSource.portNumber=1433
ctx.dataSource.serverName=host
Quill context that executes JDBC queries inside of ZIO. Unlike most other contexts
that require passing in a java.sql.DataSource when the context is created, this context's
run methods return a ZIO that has a DataSource resource dependency.
Naturally, this should be provided later on in your application
(see ZioJdbc for helper methods that assist in doing this).
Since resource dependency is Has[DataSource] the result of a run call is ZIO[Has[DataSource], SQLException, T].
This means that if you have a DataSource object, you can just provide it!
def ds: DataSource = _
run(people).provide(Has(ds))Since most quill-zio methods return
ZIO[Has[DataSource], SQLException, T]the typeQIO[T]i.e. Quill-IO has been defined as an alias.For underlying-contexts (see below) that depend on
Has[Connection], the aliasQCIO[T](i.e. Quill-Connection-IO) has been defined forZIO[Has[Connection], SQLException, T].
Since in most JDBC use-cases, a connection-pool datasource (e.g. Hikari) is used,
constructor-methods fromPrefix, fromConfig, fromJdbcConfig are available on
DataSourceLayer to construct instances of a ZLayer[Any, SQLException, Has[DataSource]]
which can be easily used to provide a DataSource dependency.
You can use them like this:
import ZioJdbc._
val zioDs = DataSourceLayer.fromPrefix("testPostgresDB")
MyZioContext.run(query[Person]).provideCustomLayer(zioDS)If in some rare cases, you wish to provide a java.sql.Connection to a run method directly, you can delegate
to the underlying-context. This is a more low-level context whose run methods have a Has[Connection] resource.
Here is an example of how this can be done.
def conn: Connection = _ // If you are starting with a connection object
import io.getquill.context.ZioJdbc._
// Import encoders/decoders of the underlying context. Do not import quote/run/prepare methods to avoid conflicts.
import MyZioContext.underlying.{ quote => _, run => _, prepare => _, _ }
MyZioContext.underlying.run(people).provide(Has(conn))If you are working with an underlying-context and want to provide a DataSource instead of a connection,
you can use the onDataSource method. Note however that this is only needed when working with an underlying-context.
When working with a normal context, onDataSource is not available or necessary
(since for a normal contexts R will be Has[DataSource]).
val ds: DataSource = _
import io.getquill.context.ZioJdbc._
// Import encoders/decoders of the underlying context. Do not import quote/run/prepare methods to avoid conflicts.
import MyZioContext.underlying.{ quote => _, run => _, prepare => _, _ }
MyZioContext.underlying.run(people).onDataSource.provide(Has(ds))Also note that if you are using a Plain Scala app however, you will need to manually run it i.e. using zio.Runtime
Runtime.default.unsafeRun(MyZioContext.run(query[Person]).provideLayer(zioDS))
One additional useful pattern is to use import io.getquill.context.qzio.ImplicitSyntax.Implicit to provide
an implicit DataSource to one or multiple run(qry) calls in a context. This is very useful when creating
DAO patterns that will reuse a DataSource many times:
case class MyQueryService(ds: DataSource with Closeable) { // I.e. our DAO
import Ctx._
implicit val env = Implicit(Has(ds)) // This will be looked up in each `.implicitDS` call
val joes = Ctx.run(query[Person].filter(p => p.name == "Joe")).implicitDS
val jills = Ctx.run(query[Person].filter(p => p.name == "Jill")).implicitDS
val alexes = Ctx.run(query[Person].filter(p => p.name == "Alex")).implicitDS
}More examples of a Quill-JDBC-ZIO app quill-jdbc-zio/src/test/scala/io/getquill/examples.
The ZioJdbcContext can stream using zio.ZStream:
ctx.stream(query[Person]) // returns: ZStream[Has[Connection], Throwable, Person]
.run(Sink.collectAll).map(_.toList) // returns: ZIO[Has[Connection], Throwable, List[T]]
The ZioJdbcContexts provide support for transactions without needing thread-local storage or similar
because they propagate the resource dependency in the ZIO effect itself (i.e. the Has[Connection] in Zio[Has[Connection], _, _]).
