优点:
缺点:(实际上也是由HDFS设计的特性所决定的)
java接口
- 从Hadoop URL读取数据
- java自带的URL可以读取url的信息,new URL("hdfs://host/path"").openStream()
- 默认读取不到hdfs,需要通过 URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()) 参见URLCat.java
- 每个JVM只能执行一次 setURLStreamHandlerFactory()
- 通过FileSystem API读取数据
- 直接使用InputStream
- 使用FSDataInputStream
- 写入数据
- FSDataOutputStream
- 目录
- mkdirs(Path p)
- 查询文件系统
- 文件元数据: FileStatus,封装了文件长度、块大小、副本、修改时间、所有者、权限等信息
- 列出文件: listStatus()
- FileStatus[] listStatus(Path p)
- FileStatus[] listStatus(Path p, PathFilter filter)
- FileStatus[] listStatus(Path[] ps, PathFilter filter)
- Hadoop的FileUtil中stat2Paths()可以把FileStatus[]转为Path[]
- 文件模式:可以使用通配符来寻找需要执行的文件
- FileStatus[] globStatus(Path pathPattern)
- FileStatus[] globStatus(Path pathPattern, PathFilter filter)
- 支持的通配符跟Unix系统一直
- PathFilter对象: 以编程的方式控制通配符
- 实现PathFilter接口的accept() 方法
- 删除数据: delete(Path f, boolean recursive) recursive=true时,非空目录及其内容会被永久性删除

注意:
- 第1步请求NN上传文件,NN会做一系列检查,比如目标文件是否已经存在,父目录是否存在,是否有权限等
- 第2步返回成功了之后才开始请求上传第一个block

HDFS对数据的一致性和安全性要求高。
SecondaryNameNode:专门用于FsImage和Edits的合并。也被称为检查节点(为NN执行检查服务)
- 元信息需要在内存里也需要在磁盘中备份:FsImage
- 同步更新FsImage效率过低,引入Edits(只追加,效率高)。每当元数据有变化的时候,修改内存中的元数据并追加到Edits中
- 长时间使用Edits会导致文件过大,需要定期合并,故映入2ndNameNode
持有化技术:
- Redis:加载高效,生成慢 <==> hadoop 2NN
- RDB:生成快,加载慢,安全性略低 <==> FsImage
- AOF:实时操作,安全性高。资源占用多 <==> edits.log

先更新文件、再更新内存。为了安全性考虑。如果更新了内存,然后断电,那么数据就丢失了
- hdfs-default.xml 默认2NN一小时执行一次checkpoint
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
- 一分钟检查一次操作次数
- 当操作次数达到100万时,2NN执行一次
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
两种方法:
- 将2NN中的数据拷贝到NN存储数据的目录
# 1. kill -9 NameNode进程
# 2. 删除NN存储的数据(/data/hadoop/tmp/dfs/name)
rm -rf /data/hadoop/tmp/dfs/name/*
# 3. 拷贝2NN中数据到原NN存储数据的目录
scp -r beifeng@s02:/data/hadoop/tmp/dfs/namesecondary/* /data/hadoop/tmp/dfs/name/
# 4. 重新启动NameNode
sbin/hadoop-daemon.sh start namenode
- 使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中
# 1. 修改hdfs-site.xml
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
# 2. kill -9 NameNode进程
# 3. 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
# 4. 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
scp -r hadoop@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary hadoop@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/
