Add a new field descriptor "relationship" in TableSchema #803
Comments
|
I translate in english the example above (extract IRVE example) Thank you for your consideration of this proposal ! |
|
It could help studying the proposal to give an example within the issue itself (not just to refer to the PDF.) Can you write down a minimal example on how to use such a new field descriptor "relationship" in a schema? Can you explain what value it provides for describing and processing (consistency-checks, etc.) the data? |
|
Thank you Bastien for your comment. Below is a note that offers both a simple example, an argument and links to detailed examples. From my point of view, the value is very clear :
Methodology for taking into account relations between fields in tabular representationsThis note proposes an evolution to the methodology used in several opendata projects (eg. french guide to préparation des données à l'ouverture et la circulation) Only the additions that could be made to the existing approach are discussed below. 0 - Introduction0.1 - ObjectiveThe data schema definition tools (eg TableSchema) define on the one hand descriptive and explanatory information of a data structure and on the other hand the rules to be respected to document this structure. The rules currently defined mainly concern the fields taken separately but do not include the relationships between the fields that make up this structure.
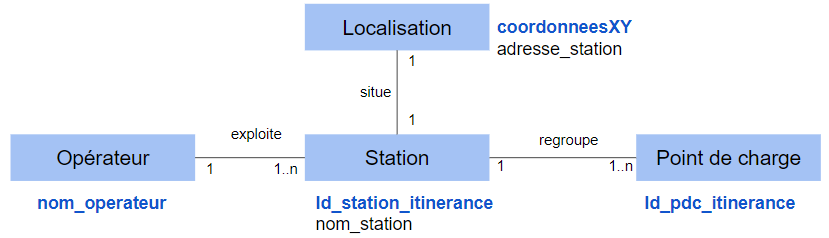
Relationships between fields are important in the consistency of a dataset. Moreover, they are very often expressed in the data models that describe them. The proposed evolution therefore consists in taking into account these relationships between fields at the level of the preparation phase as well as at the level of the operating phase: 0.2 - ExampleIn order to facilitate understanding of the subject, an example will be treated throughout this presentation. It concerns electric vehicle charging infrastructures (IRVE) which is the subject of a detailed schema and a large data set lien data.gouv.fr An analysis of the complete IRVE dataset is available on this link. The example presented is also detailed on this link. 1 - Preparation: Establishing the table schema1.1 Description of the conceptual data modelThe conceptual data model makes it possible to describe the structuring of the information that makes up the data sets.
The initial modeling does not take implementation constraints into account; it is a tool for dialogue between the various stakeholders.
1.2 Description of the logical data modelThe logical data model declines the conceptual model according to the envisaged information system (eg relational database, object modelling, etc.). In the case of a tabular implementation, the logical model shows each of the future fields as an entity with the following rules:
The logical model is therefore directly deduced from the conceptual model.
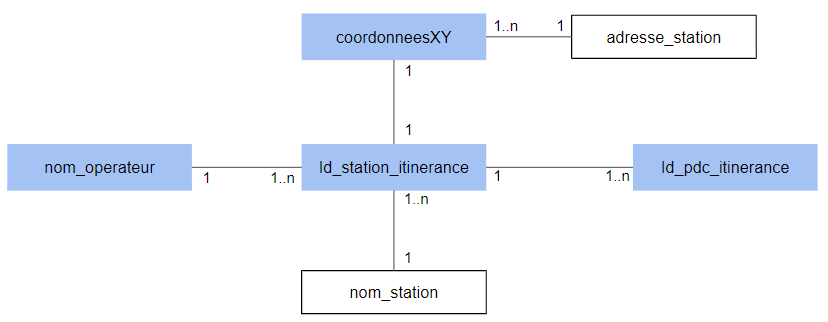
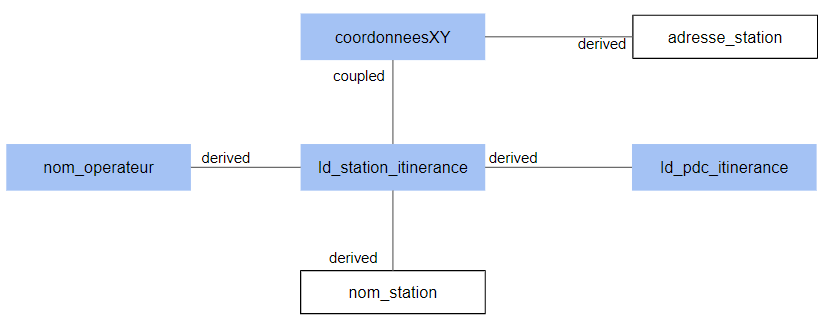