As with the other contexts, if an exception is thrown anywhere inside a task or sub-task within a transaction block, the entire block
will be rolled back by the database.
Basic syntax:
val trans =
ctx.transaction {
for {
_ <- ctx.run(query[Person].delete)
_ <- ctx.run(query[Person].insertValue(Person("Joe", 123)))
p <- ctx.run(query[Person])
} yield p
} //returns: ZIO[Has[Connection], Throwable, List[Person]]
val result = Runtime.default.unsafeRun(trans.onDataSource.provide(ds)) //returns: List[Person]
libraryDependencies ++= Seq(
"mysql" % "mysql-connector-java" % "8.0.17",
"io.getquill" %% "quill-jdbc-zio" % "3.16.4-SNAPSHOT"
)
val ctx = new MysqlZioJdbcContext(SnakeCase)
// Also can be static:
object MyContext extends MysqlZioJdbcContext(SnakeCase)ctx.dataSourceClassName=com.mysql.cj.jdbc.MysqlDataSource
ctx.dataSource.url=jdbc:mysql://host/database
ctx.dataSource.user=root
ctx.dataSource.password=root
ctx.dataSource.cachePrepStmts=true
ctx.dataSource.prepStmtCacheSize=250
ctx.dataSource.prepStmtCacheSqlLimit=2048
ctx.connectionTimeout=30000
libraryDependencies ++= Seq(
"org.postgresql" % "postgresql" % "42.2.8",
"io.getquill" %% "quill-jdbc-zio" % "3.16.4-SNAPSHOT"
)
val ctx = new PostgresZioJdbcContext(SnakeCase)
// Also can be static:
object MyContext extends PostgresZioJdbcContext(SnakeCase)ctx.dataSourceClassName=org.postgresql.ds.PGSimpleDataSource
ctx.dataSource.user=root
ctx.dataSource.password=root
ctx.dataSource.databaseName=database
ctx.dataSource.portNumber=5432
ctx.dataSource.serverName=host
ctx.connectionTimeout=30000
libraryDependencies ++= Seq(
"org.xerial" % "sqlite-jdbc" % "3.28.0",
"io.getquill" %% "quill-jdbc-zio" % "3.16.4-SNAPSHOT"
)
val ctx = new SqlitezioJdbcContext(SnakeCase)
// Also can be static:
object MyContext extends SqlitezioJdbcContext(SnakeCase)ctx.driverClassName=org.sqlite.JDBC
ctx.jdbcUrl=jdbc:sqlite:/path/to/db/file.db
libraryDependencies ++= Seq(
"com.h2database" % "h2" % "1.4.199",
"io.getquill" %% "quill-jdbc-zio" % "3.16.4-SNAPSHOT"
)
val ctx = new H2ZioJdbcContext(SnakeCase)
// Also can be static:
object MyContext extends H2ZioJdbcContext(SnakeCase)ctx.dataSourceClassName=org.h2.jdbcx.JdbcDataSource
ctx.dataSource.url=jdbc:h2:mem:yourdbname
ctx.dataSource.user=sa
libraryDependencies ++= Seq(
"com.microsoft.sqlserver" % "mssql-jdbc" % "7.4.1.jre8",
"io.getquill" %% "quill-jdbc-zio" % "3.16.4-SNAPSHOT"
)
val ctx = new SqlServerZioJdbcContext(SnakeCase)
// Also can be static:
object MyContext extends SqlServerZioJdbcContext(SnakeCase)ctx.dataSourceClassName=com.microsoft.sqlserver.jdbc.SQLServerDataSource
ctx.dataSource.user=user
ctx.dataSource.password=YourStrongPassword
ctx.dataSource.databaseName=database
ctx.dataSource.portNumber=1433
ctx.dataSource.serverName=host
Quill supports Oracle version 12c and up although due to licensing restrictions, version 18c XE is used for testing.
