forked from abdelhadie-almalla/image_captioning
-
Notifications
You must be signed in to change notification settings - Fork 0
/
image_captioning_version_16.1--feature_concatination--boundingboxes.py
765 lines (589 loc) · 34.1 KB
/
image_captioning_version_16.1--feature_concatination--boundingboxes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
# -*- coding: utf-8 -*-
"""image_captioning.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1xGL2xIqUU_SWiehNi6-xREkHlD4absHy
##### Copyright 2018 The TensorFlow Authors.
"""
# @title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""# Image captioning with visual attention
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/tutorials/text/image_captioning">
<img src="https://www.tensorflow.org/images/tf_logo_32px.png" />
View on TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/text/image_captioning.ipynb">
<img src="https://www.tensorflow.org/images/colab_logo_32px.png" />
Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/docs/blob/master/site/en/tutorials/text/image_captioning.ipynb">
<img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />
View source on GitHub</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/docs/site/en/tutorials/text/image_captioning.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png" />Download notebook</a>
</td>
</table>
Given an image like the example below, our goal is to generate a caption such as "a surfer riding on a wave".

*[Image Source](https://commons.wikimedia.org/wiki/Surfing#/media/File:Surfing_in_Hawaii.jpg); License: Public Domain*
To accomplish this, you'll use an attention-based model, which enables us to see what parts of the image the model focuses on as it generates a caption.
The model architecture is similar to [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://arxiv.org/abs/1502.03044).
This notebook is an end-to-end example. When you run the notebook, it downloads the [MS-COCO](http://cocodataset.org/#home) dataset, preprocesses and caches a subset of images using Inception V3, trains an encoder-decoder model, and generates captions on new images using the trained model.
In this example, you will train a model on a relatively small amount of data—the first 30,000 captions for about 20,000 images (because there are multiple captions per image in the dataset).
"""
import tensorflow as tf
tf.get_logger().setLevel('ERROR') # hadie
# You'll generate plots of attention in order to see which parts of an image
# our model focuses on during captioning
import matplotlib.pyplot as plt
# Scikit-learn includes many helpful utilities
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
import re
import numpy as np
import os
import time
import json
from glob import glob
from PIL import Image
import pickle
from tqdm import tqdm # hadie
from termcolor import colored # hadie
from builtins import len # hadie
import datetime # hadie
from model import DATASET, EXAMPLE_NUMBER, LIMIT_SIZE , WORD_DICT_SIZE, TEST_SET_PROPORTION, MY_EMBEDDING_DIM, UNIT_COUNT, CNN_Encoder, RNN_Decoder, MY_OPTIMIZER, MY_LOSS_OBJECT, REMOVE_CHECKPOINTS_AND_MODEL_AND_RETRAIN, EPOCH_COUNT, feature_extraction_model, split # hadie
from timeit import default_timer as timer # hadie
import threading # hadie
# change the current working directory to the parent directory of this code file # hadie
os.chdir(os.path.dirname(os.path.abspath(__file__))) # hadie
from yolo import image_path_to_yolo_bounding_boxes # hadie
start_date = datetime.datetime.now() # hadie
my_start = timer() # hadie
"""## Download and prepare the MS-COCO dataset
You will use the [MS-COCO dataset](http://cocodataset.org/#home) to train our model. The dataset contains over 82,000 images, each of which has at least 5 different caption annotations. The code below downloads and extracts the dataset automatically.
