Using MongoDB Atlas' Vector Search engine, we store dense vectors and calculate similarities all within the data storage layer.
See the short video below:

Jupyter Notebook Demonstration
pip install sentence_transformers, pymongoWe'll be using a popular pre-trained sentence transformer model. You can alternatively train your own or re-train an existing one.
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
import pymongo
connection = pymongo.MongoClient(mongo_uri)
vector_collection = connection['eap']['vector']Convert each object's name into its' corresponding vector embedding, then store it in the vector database.
products = [
{"name": "Mozzarella"},
{"name": "Parmesan"},
{"name": "Cheddar"},
{"name": "Brie"},
{"name": "Swiss"},
{"name": "Gruyere"},
{"name": "Feta"},
{"name": "Gouda"},
{"name": "Provolone"},
{"name": "Monterey Jack"}
]
# create a new embedding field for each product object
for product in products:
# convert to embedding, then to array
embeddings = model.encode(product['name']).tolist()
product['embedding'] = embeddings
vector_collection.insert(product)We use the default HNSW KNN index structure when we create our field mapping definition:
{
"mappings": {
"fields": {
"embedding": [
{
"dimensions": 384,
"similarity": "euclidean",
"type": "knnVector"
}
]
}
}
}The heart of vector search is in the similarity calculation. Here we use cosine similarity but you can experiment with others.
query = "cheese"
vector_query = model.encode(query).tolist()
pipeline = [
{
"$search": {
"knnBeta": {
"vector": vector_query,
"path": "embedding",
"k": 10
}
}
},
{
"$project": {
"embedding": 0,
"_id": 0,
'score': {
'$meta': 'searchScore'
}
}
}
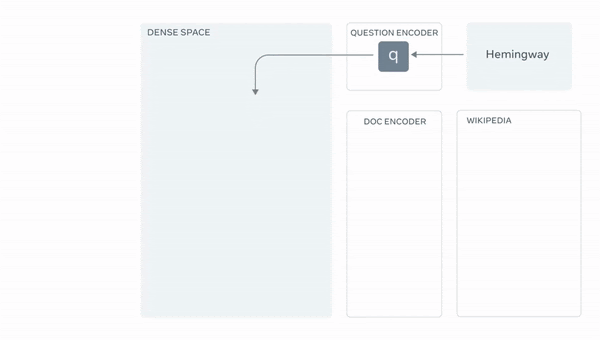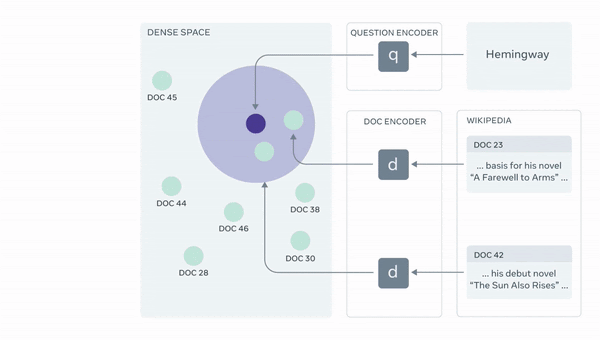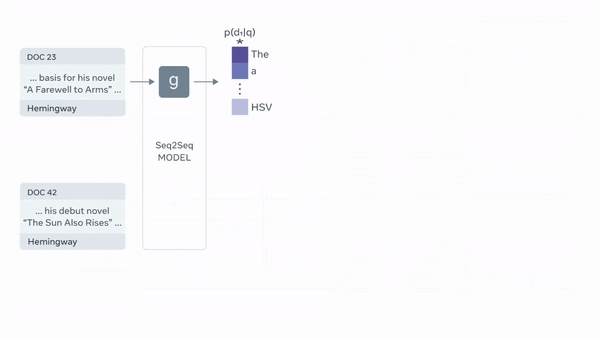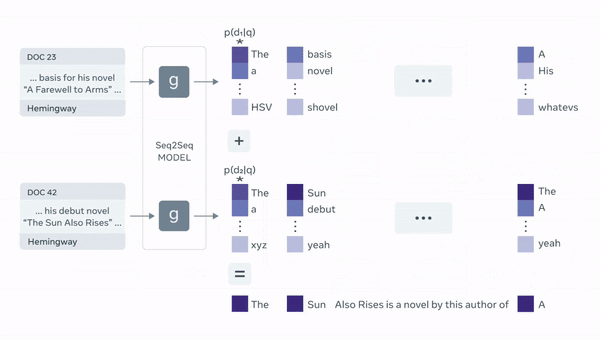
]Retrieval augmentation is a technique for improving QA bots by augmenting the prompt with relevant documents retrieved from a knowledge base. This helps the bots to access information outside of their training set and improve interpretability. However, it can be challenging to retrieve relevant documents and for the bots to understand them.
{kind=link}
{kind=link}
- Accept corpus
- Split into chunks
- Embed the chunks
- Ask a question (Q)
- Return top K chunks
- Run chunks through GPT
- Return results in a structured form
- Embedding
- ANN Search
- Filter
- Re-Ranking
- Model versioning, hosting, and scaling
- Implement any number of the vector search use cases