libraryDependencies ++= Seq(
"com.oracle.jdbc" % "ojdbc8" % "18.3.0.0.0",
"io.getquill" %% "quill-jdbc-zio" % "3.16.4-SNAPSHOT"
)
val ctx = new OracleZioJdbcContext(SnakeCase)
// Also can be static:
object MyContext extends OracleZioJdbcContext(SnakeCase)ctx.dataSourceClassName=oracle.jdbc.xa.client.OracleXADataSource
ctx.dataSource.databaseName=xe
ctx.dataSource.user=database
ctx.dataSource.password=YourStrongPassword
ctx.dataSource.driverType=thin
ctx.dataSource.portNumber=1521
ctx.dataSource.serverName=host
The quill-jdbc-monix module integrates the Monix asynchronous programming framework with Quill,
supporting all of the database vendors of the quill-jdbc module.
The Quill Monix contexts encapsulate JDBC Queries and Actions into Monix Tasks
and also include support for streaming queries via Observable.
The MonixJdbcContext can stream using Monix Observables:
ctx.stream(query[Person]) // returns: Observable[Person]
.foreachL(println(_))
.runSyncUnsafe()
The MonixJdbcContext provides support for transactions by storing the connection into a Monix Local.
This process is designed to be completely transparent to the user. As with the other contexts,
if an exception is thrown anywhere inside a task or sub-task within a transaction block, the entire block
will be rolled back by the database.
Basic syntax:
val trans =
ctx.transaction {
for {
_ <- ctx.run(query[Person].delete)
_ <- ctx.run(query[Person].insertValue(Person("Joe", 123)))
p <- ctx.run(query[Person])
} yield p
} //returns: Task[List[Person]]
val result = trans.runSyncUnsafe() //returns: List[Person]
Streaming can also be done inside of transaction block so long as the result is converted to a task beforehand.
val trans =
ctx.transaction {
for {
_ <- ctx.run(query[Person].insertValue(Person("Joe", 123)))
ppl <- ctx
.stream(query[Person]) // Observable[Person]
.foldLeftL(List[Person]())({case (l, p) => p +: l}) // ... becomes Task[List[Person]]
} yield ppl
} //returns: Task[List[Person]]
val result = trans.runSyncUnsafe() //returns: List[Person]
Use a Runner object to create the different MonixJdbcContexts.
The Runner does the actual wrapping of JDBC calls into Monix Tasks.
import monix.execution.Scheduler
import io.getquill.context.monix.Runner
// You can use the default Runner when constructing a Monix jdbc contexts.
// The resulting tasks will be wrapped with whatever Scheduler is
// defined when you do task.syncRunUnsafe(), typically a global implicit.
lazy val ctx = new MysqlMonixJdbcContext(SnakeCase, "ctx", EffectWrapper.default)
// However...
// Monix strongly suggests that you use a separate thread pool for database IO
// operations. `Runner` provides a convenience method in order to do this.
lazy val ctx = new MysqlMonixJdbcContext(SnakeCase, "ctx", Runner.using(Scheduler.io()))libraryDependencies ++= Seq(
"mysql" % "mysql-connector-java" % "8.0.17",
"io.getquill" %% "quill-jdbc-monix" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new MysqlMonixJdbcContext(SnakeCase, "ctx", EffectWrapper.default)ctx.dataSourceClassName=com.mysql.cj.jdbc.MysqlDataSource
ctx.dataSource.url=jdbc:mysql://host/database
ctx.dataSource.user=root
ctx.dataSource.password=root
ctx.dataSource.cachePrepStmts=true
ctx.dataSource.prepStmtCacheSize=250
ctx.dataSource.prepStmtCacheSqlLimit=2048
ctx.connectionTimeout=30000
libraryDependencies ++= Seq(
"org.postgresql" % "postgresql" % "42.2.8",
"io.getquill" %% "quill-jdbc-monix" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new PostgresMonixJdbcContext(SnakeCase, "ctx", EffectWrapper.default)ctx.dataSourceClassName=org.postgresql.ds.PGSimpleDataSource
ctx.dataSource.user=root
ctx.dataSource.password=root
ctx.dataSource.databaseName=database
ctx.dataSource.portNumber=5432
ctx.dataSource.serverName=host
ctx.connectionTimeout=30000
libraryDependencies ++= Seq(