**Caution: large download ahead**. You'll use the training set, which is a 13GB file.
"""
if not os.path.exists("trained_model_" + feature_extraction_model): # create the dicrectory if it does not exists # hadie
os.makedirs("trained_model_" + feature_extraction_model) # hadie
if DATASET == "mscoco": # hadie
# Download caption annotation files
annotation_folder = '/annotations/'
if not os.path.exists(os.path.abspath('.') + annotation_folder):
annotation_zip = tf.keras.utils.get_file('captions.zip',
cache_subdir=os.path.abspath('.'),
origin='http://localhost:8080/annotations_trainval2014.zip', # hadie
extract=True)
if split == 0:
annotation_file = os.path.dirname(annotation_zip) + '/annotations/captions_train2014.json'
else:
annotation_file = os.path.dirname(annotation_zip) + '/annotations/captions_val2014.json'
os.remove(annotation_zip)
else:
if split == 0:
annotation_file = 'annotations/captions_train2014.json'
else:
annotation_file = 'annotations/captions_val2014.json'
# Download image files
image_folder = '/train2014/'
if not os.path.exists(os.path.abspath('.') + image_folder):
image_zip = tf.keras.utils.get_file('train2014.zip',
cache_subdir=os.path.abspath('.'),
origin='http://localhost:8080/train2014.zip', # hadie
extract=True)
PATH = os.path.dirname(image_zip) + image_folder
os.remove(image_zip)
else:
PATH = os.path.abspath('.') + image_folder
elif DATASET == "flickr8k": # hadie
# Download caption annotation files
annotation_folder = '/annotations_flickr8k/'
if not os.path.exists(os.path.abspath('.') + annotation_folder):
annotation_zip = tf.keras.utils.get_file('captions.zip',
cache_subdir=os.path.abspath('.'),
origin='http://localhost:8080/annotations_flickr8k.zip', # hadie
extract=True)
if split == 0:
annotation_file = os.path.dirname(annotation_zip) + '/annotations_flickr8k/flickr8k_trainval_in_mscoco_format.json'
else:
annotation_file = os.path.dirname(annotation_zip) + '/annotations_flickr8k/flickr8k_testing_in_mscoco_format.json'
os.remove(annotation_zip)
else:
if split == 0:
annotation_file = 'annotations_flickr8k/flickr8k_trainval_in_mscoco_format.json'
else:
annotation_file = 'annotations_flickr8k/flickr8k_testing_in_mscoco_format.json'
# Download image files
image_folder = '/flickr8k/'
if not os.path.exists(os.path.abspath('.') + image_folder):
image_zip = tf.keras.utils.get_file('flickr8k.zip',
cache_subdir=os.path.abspath('.'),
origin='http://localhost:8080/flickr8k.zip', # hadie
extract=True)
PATH = os.path.dirname(image_zip) + image_folder
os.remove(image_zip)
else:
PATH = os.path.abspath('.') + image_folder
elif DATASET == "flickr30k": # hadie
# Download caption annotation files
annotation_folder = '/annotations_flickr30k/'
if not os.path.exists(os.path.abspath('.') + annotation_folder):
annotation_zip = tf.keras.utils.get_file('captions.zip',
cache_subdir=os.path.abspath('.'),
origin='http://localhost:8080/annotations_flickr30k.zip', # hadie
extract=True)
if split == 0:
annotation_file = os.path.dirname(annotation_zip) + '/annotations_flickr30k/flickr30k_trainval_in_mscoco_format.json'
else:
annotation_file = os.path.dirname(annotation_zip) + '/annotations_flickr30k/flickr30k_testing_in_mscoco_format.json'
os.remove(annotation_zip)
else:
if split == 0:
annotation_file = 'annotations_flickr30k/flickr30k_trainval_in_mscoco_format.json'
else:
annotation_file = 'annotations_flickr30k/flickr30k_testing_in_mscoco_format.json'
# Download image files
image_folder = '/flickr30k/'
if not os.path.exists(os.path.abspath('.') + image_folder):
image_zip = tf.keras.utils.get_file('flickr30k.zip',
cache_subdir=os.path.abspath('.'),
origin='http://localhost:8080/flickr30k.zip', # hadie
extract=True)
PATH = os.path.dirname(image_zip) + image_folder
os.remove(image_zip)
else:
PATH = os.path.abspath('.') + image_folder
else: # hadie
print("Unknow dataset: " + DATASET) # hadie
exit() # hadie
"""## Optional: limit the size of the training set
To speed up training for this tutorial, you'll use a subset of 30,000 captions and their corresponding images to train our model. Choosing to use more data would result in improved captioning quality.
"""
# Read the json file
with open(annotation_file, 'r') as f:
annotations = json.load(f)
# Store captions and image names in vectors
all_captions = []
all_img_name_vector = []
all_ids = [] # hadie
# create an image index # hadie
image_id_index = {} # hadie
for img in annotations['images']: # hadie
image_id_index[img['id']] = img['file_name'] # hadie
for annot in annotations['annotations']:
caption = '<start> ' + annot['caption'] + ' <end>'
image_id = annot['image_id']
if DATASET == "mscoco": # hadie
full_coco_image_path = PATH + image_id_index[image_id]
# print(full_coco_image_path, image_id)
else: # hadie
full_coco_image_path = PATH + image_id + ".jpg" # hadie
all_ids.append(image_id) # hadie
all_img_name_vector.append(full_coco_image_path)
all_captions.append(caption)
# Shuffle captions and image_names together
# Set a random state
train_ids, train_captions, img_name_vector = shuffle(all_ids, # hadie
all_captions,
all_img_name_vector,
random_state=1)
# Select the first 30000 captions from the shuffled set
num_examples = EXAMPLE_NUMBER # hadie
if LIMIT_SIZE: # hadie
train_ids = train_ids[:num_examples]
train_captions = train_captions[:num_examples]
img_name_vector = img_name_vector[:num_examples]
print("training captions: ", len(train_captions), ", all captions: ", len(all_captions)) # hadie
"""## Preprocess the images using InceptionV3
Next, you will use InceptionV3 (which is pretrained on Imagenet) to classify each image. You will extract features from the last convolutional layer.
First, you will convert the images into InceptionV3's expected format by:
* Resizing the image to 299px by 299px
* [Preprocess the images](https://cloud.google.com/tpu/docs/inception-v3-advanced#preprocessing_stage) using the [preprocess_input](https://www.tensorflow.org/api_docs/python/tf/keras/applications/inception_v3/preprocess_input) method to normalize the image so that it contains pixels in the range of -1 to 1, which matches the format of the images used to train InceptionV3.
"""
# the load_image function has been moved to a separate file by hadie
import importlib # hadie
mod = importlib.import_module("feature_extraction_model_" + feature_extraction_model) # hadie
image_model = mod.image_model # hadie
load_image = mod.load_image # hadie
attention_features_shape = mod.attention_features_shape + 1 # hadie
"""## Initialize InceptionV3 and load the pretrained Imagenet weights
Now you'll create a tf.keras model where the output layer is the last convolutional layer in the InceptionV3 architecture. The shape of the output of this layer is ```8x8x2048```. You use the last convolutional layer because you are using attention in this example. You don't perform this initialization during training because it could become a bottleneck.
* You forward each image through the network and store the resulting vector in a dictionary (image_name --> feature_vector).
* After all the images are passed through the network, you pickle the dictionary and save it to disk.
"""
# the image_model variable has been moved to a separate file by hadie
new_input = image_model.input
hidden_layer = image_model.layers[-1].output
image_features_extract_model = tf.keras.Model(new_input, hidden_layer)
"""## Caching the features extracted from InceptionV3
You will pre-process each image with InceptionV3 and cache the output to disk. Caching the output in RAM would be faster but also memory intensive, requiring 8 \* 8 \* 2048 floats per image. At the time of writing, this exceeds the memory limitations of Colab (currently 12GB of memory).
Performance could be improved with a more sophisticated caching strategy (for example, by sharding the images to reduce random access disk I/O), but that would require more code.
The caching will take about 10 minutes to run in Colab with a GPU. If you'd like to see a progress bar, you can:
1. install [tqdm](https://github.com/tqdm/tqdm):
`!pip install tqdm`
2. Import tqdm:
`from tqdm import tqdm`
3. Change the following line:
`for img, path in image_dataset:`
to:
`for img, path in tqdm(image_dataset):`
"""
print("-----------------------------START OF EXECUTION-----------------------------") # hadie
# Get unique images
encode_train = sorted(set(img_name_vector))
# only get unprocessed images # hadie
encode_train = [x for x in encode_train if not os.path.exists(x + "_" + feature_extraction_model + ".npy")] # hadie
features_shape = 2048
print("extracting features (" + str(len(encode_train)) + ") file(s)") # hadie
if len(encode_train) > 0: # hadie
# Feel free to change batch_size according to your system configuration
image_dataset = tf.data.Dataset.from_tensor_slices(encode_train)
image_dataset = image_dataset.map(load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE).batch(16)
for img, path in tqdm(image_dataset): # hadie
batch_features = image_features_extract_model(img)
batch_features = tf.reshape(batch_features,
(batch_features.shape[0], -1, batch_features.shape[3]))
for bf, p in zip(batch_features, path):
path_of_feature = p.numpy().decode("utf-8")
yolo_features = image_path_to_yolo_bounding_boxes(path_of_feature) # hadie
yolo_features = np.array(yolo_features.flatten()) # hadie
yolo_features = np.pad(yolo_features, (0, features_shape - yolo_features.shape[0]), 'constant', constant_values=(0, 0)).astype(np.float32) # hadie
combined_features = np.vstack((bf.numpy(), yolo_features)).astype(np.float32) # hadie
np.save(path_of_feature + "_" + feature_extraction_model, combined_features) # hadie
print("finished extracting features") # hadie
"""## Preprocess and tokenize the captions
* First, you'll tokenize the captions (for example, by splitting on spaces). This gives us a vocabulary of all of the unique words in the data (for example, "surfing", "football", and so on).
* Next, you'll limit the vocabulary size to the top 5,000 words (to save memory). You'll replace all other words with the token "UNK" (unknown).
* You then create word-to-index and index-to-word mappings.
* Finally, you pad all sequences to be the same length as the longest one.
"""
# Find the maximum length of any caption in our dataset
def calc_max_length(tensor):
return max(len(t) for t in tensor)
# Choose the top 5000 words from the vocabulary
top_k = WORD_DICT_SIZE # hadie
if not REMOVE_CHECKPOINTS_AND_MODEL_AND_RETRAIN: # hadie
print("using the cashed tokenizer") # hadie
# loading the tokenizer # hadie
with open("trained_model_" + feature_extraction_model + "/tokenizer.pickle", 'rb') as handle: # hadie
tokenizer = pickle.load(handle) # hadie
else: # hadie
print("tokenizing and padding captions") # hadie
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=top_k,
oov_token="<unk>",
filters='!"#$%&()*+.,-/:;=?@[\]^_`{|}~ ')
tokenizer.fit_on_texts(train_captions)
train_seqs = tokenizer.texts_to_sequences(train_captions) # 777 maybe this line needs removal
tokenizer.word_index['<pad>'] = 0
tokenizer.index_word[0] = '<pad>'
# saving the tokenizer to disk # hadie
with open("trained_model_" + feature_extraction_model + "/tokenizer.pickle", 'wb') as handle: # hadie
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL) # hadie
# Create the tokenized vectors
train_seqs = tokenizer.texts_to_sequences(train_captions)
# Pad each vector to the max_length of the captions
# If you do not provide a max_length value, pad_sequences calculates it automatically
cap_vector = tf.keras.preprocessing.sequence.pad_sequences(train_seqs, padding='post')
if not REMOVE_CHECKPOINTS_AND_MODEL_AND_RETRAIN: # hadie
file = "trained_model_" + feature_extraction_model + "/max_length.txt" # hadie
with open(file, 'r') as filetoread: # hadie
max_length = int(filetoread.readline()) # hadie
else: # hadie
# Calculates the max_length, which is used to store the attention weights
max_length = calc_max_length(train_seqs)
file = "trained_model_" + feature_extraction_model + "/max_length.txt" # hadie
with open(file, 'w') as filetowrite: # hadie
filetowrite.write(str(max_length)) # write the maximum length to disk # hadie
print("finished tokenizing and padding captions") # hadie
"""## Split the data into training and testing"""
# Create training and validation sets using an 80-20 split
if TEST_SET_PROPORTION == 0:
image_id_train = train_ids
image_id_val = []
img_name_train = img_name_vector
img_name_val = []
cap_train = cap_vector
cap_val = []
elif TEST_SET_PROPORTION == 1:
image_id_train = []
image_id_val = train_ids
img_name_train = []
img_name_val = img_name_vector
cap_train = []
cap_val = cap_vector
else:
image_id_train, image_id_val, img_name_train, img_name_val, cap_train, cap_val = train_test_split(
train_ids, # hadie
img_name_vector,
cap_vector,
test_size=TEST_SET_PROPORTION, # hadie
random_state=0)
print("len(img_name_train) = ", len(img_name_train), ", len(cap_train) = ", len(cap_train), ", len(img_name_val) = ", len(img_name_val), ", len(cap_val) = ", len(cap_val)) # hadie
"""## Create a tf.data dataset for training
Our images and captions are ready! Next, let's create a tf.data dataset to use for training our model.
