原文:http://d0evi1.com/tdm/
阿里在KDD 2018上开放了它们的方法:《Learning Tree-based Deep Model for Recommender Systems》, 我们来看下:
在推荐系统设计中,为每个用户从整个语料(corpus)集中预测最好的候选集合,存在许多挑战。在海量corpus的系统中,一些推荐算法会失败。与corpus size成线性预测复杂度关系是不可接受的。部署这样的大规模推荐系统,预测每个用户所需要的计算量是受限的。除了精准度外,在用户体验上也应考虑推荐items的新颖度(novelty)。推荐结果中如果包含许多与用户的历史行为的同质items是不可接受的。
在处理海量corpus时,为了减少计算量,memory-based的CF方法在工业界常被广泛使用。作为CF家族的代表方法,item-based CF可以从非常大的corpus进行推荐,只需要很少的计算量,具体决取于预计算的item pairs间的相似度,以及使用用户历史行为作为触发器(triggers)来召回多个相似items。然而,这限制了候选集的范围,例如,只有与triggers相似的items可以被推荐。这阻止了推荐系统跳出它们的历史行为来探索潜在的其它用户兴趣,限制了召回结果的accuracy。实际上,推荐的新颖性(novelty)也是很重要的。另一个减小计算量的方法是,进行粗粒度推荐(coarsegrained recommendation)。例如,系统为用户推荐少量的item类目,并根据它选择所有相应的items,接着进行一个ranking stage。然而,对于大语料,计算问题仍然没解决。如果类目数很大,类目推荐本身也会遇到计算瓶颈。如果不这样做,一些类目将不可避免地包含过多items,使得后续的ranking计算行不通。另外,使用的类目通常不是为推荐问题专门设计的,它也会对推荐的accuracy有害。
在推荐系统的相关文献中,model-based的方法是一个很活跃的话题。像矩阵分解(MF)这样的模型,尝试将pairwise user-item偏好分解成user factors和item factors,接着为每个用户推荐它最喜欢的items。因子分解机(FM)进一步提出了一个统一模型,对于任意类型的输入数据,可以模仿不同的因子分解模型。在一些真实场景中,没有显式偏好,只有隐式用户反馈(例如:像点击 or 购买 这样的用户行为),Bayesian personalized ranking【29】给出了一个求解思路,它会将三元组中的偏好按局部顺序进行公式化,并将它应用到MF模型中。工业界,YouTube使用DNN来学习user embedding和item embeddings,其中,两种类型的embeddings会分别由其相对应的特征进行生成。在上述所有类型的方法中,user-item pair的偏好可以被公式化成,user vector表示与item vector表示间的内积(inner product)。预测阶段等同于检索用户向量在内积空间中的最近邻。对于向量搜索问题,像hashing或quantization[18]用于近似kNN搜索来确保检索的高效性。
然而,在user vector representations和item vector representations间的内积交互形式,严重限制了模型的能力。存在许多类型的其它更具表现力的交互形式,例如,用户历史行为和候选items间的cross-product特征在CTR预估上广泛被使用。最近的工作【13】提出了一种neural CF方法,它使用一个神经网络来替代内积,被用于建模user和item向量表示间的交互。该工作的试验结果表明,一个多层前馈神经网络,比固定内积方法的效果要好。DIN[34]指出,用户兴趣是分散的,一种基于attention机制的网络结构可以根据不同候选items生成不同的user vectors。除了上述工作外,其它像product NN[27]的方法也表明高级NN的效果。然而,这些类型的模型与user vector和item vector间的内积方法(利用高效的kNN搜索)不相一致,在大规模推荐系统中,它们不能被用于召回候选集。为了克服计算屏障,在大规模推荐中使用高级NN是个问题。