"org.xerial" % "sqlite-jdbc" % "3.28.0",
"io.getquill" %% "quill-jdbc-monix" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new SqliteMonixJdbcContext(SnakeCase, "ctx", EffectWrapper.default)ctx.driverClassName=org.sqlite.JDBC
ctx.jdbcUrl=jdbc:sqlite:/path/to/db/file.db
libraryDependencies ++= Seq(
"com.h2database" % "h2" % "1.4.199",
"io.getquill" %% "quill-jdbc-monix" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new H2MonixJdbcContext(SnakeCase, "ctx", EffectWrapper.default)ctx.dataSourceClassName=org.h2.jdbcx.JdbcDataSource
ctx.dataSource.url=jdbc:h2:mem:yourdbname
ctx.dataSource.user=sa
libraryDependencies ++= Seq(
"com.microsoft.sqlserver" % "mssql-jdbc" % "7.4.1.jre8",
"io.getquill" %% "quill-jdbc-monix" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new SqlServerMonixJdbcContext(SnakeCase, "ctx", EffectWrapper.default)ctx.dataSourceClassName=com.microsoft.sqlserver.jdbc.SQLServerDataSource
ctx.dataSource.user=user
ctx.dataSource.password=YourStrongPassword
ctx.dataSource.databaseName=database
ctx.dataSource.portNumber=1433
ctx.dataSource.serverName=host
Quill supports Oracle version 12c and up although due to licensing restrictions, version 18c XE is used for testing.
Note that the latest Oracle JDBC drivers are not publicly available. In order to get them, you will need to connect to Oracle's private maven repository as instructed here. Unfortunately, this procedure currently does not work for SBT. There are various workarounds available for this situation here.
libraryDependencies ++= Seq(
"com.oracle.jdbc" % "ojdbc8" % "18.3.0.0.0",
"io.getquill" %% "quill-jdbc-monix" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new OracleJdbcContext(SnakeCase, "ctx")ctx.dataSourceClassName=oracle.jdbc.xa.client.OracleXADataSource
ctx.dataSource.databaseName=xe
ctx.dataSource.user=database
ctx.dataSource.password=YourStrongPassword
ctx.dataSource.driverType=thin
ctx.dataSource.portNumber=1521
ctx.dataSource.serverName=host
Async support via NDBC driver is available with Postgres database.
Transaction support is provided out of the box by NDBC:
ctx.transaction {
ctx.run(query[Person].delete)
// other transactional code
}The body of transaction can contain calls to other methods and multiple run calls since the transaction is automatically handled.
libraryDependencies ++= Seq(
"io.getquill" %% "quill-ndbc-postgres" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new NdbcPostgresContext(Literal, "ctx")ctx.ndbc.dataSourceSupplierClass=io.trane.ndbc.postgres.netty4.DataSourceSupplier
ctx.ndbc.host=host
ctx.ndbc.port=1234
ctx.ndbc.user=root
ctx.ndbc.password=root
ctx.ndbc.database=database
The quill-async module provides simple async support for MySQL and Postgres databases.
The async module provides transaction support based on a custom implicit execution context:
ctx.transaction { implicit ec =>
ctx.run(query[Person].delete)
// other transactional code
}
The body of transaction can contain calls to other methods and multiple run calls, but the transactional code must be done using the provided implicit execution context. For instance:
def deletePerson(name: String)(implicit ec: ExecutionContext) =
ctx.run(query[Person].filter(_.name == lift(name)).delete)
ctx.transaction { implicit ec =>
deletePerson("John")
}
Depending on how the main execution context is imported, it is possible to produce an ambiguous implicit resolution. A way to solve this problem is shadowing the multiple implicits by using the same name:
import scala.concurrent.ExecutionContext.Implicits.{ global => ec }
def deletePerson(name: String)(implicit ec: ExecutionContext) =
ctx.run(query[Person].filter(_.name == lift(name)).delete)
ctx.transaction { implicit ec =>
deletePerson("John")
}
Note that the global execution context is renamed to ec.
ctx.host=host
ctx.port=1234
ctx.user=root
ctx.password=root
ctx.database=database
or use connection URL with database-specific scheme (see below):
ctx.url=scheme://host:5432/database?user=root&password=root
ctx.poolMaxQueueSize=4
ctx.poolMaxObjects=4
ctx.poolMaxIdle=999999999
ctx.poolValidationInterval=10000
Also see PoolConfiguration documentation.
ctx.sslmode=disable # optional, one of [disable|prefer|require|verify-ca|verify-full]
ctx.sslrootcert=./path/to/cert/file # optional, required for sslmode=verify-ca or verify-full
ctx.charset=UTF-8
ctx.maximumMessageSize=16777216
ctx.connectTimeout=5s
ctx.testTimeout=5s
ctx.queryTimeout=10m
libraryDependencies ++= Seq(
"io.getquill" %% "quill-async-mysql" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new MysqlAsyncContext(SnakeCase, "ctx")See above
For url property use mysql scheme:
ctx.url=mysql://host:3306/database?user=root&password=root
libraryDependencies ++= Seq(
"io.getquill" %% "quill-async-postgres" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new PostgresAsyncContext(SnakeCase, "ctx")For url property use postgresql scheme:
ctx.url=postgresql://host:5432/database?user=root&password=root
The quill-jasync module provides simple async support for Postgres databases.
The async module provides transaction support based on a custom implicit execution context:
ctx.transaction { implicit ec =>
ctx.run(query[Person].delete)
// other transactional code
}
The body of transaction can contain calls to other methods and multiple run calls, but the transactional code must be done using the provided implicit execution context. For instance:
def deletePerson(name: String)(implicit ec: ExecutionContext) =
ctx.run(query[Person].filter(_.name == lift(name)).delete)
ctx.transaction { implicit ec =>
deletePerson("John")
}
Depending on how the main execution context is imported, it is possible to produce an ambiguous implicit resolution. A way to solve this problem is shadowing the multiple implicits by using the same name:
import scala.concurrent.ExecutionContext.Implicits.{ global => ec }
def deletePerson(name: String)(implicit ec: ExecutionContext) =
ctx.run(query[Person].filter(_.name == lift(name)).delete)
ctx.transaction { implicit ec =>
deletePerson("John")
}
Note that the global execution context is renamed to ec.
ctx.host=host
ctx.port=1234
ctx.username=root
ctx.password=root
ctx.database=database
or use connection URL with database-specific scheme (see below):
ctx.url=scheme://host:5432/database?user=root&password=root
Also see full settings ConnectionPoolConfiguration documentation.
ctx.sslmode=disable # optional, one of [disable|prefer|require|verify-ca|verify-full]
ctx.sslrootcert=./path/to/cert/file # optional, required for sslmode=verify-ca or verify-full
libraryDependencies ++= Seq(
"io.getquill" %% "quill-jasync-mysql" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new MysqlJAsyncContext(SnakeCase, "ctx")See above
For url property use mysql scheme:
ctx.url=mysql://host:3306/database?user=root&password=root
libraryDependencies ++= Seq(
"io.getquill" %% "quill-jasync-postgres" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new PostgresJAsyncContext(SnakeCase, "ctx")For url property use postgresql scheme:
ctx.url=postgresql://host:5432/database?user=root&password=root
The quill-jasync-zio module provides ZIO async support for Postgres databases.
ctx.host=host
ctx.port=1234
ctx.username=root
ctx.password=root
ctx.database=database
or use connection URL with database-specific scheme (see below):
ctx.url=scheme://host:5432/database?user=root&password=root
Also see full settings ConnectionPoolConfiguration documentation.
