Tokenization is a process to fragment text into tokens. Tokens are the surfaces that can be parsed by the morphologic parser.
For example, for the text "Ali topu at." tokens are ["Ali","topu","at","."].
This process could be quite complicated since there are ambiguous rules:
.can be used as sentence ending character, ordinal number character (1.->birinci), number grouping character (10.000), helper character for other punctuation (!..), etc.,can be used as semantic grouping for sentences, decimal separator (3,24), etc.II.could mean2ndor a sentence ending with wordII.- ...
A tokenizer should be able to fragment these tokens.
A complex example (which actually is not logical) : III. İbrahim, 2. defa savaşa gitti. 3,45 km olan yolu...
Here is the tokens that could be parsed by the morphologic parser in a logical way.
["III."+RomanOrdinal , "İbrahim"+FirstLetterUpperCaseWord, ","+Punc, "2."+OrdinalNumber, "defa"+LowerCaseWord, "savaşa"+LowerCaseWord, "gitti"+LowerCaseWord, "."+Punc, "3,45"+CardinalNumber, "km"+Abbr, "olan"+LowerCaseWord, "yolu"+LowerCaseWord, "..."+Punc]
Meta info which is also included in the results could help. Morphological parser could in theory use that information, although TRNLTK doesn't offer this feature yet.
There are various methods for doing tokenization.
One method is to define rules manually to recognize words and their boundaries. Advantage is to have really stable process which performs good in terms of speed. Also, if it is done good, rules come intuitively. Bad side is, there can be a lot of ambiguity where system cannot resolve. Also, defining rules for exceptions could make rule system quite complex; thus hard to maintain.
Another approach is to find rules from a training set. That means, a system can infer rules from a pair of non-tokenized text and a tokenized text. This is the approach used in TRNLTK tokenizer.
Please see Zemberek3 tokenizer for a good working example. It is based on ANTLR where rules for ANTLR is defined manually. It is quite fast.
In TRNLTK, a text block is split into morphologically parsable parts using a tokenizer. This tokenizer learns rules from existing tokenization done. That means, a training set is used for training.
In that set, entries for normal text and word-separated split text is found.

First sentence "Ali geldi." is the text valid according to Turkish sentence rules. Second sentence "Ali geldi ." is the tokenized text, where tokens are separated with white space.
Tokenizer reads first sentence and extracts the following rule: **If there is a "." character after a word without any white space, separate the "." and mark it as a new token.
Please note that, in this example, rule extraction only considers the past 1 word. So, it fails in the following case:
- Train "3, 4" -> "3 , 4"
- Which means learning ()()() -> ()()()()
- Train "3,4 oran" -> "3,4 oran"
- Which means learning ()()() -> ()()()
- Tokenization "3, 4 elma" -> "3 , 4 elma"
- Wrong tokenization "3,4 oran" -> "3 ,4 oran" since a rule like following is extracted : "if there is a number and then a comma followed by a space, separate comma and mark it as a new token"
In order to fix this problem, tokenizer needs to check 2 text groups from the left and the right.
- Train "3, 4" -> "3 , 4"
- Which means learning ()()() -> ()()>()()
- Train "3,4 oran" -> "3,4 oran"
- Which means learning ()()() -> ()()()
- Tokenize "3, 4 elma" -> "3 , 4 elma"
- Tokenize "3,4 oran" -> "3,4 oran"
N=2 almost covers all cases (99%), but N is customizable. Of course N=3 or anything larger will result in a bigger number of tokenization rules and thus it will be much slower (in the order of K^N)
Let us show the graph for a very simple tokenization rule with N=2:
- "ali␣geldi." -> "ali␣geldi ."

blue : add space red : don't add space
From here we can infer a new rule:
Premise : If a <Space+Word> block is followed by a <Dot+Sentence_End> block, add a space in between.
Thus, if a <Space+CapitalizedWord> block is followed by a <Dot+Sentence_End> block, add a space in between.

solid line : observed rule dashed line : inferred rule
We can make another inference:
Premise : If a <Sentence_Start+Word> block is followed by a <Space+Word> block, don't add a space in between.
Thus, if a <Sentence_Start+Word> block is followed by a <Space+CapitalizedWord> block, don't add a space in betwen.
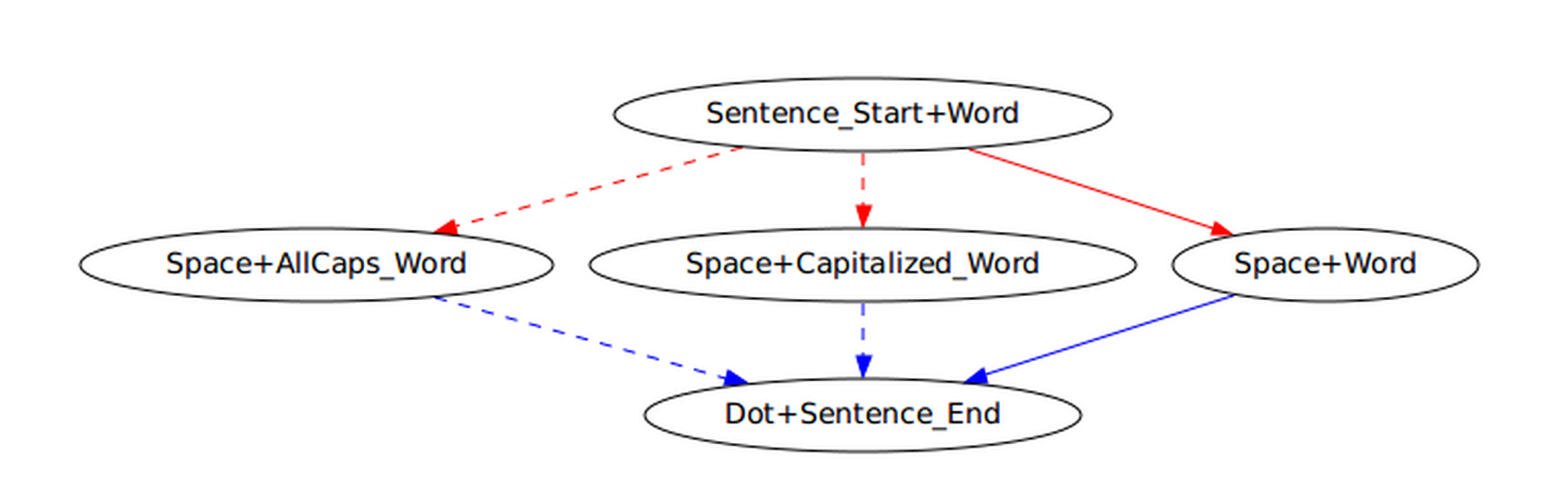
Further inference can be made from just one training rule:

One important factor here is to have a consistency.
- While training with different examples, if a new rule is observed:
- Existing inferred rules are overwritten
- Existing observed rules are expected to have the same "add space" value with the new observed rule
- If a new rule is observed because of a new observed rule:
- Existing inferred rules are expected to have the same "add space" value with the new inferred rule
- Existing observed rules are expected to have the same "add space" value with the new inferred rule
More details : https://docs.google.com/document/d/14yXsEgeZyaoyyvM9Yo7pUPNP8VARmw7DXV0F-kd6f_8/edit?usp=sharing
In a big text there might be some cases where there is no observed or inferred rule to handle it. It is up to the client of tokenizer to what to do in that case:
- Strict: An exception is thrown when there is no rule found.
- Not Strict: değilse, bulamadığı kural için boşluk koymuyor. Mesela training datasında şu yok : “¬3¬3x”. Bu durumu infer edecek bir durum da yok. recordStats: True ise eksik olan kurallar veya kullanılan kurallar tutuluyor. Eksik olan kuralları inceleyip, training datasına ekleyebiliriz bu sayede.
Akinlara yolladigim mailin aciklamasi strict vs nostrict machine learning, supervised
1 cumle 1 tokenized cumle Ornek cumle ornek tokenized cumle
Just tokenize the input to be pa
ANTLR Learning
Please see the following document for implementation details (in Turkish) : https://docs.google.com/document/d/14yXsEgeZyaoyyvM9Yo7pUPNP8VARmw7DXV0F-kd6f_8/edit?usp=sharing