"""
# Feel free to change these parameters according to your system's configuration
BATCH_SIZE = 64 # 64
BUFFER_SIZE = 10000 # 1000
embedding_dim = MY_EMBEDDING_DIM # hadie
units = UNIT_COUNT # hadie
vocab_size = top_k + 1
num_steps = len(img_name_train) // BATCH_SIZE
# Shape of the vector extracted from InceptionV3 is (64, 2048)
# These two variables represent that vector shape
# the definition of features_shape = 2048 was moved up
# the attention_features variable has been moved to a separate file by hadie
# Load the numpy files
def map_func(img_name, cap):
img_tensor = np.load(img_name.decode('utf-8') + "_" + feature_extraction_model + '.npy')
return img_tensor, cap
dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train))
# Use map to load the numpy files in parallel
dataset = dataset.map(lambda item1, item2: tf.numpy_function(
map_func, [item1, item2], [tf.float32, tf.int32]),
num_parallel_calls=tf.data.experimental.AUTOTUNE)
# Shuffle and batch
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
"""## Model
Fun fact: the decoder below is identical to the one in the example for [Neural Machine Translation with Attention](../sequences/nmt_with_attention.ipynb).
The model architecture is inspired by the [Show, Attend and Tell](https://arxiv.org/pdf/1502.03044.pdf) paper.
* In this example, you extract the features from the lower convolutional layer of InceptionV3 giving us a vector of shape (8, 8, 2048).
* You squash that to a shape of (64, 2048).
* This vector is then passed through the CNN Encoder (which consists of a single Fully connected layer).
* The RNN (here GRU) attends over the image to predict the next word.
"""
# the model has been moved to model.py by hadie
encoder = CNN_Encoder(embedding_dim)
decoder = RNN_Decoder(embedding_dim, units, vocab_size)
optimizer = MY_OPTIMIZER # hadie
loss_object = MY_LOSS_OBJECT # hadie
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
"""## Checkpoint"""
checkpoint_path = "./checkpoints/train"
# hadie
if REMOVE_CHECKPOINTS_AND_MODEL_AND_RETRAIN:
try:
for filename in os.listdir(checkpoint_path):
print("deleting " + checkpoint_path + "/" + filename)
os.unlink(checkpoint_path + "/" + filename)
except Exception as e:
print('Failed to delete %s. Reason: %s' % (checkpoint_path + "/" + filename, e))
# remove the saved model too
if os.path.exists("./trained_model_" + feature_extraction_model + "/my_model.index"):
print("deleting trained_model_" + feature_extraction_model + "/my_model.index")
os.unlink("./trained_model_" + feature_extraction_model + "/my_model.index")
if os.path.exists("./trained_model_" + feature_extraction_model + "/checkpoint"):
print("deleting /trained_model_" + feature_extraction_model + "/checkpoint")
os.unlink("./trained_model_" + feature_extraction_model + "/checkpoint")
if os.path.exists("./trained_model_" + feature_extraction_model + "/my_model.data-00000-of-00001"):
print("deleting trained_model_" + feature_extraction_model + "/my_model.data-00000-of-00001")
os.unlink("./trained_model_" + feature_extraction_model + "/my_model.data-00000-of-00001")
if os.path.exists("./trained_model_" + feature_extraction_model + "/learning_curve.png"):
print("deleting trained_model_" + feature_extraction_model + "/learning_curve.png")
os.unlink("./trained_model_" + feature_extraction_model + "/learning_curve.png")
ckpt = tf.train.Checkpoint(encoder=encoder,
decoder=decoder,
optimizer=optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
start_epoch = 0
if ckpt_manager.latest_checkpoint:
start_epoch = int(ckpt_manager.latest_checkpoint.split('-')[-1])
# restoring the latest checkpoint in checkpoint_path
ckpt.restore(ckpt_manager.latest_checkpoint)
"""## Training
* You extract the features stored in the respective `.npy` files and then pass those features through the encoder.
* The encoder output, hidden state(initialized to 0) and the decoder input (which is the start token) is passed to the decoder.
* The decoder returns the predictions and the decoder hidden state.
* The decoder hidden state is then passed back into the model and the predictions are used to calculate the loss.
* Use teacher forcing to decide the next input to the decoder.
* Teacher forcing is the technique where the target word is passed as the next input to the decoder.
* The final step is to calculate the gradients and apply it to the optimizer and backpropagate.