ctx.sslmode=disable # optional, one of [disable|prefer|require|verify-ca|verify-full]
ctx.sslrootcert=./path/to/cert/file # optional, required for sslmode=verify-ca or verify-full
libraryDependencies ++= Seq(
"io.getquill" %% "quill-jasync-zio-postgres" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new PostgresZioJAsyncContext(SnakeCase)
// Also can be static:
object MyContext extends PostgresZioJAsyncContext(Literal)In order to run operation in this context we need to provide ZioJAsyncConnection instance.
object MyApp extends zio.App {
object DBContext extends PostgresZioJAsyncContext(Literal)
import DBContext._
val dependencies =
PostgresJAsyncContextConfig.loadConfig("testPostgresDB") >>>
ZioJAsyncConnection.live[PostgreSQLConnection]
val program = run(query[Person])
def run(args: List[String]) = program.provideLayer(dependencies).exitCode
}For url property use postgresql scheme:
ctx.url=postgresql://host:5432/database?user=root&password=root
Support for the Twitter Finagle library is available with MySQL and Postgres databases.
The finagle context provides transaction support through a Local value. See twitter util's scaladoc for more details.
ctx.transaction {
ctx.run(query[Person].delete)
// other transactional code
}
The finagle context allows streaming a query response, returning an AsyncStream value.
ctx.stream(query[Person]) // returns: Future[AsyncStream[Person]]
.flatMap(_.toSeq())
The body of transaction can contain calls to other methods and multiple run calls since the transaction is automatically propagated through the Local value.
libraryDependencies ++= Seq(
"io.getquill" %% "quill-finagle-mysql" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new FinagleMysqlContext(SnakeCase, "ctx")ctx.dest=localhost:3306
ctx.user=root
ctx.password=root
ctx.database=database
ctx.pool.watermark.low=0
ctx.pool.watermark.high=10
ctx.pool.idleTime=5 # seconds
ctx.pool.bufferSize=0
ctx.pool.maxWaiters=2147483647
The finagle context provides transaction support through a Local value. See twitter util's scaladoc for more details.
ctx.transaction {
ctx.run(query[Person].delete)
// other transactional code
}
The body of transaction can contain calls to other methods and multiple run calls since the transaction is automatically propagated through the Local value.
libraryDependencies ++= Seq(
"io.getquill" %% "quill-finagle-postgres" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new FinaglePostgresContext(SnakeCase, "ctx")ctx.host=localhost:3306
ctx.user=root
ctx.password=root
ctx.database=database
ctx.useSsl=false
ctx.hostConnectionLimit=1
ctx.numRetries=4
ctx.binaryResults=false
ctx.binaryParams=false
libraryDependencies ++= Seq(
"io.getquill" %% "quill-cassandra" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new CassandraSyncContext(SnakeCase, "ctx")lazy val ctx = new CassandraAsyncContext(SnakeCase, "ctx")The configurations are set using runtime reflection on the Cluster.builder instance. It is possible to set nested structures like queryOptions.consistencyLevel, use enum values like LOCAL_QUORUM, and set multiple parameters like in credentials.
ctx.keyspace=quill_test
ctx.preparedStatementCacheSize=1000
ctx.session.contactPoint=127.0.0.1
ctx.session.withPort=9042
ctx.session.queryOptions.consistencyLevel=LOCAL_QUORUM
ctx.session.withoutMetrics=true
ctx.session.withoutJMXReporting=false
ctx.session.credentials.0=root
ctx.session.credentials.1=pass
ctx.session.maxSchemaAgreementWaitSeconds=1
ctx.session.addressTranslator=com.datastax.driver.core.policies.IdentityTranslator
Quill context that executes Cassandra queries inside of ZIO. Unlike most other contexts
that require passing in a Data Source, this context takes in a CassandraZioSession
as a resource dependency which can be provided later (see the CassandraZioSession object for helper methods
that assist in doing this).
The resource dependency itself is just a Has[CassandraZioSession] hence run(qry) and other methods in this context will return
ZIO[Has[CassandraZioSession], Throwable, T]. The type CIO[T] i.e. Cassandra-IO is an alias for this.
