Scraping ChatGPT with Python
Scraping ChatGPT with Python
 Welcome to the new way of scraping the web. In the following guide, we will scrape BestBuy product pages, without writing any parsers, using one simple library: Scrapezone SDK.
Welcome to the new way of scraping the web. In the following guide, we will scrape BestBuy product pages, without writing any parsers, using one simple library: Scrapezone SDK.
 These extensions for scraping Google maps can be used for a number of purposes in various situations that can be either data collection or market research.
These extensions for scraping Google maps can be used for a number of purposes in various situations that can be either data collection or market research.
 Everything you need to know to automate, optimize and streamline the data collection process in your organization!
Everything you need to know to automate, optimize and streamline the data collection process in your organization!
 Check out this step-by-step guide on how to build your own LinkedIn scraper for free!
Check out this step-by-step guide on how to build your own LinkedIn scraper for free!
 A brief comparison between Selenium and Playwright from a web scraping perspective. Which one is the most convenient to use?
A brief comparison between Selenium and Playwright from a web scraping perspective. Which one is the most convenient to use?
 Learn how to emulate a normal user request and scrape Google Search Console data using Python and Beautiful Soup.
Learn how to emulate a normal user request and scrape Google Search Console data using Python and Beautiful Soup.
 Glassdoor is one of the biggest job markets in the world but can be hard to scrape. In this article, we'll legally extract job data with Python & Beautiful Soup
Glassdoor is one of the biggest job markets in the world but can be hard to scrape. In this article, we'll legally extract job data with Python & Beautiful Soup
 Learn the fundamental distinctions between web crawling and web scraping, and determine which one is right for you.
Learn the fundamental distinctions between web crawling and web scraping, and determine which one is right for you.
 Too lazy to scrape nlp data yourself? In this post, I’ll show you a quick way to scrape NLP datasets using Youtube and Python.
Too lazy to scrape nlp data yourself? In this post, I’ll show you a quick way to scrape NLP datasets using Youtube and Python.
 La necesidad de extraer datos de sitios web está aumentando. Cuando realizamos proyectos relacionados con datos, como el monitoreo de precios, análisis de negocios o agregador de noticias, siempre tendremos que registrar los datos de los sitios web. Sin embargo, copiar y pegar datos línea por línea ha quedado desactualizado. En este artículo, le enseñaremos cómo convertirse en un "experto" en la extracción de datos de sitios web, que consiste en hacer web scraping con python.
La necesidad de extraer datos de sitios web está aumentando. Cuando realizamos proyectos relacionados con datos, como el monitoreo de precios, análisis de negocios o agregador de noticias, siempre tendremos que registrar los datos de los sitios web. Sin embargo, copiar y pegar datos línea por línea ha quedado desactualizado. En este artículo, le enseñaremos cómo convertirse en un "experto" en la extracción de datos de sitios web, que consiste en hacer web scraping con python.
 In the last few years, web scraping has been one of my day to day and frequently needed tasks. I was wondering if I can make it smart and automatic to save lots of time. So I made AutoScraper!
In the last few years, web scraping has been one of my day to day and frequently needed tasks. I was wondering if I can make it smart and automatic to save lots of time. So I made AutoScraper!
 As the CEO of a proxy service and data scraping solutions provider, I understand completely why global data breaches that appear on news headlines at times have given web scraping a terrible reputation and why so many people feel cynical about Big Data these days.
As the CEO of a proxy service and data scraping solutions provider, I understand completely why global data breaches that appear on news headlines at times have given web scraping a terrible reputation and why so many people feel cynical about Big Data these days.
 Scraping football data (soccer in the US) is a great way to build comprehensive datasets to help create stats dashboards. Check out our football data scraper!
Scraping football data (soccer in the US) is a great way to build comprehensive datasets to help create stats dashboards. Check out our football data scraper!
 Ever since Google Web Search API deprecation in 2011, I've been searching for an alternative. I need a way to get links from Google search into my Python script. So I made my own, and here is a quick guide on scraping Google searches with requests and Beautiful Soup.
Ever since Google Web Search API deprecation in 2011, I've been searching for an alternative. I need a way to get links from Google search into my Python script. So I made my own, and here is a quick guide on scraping Google searches with requests and Beautiful Soup.
 As a marketer, you probably know that social media marketing is part art, part science.
As a marketer, you probably know that social media marketing is part art, part science.
 An easy tutorial showcasing the power of puppeteer and browserless. Scrape Amazon.com to gather prices of specific items automatically!
An easy tutorial showcasing the power of puppeteer and browserless. Scrape Amazon.com to gather prices of specific items automatically!
 The most talented developers in the world can be found on GitHub. What if there was an easy, fast and free way to find, rank and recruit them? I'll show you exactly how to to this in less than a minute using free tools and a process that I've hacked together to vet top tech talent at BizPayO.
The most talented developers in the world can be found on GitHub. What if there was an easy, fast and free way to find, rank and recruit them? I'll show you exactly how to to this in less than a minute using free tools and a process that I've hacked together to vet top tech talent at BizPayO.
 While building ScrapingBee I'm always checking different forums everyday to help people about web scraping related questions and engage with the community.
While building ScrapingBee I'm always checking different forums everyday to help people about web scraping related questions and engage with the community.
 La necesidad de extraer datos de sitios web está aumentando. Cuando realizamos proyectos relacionados con datos, como el monitoreo de precios, análisis de negocios o agregador de noticias, siempre tendremos que registrar los datos de los sitios web. Sin embargo, copiar y pegar datos línea por línea ha quedado desactualizado. En este artículo, le enseñaremos cómo convertirse en un "experto" en la extracción de datos de sitios web, que consiste en hacer web scraping con python.
La necesidad de extraer datos de sitios web está aumentando. Cuando realizamos proyectos relacionados con datos, como el monitoreo de precios, análisis de negocios o agregador de noticias, siempre tendremos que registrar los datos de los sitios web. Sin embargo, copiar y pegar datos línea por línea ha quedado desactualizado. En este artículo, le enseñaremos cómo convertirse en un "experto" en la extracción de datos de sitios web, que consiste en hacer web scraping con python.
 While there are a few different libraries for scraping the web with Node.js, in this tutorial, i'll be using the puppeteer library.
While there are a few different libraries for scraping the web with Node.js, in this tutorial, i'll be using the puppeteer library.
 Scrapy is an application framework for crawling web sites and extracting structured/unstructured data which can be used for a wide range of applications such as data mining, information processing or historical archival.As we all know, this is the age of “Data”. Data is everywhere, and every organisation wants to work with Data and take its business to a higher level. In this scenario Scrapy plays a vital role to provide Data to these organisations so that they can use it in wide range of applications. Scrapy is not only able to scrap data from websites, but it is able to scrap data from web services.
Scrapy is an application framework for crawling web sites and extracting structured/unstructured data which can be used for a wide range of applications such as data mining, information processing or historical archival.As we all know, this is the age of “Data”. Data is everywhere, and every organisation wants to work with Data and take its business to a higher level. In this scenario Scrapy plays a vital role to provide Data to these organisations so that they can use it in wide range of applications. Scrapy is not only able to scrap data from websites, but it is able to scrap data from web services.
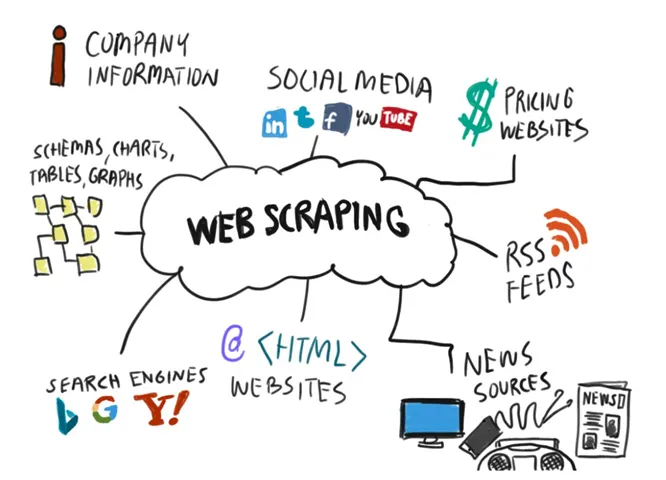 Previously published at https://www.octoparse.es/blog/15-preguntas-frecuentes-sobre-web-scraping
Previously published at https://www.octoparse.es/blog/15-preguntas-frecuentes-sobre-web-scraping
 Usually forgotten in all Data Science masters and courses, Web Scraping is, in my honest opinion a basic tool in the Data Scientist toolset, as is the tool for getting and therefore using external data from your organization when public databases are not available.
Usually forgotten in all Data Science masters and courses, Web Scraping is, in my honest opinion a basic tool in the Data Scientist toolset, as is the tool for getting and therefore using external data from your organization when public databases are not available.
 It’s safe to say that the amount of data available on the internet nowadays is practically limitless, with much of it no more than a few clicks away. However, gaining access to the information you need sometimes involves a lot of time, money, and effort.
It’s safe to say that the amount of data available on the internet nowadays is practically limitless, with much of it no more than a few clicks away. However, gaining access to the information you need sometimes involves a lot of time, money, and effort.
 Con el advenimiento de los grandes datos, las personas comienzan a obtener datos de Internet para el análisis de datos con la ayuda de rastreadores web. Hay varias formas de hacer su propio rastreador: extensiones en los navegadores, codificación de python con Beautiful Soup o Scrapy, y también herramientas de extracción de datos como Octoparse.
Con el advenimiento de los grandes datos, las personas comienzan a obtener datos de Internet para el análisis de datos con la ayuda de rastreadores web. Hay varias formas de hacer su propio rastreador: extensiones en los navegadores, codificación de python con Beautiful Soup o Scrapy, y también herramientas de extracción de datos como Octoparse.
 Web scraping has broken the barriers of programming and can now be done in a much simpler and easier manner without using a single line of code.
Web scraping has broken the barriers of programming and can now be done in a much simpler and easier manner without using a single line of code.
 Last week I finished my Ruby curriculum at Microverse. So I was ready to build my Capstone Project. Which is a solo project at the end of each of the Microverse technical curriculum sections.
Last week I finished my Ruby curriculum at Microverse. So I was ready to build my Capstone Project. Which is a solo project at the end of each of the Microverse technical curriculum sections.
 The travel industry is a major service sector in most countries these days. It is also a major employment and revenue provider. This demands a lot of constant innovation and maintenance. The travel industry is a dynamic industry where the needs and preferences of a customer change every moment. The market players in this field need to keep up with the trends in the industry, the choices of the customers and even on the details of their own historical performance to perform better as time progresses. Thus, as you would presume, the companies working in the travel sector need a lot of data from multiple sources and a pipeline to assess and use that data for insights and recommendations.
The travel industry is a major service sector in most countries these days. It is also a major employment and revenue provider. This demands a lot of constant innovation and maintenance. The travel industry is a dynamic industry where the needs and preferences of a customer change every moment. The market players in this field need to keep up with the trends in the industry, the choices of the customers and even on the details of their own historical performance to perform better as time progresses. Thus, as you would presume, the companies working in the travel sector need a lot of data from multiple sources and a pipeline to assess and use that data for insights and recommendations.
 With the massive increase in the volume of data on the Internet, this technique is becoming increasingly beneficial in retrieving information from websites and applying them for various use cases. Typically, web data extraction involves making a request to the given web page, accessing its HTML code, and parsing that code to harvest some information. Since JavaScript is excellent at manipulating the DOM (Document Object Model) inside a web browser, creating data extraction scripts in Node.js can be extremely versatile. Hence, this tutorial focuses on javascript web scraping.
With the massive increase in the volume of data on the Internet, this technique is becoming increasingly beneficial in retrieving information from websites and applying them for various use cases. Typically, web data extraction involves making a request to the given web page, accessing its HTML code, and parsing that code to harvest some information. Since JavaScript is excellent at manipulating the DOM (Document Object Model) inside a web browser, creating data extraction scripts in Node.js can be extremely versatile. Hence, this tutorial focuses on javascript web scraping.
 La necesidad de crawling datos web ha aumentado en los últimos años. Los datos crawled se pueden usar para evaluación o predicción en diferentes campos. Aquí, me gustaría hablar sobre 3 métodos que podemos adoptar para scrape datos desde un sitio web.
La necesidad de crawling datos web ha aumentado en los últimos años. Los datos crawled se pueden usar para evaluación o predicción en diferentes campos. Aquí, me gustaría hablar sobre 3 métodos que podemos adoptar para scrape datos desde un sitio web.
 No-Code tools for collecting data for your Data Science project
No-Code tools for collecting data for your Data Science project
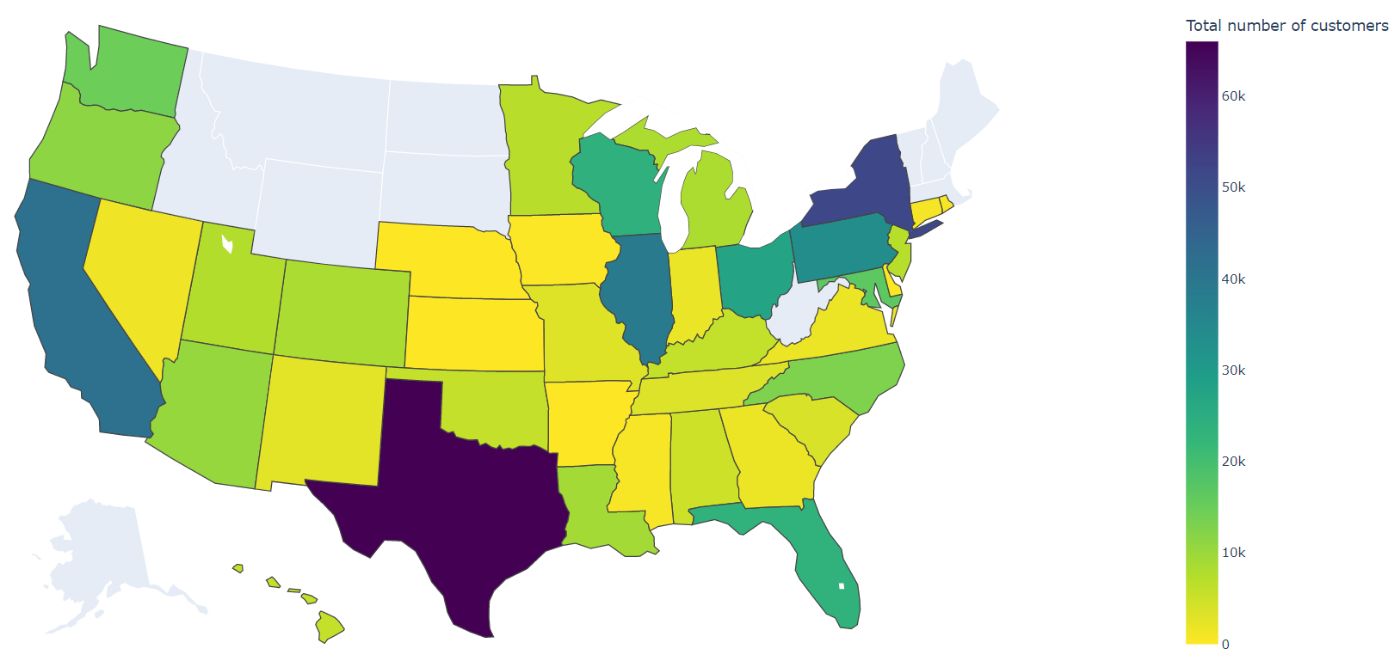 Early January 2022, I spontaneously bought a pager. I looked into the US pager market, and to my surprise...
Early January 2022, I spontaneously bought a pager. I looked into the US pager market, and to my surprise...
 Online Shopping for various commodities is no more a luxury but has rather become a necessity now. Getting your desired product on your doorstep has made it easier for consumers to shop effortlessly. As a result, several niche e-commerce or generic shopping sites pop up every year. This trend is not limited to some specific region rather it’s a global phenomenon now, as more and more people are preferring online shopping over visiting outlets due to traffic congestions and ease of purchasing. This is why it’s predicted that by 2021, overall 15.5% of sales will be generated via online websites.
Online Shopping for various commodities is no more a luxury but has rather become a necessity now. Getting your desired product on your doorstep has made it easier for consumers to shop effortlessly. As a result, several niche e-commerce or generic shopping sites pop up every year. This trend is not limited to some specific region rather it’s a global phenomenon now, as more and more people are preferring online shopping over visiting outlets due to traffic congestions and ease of purchasing. This is why it’s predicted that by 2021, overall 15.5% of sales will be generated via online websites.