"""
# adding this in a separate cell because if you run the training cell
# many times, the loss_plot array will be reset
loss_plot = []
@tf.function
def train_step(img_tensor, target):
loss = 0
# initializing the hidden state for each batch
# because the captions are not related from image to image
hidden = decoder.reset_state(batch_size=target.shape[0])
dec_input = tf.expand_dims([tokenizer.word_index['<start>']] * target.shape[0], 1)
with tf.GradientTape() as tape:
features = encoder(img_tensor)
for i in range(1, target.shape[1]):
# passing the features through the decoder
predictions, hidden, _ = decoder(dec_input, features, hidden)
loss += loss_function(target[:, i], predictions)
# using teacher forcing
dec_input = tf.expand_dims(target[:, i], 1)
total_loss = (loss / int(target.shape[1]))
trainable_variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(gradients, trainable_variables))
return loss, total_loss
EPOCHS = EPOCH_COUNT # hadie
if not os.path.exists("trained_model_" + feature_extraction_model + "/my_model.index"): # hadie
print("training..") # hadie
for epoch in range(start_epoch, EPOCHS):
start = time.time()
total_loss = 0
for (batch, (img_tensor, target)) in enumerate(dataset):
batch_loss, t_loss = train_step(img_tensor, target)
total_loss += t_loss
if batch % 100 == 0:
print ('Epoch {} Batch {} Loss {:.4f}'.format(
epoch + 1, batch, batch_loss.numpy() / int(target.shape[1])))
# storing the epoch end loss value to plot later
loss_plot.append(total_loss / num_steps)
if epoch % 5 == 0:
ckpt_manager.save()
print ('Epoch {} Loss {:.6f}'.format(epoch + 1,
total_loss / num_steps))
print ('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
# save model to disk # hadie
decoder.save_weights("trained_model_" + feature_extraction_model + "/my_model" , save_format="tf") # hadie
else: # hadie
print("A trained model has been found. Loading it from disk..") # hadie
# Load the previously saved weights # hadie
decoder.load_weights("trained_model_" + feature_extraction_model + "/my_model") # hadie
# showing the learning curve is moved from here by hadie
"""## Caption!
* The evaluate function is similar to the training loop, except you don't use teacher forcing here. The input to the decoder at each time step is its previous predictions along with the hidden state and the encoder output.
* Stop predicting when the model predicts the end token.
* And store the attention weights for every time step.
"""
def evaluate(image):
attention_plot = np.zeros((max_length, attention_features_shape))
hidden = decoder.reset_state(batch_size=1)
temp_input = tf.expand_dims(load_image(image)[0], 0)
img_tensor_val = image_features_extract_model(temp_input)
img_tensor_val = tf.reshape(img_tensor_val, (img_tensor_val.shape[0], -1, img_tensor_val.shape[3]))
yolo_features = image_path_to_yolo_bounding_boxes(image.decode("utf-8")) # hadie
yolo_features = np.array(yolo_features.flatten()) # hadie
yolo_features = np.pad(yolo_features, (0, features_shape - yolo_features.shape[0]), 'constant', constant_values=(0, 0)).astype(np.float32) # hadie
combined_features = np.vstack((img_tensor_val[0].numpy(), yolo_features)).astype(np.float32) # hadie
features = encoder(combined_features) # hadie
dec_input = tf.expand_dims([tokenizer.word_index['<start>']], 0)
result = []
for i in range(max_length):
predictions, hidden, attention_weights = decoder(dec_input, features, hidden)
attention_plot[i] = tf.reshape(attention_weights, (-1,)).numpy()
predicted_id = tf.random.categorical(predictions, 1)[0][0].numpy()
result.append(tokenizer.index_word[predicted_id])
if tokenizer.index_word[predicted_id] == '<end>':
return result, attention_plot
dec_input = tf.expand_dims([predicted_id], 0)
attention_plot = attention_plot[:len(result),:]
return result, attention_plot
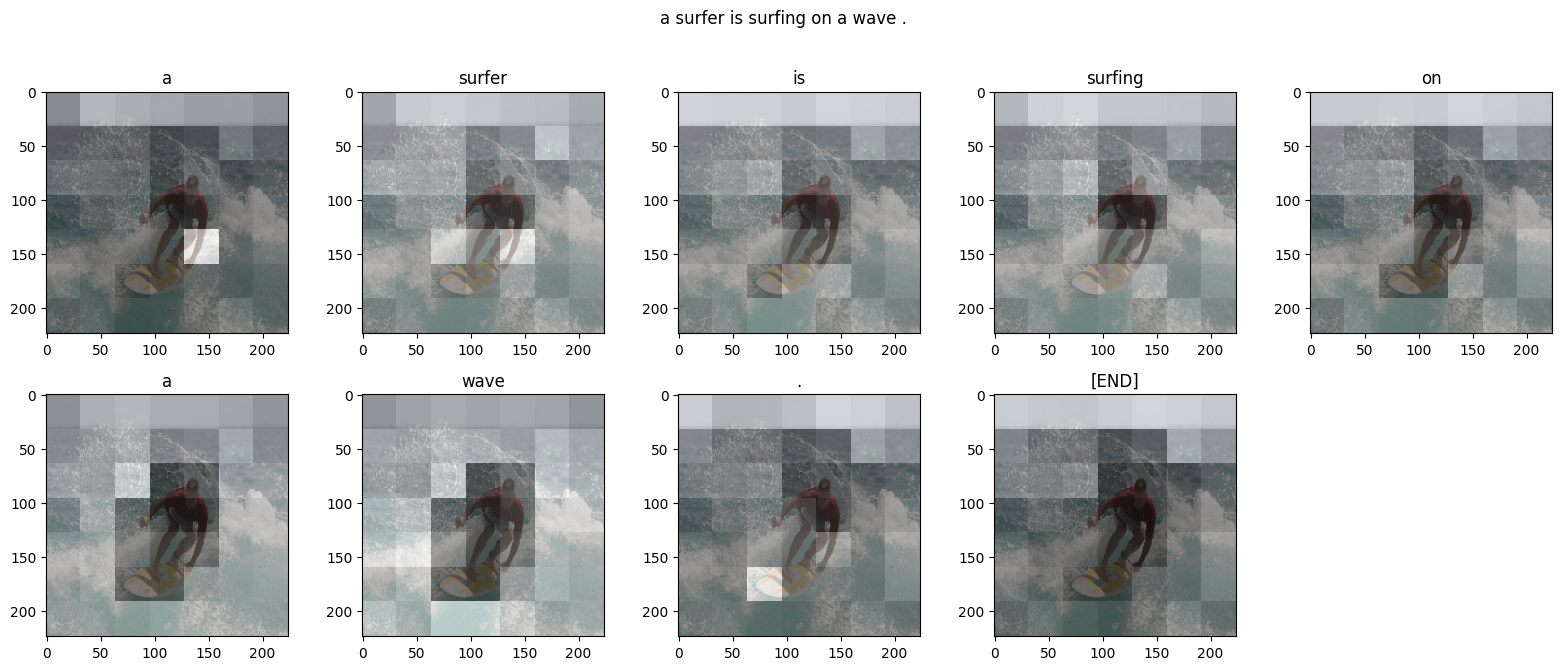
def plot_attention(image, result, attention_plot):
temp_image = np.array(Image.open(image))
fig = plt.figure(figsize=(10, 10))
len_result = len(result)
for l in range(len_result):
temp_att = np.resize(attention_plot[l], (8, 8))
ax = fig.add_subplot(len_result // 2, len_result // 2, l + 1)
ax.set_title(result[l])
img = ax.imshow(temp_image)
ax.imshow(temp_att, cmap='gray', alpha=0.6, extent=img.get_extent())
plt.tight_layout()
plt.show()
# captions on the validation set
# rid = np.random.randint(0, len(img_name_val))
# image = img_name_val[rid]
# real_caption = ' '.join([tokenizer.index_word[i] for i in cap_val[rid] if i not in [0]])
# result, attention_plot = evaluate(image)
#
# print ('Real Caption:', real_caption)
# print ('Prediction Caption:', ' '.join(result))
# plot_attention(image, result, attention_plot)
# image = "C:/Users/Hadie/Downloads/download.jpg" # hadie
# result, attention_plot = evaluate(image) # hadie
# print ('Prediction Caption:`', ' '.join(result)) # hadie
# plot_attention(image, result, attention_plot) # hadie
"""## Try it on your own images
For fun, below we've provided a method you can use to caption your own images with the model we've just trained. Keep in mind, it was trained on a relatively small amount of data, and your images may be different from the training data (so be prepared for weird results!)
"""
# image_url = 'https://tensorflow.org/images/surf.jpg'
# image_extension = image_url[-4:]
# image_path = tf.keras.utils.get_file('image' + image_extension,
# origin=image_url)
# in the future, prediction of a single image will be moved to a separate file
# result, attention_plot = evaluate(image_path) # hadie
# print ('Prediction Caption:', ' '.join(result)) # hadie
# plot_attention(image_path, result, attention_plot) # hadie
# opening the image # hadie
# Image.open(image_path) # hadie
# validation, this whole section was written by hadie # hadie
def validate_image(id, image_name_for_validation, original_caption):
print("Evaluating:", image_name_for_validation.decode("utf-8"), "From thread", threading.current_thread().ident)
result, attention_plot = evaluate(image_name_for_validation) # generate the hypothesis
result = ' '.join(result).replace("<end>", "").strip() # remove unnecessary characters
dict = {}
dict["image_id"] = int(id) # .decode("utf-8")
dict["caption"] = result;
dict["original_caption"] = original_caption.decode("utf-8")
dict["file_name"] = image_name_for_validation.decode("utf-8")
return json.dumps(dict)
caption_strings_val = list(map(lambda item: (' '.join([tokenizer.index_word[i] for i in item if i not in [0]])).replace("<end>", "").replace("<start>", "").strip(), cap_val)) # convert to a list of strings
validation_dataset = tf.data.Dataset.from_tensor_slices((image_id_val, img_name_val, caption_strings_val)) # create the dataset
eval_start_date = datetime.datetime.now() # hadie
list_of_dicts = validation_dataset.map(lambda item1, item2, item3: tf.numpy_function(validate_image, [item1, item2, item3], [tf.string]), num_parallel_calls=1) # run in parallel
list_of_dicts = list(list_of_dicts.as_numpy_iterator()) # convert to a list
list_of_dicts = [item for sublist in list_of_dicts for item in sublist] # flatten the list by removing nested tuples
list_of_dicts = list(map(lambda item: json.loads(item), list_of_dicts)) # rewrap the strings as dictionaries, then convert to a list
# eliminate duplicate id entries because the evaluation code does not allow them
added_ids = []
unique_list_of_dicts = []
for dict in list_of_dicts:
if not dict["image_id"] in added_ids:
added_ids.append(dict["image_id"])
unique_list_of_dicts.append(dict)
file = "trained_model_" + feature_extraction_model + "/results.json" # hadie
with open(file, 'w') as filetowrite: # hadie
filetowrite.write(json.dumps(unique_list_of_dicts)) # hadie
print("The results have been written to trained_model_" + feature_extraction_model + "/results.json") # hadie
print("Main thread:", threading.current_thread().ident) # hadie
end_date = datetime.datetime.now() # hadie
my_end = timer() # hadie
hours, rem = divmod(my_end - my_start, 3600) # hadie
minutes, seconds = divmod(rem, 60) # hadie
print("Start time: " + str(start_date)) # hadie
print("Evaluation start time: " + str(eval_start_date)) # hadie
print("End time: " + str(end_date)) # hadie
print("Time elapsed (hours:minutes:seconds): {:0>2}:{:0>2}:{:05.2f}".format(int(hours), int(minutes), seconds)) # hadie
if REMOVE_CHECKPOINTS_AND_MODEL_AND_RETRAIN: # hadie
plt.plot(loss_plot)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Loss Plot')
plt.savefig("trained_model_" + feature_extraction_model + "/learning_curve.png") # hadie
# plt.show() # hadie
print("The learning curve has been written to trained_model_" + feature_extraction_model + "/learning_curve.png") # hadie
print("Feature extraction model: " + feature_extraction_model)
print("Dataset: " + DATASET)
print("Development set proportion: " + str(TEST_SET_PROPORTION))
print("with yolo bounding boxes")
"""# Next steps
Congrats! You've just trained an image captioning model with attention. Next, take a look at this example [Neural Machine Translation with Attention](../sequences/nmt_with_attention.ipynb). It uses a similar architecture to translate between Spanish and English sentences. You can also experiment with training the code in this notebook on a different dataset.
"""