Providing a CassandraZioSession dependency is now very simple:
val session: CassandraZioSession = _
run(people)
.provide(Has(session))Various methods in the io.getquill.CassandraZioSession can assist in simplifying it's creation, for example, you can
provide a Config object instead of a CassandraZioSession like this:
val zioSessionLayer: ZLayer[Any, Throwable, Has[CassandraZioSession]] =
CassandraZioSession.fromPrefix("testStreamDB")
run(query[Person])
.provideCustomLayer(zioSessionLayer)(Note that the resulting CassandraZioSession has a closing bracket)
If you are using a Plain Scala app, you will need to manually run it e.g. using zio.Runtime
Runtime.default.unsafeRun(MyZioContext.run(query[Person]).provideCustomLayer(zioSessionLayer))One additional useful pattern is to use import io.getquill.context.qzio.ImplicitSyntax.Implicit to provide
an implicit CassandraZioSession to one or multiple run(qry) calls in a context. This is very useful when creating
DAO patterns that will reuse a CassandraZioSession many times:
case class MyQueryService(cs: CassandraZioSession) {
import Ctx._
implicit val env = Implicit(Has(cs))
def joes = Ctx.run { query[Person].filter(p => p.name == "Joe") }.implicitly
def jills = Ctx.run { query[Person].filter(p => p.name == "Jill") }.implicitly
def alexes = Ctx.run { query[Person].filter(p => p.name == "Alex") }.implicitly
}More examples of a Quill-Cassandra-ZIO app quill-cassandra-zio/src/test/scala/io/getquill/context/cassandra/zio/examples.
libraryDependencies ++= Seq(
"io.getquill" %% "quill-cassandra-zio" % "3.16.4-SNAPSHOT"
)
libraryDependencies ++= Seq(
"io.getquill" %% "quill-cassandra-monix" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new CassandraMonixContext(SnakeCase, "ctx")lazy val ctx = new CassandraStreamContext(SnakeCase, "ctx")libraryDependencies ++= Seq(
"io.getquill" %% "quill-cassandra-alpakka" % "3.16.4-SNAPSHOT"
)
See Alpakka Cassandra documentation page for more information.
import akka.actor.ActorSystem
import akka.stream.alpakka.cassandra.CassandraSessionSettings
import akka.stream.alpakka.cassandra.scaladsl.{CassandraSession, CassandraSessionRegistry}
import io.getquill.CassandraAlpakkaContext
val system: ActorSystem = ???
val alpakkaSessionSettings = CassandraSessionSettings("quill-test.alpakka.cassandra")
val alpakkaSession: CassandraSession = CassandraSessionRegistry.get(system).sessionFor(alpakkaSessionSettings)
lazy val ctx = new CassandraAlpakkaContext(SnakeCase, alpakkaSession, preparedStatementCacheSize = 100)// alpakka cassandra session with keyspace
quill-test.alpakka.cassandra: ${alpakka.cassandra} { // inheritance of alpakka.cassandra session configuration
// custom datastax driver setup
datastax-java-driver-config = quill-test-datastax-java-driver
}
quill-test-datastax-java-driver {
basic {
// keyspace at datastax driver setup, as there is not different option now
session-keyspace = "quill_test"
}
}
libraryDependencies ++= Seq(
"io.getquill" %% "quill-orientdb" % "3.16.4-SNAPSHOT"
)
lazy val ctx = new OrientDBSyncContext(SnakeCase, "ctx")The configurations are set using OPartitionedDatabasePool which creates a pool of DB connections from which an instance of connection can be acquired. It is possible to set DB credentials using the parameter called username and password.
ctx.dbUrl=remote:127.0.0.1:2424/GratefulDeadConcerts
ctx.username=root
ctx.password=root
Quill now has a highly customizable code generator. Currently, it only supports JDBC but it will soon be extended to other contexts. With a minimal amount of configuration, the code generator takes schemas like this:
-- Using schema 'public'
create table public.Person (
id int primary key auto_increment,
first_name varchar(255),
last_name varchar(255),
age int not null
);
create table public.Address (
person_fk int not null,
street varchar(255),
zip int
);Producing objects like this:
// src/main/scala/com/my/project/public/Person.scala
package com.my.project.public
case class Person(id: Int, firstName: Option[String], lastName: Option[String], age: Int)// src/main/scala/com/my/project/public/Address.scala
package com.my.project.public
case class Address(personFk: Int, street: Option[String], zip: Option[Int])Have a look at the CODEGEN.md manual page for more details.
