Lambda表达式的作用:一句话概括就是由垃圾代码变成高级代码的过程
- 演变过程: 垃圾代码 -> 策略模式 -> 匿名内部类 ->
Lambda表达式
Consumer:<T>:消费型接口; 只有输入,没有输出,需要实现的抽象函数为:void accept(T t);
/**
* 1.Consumer<T>:消费型接口
*/
@Test
public void test01() {
happy(1000, (x) -> System.out.println("消费了" + x + "元"));
}
public void happy(double money, Consumer<Double> con) {
con.accept(money);
}
Supplier:<T>供给型接口; 没有输入,只有输出,用来产生一个对象,需要实现的抽象函数为:T get();
/**
* 2.供给型接口:Supplier<T>
* 用来产生一个对象
*/
@Test
public void test02() {
List<Integer> list = getNumList(10, () -> (int) (Math.random() * 100));
System.out.println(list);
}
//需求,产生指定个数的数字(类型未知)并放入集合中
private List<Integer> getNumList(int num, Supplier<Integer> sup) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < num; i++) {
Integer n = sup.get();
list.add(n);
}
return list;
}
Function:<T,R>函数型接口; 输入一个对象,返回一个对象,需要实现的抽象函数为:R apply(T t);
/**
* 3.Function<T,R>:函数型接口
*/
@Test
public void test03() {
System.out.println(strHandler("\t\t 我乃梁奉先是也 ", String::trim));
System.out.println(strHandler("我乃梁奉先是也", (str) -> str.substring(2, 5)));
}
//需求:用于处理字符串
public String strHandler(String str, Function<String, String> function) {
return function.apply(str);
}
Predicate:<T>断言型接口; 输入一个对象,返回一个Boolean值,需要实现的抽象函数为boolean test(T t)
/**
* 4.Predicate<T>:断言型接口
*/
@Test
public void test04(){
List<String> list= Arrays.asList("Hello","我乃梁奉先是也","Lambda","www","ok");
//过滤长度大于三的字符串
System.out.println(filterStr(list,(str)->str.length()>3));
}
//需求,将满足条件的字符串添加到集合中
private List<String> filterStr(List<String> list, Predicate<String> predicate) {
List<String> strList = new ArrayList<>();
for (String str : list) {
if (predicate.test(str)) {
strList.add(str);
}
}
return strList;
}断言组合(谓词组合),与或非
public class PredicateFunction {
//抽取公共代码
static List<Apple> filterApples(List<Apple> inventory, Predicate<Apple> p){
List<Apple> result = new ArrayList<>();
inventory.forEach(apple -> {
if(p.test(apple)){
result.add(apple);
}
});
return result;
}
public static void main(String[] args) {
String[] colors = {"green","yellow","blue"};
Random r = new Random();
List<Apple> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(new Apple(colors[r.nextInt(colors.length)],r.nextInt(200)));
}
System.out.println(filterApples(list,Apple::isGreenApple));
System.out.println(filterApples(list,Apple::isHealthyApple));
//组合两个条件
Predicate<Apple> p1 = Apple::isGreenApple;
Predicate<Apple> p2 = Apple::isHealthyApple;
//或运输
System.out.println(filterApples(list,p1.or(p2)));
//and运算
System.out.println(filterApples(list,p1.and(p2)));
}
}
@Data
@AllArgsConstructor
class Apple{
private String color;
private int weight;
public static boolean isGreenApple(Apple apple){
return "green".equalsIgnoreCase(apple.getColor());
}
public static boolean isHealthyApple(Apple apple){
return apple.getWeight() > 150;
}
}方法引用主要有三种语法格式:方法引用:若Lambda体中的内容有方法已经实现了,我们可以使用"方法引用"(可以理解为方法引用是Lambda表达式的另一种表现形式)
对象::实例方法名类::静态方法名类::实例方法名
- Lambda体中调用方法的参数列表与返回值类型,要与函数式接口中抽象方法的参数列表和返回值类型保持一致
- 若Lambda参数列表中的第一参数是是实例方法的调用者,而第二个参数是实例方法的参数时,可以使用
ClassName::method
对象::实例方法名
/**
* 1.对象::实例方法名
* 要求:该对象的实例方法的参数列表和返回类型要和核心接口一致
*/
@Test
public void test01() {
//Consumer<String> consumer=(x)->System.out.println(x);
//用lambda表达式的方法引用形式实现抽象方法
Consumer<String> consumer = System.out::println;
//往抽象方法传参
consumer.accept("我乃梁奉先是也");
}```java /** * 2.类::静态方法名 */ @Test public void test03() { List list = Arrays.asList("a","aaa","ddd"); list.forEach(System.out::println); } ```
类::静态方法名
类::实例方法名
/**
* 3.类::实例方法名
*/
@Test
public void test04(){
//BiPredicate是Predicate的子类,它可以传入两个参数,并返回一个Boolean值
BiPredicate<String,String> bp= String::equals;
System.out.println(bp.test("1","2"));
}Stream 的三个操作步骤
创建Stream中间操作终止操作(终端操作)
终止操作常用方法:
一、查找和匹配
allMatch:检查是否匹配所有元素anyMatch:检查是否至少匹配一个元素noneMatch:检查是否没有匹配所有元素findFirst:返回第一个元素findAny:返回当前流中的任意元素count:返回流中元素的总个数max:返回流中的最大值min:返回流中的最小值
二、规约
reduce(T identity,BinaryOperator)/reduce(BinaryOperator):可以将流中的元素反复结合起来,得到一个值
三、收集:
collect:将流转换为其他形式。接受一个Collector接口的实现,用于给Stream中元素做汇总的方法
下面栗子中用到的employees集合:
List<Employee> employees = Arrays.asList(
new Employee("张三", 18, 9999.99, Employee.Status.FREE),
new Employee("李四", 58, 5555.55, Employee.Status.BUSY),
new Employee("王五", 26, 3333.33, Employee.Status.VOCATION),
new Employee("赵六", 36, 6666.66, Employee.Status.FREE),
new Employee("田七", 19, 8888.88, Employee.Status.BUSY),
new Employee("田七", 19, 8888.88, Employee.Status.BUSY),
new Employee("田七", 19, 8888.88, Employee.Status.BUSY)
);
allMatchanyMatchnoneMatchfindFirst
@Test
public void test01() {
/**
* employees是一个JavaBean,里面存放着name、age、salary属性和一个枚举类型status,status有FREE、BUSY、
* VOCATION
*/
//allMatch:检查是否匹配所有元素
Boolean b = employees.stream()
.allMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b);
System.out.println("---------------------------");
//anyMatch:检查是否至少匹配一个元素
Boolean b2 = employees.stream()
.anyMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b2);
System.out.println("---------------------------");
//noneMatch:检查是否没有匹配所有元素
Boolean b3 = employees.stream()
.noneMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b3);
System.out.println("---------------------------");
//findFirst:返回第一个元素
Optional<Employee> op = employees.stream()
//先根据Salary升序
.sorted(Comparator.comparingDouble(Employee::getSalary))
//取出第一个元素
.findFirst();
System.out.println(op.get());
}
countmaxmin
@Test
public void test02() {
//count:返回流中元素的总个数
Long count = employees.stream()
.count();
System.out.println(count);
System.out.println("-----------");
//max:返回流中的最大值
Optional<Employee> op1 = employees.stream()
.max(Comparator.comparingDouble(Employee::getSalary));
System.out.println(op1.get());
System.out.println("------------");
Optional<Double> op2 = employees.stream()
.map(Employee::getSalary)
.min(Double::compare);
System.out.println(op2.get());
}
reduce(T identity,BinaryOperator)reduce(BinaryOperator)
/**
* 规约:reduce(T identity,BinaryOperator)/reduce(BinaryOperator):可以将流中的元素反复结合起来,得到一个值
*/
@Test
public void test03() {
//reduce(T identity,BinaryOperator)
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = list.stream()
//identity是一个种子,也就是规约的起始值;后面写对元素的操作
.reduce(0, Integer::sum);
System.out.println(sum);
//reduce(BinaryOperator),由于没有起始值所以可能为空,故返回Optional类型
Optional<Double> op = employees.stream()
.map(Employee::getSalary)
.reduce(Double::sum);
System.out.println(op.get());
}
collect
/**
* 收集:collect:将流转换为其他形式。接受一个Collector接口的实现,用于给Stream中元素做汇总的方法
*/
//对字符串收集,修改
@Test
public void test10(){
String str = employees.stream()
.map(Employee::getName)
//.collect(Collectors.joining());//返回字符串:张三李四王五赵六田七田七田七
//.collect(Collectors.joining(","));//返回字符串:张三,李四,王五,赵六,田七,田七,田七
//返回字符串:开始拼接:张三,李四,王五,赵六,田七,田七,田七;结束拼接
.collect(Collectors.joining(",","开始拼接:",";结束拼接"));
System.out.println(str);
}
//求算数运算的另一种方法
@Test
public void test09(){
DoubleSummaryStatistics dss = employees.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary));
System.out.println("求和为:"+dss.getSum());
System.out.println("求平均值为:"+dss.getAverage());
System.out.println("求最大值为:"+dss.getMax());
}
//分区(分片),可以分为true和false区,满足条件的一个区,不满足条件的一个区
@Test
public void test08(){
Map<Boolean, List<Employee>> map = employees.stream()
.collect(Collectors.partitioningBy((e) -> e.getSalary() > 8000));
System.out.println(map);
}
//多级分组进行操作
@Test
public void test07(){
Map<Employee.Status, Map<String, List<Employee>>> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getStatus, Collectors.groupingBy((e) -> {
if (e.getAge() <= 35) {
return "青年";
} else if (e.getAge() <= 50) {
return "中年";
} else {
return "老年";
}
})));
System.out.println(map);
}
//分组进行操作
@Test
public void test06(){
Map<Employee.Status, List<Employee>> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getStatus));
System.out.println(map);
}
@Test
public void test05() {
//总数
Long count = employees.stream()
.collect(Collectors.counting());
System.out.println("员工的总数是:" + count);
//平均值
Double avg = employees.stream()
.collect(Collectors.averagingDouble(Employee::getSalary));
System.out.println("工资的平均值是:" + avg);
//总和
Double sum = employees.stream()
.collect(Collectors.summingDouble(Employee::getSalary));
System.out.println("工资的总和是:" + sum);
//最大值
Optional<Employee> max = employees.stream()
.collect(Collectors.maxBy((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())));
System.out.println("工资的最大值是:" + max.get());
//最小值
Optional<Double> min = employees.stream()
.map(Employee::getSalary)
.collect(Collectors.minBy(Double::compare));
System.out.println(min.get());
}
@Test
public void test04() {
//将处理后的流返回成一个List集合
List<String> list = employees.stream()
.map(Employee::getName)
.collect(Collectors.toList());
list.forEach(System.out::println);
System.out.println("--------------------");
//将处理后的流返回成一个Set集合
Set<String> set = employees.stream()
.map(Employee::getName)
.collect(Collectors.toSet());
set.forEach(System.out::println);
System.out.println("---------------------");
//需要将搜集的结果存放在特定的数据结构中
HashSet<String> hashSet = employees.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(HashSet::new));//产生一个集合
hashSet.forEach(System.out::println);
}/**
* 练习一:给定一个数字列表,如何返回一个由每个数的平方构成的列表呢?给定[1,2,3,4,5],应该返回[1,4,9,16,25]
*/
@Test
public void test01(){
List<Integer> list= Arrays.asList(1,2,3,4,5);
list.stream()
.map((x)->x*x)
.forEach(System.out::println);
}
/**
* 练习二:怎样用map和reduce方法数一数流中有多少个Employee呢?
*/
@Test
public void test02(){
List<Employee> employees = Arrays.asList(
new Employee("张三", 18, 9999.99, Employee.Status.FREE),
new Employee("李四", 58, 5555.55, Employee.Status.BUSY),
new Employee("王五", 26, 3333.33, Employee.Status.VOCATION),
new Employee("赵六", 36, 6666.66, Employee.Status.FREE),
new Employee("田七", 19, 8888.88, Employee.Status.BUSY),
new Employee("田七", 19, 8888.88, Employee.Status.BUSY),
new Employee("田七", 19, 8888.88, Employee.Status.BUSY)
);
Optional<Integer> sum = employees.stream()
//这里表示每一个对象进去不进行操作,返回1
.map((e) -> 1)
//对每一个对象返回的1进行累加,即计数
.reduce(Integer::sum);
System.out.println(sum.get());
}peek:如同于map,能得到流中的每一个元素。但map接收的是一个Function表达式,有返回值;而peek接收的是Consumer表达式,没有返回值。
Student s1 = new Student("aa", 10);
Student s2 = new Student("bb", 20);
List<Student> studentList = Arrays.asList(s1, s2);
studentList.stream()
.peek(o -> o.setAge(100))
.forEach(System.out::println);
//结果:
Student{name='aa', age=100}
Student{name='bb', age=100}
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流
Java 8中对并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API可以声明性地通过parallel()和sequential()在并行流与顺序流之间进行切换
Fork/Join框架就是把大任务fork成小任务,交给不同线程处理后将结果join的过程
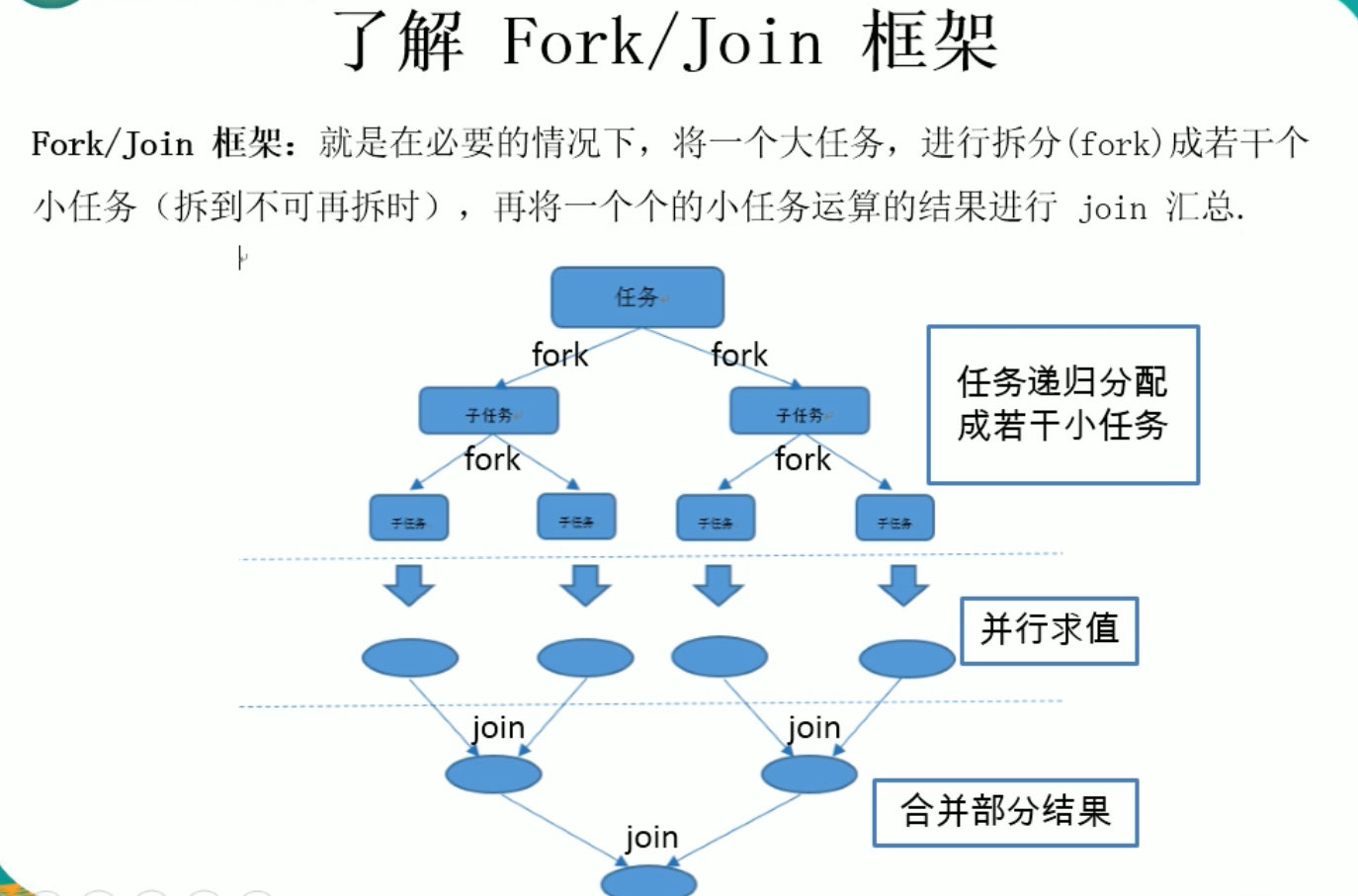
Fork/Join框架与传统线程池的区别

框架类
package com.fx.StreamAPI;
import java.util.concurrent.RecursiveTask;
/**
* @author: 奉先
* @date: 2021/9/20 21:59
* Description:这是一个简单的ForkJoin框架,本例中用于计算大数累加,例如从0累加到1000_000_000(billion)
*/
public class ForkJoinCalculate extends RecursiveTask<Long> {
//提供一个序列号
private static final long serialVersionUID = 1234567890L;
//操作的开始位置
private long start;
//操作的结束位置
private long end;
//拆分停止的临界值
private static final long THRESHOLD = 10000;
//提供一个构造器
public ForkJoinCalculate(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
//如果拆分的长度小于临界值,执行操作,在这个案例里操作为累加求和
if (length <= THRESHOLD) {
long sum = 0;
for (long i = start; i < end; i++) {
sum += i;
}
return sum;
} else {
//length长度大于临界值,进行拆分
//获得拆分长度的中间值
long middle = (start + end) / 2;
ForkJoinCalculate left = new ForkJoinCalculate(start, middle);
//拆分子任务,同时压入线程队列
left.fork();
ForkJoinCalculate right = new ForkJoinCalculate(middle + 1, end);
right.fork();
//完成fork交给不同线程处理完后要Join结果
return left.join() + right.join();
}
}
}测试类
package com.fx.StreamAPI;
import org.junit.Test;
import java.time.Duration;
import java.time.Instant;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.stream.LongStream;
/**
* @author: 奉先
* @date: 2021/9/20 22:45
* Description:此类是ForkJoinCalculate的测试类
*/
public class TestForkJoin {
/**
* Java8之前的写法,方法调用较麻烦
*/
@Test
public void test01(){
//记录一下时间戳
Instant startTime = Instant.now();
//执行ForkJoin需要ForkJoin线程池的支持
ForkJoinPool pool=new ForkJoinPool();
//从zero累加到billion
ForkJoinTask<Long> task=new ForkJoinCalculate(0,1000_000_000L);
Long sum=pool.invoke(task);
//记录一下时间戳
Instant endTime = Instant.now();
System.out.println(sum);
//打印时间戳
System.out.println("耗费时间:"+Duration.between(startTime,endTime).toMillis());//耗时325ms
}
/**
* 普通for循环
*/
@Test
public void test02(){
long sum=0L;
for (int i = 0; i <= 1000_000_000L; i++) {
sum+=i;
}
System.out.println(sum);//耗时2s645ms
}
/**
* Java8并行流
*/
@Test
public void test03(){
//记录一下时间戳
Instant startTime = Instant.now();
long Time = LongStream.rangeClosed(0, 1000_000_000L)
//启用并行流
.parallel()
.reduce(0, Long::sum);
System.out.println(Time);
Instant endTime = Instant.now();
System.out.println("耗费时间:"+Duration.between(startTime,endTime).toMillis());//耗费时间:242ms
}
}
常用方法:
Optional<T>类(java.util.Optional)是一个容器类,代表一个值存在或不存在,原来用null表示一个值不存在,现在Optional可以更好的表达这个概念,并且可以有效的避免NullPointException
Optional.of(T t):创建一个Optional实例Optional.empty():创建一个空的Optional实例Optional.ofNullable(T t):若t不为null,创建Optional实例,否则创建空实例get():取出容器类里封装的对象isPresent():判断是否包含值orElse(T t):如果调用对象包含值,返回该值,否则返回torElseGet(Supplier s):如果调用对象包含值,返回该值,否则返回s获取的值map(Function f):如果有值对其处理,并返回处理后的Optional,否则返回Optional.empty()flatMap(Function mapper):与map类似,要求返回值必须是Opeional
/**
* map(Function f):如果有值对其处理,并返回处理后的 Optional,否则返回 Optional.empty()
* flatmap(Function mapper):与 map 相似,要求返回值必须是 Optional
*/
@Test
public void test06(){
Optional<Employee> op = Optional.ofNullable(new Employee("钱一", 18, 8888.88,
Employee.Status.FREE));
//与Stream的map作用类似
Optional<String> op2 = op.map(Employee::getName);
System.out.println(op2.get());
//flatmap要求返回对象也必须用Optional进行封装
Optional<String> op3 = op.flatMap((e) -> Optional.of(e.getName()));
System.out.println(op3.get());
}
/**
* orElseGet(Supplier s):如果调用对象包含值,返回该值,否则返回 s 获取的值
*/
@Test
public void test05(){
Optional<Employee> op = Optional.ofNullable(null);
//和orElse的区别在于,orElseGet实现的是一个供给性接口,Lambda里可以写逻辑代码,更加灵活
Employee emp = op.orElseGet(Employee::new);
System.out.println(emp);
}
/**
* orElse(T t):如果调用对象包含值,返回该值,否则返回 t
* 笔者认为这个特性非常好,笔者之前做项目的时候,为了处理NullPointException也采取相似的思路,Optional封装后很友好
*/
@Test
public void test04(){
Optional<Employee> op = Optional.ofNullable(null);
//防止为空,为空会替换成默认值
Employee emp = op.orElse(new Employee("钱一", 18, 8888.88, Employee.Status.FREE));
System.out.println(emp);
}
/**
* Optional.ofNullable(T t):若 t 不为 null,创建 Optional 实例,否则空实例
*/
@Test
public void test03() {
//ofNullable方法是of()和empty方法的折中,底层代码为return value == null ? empty() : of(value);
Optional<Employee> op = Optional.ofNullable(null);
//isPresent():判断是否包含某值,Present有现存的意思
if (op.isPresent()) {
System.out.println(op.get());
} else {
System.out.println("Optional封装的对象为空");