cd namesecondary
rm -rf in_use.lock
# 5. 导入检查点数据(等待一会ctrl+c结束掉)
bin/hdfs namenode -importCheckpoint
# 6. 启动NameNode
sbin/hadoop-daemon.sh start namenode
- 1.NameNode启动
NameNode启动时,首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的Fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode请求。这个过程期间,NameNode一直运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
- 2.DataNode启动
系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。
- 3.安全模式退出判断
如果满足“最小副本条件”,NameNode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式。
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
模拟等待安全模式
# 1.查看当前模式
[hadoop@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -safemode get
Safe mode is OFF
# 2.先进入安全模式
[hadoop@hadoop102 hadoop-2.7.2]$ bin/hdfs dfsadmin -safemode enter
# 3.创建并执行下面的脚本
在/opt/module/hadoop-2.7.2路径上,编辑一个脚本safemode.sh
[hadoop@hadoop102 hadoop-2.7.2]$ touch safemode.sh
[hadoop@hadoop102 hadoop-2.7.2]$ vim safemode.sh
#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-2.7.2/README.txt /
[hadoop@hadoop102 hadoop-2.7.2]$ chmod 777 safemode.sh
[hadoop@hadoop102 hadoop-2.7.2]$ ./safemode.sh
# 4.再打开一个窗口,执行
[hadoop@hadoop102 hadoop-2.7.2]$ bin/hdfs dfsadmin -safemode leave
# 5.观察
(a)再观察上一个窗口
Safe mode is OFF
(b)HDFS集群上已经有上传的数据了。

DataNode节点保证数据完整性的方法。
- 1)当DataNode读取Block的时候,它会计算CheckSum。
- 2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
- 3)Client读取其他DataNode上的Block。
- 4)DataNode在其文件创建后周期验证CheckSum
HDFS默认的超时时长为10分钟+30秒
计算公式:timeout=2dfs.namenode.heartbeat.recheck-interval+10dfs.heartbeat.interval
# hdfs-site.xml
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value><!-- 默认5分钟,单位是毫秒 -->
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value> <!-- 默认3秒,单位是秒 -->
</property>
注意先清空磁盘上需要来存放HDFS的位置上的所有文件,比如/opt/module/hadoop-2.7.2/data和log
步骤:
# 直接启动DataNode即可关联到集群
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start nodemanager
# 如果数据不均衡,可以使用命令实现集群的再平衡
sbin/start-balancer.sh
通过白名单的方式退役(更严格)
- 配置需要服役的主机,退役的DN不配置进去
# 1.配置白名单
# vim /usr/local/hadoop/etc/hadoop/dfs.hosts
s01
s02
s03
# 2.配置白名单位置
# vim hdfs-site.xml
<property>
<name>dfs.hosts</name>
<value>/usr/local/hadoop/etc/hadoop/dfs.hosts</value>
</property>
# 3.刷新NameNode
hdfs dfsadmin -refreshNodes
# 4.更新ResourceManager节点
yarn rmadmin -refreshNodes
通过黑名单的方式退役(更温和)
# 1.新建黑名单文件
# vim /usr/local/hadoop/etc/hadoop/dfs.hosts.exclude
添加要退役的节点,比如s04
# 2.修改hdfs-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/dfs.hosts.exclude</value>
</property>
# 3.刷新NameNode
hdfs dfsadmin -refreshNodes
# 4.更新ResourceManager节点
yarn rmadmin -refreshNodes
每个目录存储的数据不一样,主要用于想要扩展集群的大小的时候,新的磁盘可以通过这个方式配置进集群
hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
# 1. scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/hadoop/hello.txt // 推 push
scp -r root@hadoop103:/user/hadoop/hello.txt hello.txt // 拉 pull
//通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
scp -r root@hadoop103:/user/hadoop/hello.txt root@hadoop104:/user/hadoop
# 2.采用distcp命令实现两个Hadoop集群之间的递归数据复制
bin/hadoop distcp hdfs://hadoop102:9000/user/hadoop/hello.txt hdfs://hadoop103:9000/user/hadoop/hello.txt
- HDFS存储小文件的弊端(实际工作中,应该尽量避免使用HDFS处理小文件)
- 解决存储小文件的方法之一:使用存档
HDFS存档文件或HAR文件,是一个更高效的文件归档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
- 操作命令
# 归档文件
bin/hadoop archive -archiveName input.har –p /user/hadoop/input /user/hadoop/output
# 查看归档
hadoop fs -lsr /user/hadoop/output/input.har # 查看的是归档后对于NameNode而言的结果
hadoop fs -lsr har:///user/hadoop/output/input.har # 可以查看归档的所有小文件
# 解归档文件
hadoop fs -cp har:/// user/hadoop/output/input.har/* /user/hadoop
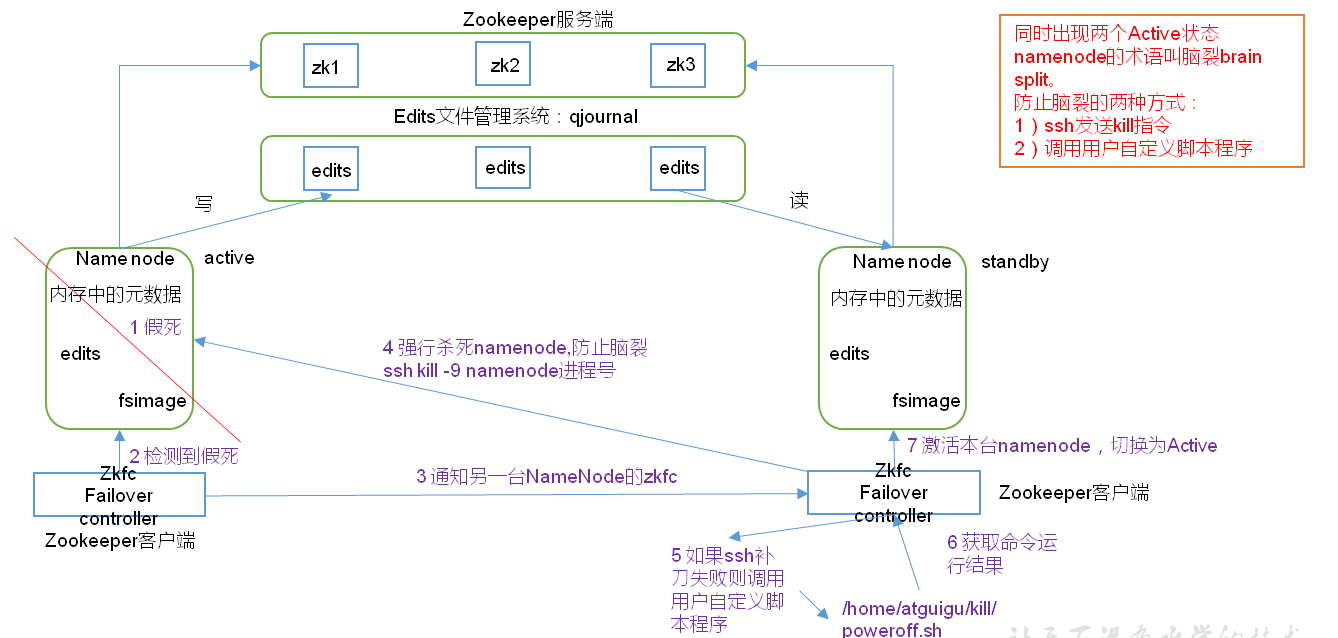
- 元数据管理方式需要改变
- 内存中各自保存一份元数据;
- Edits日志只有Active状态的NameNode节点可以做写操作;
- 两个NameNode都可以读取Edits;
- 共享的Edits放在一个共享存储中管理(qjournal和NFS两个主流实现);
- 需要一个状态管理功能模块
- 实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识
- 当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。
- 必须保证两个NameNode之间能够ssh无密码登录
- 隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程
zk服务的背后意义是使得分布式应用程序不必实现分布式和高可靠性、组管理和存在协议等
HA的自动故障转移依赖于ZooKeeper的以下功能:
- 1)故障检测:集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
- 2)现役NameNode选择:ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
- 1)健康监测:ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
- 2)ZooKeeper会话管理:当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
- 3)基于ZooKeeper的选择:如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前的现役NameNode,然后本地NameNode转换为Active状态。