libraryDependencies ++= Seq(
"io.getquill" %% "quill-codegen-jdbc" % "3.16.4-SNAPSHOT"
)
To disable logging of queries during compilation use quill.macro.log option:
sbt -Dquill.macro.log=false
Quill uses SLF4J for logging. Each context logs queries which are currently executed.
It also logs the list of parameters that are bound into a prepared statement if any.
To enable that use quill.binds.log option:
java -Dquill.binds.log=true -jar myapp.jar
Quill can pretty print compile-time produced queries by leveraging a great library
produced by @vertical-blank which is compatible
with both Scala and ScalaJS. To enable this feature use the quill.macro.log.pretty option:
sbt -Dquill.macro.log.pretty=true
Before:
[info] /home/me/project/src/main/scala/io/getquill/MySqlTestPerson.scala:20:18: SELECT p.id, p.name, p.age, a.ownerFk, a.street, a.state, a.zip FROM Person p INNER JOIN Address a ON a.ownerFk = p.id
After:
[info] /home/me/project/src/main/scala/io/getquill/MySqlTestPerson.scala:20:18:
[info] | SELECT
[info] | p.id,
[info] | p.name,
[info] | p.age,
[info] | a.ownerFk,
[info] | a.street,
[info] | a.state,
[info] | a.zip
[info] | FROM
[info] | Person p
[info] | INNER JOIN Address a ON a.ownerFk = p.id
In order to quickly start with Quill, we have setup some template projects:
Please refer to SLICK.md for a detailed comparison between Quill and Slick.
Please refer to CASSANDRA.md for a detailed comparison between Quill and other main alternatives for interaction with Cassandra in Scala.
- quill-generic - Generic DAO Support for Quill.
- scala-db-codegen - Code/boilerplate generator from db schema
- quill-cache - Caching layer for Quill
- quill-gen - a DAO generator for
quill-cache
- [Dotty/Scala 3] Functional Scala 2020 - Quill, Dotty, And The Awesome Power of 'Inline'
- [Intro] ScalaDays Berlin 2016 - Scylla, Charybdis, and the mystery of Quill
- [Intro] Postgres Philly 2019 - Introduction to Quill
- ScalaUA 2020 - Manipulating Abstract Syntax Trees (ASTs) to generate safe SQL Queries with Quill
- BeeScala 2019 - Quill + Spark = Better Together
- Scale By the Bay 2019 - Quill + Doobie = Better Together
- ScQuilL, Porting Quill to Dotty (Ongoing) - Quill, Dotty, and Macros
- [Intro] Haoyi's Programming Blog - Working with Databases using Scala and Quill
- Juliano Alves's Blog - Streaming all the way with ZIO, Doobie, Quill, http4s and fs2
- Juliano Alves's Blog - Quill: Translating Boolean Literals
- Juliano Alves's Blog - Quill NDBC Postgres: A New Async Module
- Juliano Alves's Blog - Contributing to Quill, a Pairing Session
- Medium @ Fwbrasil - quill-spark: A type-safe Scala API for Spark SQL
- Scalac.io blog - Compile-time Queries with Quill
Please note that this project is released with a Contributor Code of Conduct. By participating in this project you agree to abide by its terms. See CODE_OF_CONDUCT.md for details.
See the LICENSE file for details.
- @deusaquilus (lead maintainer)
- @fwbrasil (creator)
- @jilen
- @juliano
- @mentegy
- @mdedetrich
- @gustavoamigo
- @godenji
- @lvicentesanchez
- @mxl
You can notify all current maintainers using the handle @getquill/maintainers.
The project was created having Philip Wadler's talk "A practical theory of language-integrated query" as its initial inspiration. The development was heavily influenced by the following papers: