点击关注本公众号获取文档最新更新,并可以领取配套于本指南的 《前端面试手册》 以及最标准的简历模板.
TCP的面试题通常情况下前端不会涉及太多,此章主要面对node.js工程师。
- TCP 提供一种面向连接的、可靠的字节流服务
- 在一个 TCP 连接中,仅有两方进行彼此通信。广播和多播不能用于 TCP
- TCP 使用校验和,确认和重传机制来保证可靠传输
- TCP 给数据分节进行排序,并使用累积确认保证数据的顺序不变和非重复
- TCP 使用滑动窗口机制来实现流量控制,通过动态改变窗口的大小进行拥塞控制
| 协议 | 连接性 | 双工性 | 可靠性 | 有序性 | 有界性 | 拥塞控制 | 传输速度 | 量级 | 头部大小 |
|---|---|---|---|---|---|---|---|---|---|
| TCP | 面向连接 (Connection oriented) |
全双工(1:1) | 可靠 (重传机制) |
有序 (通过SYN排序) |
无, 有粘包情况 | 有 | 慢 | 低 | 20~60字节 |
| UDP | 无连接 (Connection less) |
n:m | 不可靠 (丢包后数据丢失) |
无序 | 有消息边界, 无粘包 | 无 | 快 | 高 | 8字节 |
UDP socket 支持 n 对 m 的连接状态, 在官方文档中有写到在 dgram.createSocket(options[, callback]) 中的 option 可以指定 reuseAddr 即 SO_REUSEADDR标志. 通过 SO_REUSEADDR 可以简单的实现 n 对 m 的多播特性 (不过仅在支持多播的系统上才有).
默认情况下, TCP 连接会启用延迟传送算法 (Nagle 算法), 在数据发送之前缓存他们. 如果短时间有多个数据发送, 会缓冲到一起作一次发送 (缓冲大小见 socket.bufferSize), 这样可以减少 IO 消耗提高性能.
如果是传输文件的话, 那么根本不用处理粘包的问题, 来一个包拼一个包就好了. 但是如果是多条消息, 或者是别的用途的数据那么就需要处理粘包.
可以参见网上流传比较广的一个例子, 连续调用两次 send 分别发送两段数据 data1 和 data2, 在接收端有以下几种常见的情况:
- A. 先接收到 data1, 然后接收到 data2 .
- B. 先接收到 data1 的部分数据, 然后接收到 data1 余下的部分以及 data2 的全部.
- C. 先接收到了 data1 的全部数据和 data2 的部分数据, 然后接收到了 data2 的余下的数据.
- D. 一次性接收到了 data1 和 data2 的全部数据.
其中的 BCD 就是我们常见的粘包的情况. 而对于处理粘包的问题, 常见的解决方案有:
- 多次发送之前间隔一个等待时间
- 关闭 Nagle 算法
- 进行封包/拆包
方案1
只需要等上一段时间再进行下一次 send 就好, 适用于交互频率特别低的场景. 缺点也很明显, 对于比较频繁的场景而言传输效率实在太低. 不过几乎不用做什么处理.
方案2
关闭 Nagle 算法, 在 Node.js 中你可以通过 socket.setNoDelay() 方法来关闭 Nagle 算法, 让每一次 send 都不缓冲直接发送.
该方法比较适用于每次发送的数据都比较大 (但不是文件那么大), 并且频率不是特别高的场景. 如果是每次发送的数据量比较小, 并且频率特别高的, 关闭 Nagle 纯属自废武功.
另外, 该方法不适用于网络较差的情况, 因为 Nagle 算法是在服务端进行的包合并情况, 但是如果短时间内客户端的网络情况不好, 或者应用层由于某些原因不能及时将 TCP 的数据 recv, 就会造成多个包在客户端缓冲从而粘包的情况. (如果是在稳定的机房内部通信那么这个概率是比较小可以选择忽略的)
方案3
封包/拆包是目前业内常见的解决方案了. 即给每个数据包在发送之前, 于其前/后放一些有特征的数据, 然后收到数据的时候根据特征数据分割出来各个数据包.
1.TCP协议是面向流的协议,UDP是面向消息的协议
UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据
2.UDP具有保护消息边界,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样对于接收端来说就容易进行区分处理了。传输协议把数据当作一条独立的消息在网上传输,接收端只能接收独立的消息。接收端一次只能接收发送端发出的一个数据包,如果一次接受数据的大小小于发送端一次发送的数据大小,就会丢失一部分数据,即使丢失,接受端也不会分两次去接收
当应用程序调用listen系统调用让一个socket进入LISTEN状态时,需要指定一个参数:backlog。这个参数经常被描述为,新连接队列的长度限制。
tcp-state-diagram.png
由于TCP建立连接需要进行3次握手,一个新连接在到达ESTABLISHED状态可以被accept系统调用返回给应用程序前,必须经过一个中间状态SYN RECEIVED(见上图)。这意味着,TCP/IP协议栈在实现backlog队列时,有两种不同的选择:

- 仅使用一个队列,队列规模由
listen系统调用backlog参数指定。当协议栈收到一个SYN包时,响应SYN/ACK包并且将连接加进该队列。当相应的ACK响应包收到后,连接变为ESTABLISHED状态,可以向应用程序返回。这意味着队列里的连接可以有两种不同的状态:SEND RECEIVED和ESTABLISHED。只有后一种连接才能被accept系统调用返回给应用程序。 - 使用两个队列——
SYN队列(待完成连接队列)和accept队列(已完成连接队列)。状态为SYN RECEIVED的连接进入SYN队列,后续当状态变更为ESTABLISHED时移到accept队列(即收到3次握手中最后一个ACK包)。顾名思义,accept系统调用就只是简单地从accept队列消费新连接。在这种情况下,listen系统调用backlog参数决定accept队列的最大规模。
历史上,起源于BSD的TCP实现使用第一种方法。这个方案意味着,但backlog限制达到,系统将停止对SYN包响应SYN/ACK包。通常,协议栈只是丢弃SYN包(而不是回一个RST包)以便客户端可以重试(而不是异常退出)。TCP/IP详解 卷3第14.5节中有提到这一点。书中作者提到,BSD实现虽然使用了两个独立的队列,但是行为跟使用一个队列并没什么区别。
在Linux上,情况有所不同,情况listen系统调用man文档页:
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog. When syncookies are enabled there is no logical maximum length and this setting is ignored. 意思是,
backlog参数的行为在Linux2.2之后有所改变。现在,它指定了等待accept系统调用的已建立连接队列的长度,而不是待完成连接请求数。待完成连接队列长度由/proc/sys/net/ipv4/tcp_max_syn_backlog指定;在syncookies启用的情况下,逻辑上没有最大值限制,这个设置便被忽略。
也就是说,当前版本的Linux实现了第二种方案,使用两个队列——一个SYN队列,长度系统级别可设置以及一个accept队列长度由应用程序指定。
现在,一个需要考虑的问题是在accept队列已满而一个已完成新连接需要用SYN队列移动到accept队列(收到3次握手中最后一个ACK包),这个实现方案是什么行为。这种情况下,由net/ipv4/tcp_minisocks.c中tcp_check_req函数处理:
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
if (child == NULL)
goto listen_overflow;
对于IPv4,第一行代码实际上调用的是net/ipv4/tcp_ipv4.c中的tcp_v4_syn_recv_sock函数,代码如下:
if (sk_acceptq_is_full(sk))
goto exit_overflow;
可以看到,这里会检查accept队列的长度。如果队列已满,跳到exit_overflow标签执行一些清理工作、更新/proc/net/netstat中的统计项ListenOverflows和ListenDrops,最后返回NULL。这会触发tcp_check_req函数跳到listen_overflow标签执行代码。
listen_overflow:
if (!sysctl_tcp_abort_on_overflow) {
inet_rsk(req)->acked = 1;
return NULL;
}
很显然,除非/proc/sys/net/ipv4/tcp_abort_on_overflow被设置为1(这种情况下发送一个RST包),实现什么都没做。
总结一下:Linux内核协议栈在收到3次握手最后一个ACK包,确认一个新连接已完成,而accept队列已满的情况下,会忽略这个包。一开始您可能会对此感到奇怪——别忘了SYN RECEIVED状态下有一个计时器实现:如果ACK包没有收到(或者是我们讨论的忽略),协议栈会重发SYN/ACK包(重试次数由/proc/sys/net/ipv4/tcp_synack_retries决定)。
看以下抓包结果就非常明显——一个客户正尝试连接一个已经达到其最大backlog的socket:
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 53302 > 9999 [SYN] Seq=0 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 66 53302 > 9999 [ACK] Seq=1 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 71 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.207 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.623 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
1.199 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
1.199 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 6#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
1.455 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.123 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.399 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
3.399 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 10#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
6.459 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
7.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
7.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 13#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
13.131 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
15.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
15.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 16#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
26.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
31.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
31.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 19#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
53.179 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 54 9999 > 53302 [RST] Seq=1 Len=0
由于客户端的TCP实现在收到多个SYN/ACK包时,认为ACK包已经丢失了并且重传它。如果在SYN/ACK重试次数达到限制前,服务端应用从accept队列接收连接,使得backlog减少,那么协议栈会处理这些重传的ACK包,将连接状态从SYN RECEIVED变更到ESTABLISHED并且将其加入accept队列。否则,正如以上包跟踪所示,客户读会收到一个RST包宣告连接失败。
在客户端看来,第一次收到SYN/ACK包之后,连接就会进入ESTABLISHED状态。如果这时客户端首先开始发送数据,那么数据也会被重传。好在TCP有慢启动机制,在服务端还没进入ESTABLISHED之前,客户端能发送的数据非常有限。
相反,如果客户端一开始就在等待服务端,而服务端backlog没能减少,那么最后的结果是连接在客户端看来是ESTABLISHED状态,但在服务端看来是CLOSED状态。这也就是所谓的半开连接。
有一点还没讨论的是:man listen中提到每次收到新SYN包,内核往SYN队列追加一个新连接(除非该队列已满)。事实并非如此,net/ipv4/tcp_ipv4.c中tcp_v4_conn_request函数负责处理SYN包,请看以下代码:
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
可以看到,在accept队列已满的情况下,内核会强制限制SYN包的接收速率。如果有大量SYN包待处理,它们其中的一些会被丢弃。这样看来,就完全依靠客户端重传SYN包了,这种行为跟BSD实现一样。
下结论前,需要再研究以下Linux这种实现方式跟BSD相比有什么优势。Stevens是这样说的:
在
accept队列已满或者SYN队列已满的情况下,backlog会达到限制。第一种情况经常发生在服务器或者服务器进程非常繁忙的情况下,进程没法足够快地调用accept系统调用从中取出已完成连接。后者是HTTP服务器经常面临的问题,在服务端客户端往返时间非常长的时候(相对于连接到达速率),因为新SYN包在往返时间内都会占据一个连接对象。 大多数情况下accept队列都是空的,因为一旦有一个新连接进入队列,阻塞等待的accept系统调用将返回,然后连接从队列中取出。
Stevens建议的解决方案是简单地调大backlog。但有个问题是,应用程序在调优backlog参数时,不仅需要考虑自身对新连接的处理逻辑,还需要考虑网络状况,包括往返时间等。Linux实现实际上分成两部分:应用程序只负责调解backlog参数,确保accept调用足够快以免accept队列被塞满;系统管理员则根据网络状况调节/proc/sys/net/ipv4/tcp_max_syn_backlog,各司其职。
| 端口 | 作用说明 |
|---|---|
| 21 | 21端口主要用于FTP(File Transfer Protocol,文件传输协议)服务。 |
| 23 | 23端口主要用于Telnet(远程登录)服务,是Internet上普遍采用的登录和仿真程序。 |
| 25 | 25端口为SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)服务器所开放,主要用于发送邮件,如今绝大多数邮件服务器都使用该协议。 |
| 53 | 53端口为DNS(Domain Name Server,域名服务器)服务器所开放,主要用于域名解析,DNS服务在NT系统中使用的最为广泛。 |
| 67、68 | 67、68端口分别是为Bootp服务的Bootstrap Protocol Server(引导程序协议服务端)和Bootstrap Protocol Client(引导程序协议客户端)开放的端口。 |
| 69 | TFTP是Cisco公司开发的一个简单文件传输协议,类似于FTP。 |
| 79 | 79端口是为Finger服务开放的,主要用于查询远程主机在线用户、操作系统类型以及是否缓冲区溢出等用户的详细信息。 |
| 80 | 80端口是为HTTP(HyperText Transport Protocol,超文本传输协议)开放的,这是上网冲浪使用最多的协议,主要用于在WWW(World WideWeb,万维网)服务上传输信息的协议。 |
| 99 | 99端口是用于一个名为“Metagram Relay”(亚对策延时)的服务,该服务比较少见,一般是用不到的。 |
| 109、110 | 109端口是为POP2(Post Office Protocol Version 2,邮局协议2)服务开放的,110端口是为POP3(邮件协议3)服务开放的,POP2、POP3都是主要用于接收邮件的。 |
| 111 | 111端口是SUN公司的RPC(Remote ProcedureCall,远程过程调用)服务所开放的端口,主要用于分布式系统中不同计算机的内部进程通信,RPC在多种网络服务中都是很重要的组件。 |
| 113 | 113端口主要用于Windows的“Authentication Service”(验证服务)。 119端口:119端口是为“Network News TransferProtocol”(网络新闻组传输协议,简称NNTP)开放的。 |
| 135 | 135端口主要用于使用RPC(Remote Procedure Call,远程过程调用)协议并提供DCOM(分布式组件对象模型)服务。 |
| 137 | 137端口主要用于“NetBIOS Name Service”(NetBIOS名称服务)。 |
| 139 | 139端口是为“NetBIOS Session Service”提供的,主要用于提供Windows文件和打印机共享以及Unix中的Samba服务。 |
| 143 | 143端口主要是用于“Internet Message Access Protocol”v2(Internet消息访问协议,简称IMAP)。 |
| 161 | 161端口是用于“Simple Network Management Protocol”(简单网络管理协议,简称SNMP)。 |
| 443 | 443端口即网页浏览端口,主要是用于HTTPS服务,是提供加密和通过安全端口传输的另一种HTTP。 |
| 554 | 554端口默认情况下用于“Real Time Streaming Protocol”(实时流协议,简称RTSP)。 |
| 1024 | 1024端口一般不固定分配给某个服务,在英文中的解释是“Reserved”(保留)。 |
| 1080 | 1080端口是Socks代理服务使用的端口,大家平时上网使用的WWW服务使用的是HTTP协议的代理服务。 |
| 1755 | 1755端口默认情况下用于“Microsoft Media Server”(微软媒体服务器,简称MMS)。 |
| 4000 | 4000端口是用于大家经常使用的QQ聊天工具的,再细说就是为QQ客户端开放的端口,QQ服务端使用的端口是8000。 |
| 5554 | 在今年4月30日就报道出现了一种针对微软lsass服务的新蠕虫病毒——震荡波(Worm.Sasser),该病毒可以利用TCP 5554端口开启一个FTP服务,主要被用于病毒的传播。 |
| 5632 | 5632端口是被大家所熟悉的远程控制软件pcAnywhere所开启的端口。 |
| 8080 | 8080端口同80端口,是被用于WWW代理服务的,可以实现网页。 |
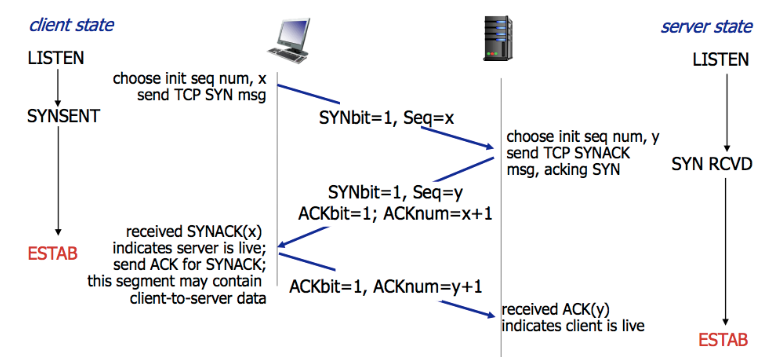
所谓三次握手(Three-way Handshake),是指建立一个 TCP 连接时,需要客户端和服务器总共发送3个包。
三次握手的目的是连接服务器指定端口,建立 TCP 连接,并同步连接双方的序列号和确认号,交换 TCP 窗口大小信息。在 socket 编程中,客户端执行 connect() 时。将触发三次握手。
- 第一次握手(SYN=1, seq=x):
客户端发送一个 TCP 的 SYN 标志位置1的包,指明客户端打算连接的服务器的端口,以及初始序号 X,保存在包头的序列号(Sequence Number)字段里。
发送完毕后,客户端进入SYN_SEND状态。 - 第二次握手(SYN=1, ACK=1, seq=y, ACKnum=x+1):
服务器发回确认包(ACK)应答。即 SYN 标志位和 ACK 标志位均为1。服务器端选择自己 ISN 序列号,放到 Seq 域里,同时将确认序号(Acknowledgement Number)设置为客户的 ISN 加1,即X+1。 发送完毕后,服务器端进入SYN_RCVD状态。 - 第三次握手(ACK=1,ACKnum=y+1)
客户端再次发送确认包(ACK),SYN 标志位为0,ACK 标志位为1,并且把服务器发来 ACK 的序号字段+1,放在确定字段中发送给对方,并且在数据段放写ISN的+1
发送完毕后,客户端进入ESTABLISHED状态,当服务器端接收到这个包时,也进入ESTABLISHED状态,TCP 握手结束。
三次握手的过程的示意图如下:
TCP 的连接的拆除需要发送四个包,因此称为四次挥手(Four-way handshake),也叫做改进的三次握手。客户端或服务器均可主动发起挥手动作,在 socket 编程中,任何一方执行 close() 操作即可产生挥手操作。
- 第一次挥手(FIN=1,seq=x)
假设客户端想要关闭连接,客户端发送一个 FIN 标志位置为1的包,表示自己已经没有数据可以发送了,但是仍然可以接受数据。
发送完毕后,客户端进入FIN_WAIT_1状态。 - 第二次挥手(ACK=1,ACKnum=x+1)
服务器端确认客户端的 FIN 包,发送一个确认包,表明自己接受到了客户端关闭连接的请求,但还没有准备好关闭连接。
发送完毕后,服务器端进入CLOSE_WAIT状态,客户端接收到这个确认包之后,进入FIN_WAIT_2状态,等待服务器端关闭连接。 - 第三次挥手(FIN=1,seq=y)
服务器端准备好关闭连接时,向客户端发送结束连接请求,FIN 置为1。
发送完毕后,服务器端进入LAST_ACK状态,等待来自客户端的最后一个ACK。 - 第四次挥手(ACK=1,ACKnum=y+1)
客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入TIME_WAIT状态,等待可能出现的要求重传的 ACK 包。
服务器端接收到这个确认包之后,关闭连接,进入CLOSED状态。
客户端等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入CLOSED状态。
四次挥手的示意图如下:

参考:
想要实时关注笔者最新的文章和最新的文档更新请关注公众号程序员面试官,后续的文章会优先在公众号更新.
简历模板: 关注公众号回复「模板」获取
《前端面试手册》: 配套于本指南的突击手册,关注公众号回复「fed」获取