为了解决上述挑战,我们提出了一个新的TDM(tree-based deep recommendation model). 树和基于树的方法在多分类问题中被广泛研究,其中,tree通常被用于划分样本(sample)/标签(label)空间,来减小计算代价。然而,研究者们涉足于推荐系统环境中使用树结构做为索引进行检索。实际上,层次化结构(hierarchical structure)的信息存在于许多领域。例如,在电商中,iPhone是细粒度item,而smartphone是粗粒度概念,iPhone属于smartphone。TDM方法会使用信息的层级,将推荐问题转化成一系列的层次化分类问题(hierarchical classification problems)。从简到难解决该问题,TDM可以同时提升accuracy和efficiency。该paper的主要贡献如下:
- TDM是第一个这样的方法,使得在大规模语料中生成推荐的任意高级模型成为可能。受益于层次化树搜索,TDM的计算量只与corpus size成log关系。
- TDM可以从大型数料中发现更精准的显著并有效的推荐结果,由于整个语料是探索式的,更有效的深度模型也可以帮助发现潜在兴趣。
- 除了更高级的模型外,TDM也通过层次化搜索来提升推荐accuracy,它可以将一个大问题划分成更小的问题分而治之。
- 作为索引的一种,为了更高效地检索,树结构可以朝着items和concepts的最优层次结构被学到,它可以帮助模型训练。我们使用一个tree learning方法,它可以对神经网络和树结构进行joint training。
- 我们在两个大规模数据集上做了大量实验,结果展示TDM的效果要比现有方法好很多。
值得一提的是,tree-based方法也在语言模型中使用(hirearchical softmax),但它与TDM在思想和公式上都不同。在对下一个词的预测问题上,常用的softmax必须计算归一化项(normalization term)来获取任意单个词的概率,它非常耗时。Hierarchical softmax使用tree结构,下一个词的概率就被转换成沿着该tree path的节点概率乘积。这样的公式将下一个词概率的计算复杂度减小到关于语料size的log级别。然而,在推荐问题上,为这些最喜爱items搜索整个语料的目标,是一个检索问题。在hierarchical softmax tree中,父节点的最优化不能保证:最优的低级别节点在它们的子节点上(descendants),并且所有items仍需要被转换成发现最优解。为了解决该检索问题,我们提出了一个类似最大堆的树公式(max-heap like tree),并引入了DNN来建模该树,它为大规模推荐提供了一个有效的方法。以下部分展示了公式的不同之处,它在性能上的优越性。另外,hierarchical softmax采用了单层hidden layer网络来解决一个特定的NLP问题,而我们提出的TDM则实际上可使用任意网络结构。
提出的tree-based模型是一个通用解法,适用于所有类型的在线内容提供商。
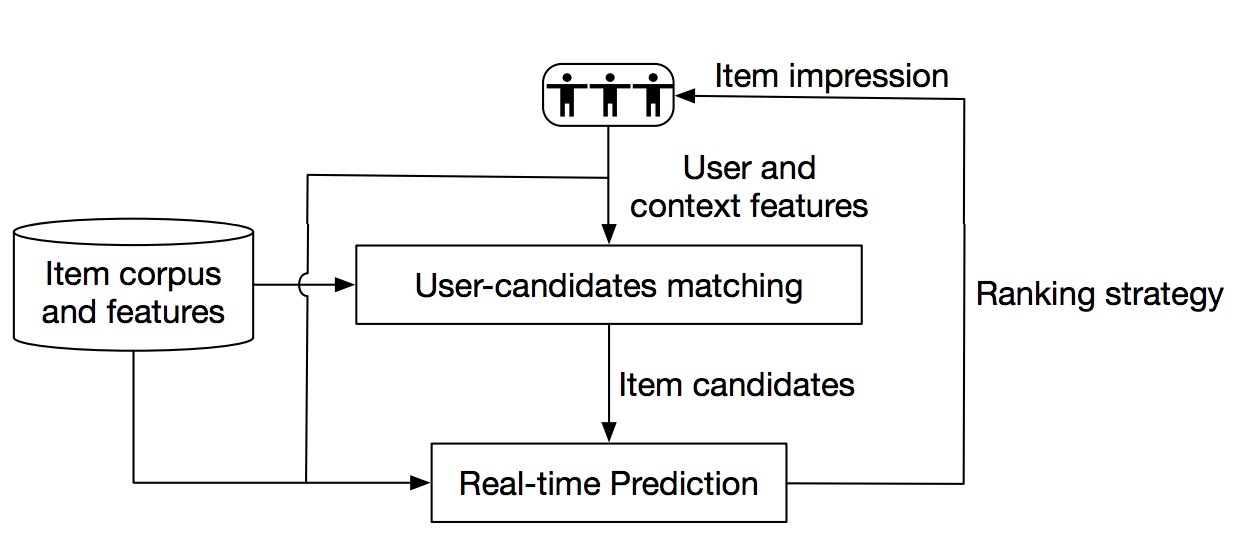
图1 Taobao展示广告(display advertising)推荐系统的系统架构
在本节,图1介绍了Taobao 展示广告推荐系统。在接受到一个用户的PV请求时,系统使用用户特征、上下文特征、以及item特征作为输入,会在matching server中从整个语料中(上百万)来生成一个相对较小的候选集合(通常百级别)。tree-based推荐模型在该stage发挥作用,并将候选集的size缩减了好多阶。
有了数百个候选items,实时预测server会使用更昂贵但也更耗时的模型[11,34]来预测像CTR或转化率之类的指标。在通过策略排完序后,一些items会最终曝光给用户。
如上所述,提出的推荐模型的目标是,构建一个含数百个items的候选集。该stage是必须的,也很难。用户在生成的候选上是否感兴趣,给出了曝光质量的一个上界。然而,从整个语料中有效抽取候选是个难题。
在本部分,我们首先介绍在我们的tree-based模型中所使用的树结构。然后,介绍hierarchical softmax来展示为什么该公式不适合推荐。最后,我们给出了一个新的类max-heap tree公式,并展示了如何训练该tree-based模型。接着,引入DNN结构。最后,我们展示了如何构建和学习在tree-based模型中构建和学习该tree。
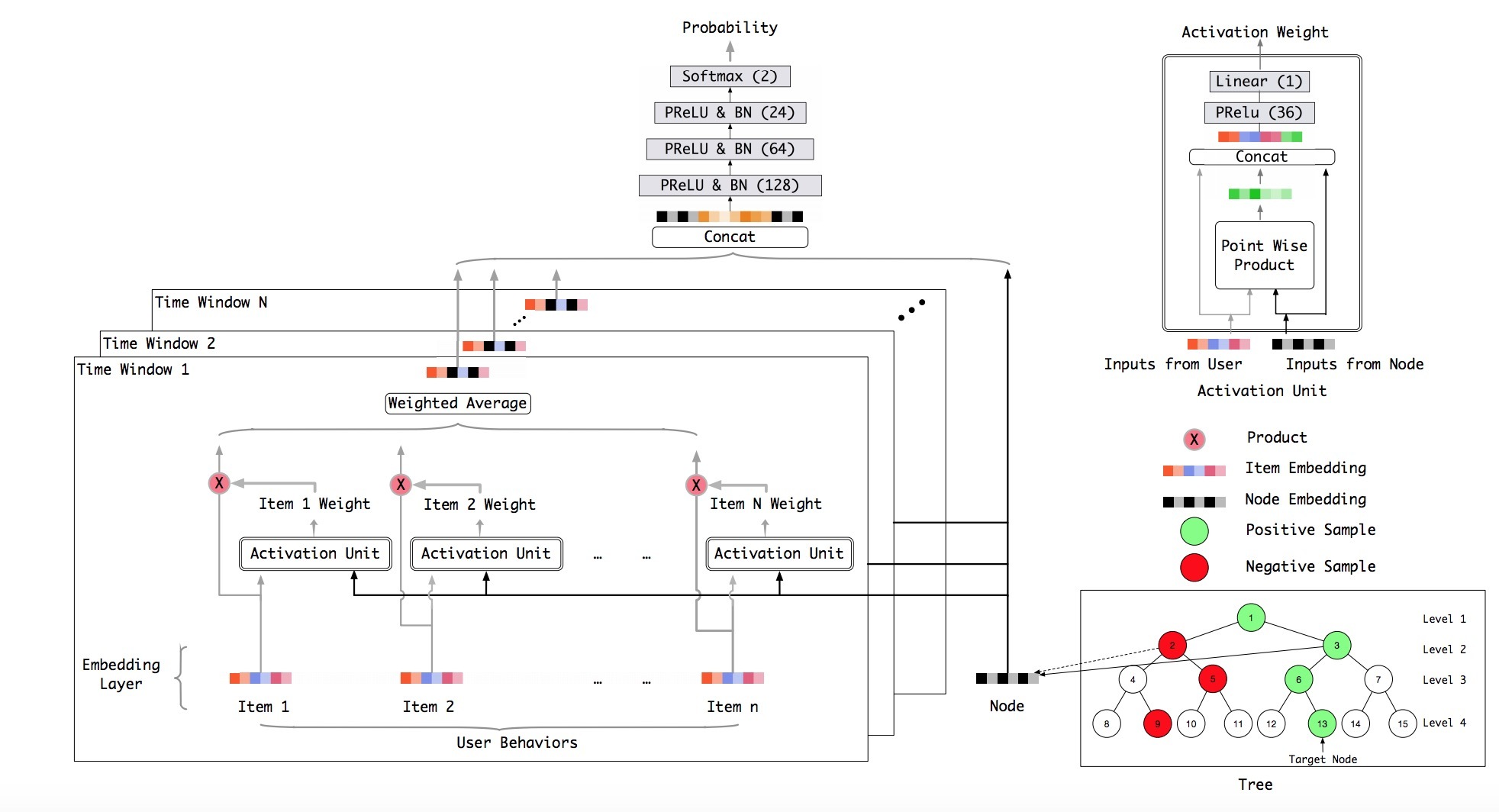
图2 tree-based deep模型架构。用户行为根据timestamp被划分成不同的时间窗口。在每个时间窗口中,item embeddings被平均加权,权重来自activation units。每个时间窗口的output沿着候选节点的embedding,被拼接成神经网络的输入。在经过三个带PReLU activation和batch normalization的fully-connected layers之后,使用一个二分类softmax来输入probability:用户是否对候选节点感兴趣。每个item和它对应的叶子节点共享相同的embedding。所有embeddings都是随机初始化的。
一棵推荐树(recommendation tree)由一个包含N个节点的集合构成,其中$$N=\lbrace n_1, n_2, ..., n_{\mid N \mid}\rbrace$$,表示$$\mid N \mid$$个孤立的非叶子节点或叶子节点。在N中的每个节点,除了根节点外,具有一个父节点、以及特定数目的子节点。特别的,在语料C中的每个item
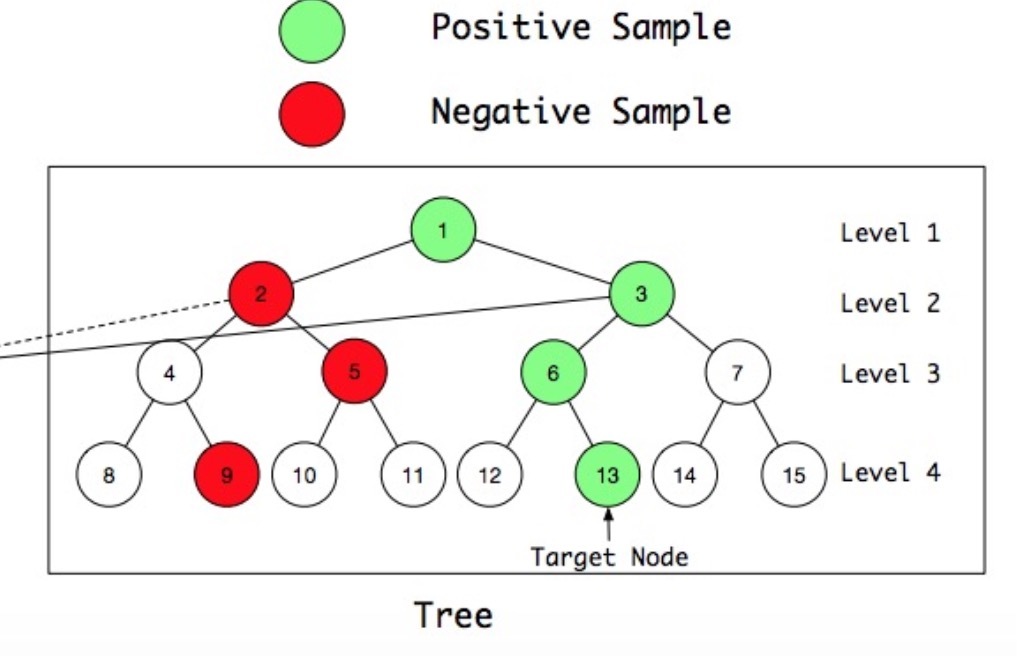
图2右下角
有了树结构,我们首先引入hierachical softmax来帮助区分TDM。在hierachical softmax中,树中的每个叶子节点n,从根节点出发到该节点具有唯一编码。例如,如果我们假定:左分枝为1,右分枝为0, 那么图2中树$$n_9$$的编码为110,
...(1)
其中:
- w:指的是叶子节点n的编码
-
$$l_j(n)$$ :是在节点n在第j层的父节点
通过上述的概率计算方式,hierarchical softmax可以避免softmax中的归一化项(语料中每个词都要遍历一次),从而解决概率计算问题。然而,为了发现最可能的叶子,该模型仍会遍历整个语料。从上到下沿着树路径(tree path)遍历每个层中最可能的节点,不能保证成功检索到最优的叶子。因此,hierarchical softmax的公式不适合大规模检索问题。另外,根据公式1, 树中的每个叶子节点以二分类的方式训练,来在两个子节点间做区分。但是如果两个节点是树中的邻居,它们很可能很相似。在推荐场景中,很可能该用户对两个子节点都感兴趣。hierarchical softmax主要会在最优解和次优解上建模,从全局上看会丢掉识别能力。如果使用贪婪定向搜索(greedy beam search)来检索这些最可能的叶子节点,一旦在树的上层做出坏的决策,模型在发现更好结果上会失败。YouTube的工作[7]也报告了他们已经尝试用hierachical softmax来学习user embeddings和item embeddings,而它比sampled-softmax[16]的方式效果要差。
hierachical softmax的公式不适合于大规模推荐,我们提出了一种新的树模型。
为了解决top-k 最喜欢items检索的效率问题,我们提出了一个最大堆树(max-heap like tree)的概率公式。最大堆树是一个树结构。其中在第j层中的非叶子节点n,对于每个用户u来说,满足以下公式:
...(2)
其中:
-
$$P^{(j)}(n \mid u)$$ :是第j层上,用户u对节点n感兴趣的真实概率(ground truth probability)。 -
$$\alpha^{(j)}$$ :是第j层指定layer的归一化项,用来确保在level上的概率和等于1。
等式(2)表明,一个父节点的真实偏好等于它的子节点的最大偏好,除以归一化项。注意,我们对该概率做细微修改,让u表示一个特定的用户状态(user state)。换句话说,一旦该用户有新行为,会从一个特定用户状态u转移到另一个状态u'。
我们的目标是,寻找具有最大偏好概率(largest preference probabilitiy)的k个叶子节点。假设,我们具有在树中每个节点n的真实概率$$P^{(j)}(n \mid u)$$,我们可以使用layer-wise的方式来检索k个节点的最大偏好概率,只有每一层的top k的子节点需要被探索。在这种方式下,top k个叶子节点可以被最终检索到。实际上,我们不需要知道在上述过程中每棵树节点的实际真实概率。我们需要知道的是每一层的概率顺序,来帮助发现在该层级上的top k个节点。基于这个观察,我们使用用户的隐式反馈数据和神经网络来训练每个层级(level)的识别器(discriminater),它可以告诉偏好概率的顺序。
假设用户u具有一个与叶子节点$$n_d$$的交互(interaction),即,$$n_d$$是一个u的正样本节点。这意味着:
其中:m是叶子层级,$$n_t$$是任意其它叶子节点。
在任意层级j中,$$l_j(n_d)$$表示在级别j上的$$n_d$$的父节点。根据等式(2)的公式,我们假设:
其中:$$n_q$$是除了$$l_j(n_d)$$外在层级j上的任意节点。
在上述分析的基础中,我们可以使用negative sampling来训练每个层级的顺序判别器(order discriminator)。细节上,与u有交互的叶子节点,它的父节点为u构成了在每个层级中的正样本集合。在每个层级上,随机选择若干负样本(除去正样本),构建了负样本集合。在图2中,绿色和红色节点给出了抽样示例。假设,给定一个用户和它的状态,目标节点是$$n_{13}$$。接着,$$n_{13}$$的父节点是正样本,这些在每个层级上随机抽取的红色节点,是负样本。这些样本接着被feed给二分类概率模型来获取层级(levels)上的顺序判别器(order discriminators)。我们使用一个全局DNN二分类模型,为所有层级使用不同输入来训练顺序判别器。可以使用高级的神经网络来提升模型能力。
假设$$y_u^+$$和$$y_u^-$$是关于u的正负样本集合。似然函数为:
$$ \prod\limits_u (\prod\limits_{u \in y_u^+} P(\hat{y}u(n) = 1 |n, u) \prod{n \in y_u^-} P(\hat{y}_u(n)=0 | n, u)) $$
...(3)
其中:
-
$$\hat{y}_u(n)$$ 是给定u的节点n的预测label。 -
$$P(\hat{y}_u(n) \mid n, u)$$ 是二分类概率模型的输出(它采用用户状态u以及抽样节点n作为输入)。
相应的loss函数为:
...(4)
其中:$$y_u(n)$$是给定u的节点n的ground truth label。3.4节将讲述如何根据loss函数来训练模型。
注意,提出的抽样方法与hierarchical softmax相当不同。对比在hierarchical softmax中使用的方法(它会让模型混淆最优和次优结果),我们的方法会为每个正节点的同层级随机选择负样本。这种方法让每一层的判别器是一个内部层级全局判别器(intra-level global)。每个层级的全局判别器(global discriminator)可以更独立的做出精准决策,不需要依赖于上层决策的好坏。全局判别能力对于hierarchical推荐方法非常重要。它可以确保:即使模型做出坏的决策,让低质量节点会漏进到上层中的候选集,通过该模型在下层也能选中那些相对更好的节点,而非非常差的节点。

算法1
给定一棵推荐树、以及一个最优模型,详细的hierarchical预测算法在算法1中描述。检索过程是layer-wise和top-down的。假设,期望的候选item数是k。对于语料C,它具有size=$$\mid C \mid$$,在最多$$2 * k * log \mid C \mid$$个节点上遍历,可以获取在一个完全二叉树上最终的推荐集合。节点数需要在一个关于log(corpus size)级别上遍历,这样可以做出高级的二分概率模型。
我们提出的TDM方法不仅减少了预测时的计算量,也潜在地提升了推荐质量(对比起在所有叶子节点上的brute-force search)。由于corpus size可能很大,如果没有这棵树,训练一个模型来直接发现最优items是一个很难的问题。使用树的层次化(tree hierarchy),大规模推荐问题可以被划分成许多更小的问题。在树的高层中只存在很少节点,判别问题更容易些。由高层上做出的决策可以重新定义候选集,它可以帮助更低层级做出更好的决策。第5.4节中的实验结果,将展示提出的hierarchical retrieval方法的效果要好于brute-force search。
下面,我们引入deep模型。整个模型如图2所示。受ctr工作的启发[34],我们为树中的每个节点学习低维embeddings,并使用attention模块来为相关行为进行软搜索(softly searching)以求更用的user representation。为了利用包含timestamp信息的用户行为,我们设计了block-wise input layer来区别在不同时间窗口的行为。历史行为可以被划分成沿timeline的不同时间窗,在每个时间窗口中的item embeddings是平均加权的。Attention模块和下面介绍的网络可以极大增强模型能力,同时可以在不能够以内积形式表示的候选集上做出用户偏好。
树节点的embeddings和树结构本身是模型的一部分。为了最小化公式(4)的Loss,抽样节点和相应的特征可以被用于训练该网络。注意,我们只在图2中出于简洁性,展示了用户行为特征的使用,而其它像user profile的features或contextual feature,可以被使用,并无大碍。
推荐树是tree-based deep推荐模型的一个基础部件。不同于multiclass和multi-label分类任务,其中tree被用于划分样本或labels,我们的推荐树会对items进行索引以方便检索。在hierarchical softmax中,词的层次结构可以根据WordNet的专家知识构建。在推荐场景,并不是每个语料可以提供特有的专家知识。一个直觉上的选择是,使用hierarchical聚类方法,基于数据集中item共现或相似度来构建树。但聚类树可能相当不均衡,不利于训练和检索。给定pairwise item similarity,paper[2]的算法给出了一种方法来通过谱聚类将items递归分割成子集。然而,对于大规模语料来说谱聚类的扩展性不够(复杂度随corpus size成三次方增长)。在本节中,我们主要关注合理和可行的树构建和学习方法。
树的初始化。由于我们假设该树表示了用户兴趣的层次结构化(hierarchical)信息,很自然地以在相近位置组织相似items的方式来构建树。假设,在许多领域中类目信息是广泛提供的,我们直觉上提出一个方法来利用item的类目信息来构建初始的树。不失一般性,我们在本节中使用二叉树。首先,我们会对所有类目随机排序,以一个intra-category的随机顺序将属于相同类目的items放置在一起。如果一个item属于多个类目,出于唯一性,item被随机分配给其中之一。这种方式下,我们给出了一个ranked items的列表。第二,这些ranked items被递归均分为两个相同的部分,直到当前集合有且仅包含一个item,它可以自顶向底构建一个近似完全二叉树。上述类型的category-based初始化,可以比完全随机树获取更好的hierarchy。
树的学习。作为模型的一部分,每棵叶子节点的embedding可以在模型训练之后被学习得到。接着,我们使用学到的叶子节点的embedding向量来聚类一棵新的树。考虑到corpus size,我们使用k-means聚类算法。在每个step,items会根据它们的embedding vectors被聚类成两个子集。注意,两个子集会被调整成相等以得到一个更平衡的树。当只剩下一个item时,递归过程停止,结果产生一棵二叉树。在我们的实验中,使用单台机器,当语料size为400w时,它会花费一个小时来构建这样的一个聚类树。第5节的实验结果表明所给树学习算法有效率。
图3展示了提出方法的online serving系统。Input feature assembling和item retrieval被划分成两个异步的stages。每个用户行为(包含点击、购买以及加入购物车),会触发realtime feature server组装新的input features。一旦接收到PV请求时,user targeting server会使用预组装的features来从该树中检索候选。如算法1所述,检索是layer-wise的,训练的神经网络被用于计算:对于给定input features,一个节点是否被喜欢的概率。
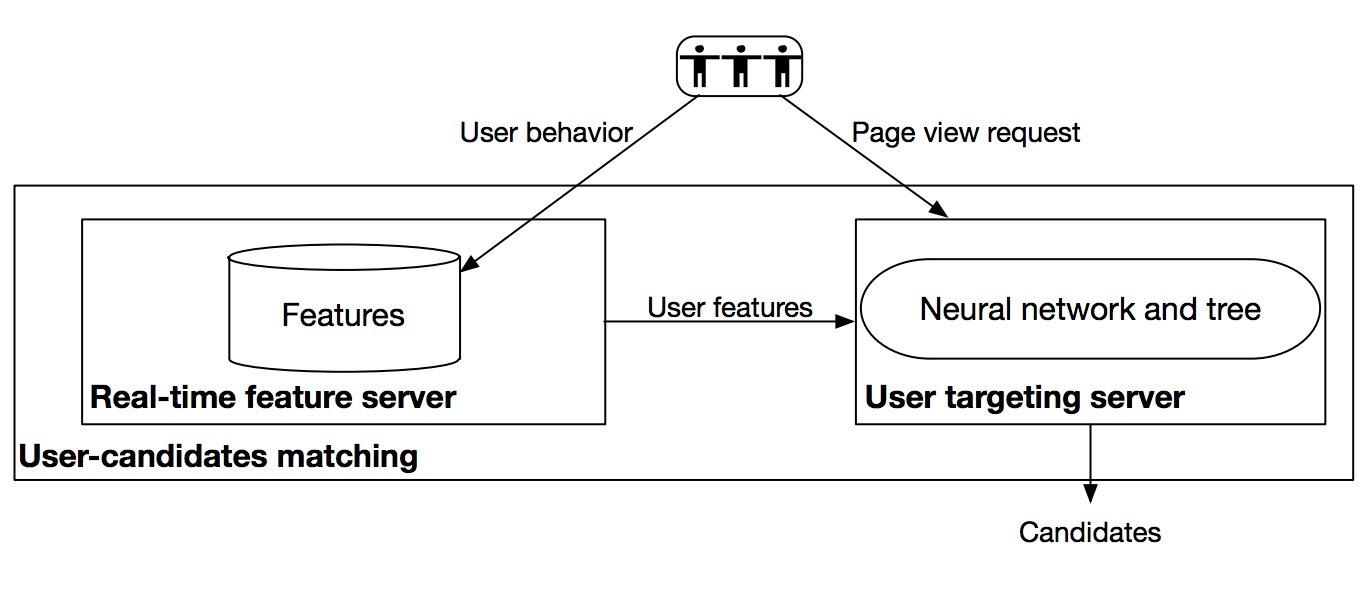
图3
本部分会研究tree-based模型的效果。实验结果在MovieLens-20M和Taobao advertising dataset(称为UserBehavior数据集)。
- MovieLens-20M: 包含了user-movie评分数据,带有timestamps。我们会处理隐式反馈问题,评分被二值化:4分以上为1. 另外,只有观看了至少10部电影的用户才会被保留。为了创建训练集、测试集、验证集,我们随机抽样了1000个用户做测试集,另1000用户做验证集,其余用户用于训练集。对于测试集和验证集,沿timeline的前一半user-movie观看记录被看成是已知行为,用于预测后一半。
- UserBehavior: 该数据集是taobao用户行为数据集的子集。我们随机选取了100w具有点击、购买、加入购物车、喜欢收藏的行为,在2017年11.25-12.03间。数据的组织与MovieLens非常相似,例如,一个user-item行为,包含了user ID, item ID, item category ID, 行为类型和timestamp。和MovieLens-20类似,只有至少有10个行为的用户会保留。10000用户会被机选中做为测试集,另一随机选中的10000用户是验证集。Item categories从taobao当前的商品类目的最底层类目得到。表1是两个数据集的主要统计:
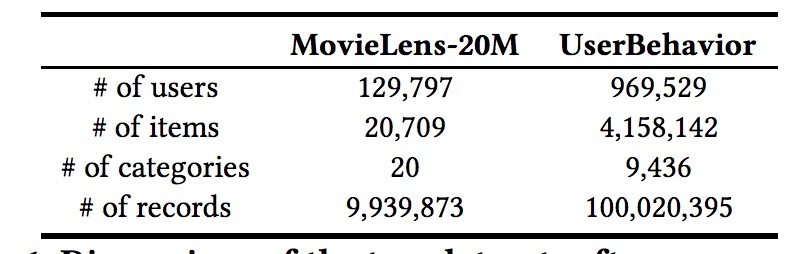
表1
为了评估不同方法效果,我们使用Precision@M, Recall@M和F-Measure@M。
- FM:由xLean项目提供的FM
- BPR-MF: 由[10]提供的BPR-MF
- Item-CF: Item-based CF,由Alibaba自己实现
- Youtube product-DNN: Youtube的方法。训练时使用Sampled-softmax,在Alibaba深度学习平台上实现。预测时在内积空间中采用Exact kNN search。
- TDM attention-DNN(tree-based模型,使用attention网络),如图2所示。树的初始化由3.5节所示,在实验期间保持不变。实现在github上。
对于FM, BPR-MF和item-CF,我们会基于验证集调参,例如:在FM和BPR-MF的因子数和迭代数,在item-CF中的邻居数。FM和BPR-MF需要用户在测试集和验证集上也具有在训练集中的反馈。因些,我们会根据timeline添加在测试集和验证集中前一半的user-item交互,到训练集中。对于Youtube product-DNN和TDM attention-DNN,节点的embeddings的维度设置为25, 因为在我们的实验中一个更高维度并不会带来很大的效果提升。hidden unit数目分别设置为128, 64, 64. 根据timestamp,用户行为被划分成10个time windows。在Youtube product-DNN和TDM attention-DNN中,对于每个隐式反馈,我们为MovieLens-20M随机选择100个负样本, 为UserBehavior随机选择600个负样本。注意,TDM的负样本数据是所有层的求和。我们会为接近叶子的层级抽样更多的负样本。
结果如表2所示:
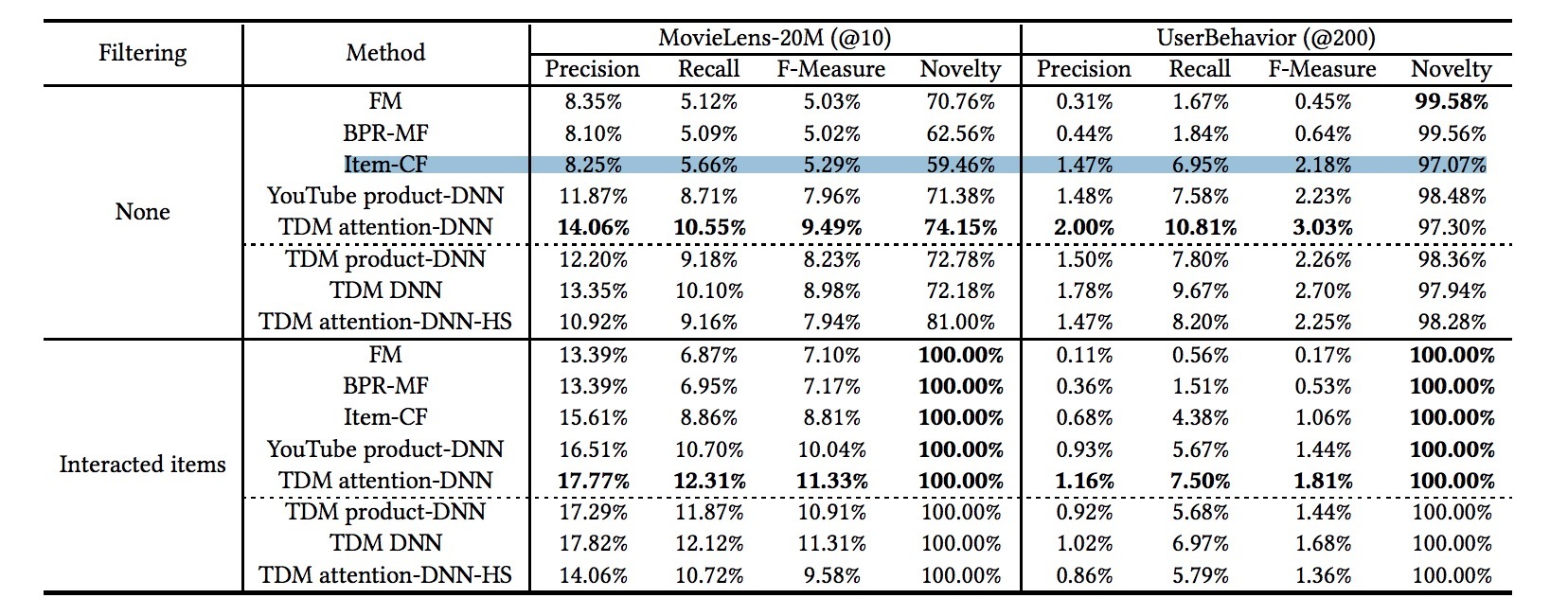
表2
为了验证新颖性(novelty),一种常用的方法是:过滤掉在推荐集中的交互项【8,20】,例如,只有这些新的items可以被最后推荐。因而,在一个完全新的结果集上比较accuracy更重要。在该实验中,结果集的size可以被补足到M,如果在过滤后size小于M。在过滤完交互items后,表2的底部展示了TDM的attention-DNN效果要好于所有baseline一大截。
为了进一步评估不同方法的能力,我们通过将这些交互类目从结果中排除做实验。每个方法可以补足以满足size需求。确实,category-level novelty在Taobao推荐系统中是最重要的新颖性(novelty)指标。我们希望减小与用户交互项的推荐数目。由于MovieLens-20M只有20个类目,该实验只包含了UserBehavior数据集,结果如表3所示。以recall指标为例,我们观察到item-CF的recall只有1.06%,由于它的推荐结果可以有一半跳出用户的历史行为。Youtube product-DNN对比item-CF会获取更好的结果,由于它从整个语料探索用户的潜在兴趣。而TDM attention-DNN在recall上的效果比Youtube的inner product方式要好34.3%。这种巨大的提升对于推荐系统来说非常有意义,它证明了更高级的模型对于推荐问题来说有巨大的不同。
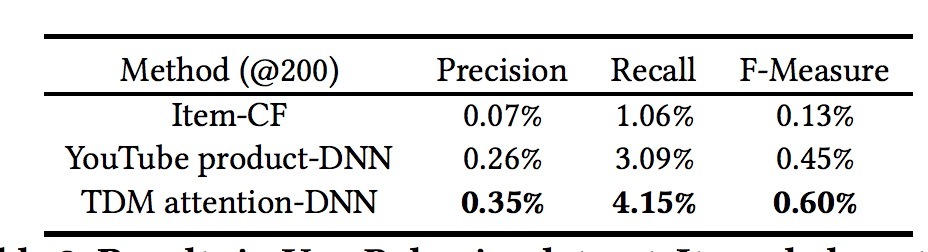
表3
TDM的变种。为了自身比较,也评估了一些变种:
- TDM product-DNN:
- TDM DNN:
- TDM attention-DNN-HS:
实验结果如表2中虚线以下所示。TDM attention-DNN到TDM DNN的比较,在UserBehavior数据集上有10% recall提升,attention模块会有明显的提升。TDM product-DNN效果比TDM DNN、TDM attention-DNN要差,因为inner product的方法比神经网络的交互形式要差些。这些结果表明:在TDM中引入的高级模型可以极大提升推荐的效果。注意,对比起TDM attention-DNN,TDM attention-DNN-HS会获取更差的结果。因为hierarchical softmax的公式不能很好适应推荐问题。
树的角色。Tree是TDM的关键组件。它不仅扮演着检索时的索引角色,也会以从粗到细的层级结构形式来建模语料。第3.3节中提到的,直接做出细粒度推荐要比以层级结构方式更难。我们通过实验证明了这个观点。图4展示了layer-wise Recall@200的hierarchical tree search(算法1)和brute-force search。该实验在UserBehavior数据集上使用TDM product-DNN模型,因为它是唯一可以采用brute-force search的变种。在高层级上(8-9),burte-force search的效果只比tree search要稍微好一点点,因为节点数很小。一旦在一个层级上的节点数增长了,对比起burte-force, search,tree search会获取更好的recall结果,因为tree search可以排除那些在高层级上的低质量结果,它可以减少在低层级上的问题的难度。该结果表明,在树结果中包含的hierarchy信息,可以帮助提升推荐的准确性。
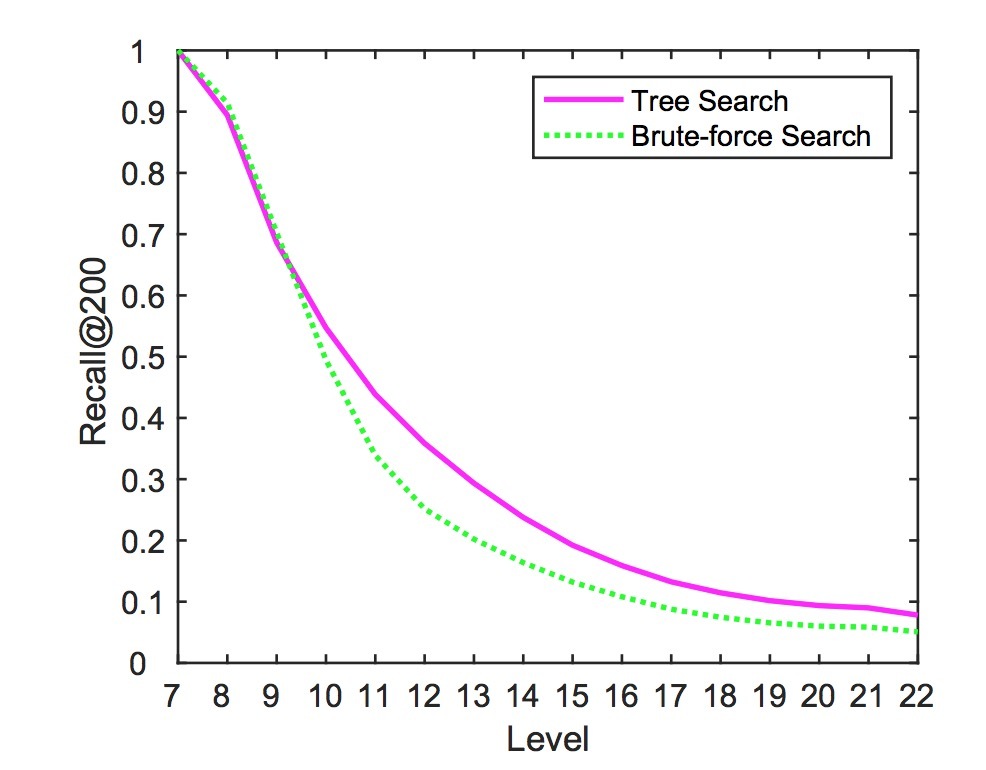
图4
tree learning。在3.5节中,我们提出了树的初始化和学习算法。表4给出了在initial tree和learnt tree间的比较结果。从结果看,我们可以发现,使用learnt tree结构的训练模型可以极大提升intial tree。例如,learnt tree的recall指标从4.15%到4.82%,对比起在过滤交互类目的实验中的initial tree,它使用Youtube product-DNN: 3.09%, item-CF: 1.06%。为了进一步比较这两个tree,我们展示了TDM attention-DNN的test loss和recall曲线,训练迭代如图5所示。从图5(a)中,我们可以看到learnt tree结构的test loss变小。图5(a)和5(b)表明,模型会收敛到较好的结果。上述结果表明,tree-learning算法可以提升items的hierarchy,从而进一步提升训练和预测。
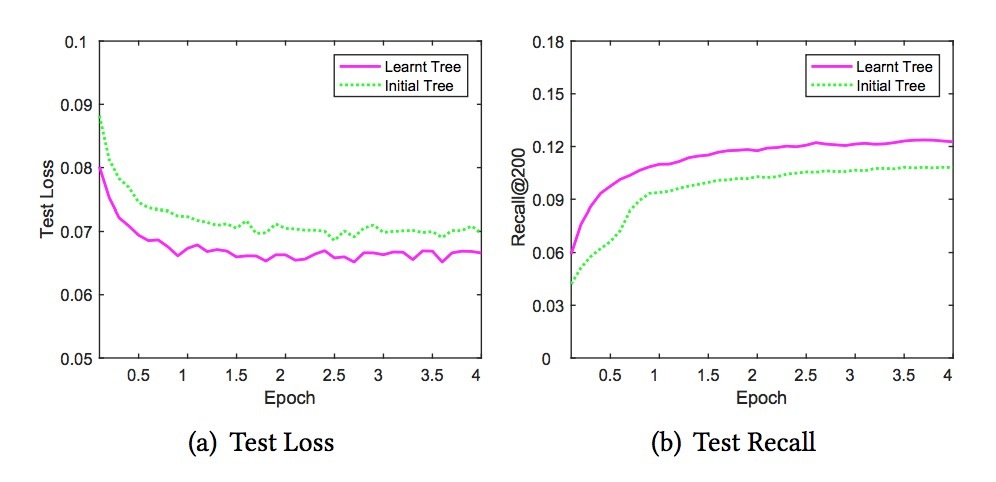
图5
我们在taobao效果广告平台的真实流量上评估了提出的TDM的方法。实验在taobao app主页上的猜你喜欢(Guess What You Like)中进行实验。用于评估效果的两个指标是:CTR和RPM(每1000的回报率)。详细如下:
...(8)
在我们的广告系统中,广告主会对一些给定的ad clusters竞价。有将近1400w的clusters,每个ad cluster包含了上百或上千条相似的ads。该验验以ad cluster的粒度开展,以保持与现有系统的一致。比较方法有:LR作为baseline。由于系统中有许多stages,部署TDM online方法是一个巨大的项目,涉及到整个系统。我们完成了第一个TDM DNN版本,并评估了online流量。每个分桶具有5%的在线流量。值得一提的是,有许多在线同时运行推荐的方法。他们从不同的视角,产生的结果进行合并进入到下一stages。TDM只会替换它们中最有效的,保持其它模块不变。带有TDM的测试分桶的平均metric提升率,如表5所示。
如表5所示,TDM方法的CTR提升了2.1%。这项提升表明提出的方法可以为用户召回更多精准的结果。另一方法,RPM的metric增加了6.4%,这意味着TDM的方法也可以为taobao广告平台带来更多回报。
预测效果。TDM使得,在大规模推荐中与user和items交叉高级神经网络变得可行,它打开了一个全新视角。值得一提的是,尽管高级神经网络在inferring时需要更多的计算,但整个预测过程的复杂度不会大于$$O(k * log \mid C \mid * t)$$,其中,k是所需结果的size,$$\mid C \mid$$是corpus size,t是网络中单个feed-forward pass的复杂度。该复杂度的上界在当前CPU/GPU硬件环境下是可接受的,在单个检索中,用户侧特征可以跨不同的节点共享,一些计算可以根据模型设计被共享。在Taobao展示广告系统中,它实际上会采用TDM DNN模型,平均一次推荐需要6ms。这样的运行时间比接下来的ctr预测模型要短,不会是系统瓶颈。