1.3 Physical modelThe physical model consists on the one hand in describing the fields in the schema and on the other hand in specifying the division into files. 1.3.1 Field structureThe fields are defined in the schema (not detailed here). It is therefore appropriate to add to this schema the relationships expressed at the level of the logic model. To do this, a
"fields": [
{
"name": "nom_operateur",
"relationship" : {
"parent" : "id_station_itinerance",
"link" : "derived"
}
},
{
"name": "id_station_itinerance",
"relationship" : {
"parent" : "id_pdc_itinerance",
"link" : "derived"
}
},
{
"name": "nom_station",
"relationship" : {
"parent" : "id_station_itinerance",
"link" : "derived"
}
},
{
"name": "adresse_station",
"relationship" : {
"parent" : "coordonneesXY",
"link" : "derived"
}
},
{
"name": "coordonnéesXY",
"relationship" : {
"parent" : "id_station_itinerance",
"link" : "coupled"
}
}
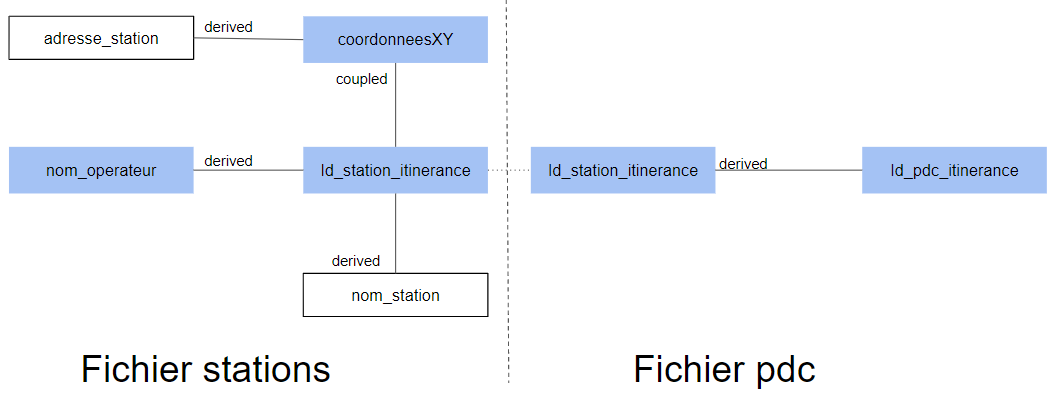
]1.3.2 Splitting into filesSeveral strategies are possible:
In the multi-file case, the separation is necessarily carried out at the level of the identifier entities.
2 - Operation: Documentation and assembly of data setsDataset documentation consists of documenting a set of rows according to the defined file structure. Four levels of analysis must be taken into account:
The first two levels are processed in the existing tools (not detailed here). The restitution of errors can be done simply by adding Boolean control fields associated with each property checked.
|
|
Thanks a lot for the analysis! Usually, new concepts are added to the Standard as a pattern, for example, #844. Would you be interested in working on one? |
|
Thank you @roll for this positive feedback. It's a good idea and I would be very happy to be able to add this topic to the list of patterns. Do I prepare a first version that I share with a PR (and we then exchange/complete it) ? Another question: On Github, to share a data model I use Mermaid. Is this compatible with the |
|
Hi @loco-philippe,
Yes 🚀 v1 website supports Mermaid - https://specs.frictionlessdata.io/, but v2 might not support it, but I think starting from mermaid version will make sense and if it's not supported in v2 (for interoperability reasons) we can just convert to text + images later |
|
Thank you @roll for your answers, i will create the PR towards the end of the year (i'm too busy to do that before !) |
|
DONE https://datapackage.org/recipes/relationship-between-fields/ Thanks a lot @loco-philippe ! |
|
Wow, glad to see this happening, congrats @loco-philippe and thanks to the whole frictionless team! |
In many cases, data are unconsistent between two fields (see extract IRVE example ).
To specify and to check the relationship between two fields (i.e. cardinality in data model), we propose to add a new field descriptor "relationship" in TableSchema.
The proposal is detailled in the joined pdf file
if you want more details or if you want me to translate the linked example, ask me.
Regards
relationship_property.pdf
.
The text was updated successfully, but these errors were encountered: