PaperbackWriter is a project that Taylor Sasser and I started in June 2018 with the goal of further understanding how neural networks can be used to replicate the English language. Furthermore, the creation of this project was made with the intent of making neural network code that was lightweight, efficient and intuitive.
The project was built and setup inside Visual Studio on Windows. The project requires only the two dependencies below to run.
- C++ 14
- CUDA 9.2 or higher
LSTM networks function very similar to vanilla neural networks in that they utilize the same feedforward and backpropagation algorithms that traditional neural networks use. The key difference resides in the ability for LSTM networks to learn across sequences of data rather than the "one-to-one" model that traditional neural networks use (as seen in the image below). This phenomenon allows for LSTMs to establish long-term dependencies over patterns of data.

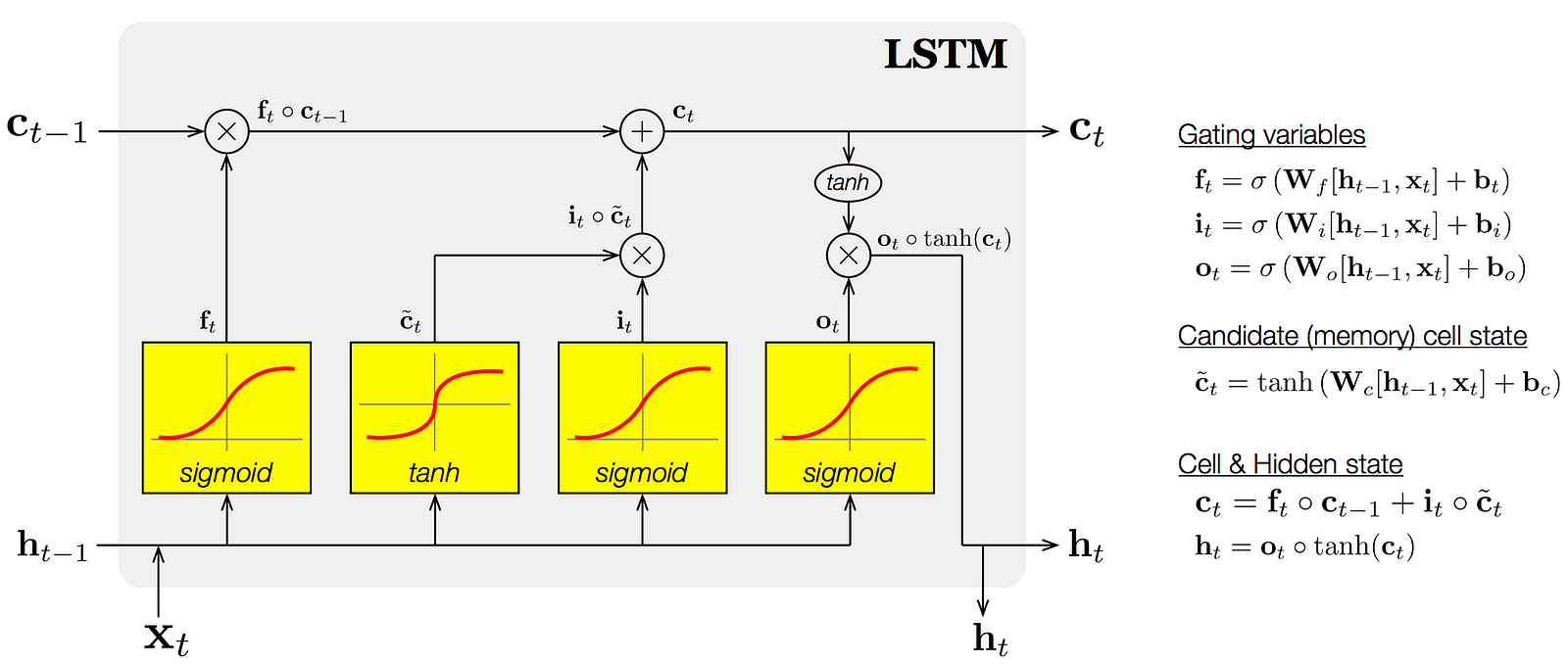
The abstract model above can be more explicitly visualed using the diagram and equations shown below, which focus on one individual LSTM unit as a part of a larger network. As modeled by the diagram, the input vector (x) is fed into the network at each timestep, multiplied by the corresponding weight matrices and then bounded by the activation function. As a result two recurrent vectors are generated, the cell and hidden state, that are fed into the next timestep. These recurrent states allow for the network to learn across sequences of data.
After the sequence has gone through a number of sequence steps, the change in the weights must be calculated w.r.t the loss function (a.k.a the gradient). This process of going back through the network and calculating the change of a cost function w.r.t each individual weight is called "backpropagation through time" (below). In the case of this project, the cross entropy function below was used to calculate the error, where the "p" is the ground truth and "q" is the network output. After "backpropagating" for a number of time steps the weights are incremented or decremented by a small amount according to the gradient and the optimizer function used (ADAGrad, RMSProp, etc.).

This process of "feeding" forward data and then "backpropagating through time" is repeated thousands or millions of times. As a result, after the training session, the network will be able to predict and generate its own sequences that closely model the data the network was trained on.
Using the code from kernel.cu the network was trained with the following constants below:
Learning Rate: 0.25
Weight Mean: 0
Weight Standard Deviation: 0.15
Hidden Size: 500
Input Size: 89
Sequence Length: 100
Optimizer: Adagrad
The network was trained on the entire "Lord of the Rings" series (including the Hobbit) by encoding each character into a vector with a size of 89. Each bit of the vector corresponded to a character in the English language. Therefore, the network was trained character by character on the book. After training for about 1.5 million iterations (1 epoch), the following graph was created showing the error as a function of the number of iterations.

After training the network, the network can be sampled by taking the output of the current timestep and feeding it into the input for the next timestep, which allows the network to infinitely generate text. Below are some of the resulting outputs after sampling the network.
ITERATION: 1070000
The Frodo past onder all hiten's on tree halt: Mhinis der and
l's air. We shadder Noint, Wow of Dorendo wroughs thoule betowest is gate in
here in has from be not op not out he could find longing
nom.'
'Dreying in not her. The bank no last, and muse get
were shorly and! 'We fell and and
Aragorn,' said Frodo they know even
the like the virnowned; Minilas,' said and his on thear Fanemares paid emwe, but in for now Bilds and will vanterngos, there before dright be of Goremened of the mounilad. Sogen in
even they had fielt if the him and his at thilt, would geew his sumble's the moved of the flokle,
ITERATION: 1240000
Pir
sappeds your his wores they had maising? 'We hand yet the Gandalf 'rass gun us of the some and sever a while
Frodo: that my is of Companing youiles. Will they well,
handued pele, usettles
as naggoth. It not palp in is not hands more towed that anster sed doget a slean you litelyss out ome lot with nor here it time with)d forty around in
hich till
were did not old fimle; and was must ang. And Gistern
be: told (he wood my stoinges were dick of sees, is head
must to nus Mer youn they sat the frould beew of the did,' small a gobes one the wand to from their, that? De ment he
still iss
only. He are his have to axpentains. 'I rudgoand ound he.
Gandalf and veliet, too Moad our matching like and Elve sit any event burny anorean it never as the nave, gard. At with aglot, and handwells their loovery, must they methed that he was sedred to all they sanbly that he
sind this for alferving all of? Sanger our at drew. Whostred forght him!GÇÖ
'What than. The Ringous cayle for gear.
Although the output has obvious gramatical and spelling errors, the network did learn to formulate sentences that are clearly English. Furthermore, the network learned the names of several characters and even attempted (rather unsuccessfully) to create diologue between characters.