}
}
/**
* Optional.empty(T t):创建一个空的 Optional 实例
*/
@Test
public void test02() {
Optional<Employee> op = Optional.empty();
//会报java.util.NoSuchElementException: No value present,也是为了快速定位异常代码
System.out.println(op.get());
}
/**
* Optional.of(T t):创建一个 Optional 实例
*/
@Test
public void test01() {
//调用of方法封装的是null时会报NullPointException,封装的意义是快速定位异常发生的地方
Optional<Employee> op = Optional.of(null);
Employee employee = op.get();
System.out.println(employee);
}栗子里用到的JavaBean
public class NewMan {
//给一个empty值,防止报空指针异常
private Optional<Goddess> goddess=Optional.empty();
···提供对应的构造器、setter/getter方法、重写toString()方法
}
public class Man {
private Goddess goddess;
···提供对应的构造器、setter/getter方法、重写toString()方法
}
public class Goddess {
private String name;
···提供对应的构造器、setter/getter方法、重写toString()方法
}栗子
/**
* Optional应用栗子,需求,获取一个男人心中女神的名字
*/
//传统方式
@Test
public void test1001(){
Man man=new Man();
String goddessName=getGoddessName(man);
//会输出女神的默认值,因为Man类女神为空
System.out.println(goddessName);
}
//Java8优化后
@Test
public void test1002(){
Optional<NewMan> op = Optional.ofNullable(null);
String str = getGoddessName2(op);
System.out.println(str);
}
//改进后防止空指针的方法
public String getGoddessName2(Optional<NewMan> man){
return man.orElse(new NewMan())
.getGoddess()
.orElse(new Goddess("女神的默认值"))
.getName();
}
//传统的防止空指针异常的栗子
public String getGoddessName(Man man){
if(null!=man){
Goddess gn=man.getGoddess();
if(null!=gn){
return gn.getName();
}
}
return "一个女神的默认值";
}由于之前的时间API中都
不是线程安全的,所以在Java8中更新了一套全新的时间API
举个栗子:
@Test
public void test01() throws ExecutionException, InterruptedException {
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd");
//每次都解析这个时间戳
Callable<Date> task= () -> sdf.parse("20210928");
//创建一个拥有十个线程的线程池
ExecutorService pool = Executors.newFixedThreadPool(10);
List<Future<Date>> results=new ArrayList<>();
for (int i = 0; i < 10; i++) {
results.add(pool.submit(task));
}
for (Future<Date> future:results) {
System.out.println(future.get());
}
}
/**
*会抛出java.util.concurrent.ExecutionException: java.lang.NumberFormatException: For input string: *"28E2289210E2"
*/使用Java8时间API:
@Test
public void test02() throws ExecutionException, InterruptedException {
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyyMMdd");
//每次都解析这个时间戳
Callable<LocalDate> task= () -> LocalDate.parse("20210929",dtf);
//创建一个拥有十个线程的线程池
ExecutorService pool = Executors.newFixedThreadPool(10);
List<Future<LocalDate>> results=new ArrayList<>();
for (int i = 0; i < 10; i++) {
results.add(pool.submit(task));
}
for (Future<LocalDate> future:results) {
System.out.println(future.get());
}
}
/**
* 输出十次2021-09-29
*/Java8为我们提供了很多安全的时间API
LocalDate:当地日期LocalTime:当地时间LocalDateTime:当地日期和时间Instant:时间戳(以Unix为例,元年指1970年1月1日零点零时零分到某个时间的毫秒值),这里获取的是UTC时间Period:计算两个“日期”之间的间隔Duration:计算两个“时间”之间的间隔
举个栗子:
@Test
public void test02() {
LocalDateTime ldf = LocalDateTime.now();
//输出ISO规定的标准时间
System.out.println(ldf);//输出2021-09-29T18:44:58.328
//输出年
System.out.println(ldf.getYear());
//输出月 getMonth()会输出英文的月份
System.out.println(ldf.getMonthValue());
//输出日
System.out.println(ldf.getDayOfMonth());
//输出时
System.out.println(ldf.getHour());
//输出分
System.out.println(ldf.getMinute());
//输出秒
System.out.println(ldf.getSecond());
}
/**
* Instant:时间戳(以Unix为例,元年指1970年1月1日零点零时零分到某个时间的毫秒值),这里获取的是UTC时间
*/
@Test
public void test03(){
//UTC是时间统一时间,在数值上等同于格林威治(GMT)时间
Instant ins1 = Instant.now();//默认获取UTC时区
System.out.println(ins1);
//修正时间
OffsetDateTime odt = ins1.atOffset(ZoneOffset.ofHours(8));
System.out.println(odt);//输出2021-09-30T15:46:46.254+08:00
}
/**
* Period:计算两个“日期”之间的间隔
*/
@Test
public void test05(){
LocalDate ld1 = LocalDate.of(2015, 1, 1);
LocalDate ld2 = LocalDate.now();
Period period = Period.between(ld1, ld2);
//默认输出ISO规定格式的时间差
System.out.println(period);//输出P6Y8M29D,表示差了6年8个月29天
//输出年
System.out.println(period.getYears());
//输出月
System.out.println(period.getMonths());
//输出日
System.out.println(period.getDays());
}
/**
* Duration:计算两个“时间”之间的间隔
*/
@Test
public void test04(){
Instant ins1=Instant.now();
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
Instant ins2 = Instant.now();
Duration duration = Duration.between(ins1, ins2);
//获取两个时间之间的毫秒值
System.out.println(duration.toMillis());
//获取两个时间之间的秒值
System.out.println(duration.getSeconds());
}LocalDateTime 毫秒值有时有有时无保存解决
/*=== 毫秒值与时间互相转换 ===*/
/*
* 毫秒值>>时间
* 思路:先转换成Instant,再加上时区(ZoneOffset也可以)转换成LocalDateTime
* 思路:使用LocalDateTime.ofEpochSecond 传入秒,和纳秒值
*/
long milli = 1555666999123L;//首先来一个long毫秒值,也可使用System.currentTimeMillis()
LocalDateTime time1 = LocalDateTime.ofInstant(Instant.ofEpochMilli(milli), ZoneId.systemDefault());
LocalDateTime time2 = LocalDateTime.ofEpochSecond(milli / 1000, (int)(milli % 1000 * 1000_000), ZoneOffset.ofHours(8));
System.out.println("毫秒值转换时间方式一:" + time1);//2019-04-19T17:43:19.123
System.out.println("毫秒值转换时间方式二:" + time2);//2019-04-19T17:43:19.123
System.out.println("两种方式结果是否一致:" + time1.equals(time2));//true
/*
* 时间>>毫秒值
* 思路:先根据当前时间的时区转换成Instant,再使用Instant对象的toEpochMilli方法
* 思路:使用toEpochSecond(ZoneOffset)和getNano()分别获得秒(整数部分,不足一秒的舍弃)和纳秒,再统一单位到毫秒进行相加
*/
LocalDateTime time = LocalDateTime.of(2019, 4, 19, 17, 43, 19, 123 * 1000_000);//首先有一个时间对象,2019-04-19T17:43:19.123
long milli1 = time.toInstant(ZoneOffset.ofHours(8)).toEpochMilli();
long milli2 = time.toEpochSecond(ZoneOffset.ofHours(8)) * 1000 + time.getNano() / 1000_000;
System.out.println("时间转换毫秒值方式一:" + milli1);
System.out.println("时间转换毫秒值方式二:" + milli2);
/*=== 文本与时间互相转换 ===*/
//文本与时间转换需要一个模板和一个 DateTimeFormatter
String pattern = "自定义文本''yyyy-MM-dd HH:mm:ss.SSS''";
DateTimeFormatter timeFormatter = DateTimeFormatter.ofPattern(pattern);
//java8版本在pattern带毫秒的解析中异常问题可使用DateTimeFormatterBuilder的appendPattern和appendValue方式进行构建(未验证)
/*DateTimeFormatter timeFormatter = new DateTimeFormatterBuilder()
.appendPattern("自定义文本''yyyy-MM-dd HH:mm:ss.")
.appendValue(ChronoField.MILLI_OF_SECOND)
.appendPattern("''").toFormatter();*/
/*
* 文本>>时间
* 思路:直接使用LocalDateTime.parse方法,传入文本和一个DateTimeFormatter实例
* 思路:使用DateTimeFormatter对象的parse方法解析出一个TemporalAccessor对象,再最为LocalDateTime.from的参数
*/
String text = "自定义文本'2019-04-19 17:43:19.123'";//假设有这样一个文本,需要转换为时间
LocalDateTime localDateTime1 = LocalDateTime.parse(text, timeFormatter);
LocalDateTime localDateTime2 = LocalDateTime.from(timeFormatter.parse(text));
System.out.println(localDateTime1);//2019-04-19T17:43:19.123
System.out.println(localDateTime2);//2019-04-19T17:43:19.123
System.out.println(localDateTime1.equals(localDateTime2));//true
/*
* 时间>>文本
* 思路:DateTimeFormatter和LocalDateTime都可以作为主调,另一个则最为参数
*/
LocalDateTime localDateTime = LocalDateTime.of(2019, 4, 19, 17, 43, 19, 123 * 1000_000);//假设有这样一个时间对象,2019-04-19T17:43:19.123 需要转换为文本
System.out.println("时间转换为自定义文本:" + timeFormatter.format(localDateTime));
System.out.println("时间转换为自定义文本:" + localDateTime.format(timeFormatter));
/*=== 文本转换为毫秒值 ===*/
/*
* 文本=>时间=>毫秒值
* 参考以上
*/

Java8为我们提供了许多关于时间的操纵
常用的方法:
TemporalAdjuster:时间校正器TemporalAdjusters:通过静态方法提供了大量的常用的TemporalAdjuster的实现

传统的输出时间的方式:
Date now=new Date(); //创建一个Date对象,获取当前时间
//指定格式化格式
SimpleDateFormat f=new SimpleDateFormat("现在时间是 "+"yyyy 年 MM 月 dd 日 E HH 点 mm 分 ss 秒");
System.out.println(f.format(now)); //将当前时间袼式化为指定的格式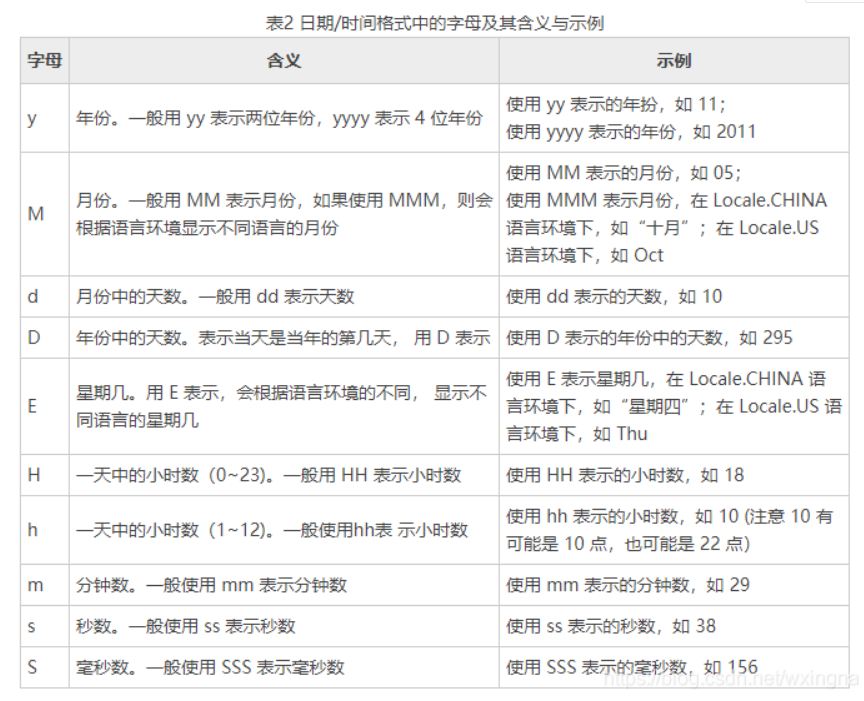
- 允许声明在接口中实现了的方法,称为
默认方法 - 允许在接口中定义
静态方法
当继承类和实现接口冲突时,遵守
类优先的规则
举个栗子:
//用Java8新特性在接口中定义一个默认方法
public interface MyFunction {
default String getName(){
return "返回MyFunction里的值";
}
}
//定义一个普通的类
public class MyClass {
public String getName(){
return "返回MyClass里的值";
}
}
//定义一个类对上述类继承
public class SubClass extends MyClass implements MyFunction {}
//测试,输出‘返回MyClass里的值’,表示当继承类和实现接口冲突时,遵守类优先的规则
public class TestDefaultInterface {
public static void main(String[] args) {
SubClass subClass = new SubClass();
System.out.println(subClass.getName());
}
}详解:
