我们知道__简单选择排序__的时间复杂度为O(n^2),熟悉各种排序算法的朋友都知道,这个时间复杂度是很大的,所以怎样减小简单选择排序的时间复杂度呢?简单选择排序主要 操作是进行关键字的比较,所以怎样减少比较次数就是改进的关键。简单选择排序中第i趟需要进行__n-i__次比较,如果我们用到前面已排好的序列__a[1...i-1]__ 是否可以减少比较次数呢?答案是可以的。举个例子来说吧,A、B、C进行比赛,B战胜了A,C战胜了B,那么显然C可以战胜A,C和A就不用比了。正是基于这种思想,有人提出了__树形选择排序__:对n个记录进行两两比较,然后在([n/2]向上取整)个较小者之间在进行两两比较,如此重复,直到选出最小记录。但是这种排序算法需要的辅助空间比较多,所以威洛姆斯(J . Willioms)在1964年提出了另一种选择排序,这就是下面要谈的__堆排序__。
首先堆heap是一种数据结构,是一棵完全二叉树且满足性质:所有非叶子结点的值均不大于或均不小于其左、右孩子结点的值.
堆排序的基本思想是利用heap这种数据结构(可看成一个完全二叉树),使在排序中比较的次数明显减少。
堆排序的时间复杂度为O(n*log(n)), 非稳定排序,原地排序(空间复杂度O(1))。
堆排序的关键在于建堆和调整堆,下面简单介绍一下建堆的过程:
第1趟将索引0至n-1处的全部数据建大顶(或小顶)堆,就可以选出这组数据的最大值(或最小值)。将该堆的根节点与这组数据的最后一个节点交换,就使的这组数据中最大(最小)值排在了最后。
第2趟将索引0至n-2处的全部数据建大顶(或小顶)堆,就可以选出这组数据的最大值(或最小值)。将该堆的根节点与这组数据的倒数第二个节点交换,就使的这组数据中最大(最小)值排在了倒数第2位。
…
第k趟将索引0至n-k处的全部数据建大顶(或小顶)堆,就可以选出这组数据的最大值(或最小值)。将该堆的根节点与这组数据的倒数第k个节点交换,就使的这组数据中最大(最小)值排在了倒数第k位。
其实整个堆排序过程中, 我们只需重复做两件事:
-
建堆(初始化+调整堆, 时间复杂度为O(n));
-
拿堆的根节点和最后一个节点交换(siftdown, 时间复杂度为O(n*log n) )
因而堆排序整体的时间复杂度为O(n*log n).
下面通过一组数据说明堆排序的方法:
9, 79, 46, 30, 58, 49
1: 先将待排序的数视作完全二叉树(按层次遍历顺序进行编号, 从0开始),如下图:
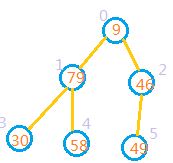
2:完全二叉树的最后一个非叶子节点,也就是最后一个节点的父节点。最后一个节点的索引为数组长度len-1,那么最后一个非叶子节点的索引应该是为(len-1)/2.也就是从索引为2的节点开始,如果其子节点的值大于其本身的值。则把他和较大子节点进行交换,即将索引2处节点和索引5处元素交换。交换后的结果如图:
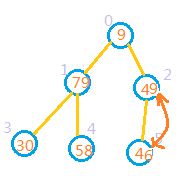
3:向前处理前一个节点,也就是处理索引为1的节点,此时79>30,79>58,因此无需交换。
4:向前处理前一个节点,也就是处理索引为0的节点,此时9 < 79,9 < 49, 因此需交换。应该拿索引为0的节点与索引为1的节点交换,因为79>49. 如图:
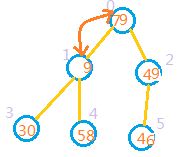
5:如果某个节点和它的某个子节点交换后,该子节点又有子节点,系统还需要再次对该子节点进行判断。如上图因为1处,3处,4处中,1处的值大于3,4出的值,所以还需交换。
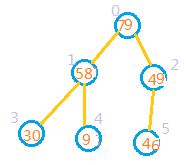
牢记: 将每次堆排序得到的最大元素与当前规模的数组最后一个元素交换。
#include<cstdio>
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
void adjust(int arr[], int len, int index)
{
int left = 2*index + 1;
int right = 2*index + 2;
int maxIdx = index;
if(left<len && arr[left] > arr[maxIdx]) maxIdx = left;
if(right<len && arr[right] > arr[maxIdx]) maxIdx = right; // maxIdx是3个数中最大数的下标
if(maxIdx != index) // 如果maxIdx的值有更新
{
swap(arr[maxIdx], arr[index]);
adjust(arr, len, maxIdx); // 递归调整其他不满足堆性质的部分
}
}
void heapSort(int arr[], int size)
{
for(int i=size/2 - 1; i >= 0; i--) // 对每一个非叶结点进行堆调整(从最后一个非叶结点开始)
{
adjust(arr, size, i);
}
for(int i = size - 1; i >= 1; i--)
{
swap(arr[0], arr[i]); // 将当前最大的放置到数组末尾
adjust(arr, i, 0); // 将未完成排序的部分继续进行堆排序
}
}
int main()
{
int array[8] = {8, 1, 14, 3, 21, 5, 7, 10};
heapSort(array, 8);
for(auto it: array)
{
cout<<it<<endl;
}
return 0;
}为何堆排序是不稳定排序?
当数组中有相等元素时,堆排序算法对这些元素的处理方法不止一种,故是不稳定的。
可重载比较函数的写法:
#include<memory.h>
#include<stdio.h>
#include<stdlib.h>
void swap(void* x, void* y, size_t sz) {
void* t = malloc(sz);
memcpy(t, x, sz);
memcpy(x, y, sz);
memcpy(y, t, sz);
free(t);
}
void makeHeap(void* x, int i, int n, size_t sz, int(*cmp)(const void*, const void*)) {
char* y = (char*)x;
int l = 2 * i + 1;
int r = 2 * i + 2;
int m;
if (l<n && (*cmp)(y + l*sz, y + i*sz)>0) m = l;
else m = i;
if (r<n && (*cmp)(y + r*sz, y + m*sz)>0) m = r;
if (m != i){
swap(y + i*sz, y + m*sz, sz);
makeHeap(x, m, n, sz, cmp);
}
}
void buildHeap(void* x, int n, size_t sz, int(*cmp)(const void*, const void*)) {
for (int i = n / 2 - 1; i >= 0; i--) makeHeap(x, i, n, sz, cmp);
}
void heapSort(void* x, int n, size_t sz, int(*cmp)(const void*, const void*)) {
buildHeap(x, n, sz, cmp);
char* y = (char*)x;
for (int i = n - 1; i >= 1; i--){
swap(y, y + i*sz, sz);
makeHeap(x, 0, --n, sz, cmp);
}
}
void p(int* x,int n){
for (int k = 0; k < n; k++){
printf("%d ", x[k]);
}
printf("\n");
}
int less(const void* a, const void* b){
return *((int*)a) < *((int*)b);
}
int greater(const void* a, const void* b){
return *((int*)a) > *((int*)b);
}
int main(){
int x[] = { 2, 3, 4, 6, 8, 2, 9, 0 };
// 降序全排列
heapSort(x, 8, sizeof(int), less);
p(x, 8);
// 升序全排列
heapSort(x, 8, sizeof(int), greater);
p(x, 8);
// 最大的4个元素,在数组末尾
heapSort(x, 4, sizeof(int), less);
p(x, 8);
}