 When you talk about web scraping, PHP is the last thing most people think about.
When you talk about web scraping, PHP is the last thing most people think about.
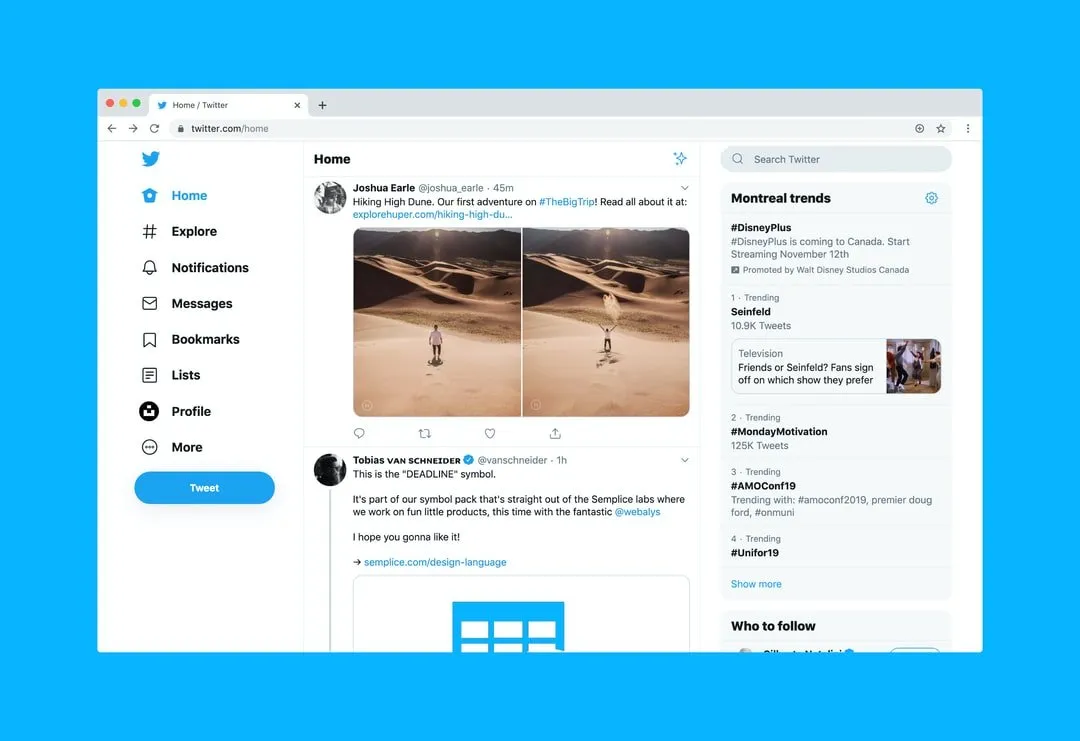 A Quick Method To Extract Tweets and Replies For Free
A Quick Method To Extract Tweets and Replies For Free
 A quick introduction to web scraping, what it is, how it works, some pros and cons, and a few tools you can use to approach it
A quick introduction to web scraping, what it is, how it works, some pros and cons, and a few tools you can use to approach it
 How to gather data without those pesky databases.
How to gather data without those pesky databases.
 With a Scriptable app, it’s possible to create a native iOS widget even with basic JavaScript knowledge.
With a Scriptable app, it’s possible to create a native iOS widget even with basic JavaScript knowledge.
 Learn how to scrape the web using scripts written in node.js to automate scraping data off of the website and using it for whatever purpose.
Learn how to scrape the web using scripts written in node.js to automate scraping data off of the website and using it for whatever purpose.
 Hi Devs!
Hi Devs!
 Suppose you want to get large amounts of information from a website as quickly as possible. How can this be done?
Suppose you want to get large amounts of information from a website as quickly as possible. How can this be done?
 Learn how to execute web scraping on Twitter using the snsscrape Python library and store scraped data automatically in database by using HarperDB.
Learn how to execute web scraping on Twitter using the snsscrape Python library and store scraped data automatically in database by using HarperDB.
 How often have you wanted a piece of information and have turned to Google for a quick answer? Every piece of information that we need in our daily lives can be obtained from the internet. You can extract data from the web and use it to make the most effective business decisions. This makes web scraping and crawling a powerful tool. If you want to programmatically capture specific information from a website for further processing, you need to either build or use a web scraper or a web crawler. We aim to help you build a web crawler for your own customized use.
How often have you wanted a piece of information and have turned to Google for a quick answer? Every piece of information that we need in our daily lives can be obtained from the internet. You can extract data from the web and use it to make the most effective business decisions. This makes web scraping and crawling a powerful tool. If you want to programmatically capture specific information from a website for further processing, you need to either build or use a web scraper or a web crawler. We aim to help you build a web crawler for your own customized use.
 To scrape a website, it’s common to send GET requests, but it's useful to know how to send data. In this article, we'll see how to start with POST requests.
To scrape a website, it’s common to send GET requests, but it's useful to know how to send data. In this article, we'll see how to start with POST requests.
 Learn how to leverage web scraping in marketing. In this article, we unpack use cases and tips for getting started.
Learn how to leverage web scraping in marketing. In this article, we unpack use cases and tips for getting started.
 Are you looking for a method of scraping Amazon reviews and do not know where to begin with? In that case, you may find this blog very useful in scraping Amazon reviews. In this blog, we will discuss scraping amazon reviews using Scrapy in python. Web scraping is a simple means of collecting data from different websites, and Scrapy is a web crawling framework in python.
Are you looking for a method of scraping Amazon reviews and do not know where to begin with? In that case, you may find this blog very useful in scraping Amazon reviews. In this blog, we will discuss scraping amazon reviews using Scrapy in python. Web scraping is a simple means of collecting data from different websites, and Scrapy is a web crawling framework in python.
 As Data Scientists, people tend to think what they do is developing and experimenting with sophisticated and complicated algorithms, and produce state of the art results. This is largely true. It is what a data scientist is mostly proud of and the most innovative and rewarding part. But what people usually don’t see is the sweat they go through to gather, process, and massage the data that leads to the great results. That’s why you can see SQL appears on most of the data scientist position requirements.
As Data Scientists, people tend to think what they do is developing and experimenting with sophisticated and complicated algorithms, and produce state of the art results. This is largely true. It is what a data scientist is mostly proud of and the most innovative and rewarding part. But what people usually don’t see is the sweat they go through to gather, process, and massage the data that leads to the great results. That’s why you can see SQL appears on most of the data scientist position requirements.
 A while ago I was trying to perform an analysis of a Medium publication for a personal project. But getting the data was a problem – scraping only the publication’s home page does not guarantee that you get all the data you want.
A while ago I was trying to perform an analysis of a Medium publication for a personal project. But getting the data was a problem – scraping only the publication’s home page does not guarantee that you get all the data you want.
 Web data extraction or web scraping in 2020 is the only way to get desired data if owners of a web site don't grant access to their users through API.
Web data extraction or web scraping in 2020 is the only way to get desired data if owners of a web site don't grant access to their users through API.
 Por favor clic el artículo original:http://www.octoparse.es/blog/70-fuentes-de-datos-gratuitas-en-2020
Por favor clic el artículo original:http://www.octoparse.es/blog/70-fuentes-de-datos-gratuitas-en-2020
 Today, We're going to build a script that scrapes Twitter to gather stock ticker symbols. We'll use those symbols to scrape yahoo finance for stock Options data. To ensure we can download all the Options data, we’ll make each web request with High Availability Onion Routing. In the end, we’ll do some Pandas magic to pull the first out of the money call contract for each symbol into the final watchlist.
Today, We're going to build a script that scrapes Twitter to gather stock ticker symbols. We'll use those symbols to scrape yahoo finance for stock Options data. To ensure we can download all the Options data, we’ll make each web request with High Availability Onion Routing. In the end, we’ll do some Pandas magic to pull the first out of the money call contract for each symbol into the final watchlist.
 In this post we are going to scrape websites to gather data via the API World's top 300 APIs of year. The major reason of doing web scraping is it saves time and avoid manual data gathering and also allows you to have all the data in a structured form.
In this post we are going to scrape websites to gather data via the API World's top 300 APIs of year. The major reason of doing web scraping is it saves time and avoid manual data gathering and also allows you to have all the data in a structured form.